 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Analysis-by-Synthesis for 6D Pose Estimation in RGB-D Images
Aug 19, 2015
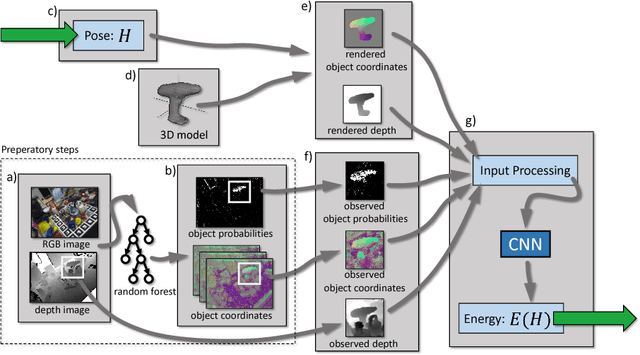

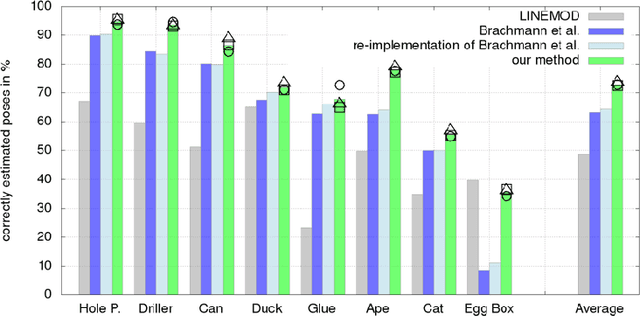
Analysis-by-synthesis has been a successful approach for many tasks in computer vision, such as 6D pose estimation of an object in an RGB-D image which is the topic of this work. The idea is to compare the observation with the output of a forward process, such as a rendered image of the object of interest in a particular pose. Due to occlusion or complicated sensor noise, it can be difficult to perform this comparison in a meaningful way. We propose an approach that "learns to compare", while taking these difficulties into account. This is done by describing the posterior density of a particular object pose with a convolutional neural network (CNN) that compares an observed and rendered image. The network is trained with the maximum likelihood paradigm. We observe empirically that the CNN does not specialize to the geometry or appearance of specific objects, and it can be used with objects of vastly different shapes and appearances, and in different backgrounds. Compared to state-of-the-art, we demonstrate a significant improvement on two different datasets which include a total of eleven objects, cluttered background, and heavy occlusion.
Cascades of Regression Tree Fields for Image Restoration
Nov 21, 2014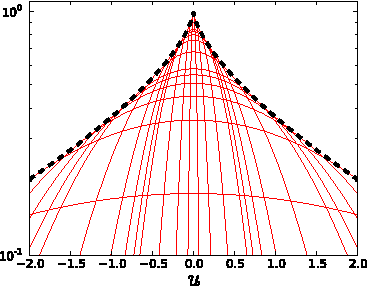
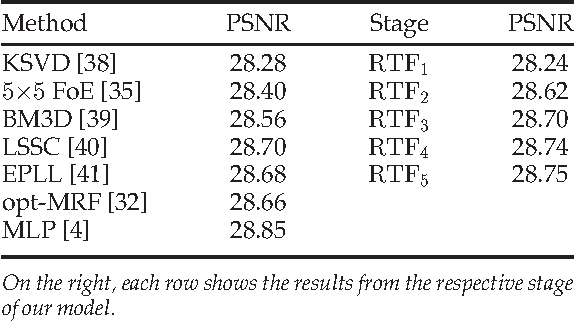
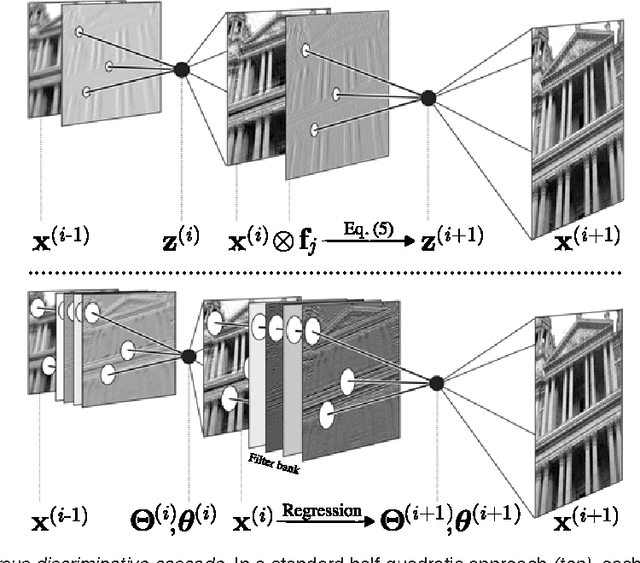
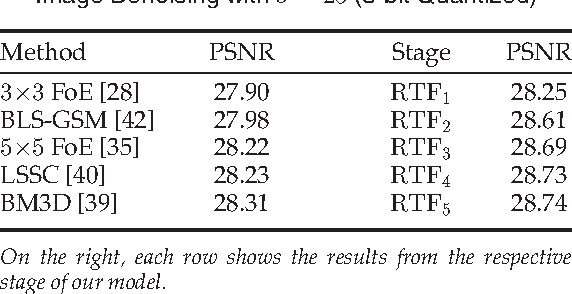
Conditional random fields (CRFs) are popular discriminative models for computer vision and have been successfully applied in the domain of image restoration, especially to image denoising. For image deblurring, however, discriminative approaches have been mostly lacking. We posit two reasons for this: First, the blur kernel is often only known at test time, requiring any discriminative approach to cope with considerable variability. Second, given this variability it is quite difficult to construct suitable features for discriminative prediction. To address these challenges we first show a connection between common half-quadratic inference for generative image priors and Gaussian CRFs. Based on this analysis, we then propose a cascade model for image restoration that consists of a Gaussian CRF at each stage. Each stage of our cascade is semi-parametric, i.e. it depends on the instance-specific parameters of the restoration problem, such as the blur kernel. We train our model by loss minimization with synthetically generated training data. Our experiments show that when applied to non-blind image deblurring, the proposed approach is efficient and yields state-of-the-art restoration quality on images corrupted with synthetic and real blur. Moreover, we demonstrate its suitability for image denoising, where we achieve competitive results for grayscale and color images.
A Comparative Study of Modern Inference Techniques for Structured Discrete Energy Minimization Problems
Apr 02, 2014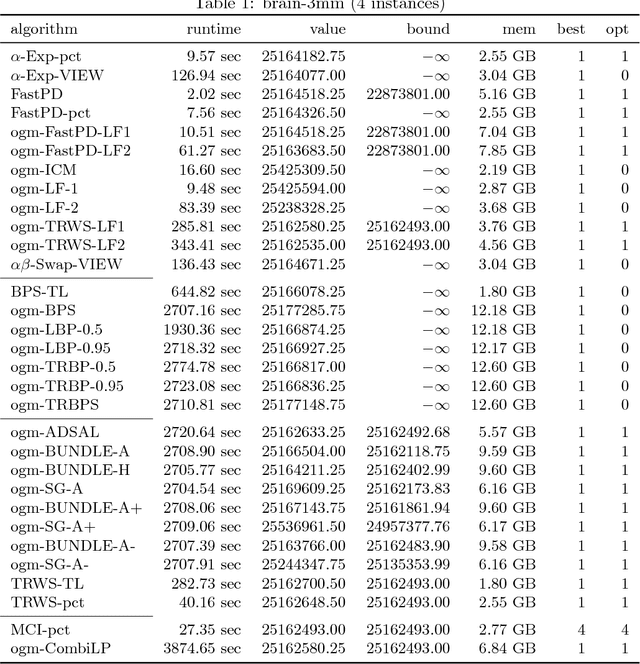
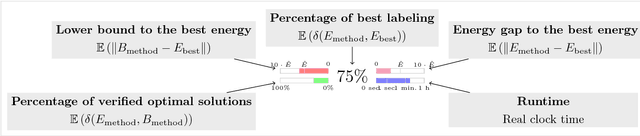
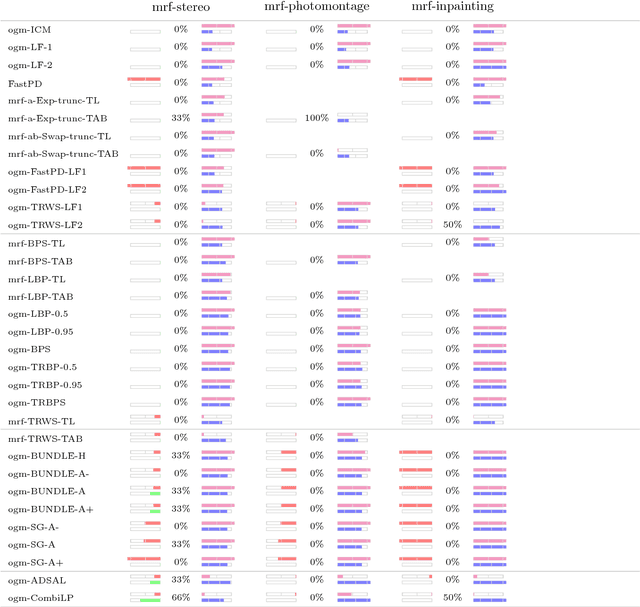
Szeliski et al. published an influential study in 2006 on energy minimization methods for Markov Random Fields (MRF). This study provided valuable insights in choosing the best optimization technique for certain classes of problems. While these insights remain generally useful today, the phenomenal success of random field models means that the kinds of inference problems that have to be solved changed significantly. Specifically, the models today often include higher order interactions, flexible connectivity structures, large la\-bel-spaces of different cardinalities, or learned energy tables. To reflect these changes, we provide a modernized and enlarged study. We present an empirical comparison of 32 state-of-the-art optimization techniques on a corpus of 2,453 energy minimization instances from diverse applications in computer vision. To ensure reproducibility, we evaluate all methods in the OpenGM 2 framework and report extensive results regarding runtime and solution quality. Key insights from our study agree with the results of Szeliski et al. for the types of models they studied. However, on new and challenging types of models our findings disagree and suggest that polyhedral methods and integer programming solvers are competitive in terms of runtime and solution quality over a large range of model types.
Curvature Prior for MRF-based Segmentation and Shape Inpainting
Sep 07, 2011
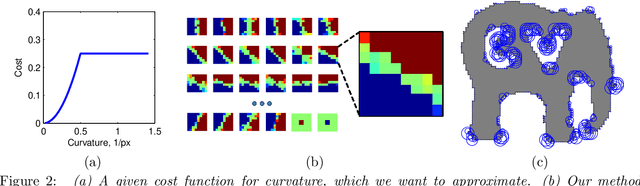
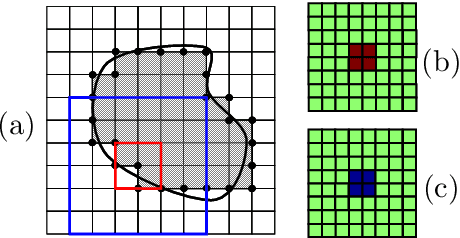
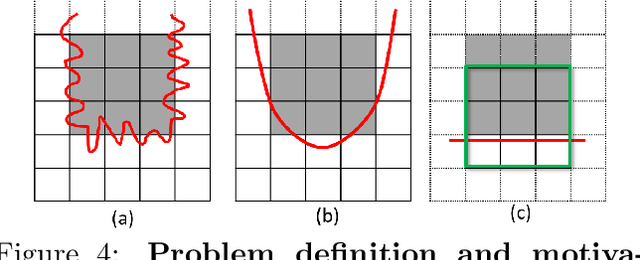
Most image labeling problems such as segmentation and image reconstruction are fundamentally ill-posed and suffer from ambiguities and noise. Higher order image priors encode high level structural dependencies between pixels and are key to overcoming these problems. However, these priors in general lead to computationally intractable models. This paper addresses the problem of discovering compact representations of higher order priors which allow efficient inference. We propose a framework for solving this problem which uses a recently proposed representation of higher order functions where they are encoded as lower envelopes of linear functions. Maximum a Posterior inference on our learned models reduces to minimizing a pairwise function of discrete variables, which can be done approximately using standard methods. Although this is a primarily theoretical paper, we also demonstrate the practical effectiveness of our framework on the problem of learning a shape prior for image segmentation and reconstruction. We show that our framework can learn a compact representation that approximates a prior that encourages low curvature shapes. We evaluate the approximation accuracy, discuss properties of the trained model, and show various results for shape inpainting and image segmentation.
Learning an Interactive Segmentation System
Dec 13, 2009



Many successful applications of computer vision to image or video manipulation are interactive by nature. However, parameters of such systems are often trained neglecting the user. Traditionally, interactive systems have been treated in the same manner as their fully automatic counterparts. Their performance is evaluated by computing the accuracy of their solutions under some fixed set of user interactions. This paper proposes a new evaluation and learning method which brings the user in the loop. It is based on the use of an active robot user - a simulated model of a human user. We show how this approach can be used to evaluate and learn parameters of state-of-the-art interactive segmentation systems. We also show how simulated user models can be integrated into the popular max-margin method for parameter learning and propose an algorithm to solve the resulting optimisation problem.