 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQUEST: A Retrieval Dataset of Entity-Seeking Queries with Implicit Set Operations
May 19, 2023



Formulating selective information needs results in queries that implicitly specify set operations, such as intersection, union, and difference. For instance, one might search for "shorebirds that are not sandpipers" or "science-fiction films shot in England". To study the ability of retrieval systems to meet such information needs, we construct QUEST, a dataset of 3357 natural language queries with implicit set operations, that map to a set of entities corresponding to Wikipedia documents. The dataset challenges models to match multiple constraints mentioned in queries with corresponding evidence in documents and correctly perform various set operations. The dataset is constructed semi-automatically using Wikipedia category names. Queries are automatically composed from individual categories, then paraphrased and further validated for naturalness and fluency by crowdworkers. Crowdworkers also assess the relevance of entities based on their documents and highlight attribution of query constraints to spans of document text. We analyze several modern retrieval systems, finding that they often struggle on such queries. Queries involving negation and conjunction are particularly challenging and systems are further challenged with combinations of these operations.
AmbiCoref: Evaluating Human and Model Sensitivity to Ambiguous Coreference
Feb 03, 2023



Given a sentence "Abby told Brittney that she upset Courtney", one would struggle to understand who "she" refers to, and ask for clarification. However, if the word "upset" were replaced with "hugged", "she" unambiguously refers to Abby. We study if modern coreference resolution models are sensitive to such pronominal ambiguity. To this end, we construct AmbiCoref, a diagnostic corpus of minimal sentence pairs with ambiguous and unambiguous referents. Our examples generalize psycholinguistic studies of human perception of ambiguity around particular arrangements of verbs and their arguments. Analysis shows that (1) humans are less sure of referents in ambiguous AmbiCoref examples than unambiguous ones, and (2) most coreference models show little difference in output between ambiguous and unambiguous pairs. We release AmbiCoref as a diagnostic corpus for testing whether models treat ambiguity similarly to humans.
Cascading Biases: Investigating the Effect of Heuristic Annotation Strategies on Data and Models
Oct 24, 2022



Cognitive psychologists have documented that humans use cognitive heuristics, or mental shortcuts, to make quick decisions while expending less effort. While performing annotation work on crowdsourcing platforms, we hypothesize that such heuristic use among annotators cascades on to data quality and model robustness. In this work, we study cognitive heuristic use in the context of annotating multiple-choice reading comprehension datasets. We propose tracking annotator heuristic traces, where we tangibly measure low-effort annotation strategies that could indicate usage of various cognitive heuristics. We find evidence that annotators might be using multiple such heuristics, based on correlations with a battery of psychological tests. Importantly, heuristic use among annotators determines data quality along several dimensions: (1) known biased models, such as partial input models, more easily solve examples authored by annotators that rate highly on heuristic use, (2) models trained on annotators scoring highly on heuristic use don't generalize as well, and (3) heuristic-seeking annotators tend to create qualitatively less challenging examples. Our findings suggest that tracking heuristic usage among annotators can potentially help with collecting challenging datasets and diagnosing model biases.
G-DAUG: Generative Data Augmentation for Commonsense Reasoning
Apr 24, 2020
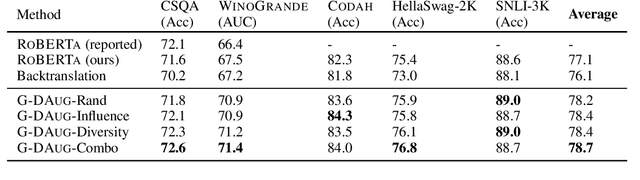
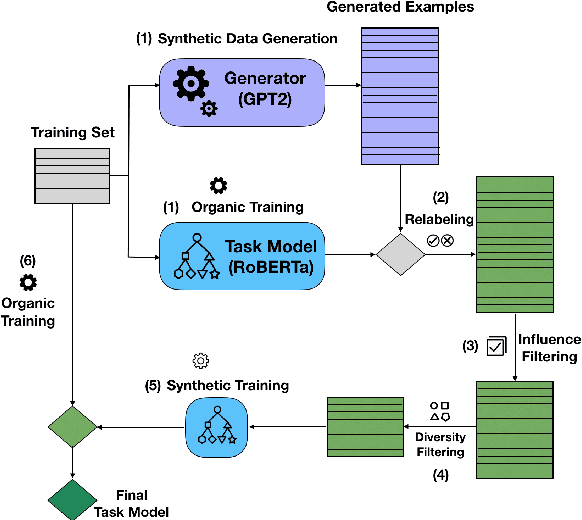
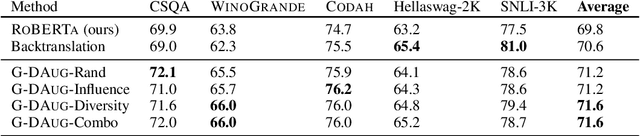
Recent advances in commonsense reasoning depend on large-scale human-annotated training data to achieve peak performance. However, manual curation of training examples is expensive and has been shown to introduce annotation artifacts that neural models can readily exploit and overfit on. We investigate G-DAUG, a novel generative data augmentation method that aims to achieve more accurate and robust learning in the low-resource setting. Our approach generates synthetic examples using pretrained language models, and selects the most informative and diverse set of examples for data augmentation. In experiments with multiple commonsense reasoning benchmarks, G-DAUG consistently outperforms existing data augmentation methods based on back-translation, and establishes a new state-of-the-art on WinoGrande, CODAH, and CommonsenseQA. Further, in addition to improvements in in-distribution accuracy, G-DAUG-augmented training also enhances out-of-distribution generalization, showing greater robustness against adversarial or perturbed examples. Our analysis demonstrates that G-DAUG produces a diverse set of fluent training examples, and that its selection and training approaches are important for performance. Our findings encourage future research toward generative data augmentation to enhance both in-distribution learning and out-of-distribution generalization.
The SIGMORPHON 2019 Shared Task: Morphological Analysis in Context and Cross-Lingual Transfer for Inflection
Oct 25, 2019
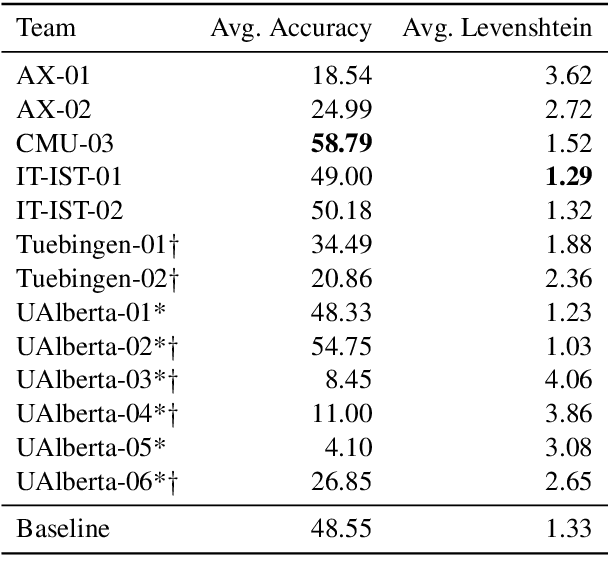
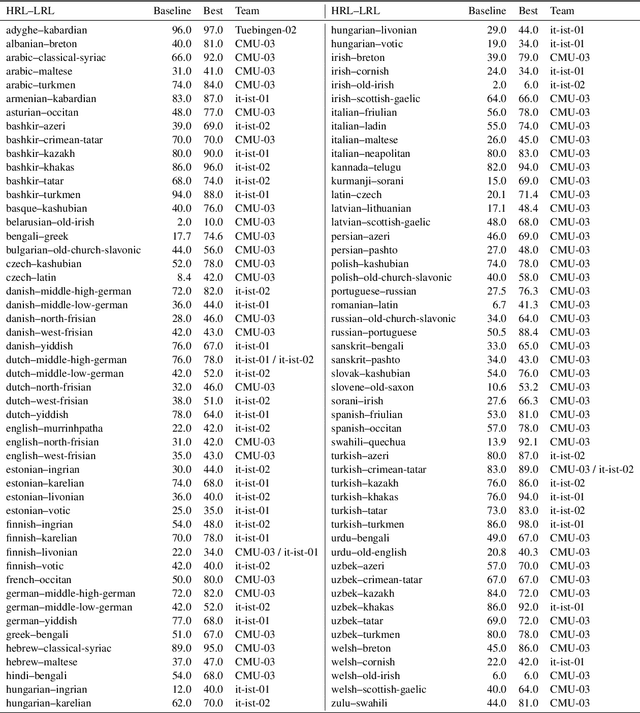
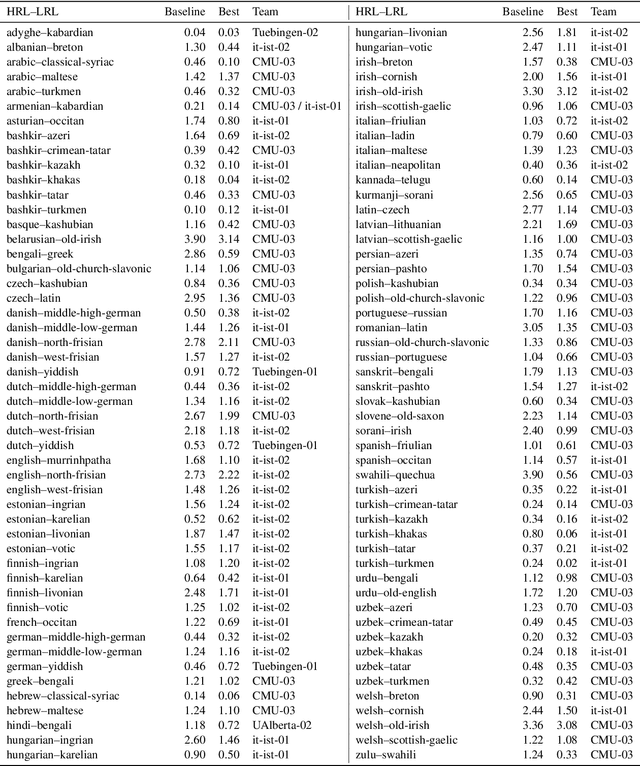
The SIGMORPHON 2019 shared task on cross-lingual transfer and contextual analysis in morphology examined transfer learning of inflection between 100 language pairs, as well as contextual lemmatization and morphosyntactic description in 66 languages. The first task evolves past years' inflection tasks by examining transfer of morphological inflection knowledge from a high-resource language to a low-resource language. This year also presents a new second challenge on lemmatization and morphological feature analysis in context. All submissions featured a neural component and built on either this year's strong baselines or highly ranked systems from previous years' shared tasks. Every participating team improved in accuracy over the baselines for the inflection task (though not Levenshtein distance), and every team in the contextual analysis task improved on both state-of-the-art neural and non-neural baselines.
* Presented at SIGMORPHON 2019
Exploiting Structural and Semantic Context for Commonsense Knowledge Base Completion
Oct 07, 2019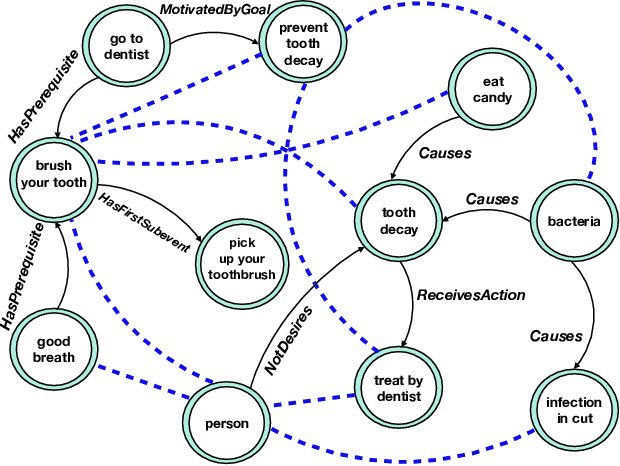

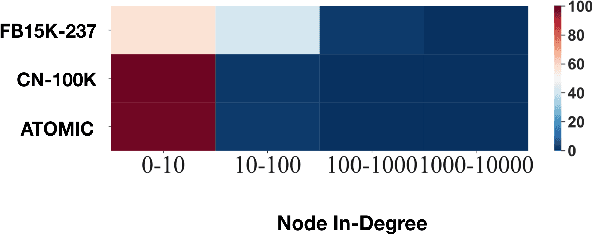
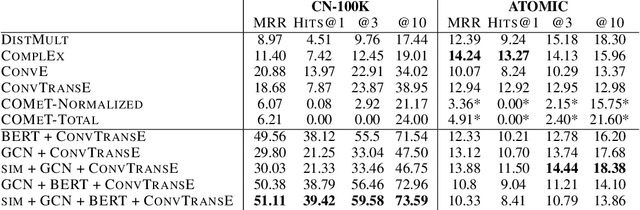
Automatic KB completion for commonsense knowledge graphs (e.g., ATOMIC and ConceptNet) poses unique challenges compared to the much studied conventional knowledge bases (e.g., Freebase). Commonsense knowledge graphs use free-form text to represent nodes, resulting in orders of magnitude more nodes compared to conventional KBs (18x more nodes in ATOMIC compared to Freebase (FB15K-237)). Importantly, this implies significantly sparser graph structures - a major challenge for existing KB completion methods that assume densely connected graphs over a relatively smaller set of nodes. In this paper, we present novel KB completion models that can address these challenges by exploiting the structural and semantic context of nodes. Specifically, we investigate two key ideas: (1) learning from local graph structure, using graph convolutional networks and automatic graph densification and (2) transfer learning from pre-trained language models to knowledge graphs for enhanced contextual representation of knowledge. We describe our method to incorporate information from both these sources in a joint model and provide the first empirical results for KB completion on ATOMIC and evaluation with ranking metrics on ConceptNet. Our results demonstrate the effectiveness of language model representations in boosting link prediction performance and the advantages of learning from local graph structure (+1.5 points in MRR for ConceptNet) when training on subgraphs for computational efficiency. Further analysis on model predictions shines light on the types of commonsense knowledge that language models capture well.
Abductive Commonsense Reasoning
Aug 15, 2019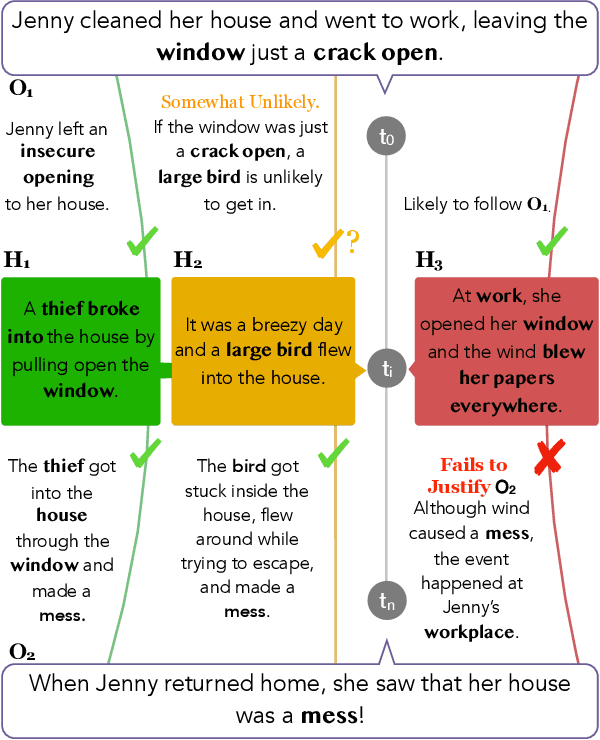
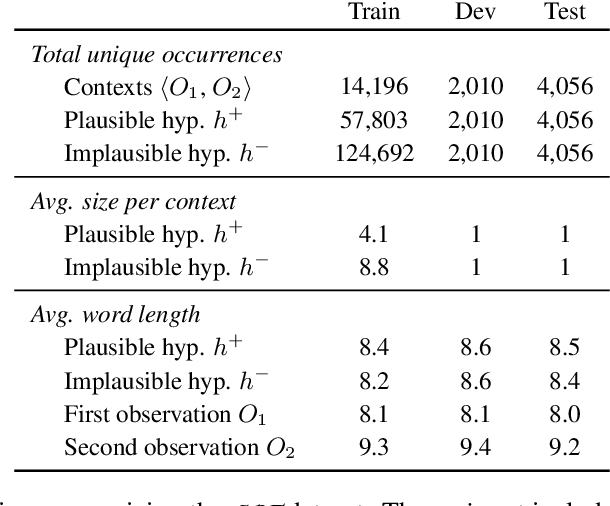
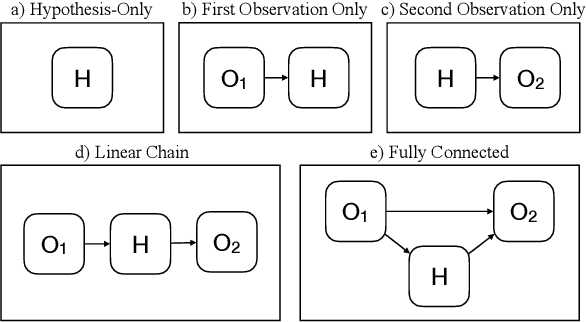
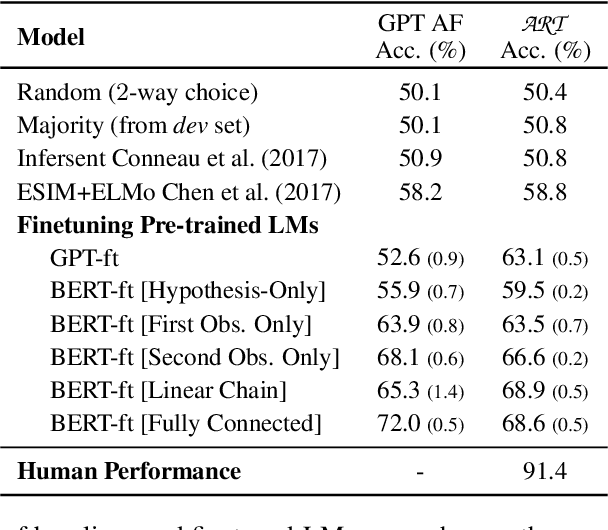
Abductive reasoning is inference to the most plausible explanation. For example, if Jenny finds her house in a mess when she returns from work, and remembers that she left a window open, she can hypothesize that a thief broke into her house and caused the mess, as the most plausible explanation. While abduction has long been considered to be at the core of how people interpret and read between the lines in natural language (Hobbs et al. (1988)), there has been relatively little NLP research in support of abductive natural language inference. We present the first study that investigates the viability of language-based abductive reasoning. We conceptualize a new task of Abductive NLI and introduce a challenge dataset, ART, that consists of over 20k commonsense narrative contexts and 200k explanations, formulated as multiple choice questions for easy automatic evaluation. We establish comprehensive baseline performance on this task based on state-of-the-art NLI and language models, which leads to 68.9% accuracy, well below human performance (91.4%). Our analysis leads to new insights into the types of reasoning that deep pre-trained language models fail to perform -- despite their strong performance on the related but fundamentally different task of entailment NLI -- pointing to interesting avenues for future research.
COMET: Commonsense Transformers for Automatic Knowledge Graph Construction
Jun 14, 2019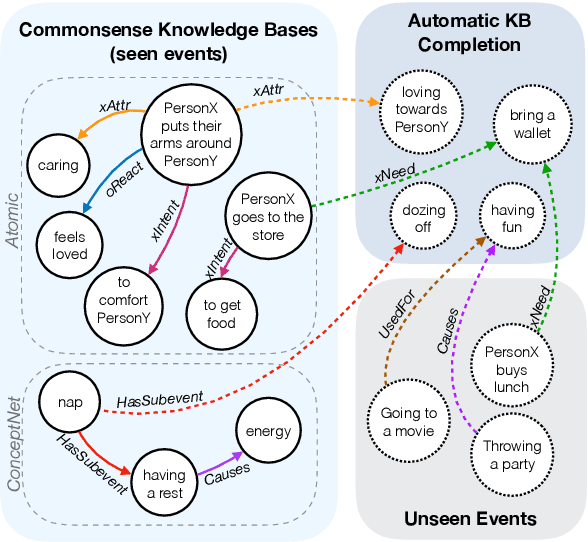
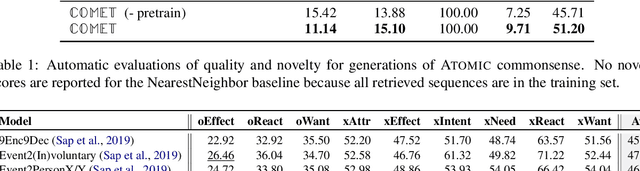
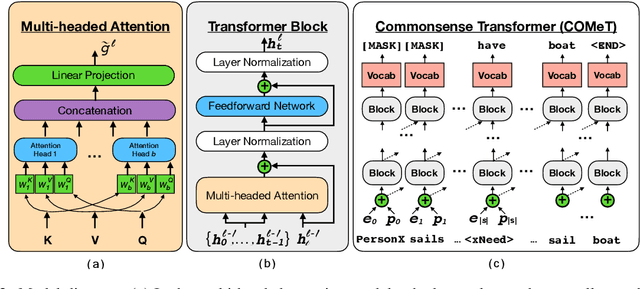
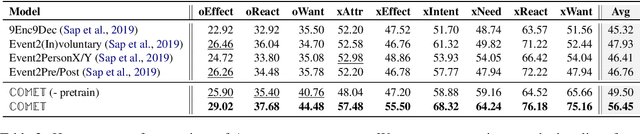
We present the first comprehensive study on automatic knowledge base construction for two prevalent commonsense knowledge graphs: ATOMIC (Sap et al., 2019) and ConceptNet (Speer et al., 2017). Contrary to many conventional KBs that store knowledge with canonical templates, commonsense KBs only store loosely structured open-text descriptions of knowledge. We posit that an important step toward automatic commonsense completion is the development of generative models of commonsense knowledge, and propose COMmonsEnse Transformers (COMET) that learn to generate rich and diverse commonsense descriptions in natural language. Despite the challenges of commonsense modeling, our investigation reveals promising results when implicit knowledge from deep pre-trained language models is transferred to generate explicit knowledge in commonsense knowledge graphs. Empirical results demonstrate that COMET is able to generate novel knowledge that humans rate as high quality, with up to 77.5% (ATOMIC) and 91.7% (ConceptNet) precision at top 1, which approaches human performance for these resources. Our findings suggest that using generative commonsense models for automatic commonsense KB completion could soon be a plausible alternative to extractive methods.
A Simple Joint Model for Improved Contextual Neural Lemmatization
Apr 05, 2019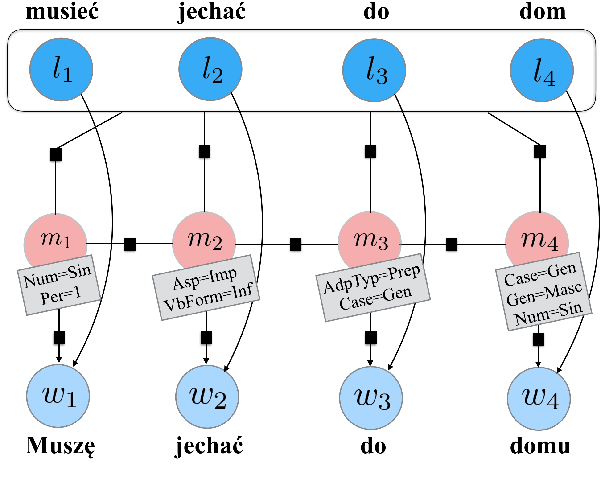
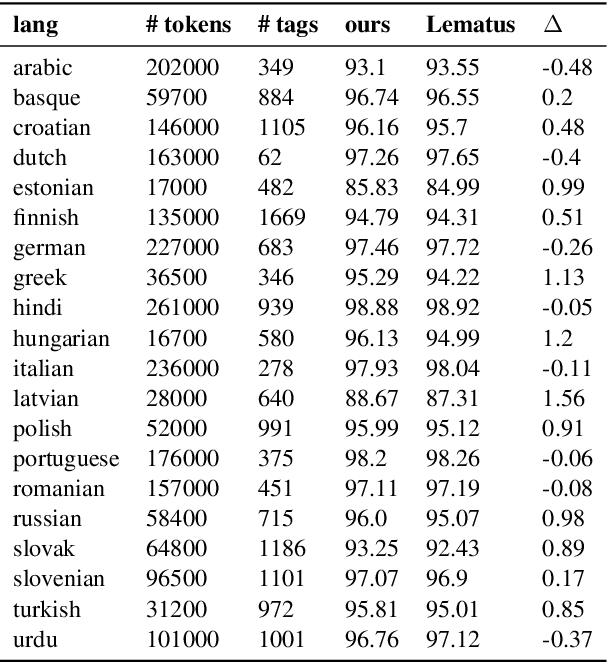


English verbs have multiple forms. For instance, talk may also appear as talks, talked or talking, depending on the context. The NLP task of lemmatization seeks to map these diverse forms back to a canonical one, known as the lemma. We present a simple joint neural model for lemmatization and morphological tagging that achieves state-of-the-art results on 20 languages from the Universal Dependencies corpora. Our paper describes the model in addition to training and decoding procedures. Error analysis indicates that joint morphological tagging and lemmatization is especially helpful in low-resource lemmatization and languages that display a larger degree of morphological complexity. Code and pre-trained models are available at https://sigmorphon.github.io/sharedtasks/2019/task2/.
Neural Factor Graph Models for Cross-lingual Morphological Tagging
Jul 11, 2018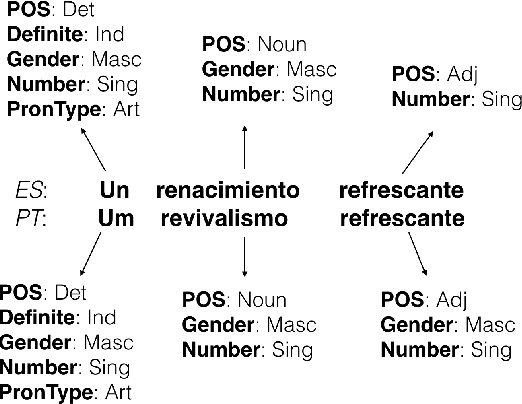
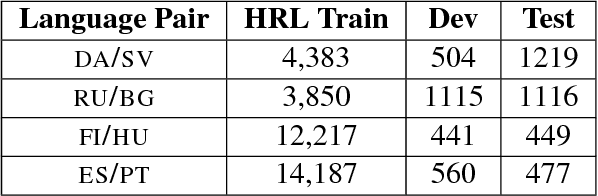
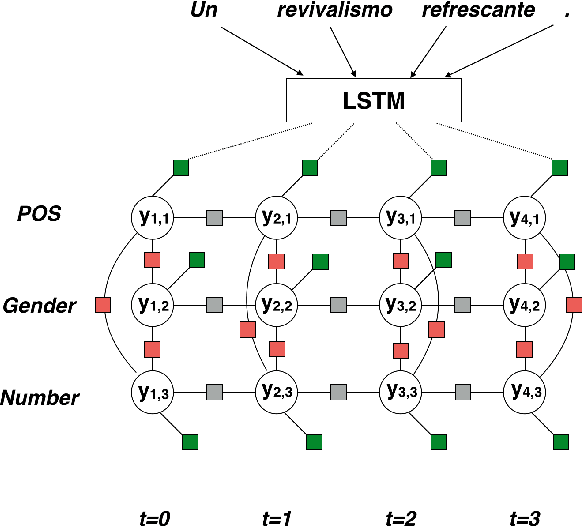
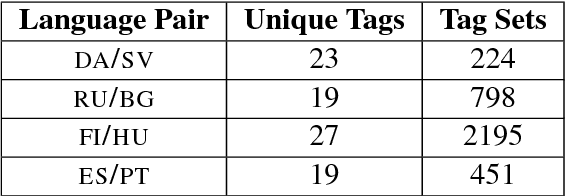
Morphological analysis involves predicting the syntactic traits of a word (e.g. {POS: Noun, Case: Acc, Gender: Fem}). Previous work in morphological tagging improves performance for low-resource languages (LRLs) through cross-lingual training with a high-resource language (HRL) from the same family, but is limited by the strict, often false, assumption that tag sets exactly overlap between the HRL and LRL. In this paper we propose a method for cross-lingual morphological tagging that aims to improve information sharing between languages by relaxing this assumption. The proposed model uses factorial conditional random fields with neural network potentials, making it possible to (1) utilize the expressive power of neural network representations to smooth over superficial differences in the surface forms, (2) model pairwise and transitive relationships between tags, and (3) accurately generate tag sets that are unseen or rare in the training data. Experiments on four languages from the Universal Dependencies Treebank demonstrate superior tagging accuracies over existing cross-lingual approaches.