 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Lightweight Single Object Tracking with UHP-SOT++
Nov 15, 2021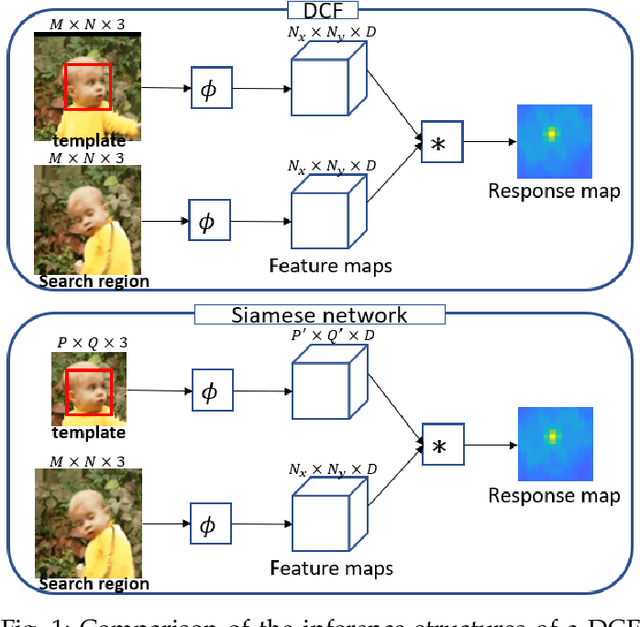


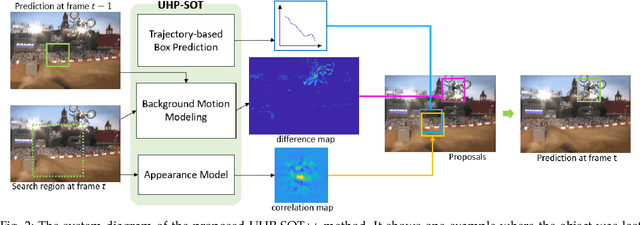
An unsupervised, lightweight and high-performance single object tracker, called UHP-SOT, was proposed by Zhou et al. recently. As an extension, we present an enhanced version and name it UHP-SOT++ in this work. Built upon the foundation of the discriminative-correlation-filters-based (DCF-based) tracker, two new ingredients are introduced in UHP-SOT and UHP-SOT++: 1) background motion modeling and 2) object box trajectory modeling. The main difference between UHP-SOT and UHP-SOT++ is the fusion strategy of proposals from three models (i.e., DCF, background motion and object box trajectory models). An improved fusion strategy is adopted by UHP-SOT++ for more robust tracking performance against large-scale tracking datasets. Our second contribution lies in an extensive evaluation of the performance of state-of-the-art supervised and unsupervised methods by testing them on four SOT benchmark datasets - OTB2015, TC128, UAV123 and LaSOT. Experiments show that UHP-SOT++ outperforms all previous unsupervised methods and several deep-learning (DL) methods in tracking accuracy. Since UHP-SOT++ has extremely small model size, high tracking performance, and low computational complexity (operating at a rate of 20 FPS on an i5 CPU even without code optimization), it is an ideal solution in real-time object tracking on resource-limited platforms. Based on the experimental results, we compare pros and cons of supervised and unsupervised trackers and provide a new perspective to understand the performance gap between supervised and unsupervised methods, which is the third contribution of this work.
A-PixelHop: A Green, Robust and Explainable Fake-Image Detector
Nov 07, 2021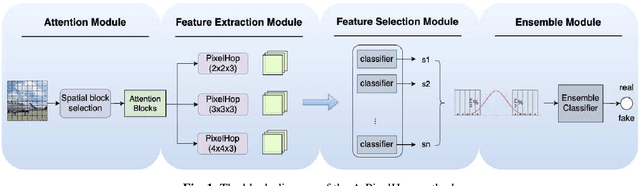


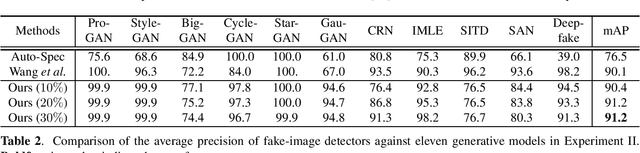
A novel method for detecting CNN-generated images, called Attentive PixelHop (or A-PixelHop), is proposed in this work. It has three advantages: 1) low computational complexity and a small model size, 2) high detection performance against a wide range of generative models, and 3) mathematical transparency. A-PixelHop is designed under the assumption that it is difficult to synthesize high-quality, high-frequency components in local regions. It contains four building modules: 1) selecting edge/texture blocks that contain significant high-frequency components, 2) applying multiple filter banks to them to obtain rich sets of spatial-spectral responses as features, 3) feeding features to multiple binary classifiers to obtain a set of soft decisions, 4) developing an effective ensemble scheme to fuse the soft decisions into the final decision. Experimental results show that A-PixelHop outperforms state-of-the-art methods in detecting CycleGAN-generated images. Furthermore, it can generalize well to unseen generative models and datasets.
PEDENet: Image Anomaly Localization via Patch Embedding and Density Estimation
Oct 29, 2021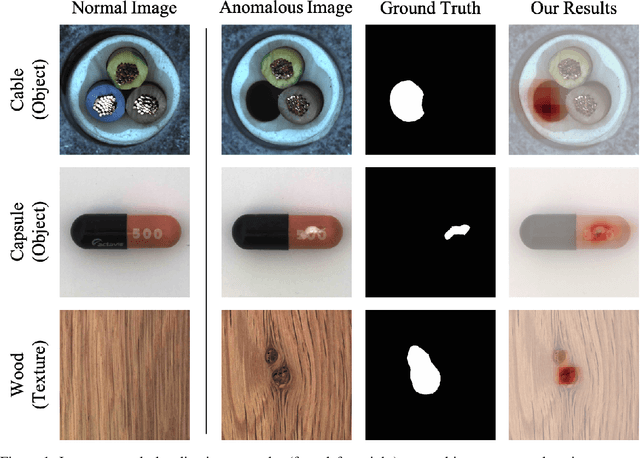
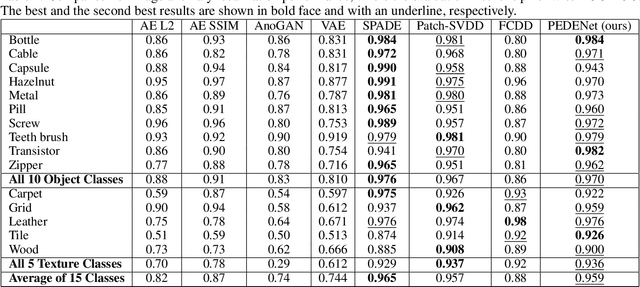
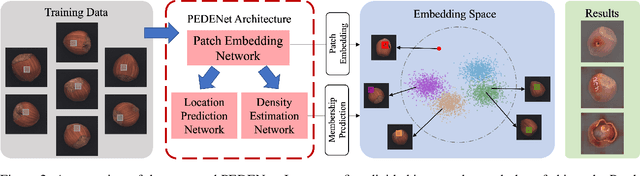
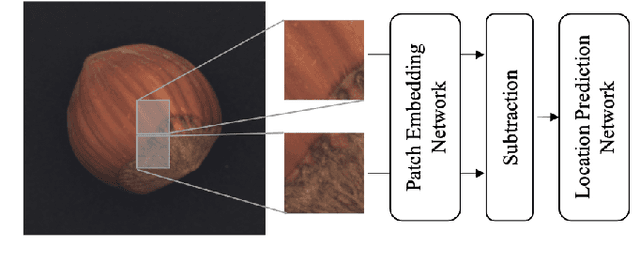
A neural network targeting at unsupervised image anomaly localization, called the PEDENet, is proposed in this work. PEDENet contains a patch embedding (PE) network, a density estimation (DE) network, and an auxiliary network called the location prediction (LP) network. The PE network takes local image patches as input and performs dimension reduction to get low-dimensional patch embeddings via a deep encoder structure. Being inspired by the Gaussian Mixture Model (GMM), the DE network takes those patch embeddings and then predicts the cluster membership of an embedded patch. The sum of membership probabilities is used as a loss term to guide the learning process. The LP network is a Multi-layer Perception (MLP), which takes embeddings from two neighboring patches as input and predicts their relative location. The performance of the proposed PEDENet is evaluated extensively and benchmarked with that of state-of-the-art methods.
Task-Specific Dependency-based Word Embedding Methods
Oct 26, 2021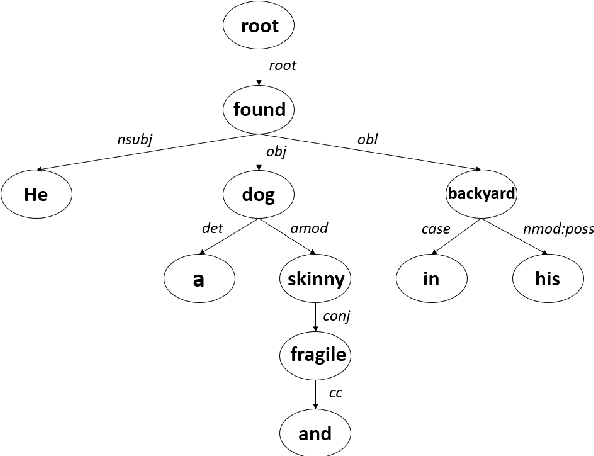
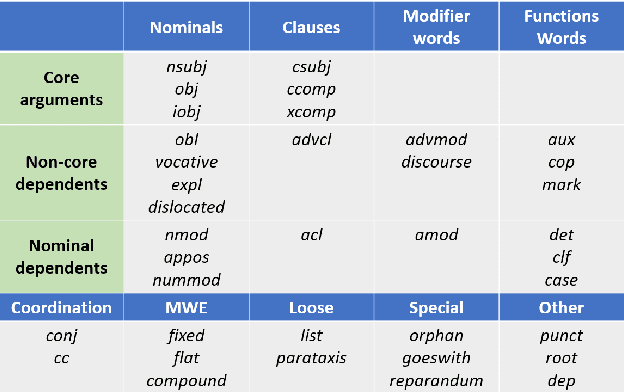
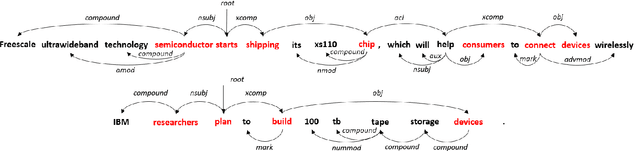
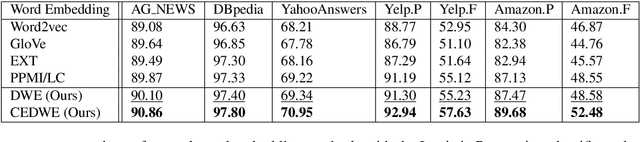
Two task-specific dependency-based word embedding methods are proposed for text classification in this work. In contrast with universal word embedding methods that work for generic tasks, we design task-specific word embedding methods to offer better performance in a specific task. Our methods follow the PPMI matrix factorization framework and derive word contexts from the dependency parse tree. The first one, called the dependency-based word embedding (DWE), chooses keywords and neighbor words of a target word in the dependency parse tree as contexts to build the word-context matrix. The second method, named class-enhanced dependency-based word embedding (CEDWE), learns from word-context as well as word-class co-occurrence statistics. DWE and CEDWE are evaluated on popular text classification datasets to demonstrate their effectiveness. It is shown by experimental results they outperform several state-of-the-art word embedding methods.
Geo-DefakeHop: High-Performance Geographic Fake Image Detection
Oct 19, 2021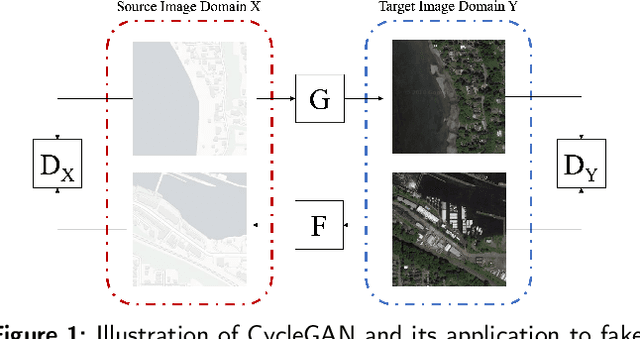
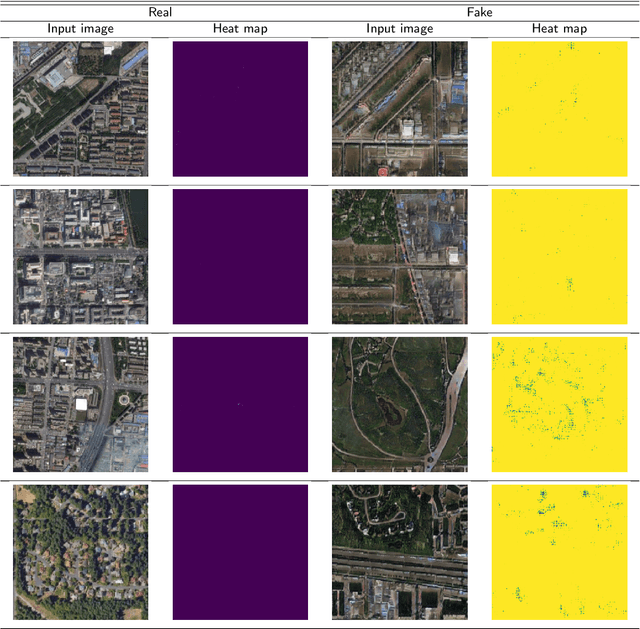
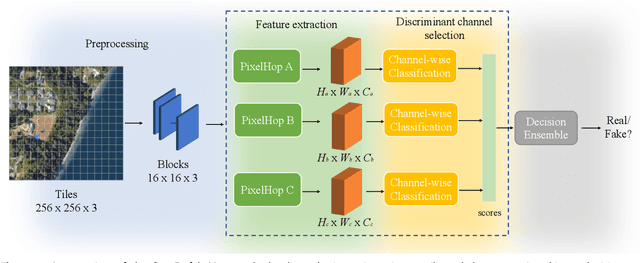

A robust fake satellite image detection method, called Geo-DefakeHop, is proposed in this work. Geo-DefakeHop is developed based on the parallel subspace learning (PSL) methodology. PSL maps the input image space into several feature subspaces using multiple filter banks. By exploring response differences of different channels between real and fake images for a filter bank, Geo-DefakeHop learns the most discriminant channels and uses their soft decision scores as features. Then, Geo-DefakeHop selects a few discriminant features from each filter bank and ensemble them to make a final binary decision. Geo-DefakeHop offers a light-weight high-performance solution to fake satellite images detection. Its model size is analyzed, which ranges from 0.8 to 62K parameters. Furthermore, it is shown by experimental results that it achieves an F1-score higher than 95\% under various common image manipulations such as resizing, compression and noise corruption.
Unsupervised Data-Driven Nuclei Segmentation For Histology Images
Oct 14, 2021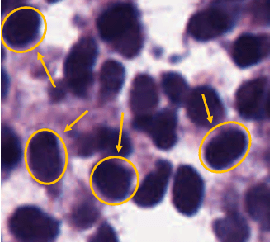
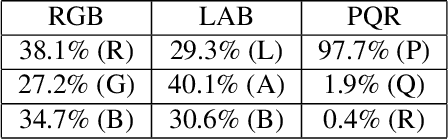

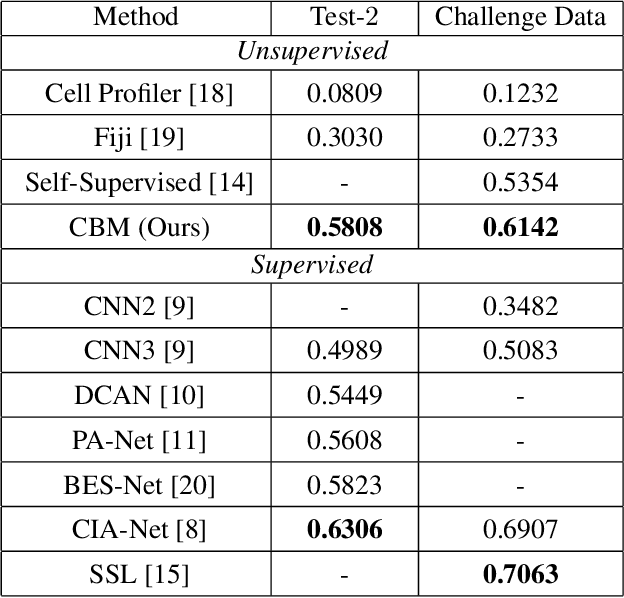
An unsupervised data-driven nuclei segmentation method for histology images, called CBM, is proposed in this work. CBM consists of three modules applied in a block-wise manner: 1) data-driven color transform for energy compaction and dimension reduction, 2) data-driven binarization, and 3) incorporation of geometric priors with morphological processing. CBM comes from the first letter of the three modules - "Color transform", "Binarization" and "Morphological processing". Experiments on the MoNuSeg dataset validate the effectiveness of the proposed CBM method. CBM outperforms all other unsupervised methods and offers a competitive standing among supervised models based on the Aggregated Jaccard Index (AJI) metric.
UHP-SOT: An Unsupervised High-Performance Single Object Tracker
Oct 05, 2021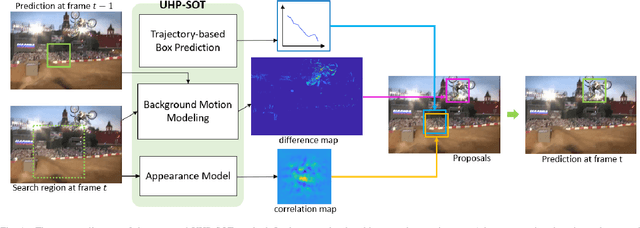

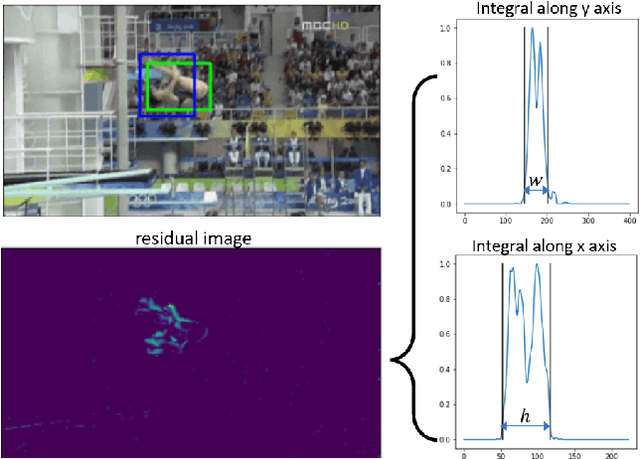
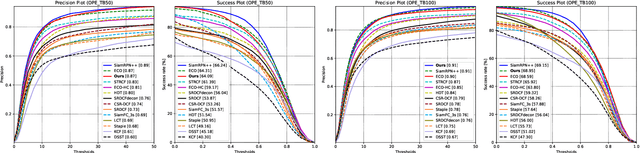
An unsupervised online object tracking method that exploits both foreground and background correlations is proposed and named UHP-SOT (Unsupervised High-Performance Single Object Tracker) in this work. UHP-SOT consists of three modules: 1) appearance model update, 2) background motion modeling, and 3) trajectory-based box prediction. A state-of-the-art discriminative correlation filters (DCF) based tracker is adopted by UHP-SOT as the first module. We point out shortcomings of using the first module alone such as failure in recovering from tracking loss and inflexibility in object box adaptation and then propose the second and third modules to overcome them. Both are novel in single object tracking (SOT). We test UHP-SOT on two popular object tracking benchmarks, TB-50 and TB-100, and show that it outperforms all previous unsupervised SOT methods, achieves a performance comparable with the best supervised deep-learning-based SOT methods, and operates at a fast speed (i.e. 22.7-32.0 FPS on a CPU).
GSIP: Green Semantic Segmentation of Large-Scale Indoor Point Clouds
Sep 24, 2021



An efficient solution to semantic segmentation of large-scale indoor scene point clouds is proposed in this work. It is named GSIP (Green Segmentation of Indoor Point clouds) and its performance is evaluated on a representative large-scale benchmark -- the Stanford 3D Indoor Segmentation (S3DIS) dataset. GSIP has two novel components: 1) a room-style data pre-processing method that selects a proper subset of points for further processing, and 2) a new feature extractor which is extended from PointHop. For the former, sampled points of each room form an input unit. For the latter, the weaknesses of PointHop's feature extraction when extending it to large-scale point clouds are identified and fixed with a simpler processing pipeline. As compared with PointNet, which is a pioneering deep-learning-based solution, GSIP is green since it has significantly lower computational complexity and a much smaller model size. Furthermore, experiments show that GSIP outperforms PointNet in segmentation performance for the S3DIS dataset.
BERTHop: An Effective Vision-and-Language Model for Chest X-ray Disease Diagnosis
Aug 10, 2021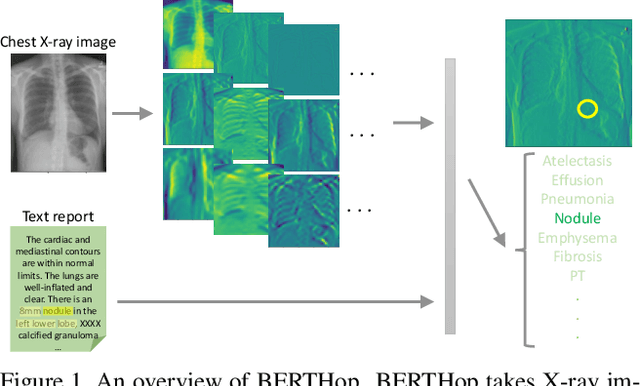
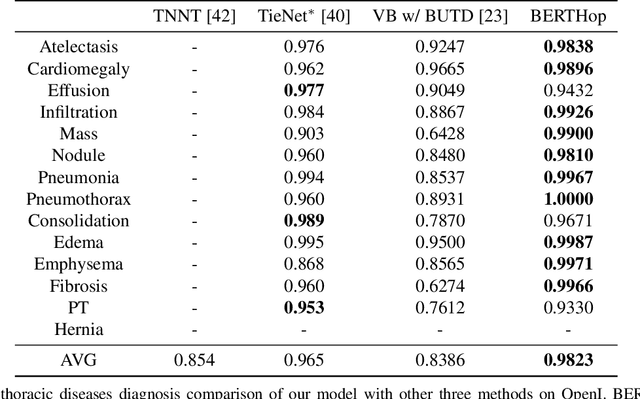
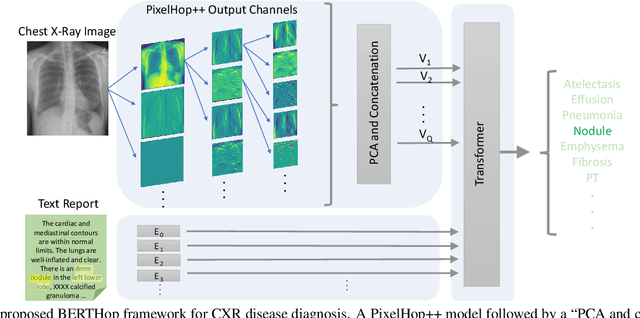
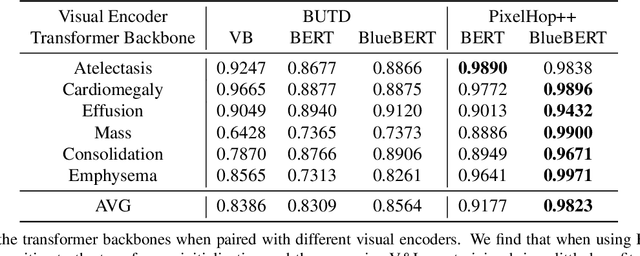
Vision-and-language(V&L) models take image and text as input and learn to capture the associations between them. Prior studies show that pre-trained V&L models can significantly improve the model performance for downstream tasks such as Visual Question Answering (VQA). However, V&L models are less effective when applied in the medical domain (e.g., on X-ray images and clinical notes) due to the domain gap. In this paper, we investigate the challenges of applying pre-trained V&L models in medical applications. In particular, we identify that the visual representation in general V&L models is not suitable for processing medical data. To overcome this limitation, we propose BERTHop, a transformer-based model based on PixelHop++ and VisualBERT, for better capturing the associations between the two modalities. Experiments on the OpenI dataset, a commonly used thoracic disease diagnosis benchmark, show that BERTHop achieves an average Area Under the Curve (AUC) of 98.12% which is 1.62% higher than state-of-the-art (SOTA) while it is trained on a 9 times smaller dataset.
Adversarial Unsupervised Domain Adaptation with Conditional and Label Shift: Infer, Align and Iterate
Aug 02, 2021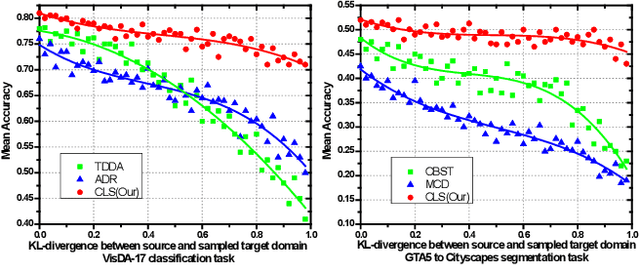
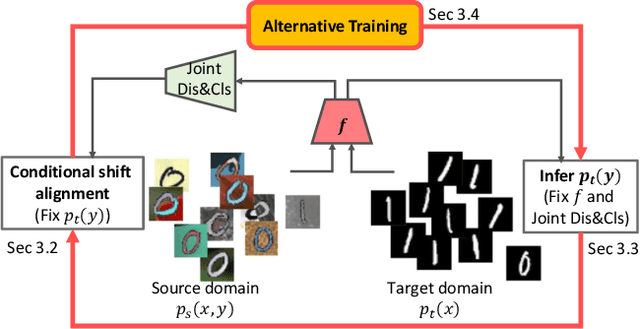
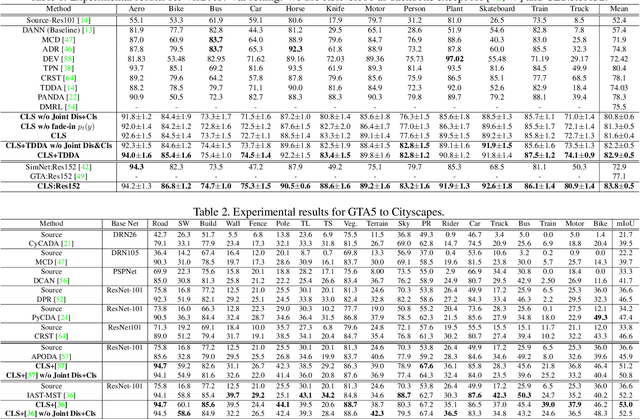
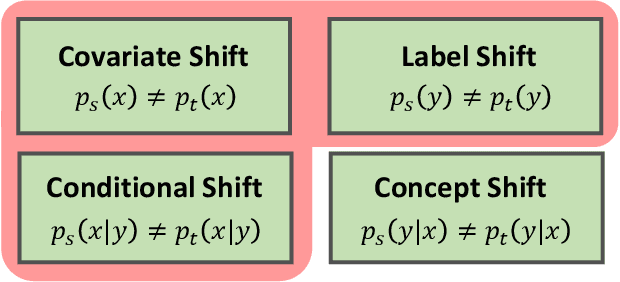
In this work, we propose an adversarial unsupervised domain adaptation (UDA) approach with the inherent conditional and label shifts, in which we aim to align the distributions w.r.t. both $p(x|y)$ and $p(y)$. Since the label is inaccessible in the target domain, the conventional adversarial UDA assumes $p(y)$ is invariant across domains, and relies on aligning $p(x)$ as an alternative to the $p(x|y)$ alignment. To address this, we provide a thorough theoretical and empirical analysis of the conventional adversarial UDA methods under both conditional and label shifts, and propose a novel and practical alternative optimization scheme for adversarial UDA. Specifically, we infer the marginal $p(y)$ and align $p(x|y)$ iteratively in the training, and precisely align the posterior $p(y|x)$ in testing. Our experimental results demonstrate its effectiveness on both classification and segmentation UDA, and partial UDA.