 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational Tradeoffs in Biological Neural Networks: Self-Stabilizing Winner-Take-All Networks
Oct 06, 2016
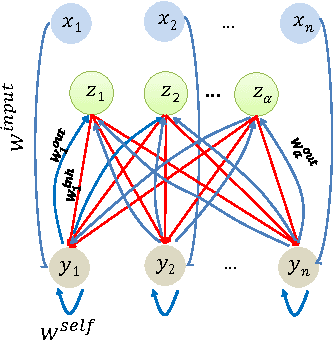
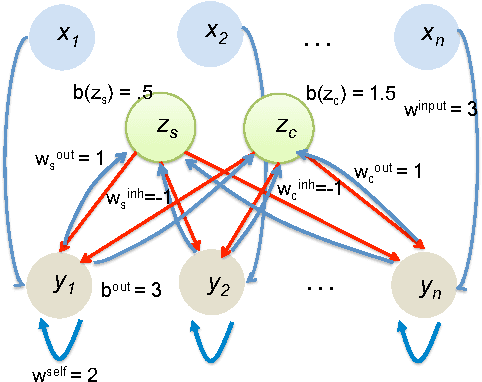
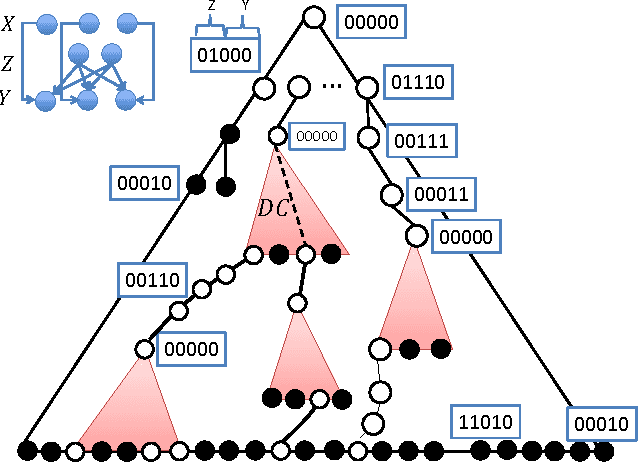
We initiate a line of investigation into biological neural networks from an algorithmic perspective. We develop a simplified but biologically plausible model for distributed computation in stochastic spiking neural networks and study tradeoffs between computation time and network complexity in this model. Our aim is to abstract real neural networks in a way that, while not capturing all interesting features, preserves high-level behavior and allows us to make biologically relevant conclusions. In this paper, we focus on the important `winner-take-all' (WTA) problem, which is analogous to a neural leader election unit: a network consisting of $n$ input neurons and $n$ corresponding output neurons must converge to a state in which a single output corresponding to a firing input (the `winner') fires, while all other outputs remain silent. Neural circuits for WTA rely on inhibitory neurons, which suppress the activity of competing outputs and drive the network towards a converged state with a single firing winner. We attempt to understand how the number of inhibitors used affects network convergence time. We show that it is possible to significantly outperform naive WTA constructions through a more refined use of inhibition, solving the problem in $O(\theta)$ rounds in expectation with just $O(\log^{1/\theta} n)$ inhibitors for any $\theta$. An alternative construction gives convergence in $O(\log^{1/\theta} n)$ rounds with $O(\theta)$ inhibitors. We compliment these upper bounds with our main technical contribution, a nearly matching lower bound for networks using $\ge \log\log n$ inhibitors. Our lower bound uses familiar indistinguishability and locality arguments from distributed computing theory. It lets us derive a number of interesting conclusions about the structure of any network solving WTA with good probability, and the use of randomness and inhibition within such a network.
Robust Shift-and-Invert Preconditioning: Faster and More Sample Efficient Algorithms for Eigenvector Computation
May 30, 2016

We provide faster algorithms and improved sample complexities for approximating the top eigenvector of a matrix. Offline Setting: Given an $n \times d$ matrix $A$, we show how to compute an $\epsilon$ approximate top eigenvector in time $\tilde O ( [nnz(A) + \frac{d \cdot sr(A)}{gap^2}]\cdot \log 1/\epsilon )$ and $\tilde O([\frac{nnz(A)^{3/4} (d \cdot sr(A))^{1/4}}{\sqrt{gap}}]\cdot \log1/\epsilon )$. Here $sr(A)$ is the stable rank and $gap$ is the multiplicative eigenvalue gap. By separating the $gap$ dependence from $nnz(A)$ we improve on the classic power and Lanczos methods. We also improve prior work using fast subspace embeddings and stochastic optimization, giving significantly improved dependencies on $sr(A)$ and $\epsilon$. Our second running time improves this further when $nnz(A) \le \frac{d\cdot sr(A)}{gap^2}$. Online Setting: Given a distribution $D$ with covariance matrix $\Sigma$ and a vector $x_0$ which is an $O(gap)$ approximate top eigenvector for $\Sigma$, we show how to refine to an $\epsilon$ approximation using $\tilde O(\frac{v(D)}{gap^2} + \frac{v(D)}{gap \cdot \epsilon})$ samples from $D$. Here $v(D)$ is a natural variance measure. Combining our algorithm with previous work to initialize $x_0$, we obtain a number of improved sample complexity and runtime results. For general distributions, we achieve asymptotically optimal accuracy as a function of sample size as the number of samples grows large. Our results center around a robust analysis of the classic method of shift-and-invert preconditioning to reduce eigenvector computation to approximately solving a sequence of linear systems. We then apply fast SVRG based approximate system solvers to achieve our claims. We believe our results suggest the general effectiveness of shift-and-invert based approaches and imply that further computational gains may be reaped in practice.
Faster Eigenvector Computation via Shift-and-Invert Preconditioning
May 26, 2016

We give faster algorithms and improved sample complexities for estimating the top eigenvector of a matrix $\Sigma$ -- i.e. computing a unit vector $x$ such that $x^T \Sigma x \ge (1-\epsilon)\lambda_1(\Sigma)$: Offline Eigenvector Estimation: Given an explicit $A \in \mathbb{R}^{n \times d}$ with $\Sigma = A^TA$, we show how to compute an $\epsilon$ approximate top eigenvector in time $\tilde O([nnz(A) + \frac{d*sr(A)}{gap^2} ]* \log 1/\epsilon )$ and $\tilde O([\frac{nnz(A)^{3/4} (d*sr(A))^{1/4}}{\sqrt{gap}} ] * \log 1/\epsilon )$. Here $nnz(A)$ is the number of nonzeros in $A$, $sr(A)$ is the stable rank, $gap$ is the relative eigengap. By separating the $gap$ dependence from the $nnz(A)$ term, our first runtime improves upon the classical power and Lanczos methods. It also improves prior work using fast subspace embeddings [AC09, CW13] and stochastic optimization [Sha15c], giving significantly better dependencies on $sr(A)$ and $\epsilon$. Our second running time improves these further when $nnz(A) \le \frac{d*sr(A)}{gap^2}$. Online Eigenvector Estimation: Given a distribution $D$ with covariance matrix $\Sigma$ and a vector $x_0$ which is an $O(gap)$ approximate top eigenvector for $\Sigma$, we show how to refine to an $\epsilon$ approximation using $ O(\frac{var(D)}{gap*\epsilon})$ samples from $D$. Here $var(D)$ is a natural notion of variance. Combining our algorithm with previous work to initialize $x_0$, we obtain improved sample complexity and runtime results under a variety of assumptions on $D$. We achieve our results using a general framework that we believe is of independent interest. We give a robust analysis of the classic method of shift-and-invert preconditioning to reduce eigenvector computation to approximately solving a sequence of linear systems. We then apply fast stochastic variance reduced gradient (SVRG) based system solvers to achieve our claims.
Principal Component Projection Without Principal Component Analysis
Feb 22, 2016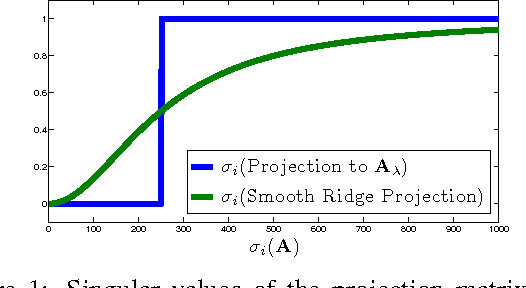
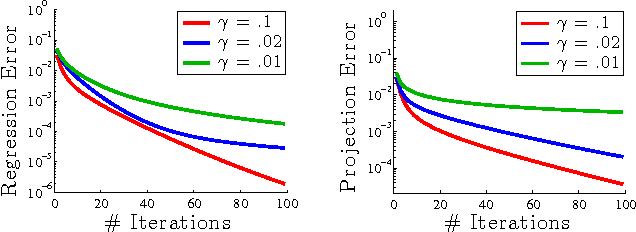
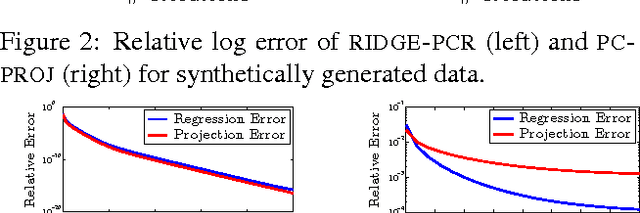
We show how to efficiently project a vector onto the top principal components of a matrix, without explicitly computing these components. Specifically, we introduce an iterative algorithm that provably computes the projection using few calls to any black-box routine for ridge regression. By avoiding explicit principal component analysis (PCA), our algorithm is the first with no runtime dependence on the number of top principal components. We show that it can be used to give a fast iterative method for the popular principal component regression problem, giving the first major runtime improvement over the naive method of combining PCA with regression. To achieve our results, we first observe that ridge regression can be used to obtain a "smooth projection" onto the top principal components. We then sharpen this approximation to true projection using a low-degree polynomial approximation to the matrix step function. Step function approximation is a topic of long-term interest in scientific computing. We extend prior theory by constructing polynomials with simple iterative structure and rigorously analyzing their behavior under limited precision.
Randomized Block Krylov Methods for Stronger and Faster Approximate Singular Value Decomposition
Oct 30, 2015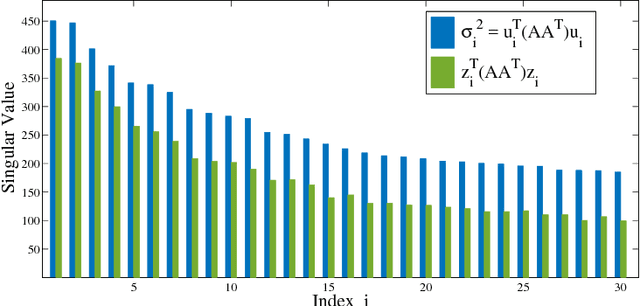
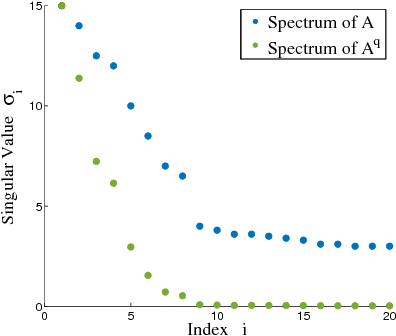
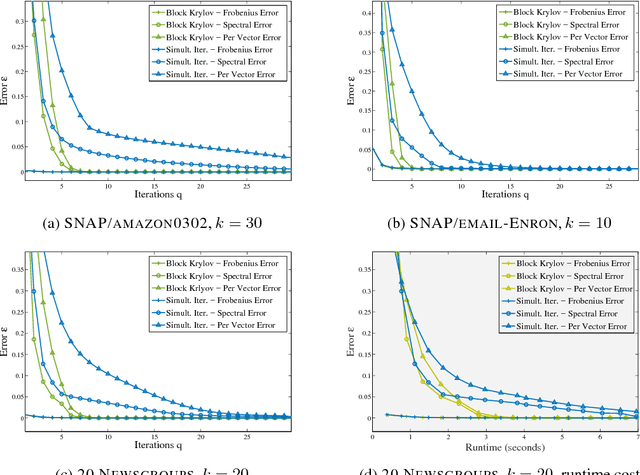
Since being analyzed by Rokhlin, Szlam, and Tygert and popularized by Halko, Martinsson, and Tropp, randomized Simultaneous Power Iteration has become the method of choice for approximate singular value decomposition. It is more accurate than simpler sketching algorithms, yet still converges quickly for any matrix, independently of singular value gaps. After $\tilde{O}(1/\epsilon)$ iterations, it gives a low-rank approximation within $(1+\epsilon)$ of optimal for spectral norm error. We give the first provable runtime improvement on Simultaneous Iteration: a simple randomized block Krylov method, closely related to the classic Block Lanczos algorithm, gives the same guarantees in just $\tilde{O}(1/\sqrt{\epsilon})$ iterations and performs substantially better experimentally. Despite their long history, our analysis is the first of a Krylov subspace method that does not depend on singular value gaps, which are unreliable in practice. Furthermore, while it is a simple accuracy benchmark, even $(1+\epsilon)$ error for spectral norm low-rank approximation does not imply that an algorithm returns high quality principal components, a major issue for data applications. We address this problem for the first time by showing that both Block Krylov Iteration and a minor modification of Simultaneous Iteration give nearly optimal PCA for any matrix. This result further justifies their strength over non-iterative sketching methods. Finally, we give insight beyond the worst case, justifying why both algorithms can run much faster in practice than predicted. We clarify how simple techniques can take advantage of common matrix properties to significantly improve runtime.
Dimensionality Reduction for k-Means Clustering and Low Rank Approximation
Apr 03, 2015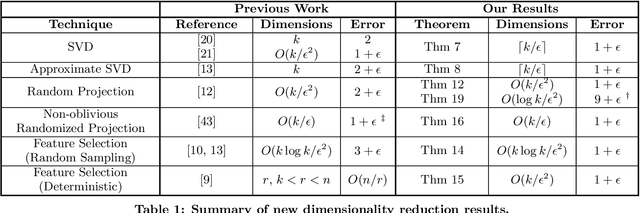
We show how to approximate a data matrix $\mathbf{A}$ with a much smaller sketch $\mathbf{\tilde A}$ that can be used to solve a general class of constrained k-rank approximation problems to within $(1+\epsilon)$ error. Importantly, this class of problems includes $k$-means clustering and unconstrained low rank approximation (i.e. principal component analysis). By reducing data points to just $O(k)$ dimensions, our methods generically accelerate any exact, approximate, or heuristic algorithm for these ubiquitous problems. For $k$-means dimensionality reduction, we provide $(1+\epsilon)$ relative error results for many common sketching techniques, including random row projection, column selection, and approximate SVD. For approximate principal component analysis, we give a simple alternative to known algorithms that has applications in the streaming setting. Additionally, we extend recent work on column-based matrix reconstruction, giving column subsets that not only `cover' a good subspace for $\bv{A}$, but can be used directly to compute this subspace. Finally, for $k$-means clustering, we show how to achieve a $(9+\epsilon)$ approximation by Johnson-Lindenstrauss projecting data points to just $O(\log k/\epsilon^2)$ dimensions. This gives the first result that leverages the specific structure of $k$-means to achieve dimension independent of input size and sublinear in $k$.
Uniform Sampling for Matrix Approximation
Aug 21, 2014Random sampling has become a critical tool in solving massive matrix problems. For linear regression, a small, manageable set of data rows can be randomly selected to approximate a tall, skinny data matrix, improving processing time significantly. For theoretical performance guarantees, each row must be sampled with probability proportional to its statistical leverage score. Unfortunately, leverage scores are difficult to compute. A simple alternative is to sample rows uniformly at random. While this often works, uniform sampling will eliminate critical row information for many natural instances. We take a fresh look at uniform sampling by examining what information it does preserve. Specifically, we show that uniform sampling yields a matrix that, in some sense, well approximates a large fraction of the original. While this weak form of approximation is not enough for solving linear regression directly, it is enough to compute a better approximation. This observation leads to simple iterative row sampling algorithms for matrix approximation that run in input-sparsity time and preserve row structure and sparsity at all intermediate steps. In addition to an improved understanding of uniform sampling, our main proof introduces a structural result of independent interest: we show that every matrix can be made to have low coherence by reweighting a small subset of its rows.