 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStabilizing Direct Training of Spiking Neural Networks: Membrane Potential Initialization and Threshold-robust Surrogate Gradient
Nov 11, 2025



Recent advancements in the direct training of Spiking Neural Networks (SNNs) have demonstrated high-quality outputs even at early timesteps, paving the way for novel energy-efficient AI paradigms. However, the inherent non-linearity and temporal dependencies in SNNs introduce persistent challenges, such as temporal covariate shift (TCS) and unstable gradient flow with learnable neuron thresholds. In this paper, we present two key innovations: MP-Init (Membrane Potential Initialization) and TrSG (Threshold-robust Surrogate Gradient). MP-Init addresses TCS by aligning the initial membrane potential with its stationary distribution, while TrSG stabilizes gradient flow with respect to threshold voltage during training. Extensive experiments validate our approach, achieving state-of-the-art accuracy on both static and dynamic image datasets. The code is available at: https://github.com/kookhh0827/SNN-MP-Init-TRSG
DreamFLEX: Learning Fault-Aware Quadrupedal Locomotion Controller for Anomaly Situation in Rough Terrains
Feb 09, 2025



Recent advances in quadrupedal robots have demonstrated impressive agility and the ability to traverse diverse terrains. However, hardware issues, such as motor overheating or joint locking, may occur during long-distance walking or traversing through rough terrains leading to locomotion failures. Although several studies have proposed fault-tolerant control methods for quadrupedal robots, there are still challenges in traversing unstructured terrains. In this paper, we propose DreamFLEX, a robust fault-tolerant locomotion controller that enables a quadrupedal robot to traverse complex environments even under joint failure conditions. DreamFLEX integrates an explicit failure estimation and modulation network that jointly estimates the robot's joint fault vector and utilizes this information to adapt the locomotion pattern to faulty conditions in real-time, enabling quadrupedal robots to maintain stability and performance in rough terrains. Experimental results demonstrate that DreamFLEX outperforms existing methods in both simulation and real-world scenarios, effectively managing hardware failures while maintaining robust locomotion performance.
TRG-planner: Traversal Risk Graph-Based Path Planning in Unstructured Environments for Safe and Efficient Navigation
Jan 03, 2025



Unstructured environments such as mountains, caves, construction sites, or disaster areas are challenging for autonomous navigation because of terrain irregularities. In particular, it is crucial to plan a path to avoid risky terrain and reach the goal quickly and safely. In this paper, we propose a method for safe and distance-efficient path planning, leveraging Traversal Risk Graph (TRG), a novel graph representation that takes into account geometric traversability of the terrain. TRG nodes represent stability and reachability of the terrain, while edges represent relative traversal risk-weighted path candidates. Additionally, TRG is constructed in a wavefront propagation manner and managed hierarchically, enabling real-time planning even in large-scale environments. Lastly, we formulate a graph optimization problem on TRG that leads the robot to navigate by prioritizing both safe and short paths. Our approach demonstrated superior safety, distance efficiency, and fast processing time compared to the conventional methods. It was also validated in several real-world experiments using a quadrupedal robot. Notably, TRG-planner contributed as the global path planner of an autonomous navigation framework for the DreamSTEP team, which won the Quadruped Robot Challenge at ICRA 2023. The project page is available at https://trg-planner.github.io .
TRIP: Terrain Traversability Mapping With Risk-Aware Prediction for Enhanced Online Quadrupedal Robot Navigation
Nov 26, 2024



Accurate traversability estimation using an online dense terrain map is crucial for safe navigation in challenging environments like construction and disaster areas. However, traversability estimation for legged robots on rough terrains faces substantial challenges owing to limited terrain information caused by restricted field-of-view, and data occlusion and sparsity. To robustly map traversable regions, we introduce terrain traversability mapping with risk-aware prediction (TRIP). TRIP reconstructs the terrain maps while predicting multi-modal traversability risks, enhancing online autonomous navigation with the following contributions. Firstly, estimating steppability in a spherical projection space allows for addressing data sparsity while accomodating scalable terrain properties. Moreover, the proposed traversability-aware Bayesian generalized kernel (T-BGK)-based inference method enhances terrain completion accuracy and efficiency. Lastly, leveraging the steppability-based Mahalanobis distance contributes to robustness against outliers and dynamic elements, ultimately yielding a static terrain traversability map. As verified in both public and our in-house datasets, our TRIP shows significant performance increases in terms of terrain reconstruction and navigation map. A demo video that demonstrates its feasibility as an integral component within an onboard online autonomous navigation system for quadruped robots is available at https://youtu.be/d7HlqAP4l0c.
Obstacle-Aware Quadrupedal Locomotion With Resilient Multi-Modal Reinforcement Learning
Sep 29, 2024



Quadrupedal robots hold promising potential for applications in navigating cluttered environments with resilience akin to their animal counterparts. However, their floating base configuration makes them vulnerable to real-world uncertainties, yielding substantial challenges in their locomotion control. Deep reinforcement learning has become one of the plausible alternatives for realizing a robust locomotion controller. However, the approaches that rely solely on proprioception sacrifice collision-free locomotion because they require front-feet contact to detect the presence of stairs to adapt the locomotion gait. Meanwhile, incorporating exteroception necessitates a precisely modeled map observed by exteroceptive sensors over a period of time. Therefore, this work proposes a novel method to fuse proprioception and exteroception featuring a resilient multi-modal reinforcement learning. The proposed method yields a controller that showcases agile locomotion performance on a quadrupedal robot over a myriad of real-world courses, including rough terrains, steep slopes, and high-rise stairs, while retaining its robustness against out-of-distribution situations.
TOSS: Real-time Tracking and Moving Object Segmentation for Static Scene Mapping
Aug 10, 2024



Safe navigation with simultaneous localization and mapping (SLAM) for autonomous robots is crucial in challenging environments. To achieve this goal, detecting moving objects in the surroundings and building a static map are essential. However, existing moving object segmentation methods have been developed separately for each field, making it challenging to perform real-time navigation and precise static map building simultaneously. In this paper, we propose an integrated real-time framework that combines online tracking-based moving object segmentation with static map building. For safe navigation, we introduce a computationally efficient hierarchical association cost matrix to enable real-time moving object segmentation. In the context of precise static mapping, we present a voting-based method, DS-Voting, designed to achieve accurate dynamic object removal and static object recovery by emphasizing their spatio-temporal differences. We evaluate our proposed method quantitatively and qualitatively in the SemanticKITTI dataset and real-world challenging environments. The results demonstrate that dynamic objects can be clearly distinguished and incorporated into static map construction, even in stairs, steep hills, and dense vegetation.
B-TMS: Bayesian Traversable Terrain Modeling and Segmentation Across 3D LiDAR Scans and Maps for Enhanced Off-Road Navigation
Jun 26, 2024



Recognizing traversable terrain from 3D point cloud data is critical, as it directly impacts the performance of autonomous navigation in off-road environments. However, existing segmentation algorithms often struggle with challenges related to changes in data distribution, environmental specificity, and sensor variations. Moreover, when encountering sunken areas, their performance is frequently compromised, and they may even fail to recognize them. To address these challenges, we introduce B-TMS, a novel approach that performs map-wise terrain modeling and segmentation by utilizing Bayesian generalized kernel (BGK) within the graph structure known as the tri-grid field (TGF). Our experiments encompass various data distributions, ranging from single scans to partial maps, utilizing both public datasets representing urban scenes and off-road environments, and our own dataset acquired from extremely bumpy terrains. Our results demonstrate notable contributions, particularly in terms of robustness to data distribution variations, adaptability to diverse environmental conditions, and resilience against the challenges associated with parameter changes.
Robust Recovery Motion Control for Quadrupedal Robots via Learned Terrain Imagination
Jun 22, 2023



Quadrupedal robots have emerged as a cutting-edge platform for assisting humans, finding applications in tasks related to inspection and exploration in remote areas. Nevertheless, their floating base structure renders them susceptible to fall in cluttered environments, where manual recovery by a human operator may not always be feasible. Several recent studies have presented recovery controllers employing deep reinforcement learning algorithms. However, these controllers are not specifically designed to operate effectively in cluttered environments, such as stairs and slopes, which restricts their applicability. In this study, we propose a robust all-terrain recovery policy to facilitate rapid and secure recovery in cluttered environments. We substantiate the superiority of our proposed approach through simulations and real-world tests encompassing various terrain types.
DreamWaQ: Learning Robust Quadrupedal Locomotion With Implicit Terrain Imagination via Deep Reinforcement Learning
Jan 25, 2023



Quadrupedal robots resemble the physical ability of legged animals to walk through unstructured terrains. However, designing a controller for quadrupedal robots poses a significant challenge due to their functional complexity and requires adaptation to various terrains. Recently, deep reinforcement learning, inspired by how legged animals learn to walk from their experiences, has been utilized to synthesize natural quadrupedal locomotion. However, state-of-the-art methods strongly depend on a complex and reliable sensing framework. Furthermore, prior works that rely only on proprioception have shown a limited demonstration for overcoming challenging terrains, especially for a long distance. This work proposes a novel quadrupedal locomotion learning framework that allows quadrupedal robots to walk through challenging terrains, even with limited sensing modalities. The proposed framework was validated in real-world outdoor environments with varying conditions within a single run for a long distance.
Retro-RL: Reinforcing Nominal Controller With Deep Reinforcement Learning for Tilting-Rotor Drones
Jul 07, 2022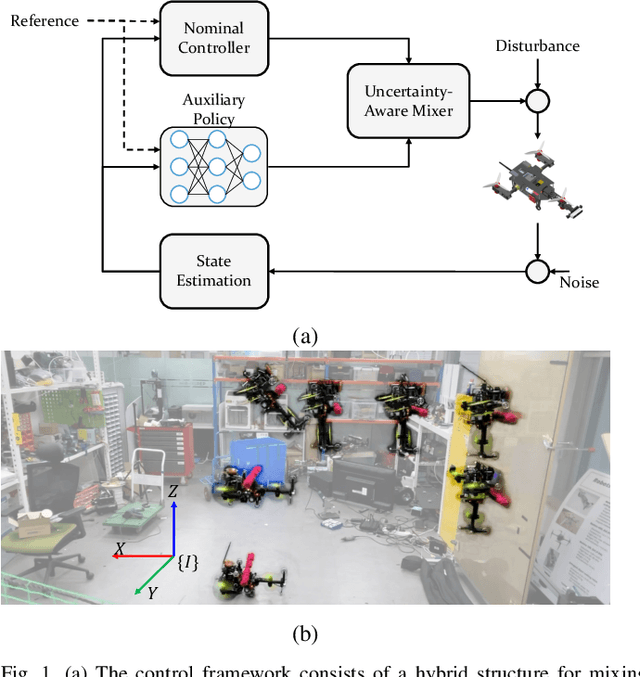
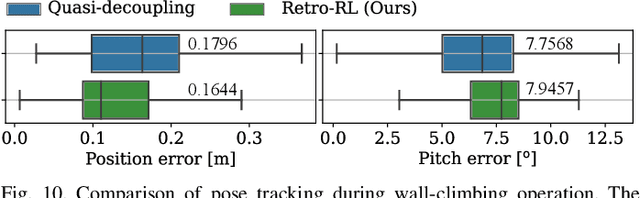
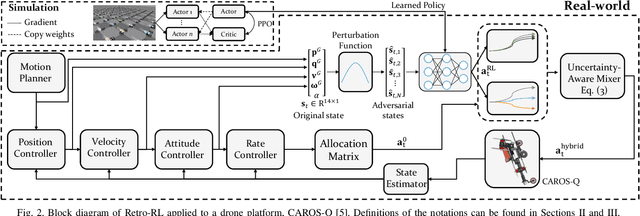
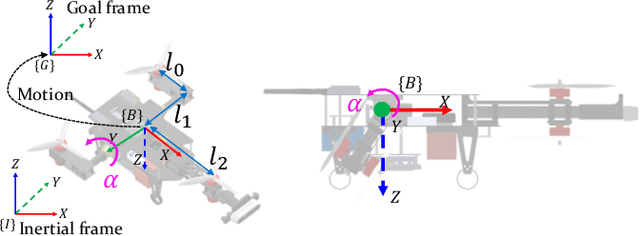
Studies that broaden drone applications into complex tasks require a stable control framework. Recently, deep reinforcement learning (RL) algorithms have been exploited in many studies for robot control to accomplish complex tasks. Unfortunately, deep RL algorithms might not be suitable for being deployed directly into a real-world robot platform due to the difficulty in interpreting the learned policy and lack of stability guarantee, especially for a complex task such as a wall-climbing drone. This paper proposes a novel hybrid architecture that reinforces a nominal controller with a robust policy learned using a model-free deep RL algorithm. The proposed architecture employs an uncertainty-aware control mixer to preserve guaranteed stability of a nominal controller while using the extended robust performance of the learned policy. The policy is trained in a simulated environment with thousands of domain randomizations to achieve robust performance over diverse uncertainties. The performance of the proposed method was verified through real-world experiments and then compared with a conventional controller and the state-of-the-art learning-based controller trained with a vanilla deep RL algorithm.