 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference Networks for Sequential Monte Carlo in Graphical Models
Mar 07, 2018


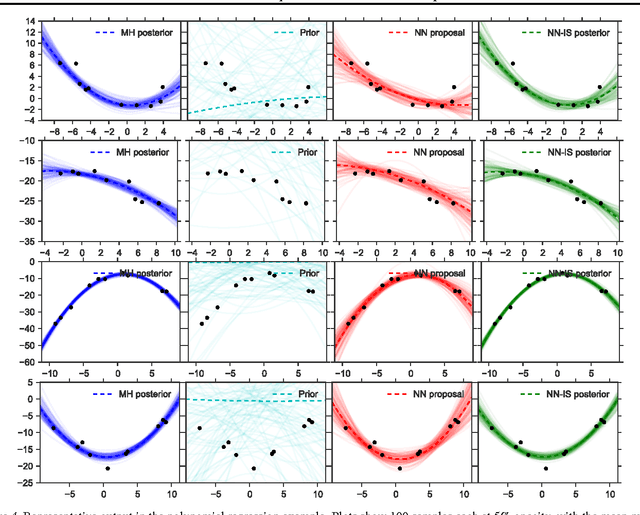
We introduce a new approach for amortizing inference in directed graphical models by learning heuristic approximations to stochastic inverses, designed specifically for use as proposal distributions in sequential Monte Carlo methods. We describe a procedure for constructing and learning a structured neural network which represents an inverse factorization of the graphical model, resulting in a conditional density estimator that takes as input particular values of the observed random variables, and returns an approximation to the distribution of the latent variables. This recognition model can be learned offline, independent from any particular dataset, prior to performing inference. The output of these networks can be used as automatically-learned high-quality proposal distributions to accelerate sequential Monte Carlo across a diverse range of problem settings.
* 10 pages. Updated from version at ICML 2016; includes code at http://github.com/tbrx/compiled-inference
Learning Disentangled Representations with Semi-Supervised Deep Generative Models
Nov 13, 2017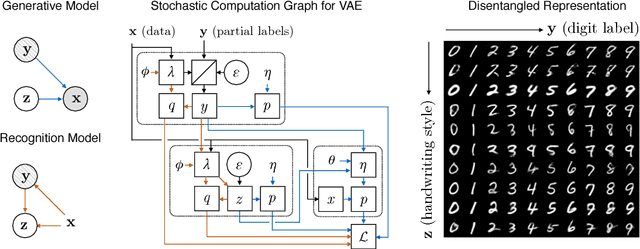

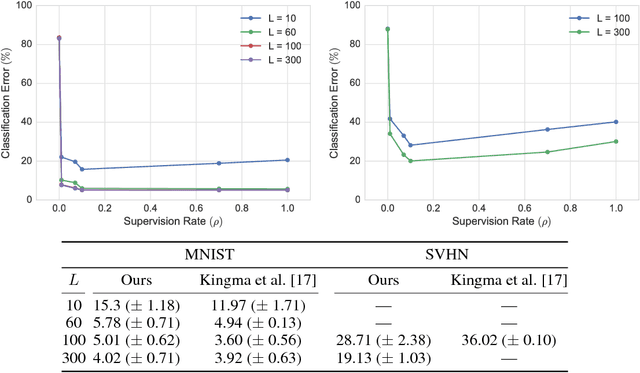
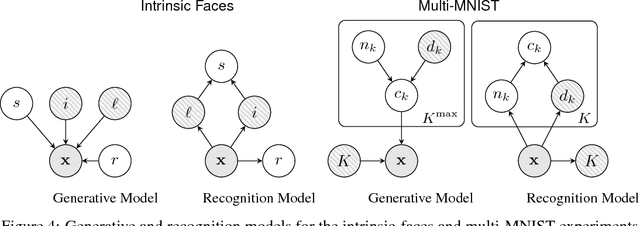
Variational autoencoders (VAEs) learn representations of data by jointly training a probabilistic encoder and decoder network. Typically these models encode all features of the data into a single variable. Here we are interested in learning disentangled representations that encode distinct aspects of the data into separate variables. We propose to learn such representations using model architectures that generalise from standard VAEs, employing a general graphical model structure in the encoder and decoder. This allows us to train partially-specified models that make relatively strong assumptions about a subset of interpretable variables and rely on the flexibility of neural networks to learn representations for the remaining variables. We further define a general objective for semi-supervised learning in this model class, which can be approximated using an importance sampling procedure. We evaluate our framework's ability to learn disentangled representations, both by qualitative exploration of its generative capacity, and quantitative evaluation of its discriminative ability on a variety of models and datasets.
Kernel Sequential Monte Carlo
Jul 25, 2017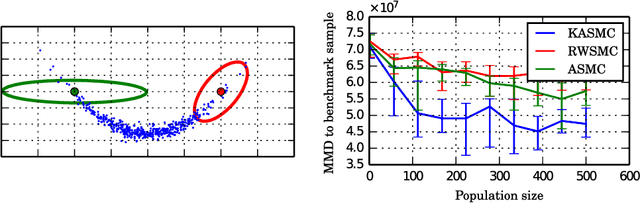
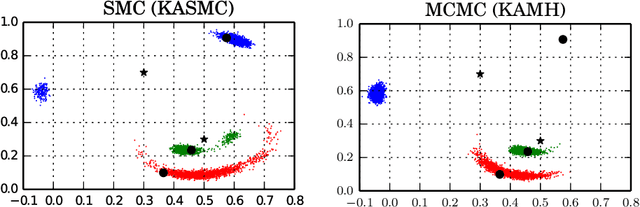
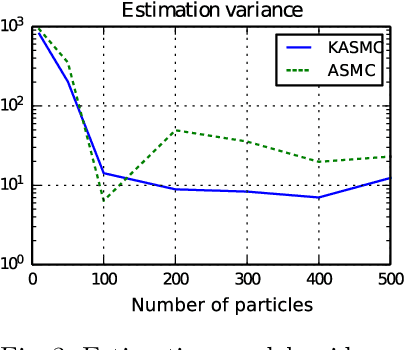
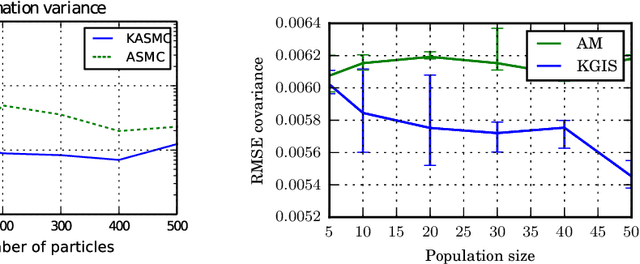
We propose kernel sequential Monte Carlo (KSMC), a framework for sampling from static target densities. KSMC is a family of sequential Monte Carlo algorithms that are based on building emulator models of the current particle system in a reproducing kernel Hilbert space. We here focus on modelling nonlinear covariance structure and gradients of the target. The emulator's geometry is adaptively updated and subsequently used to inform local proposals. Unlike in adaptive Markov chain Monte Carlo, continuous adaptation does not compromise convergence of the sampler. KSMC combines the strengths of sequental Monte Carlo and kernel methods: superior performance for multimodal targets and the ability to estimate model evidence as compared to Markov chain Monte Carlo, and the emulator's ability to represent targets that exhibit high degrees of nonlinearity. As KSMC does not require access to target gradients, it is particularly applicable on targets whose gradients are unknown or prohibitively expensive. We describe necessary tuning details and demonstrate the benefits of the the proposed methodology on a series of challenging synthetic and real-world examples.
Interacting Particle Markov Chain Monte Carlo
Apr 12, 2017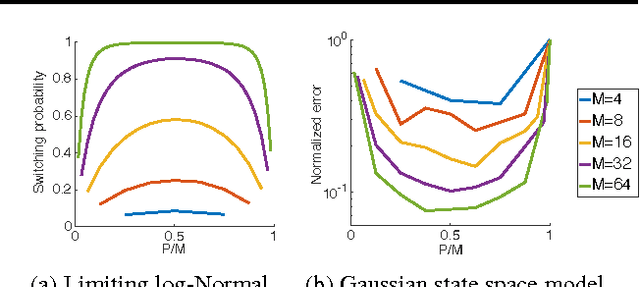
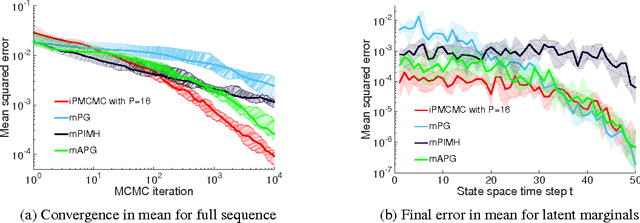
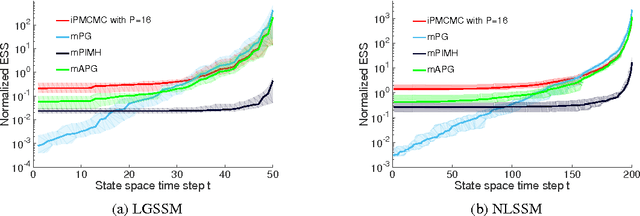
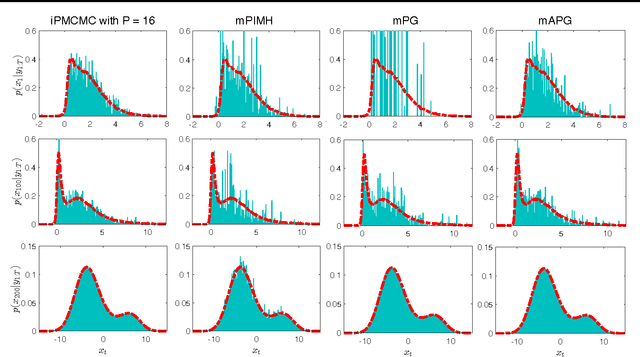
We introduce interacting particle Markov chain Monte Carlo (iPMCMC), a PMCMC method based on an interacting pool of standard and conditional sequential Monte Carlo samplers. Like related methods, iPMCMC is a Markov chain Monte Carlo sampler on an extended space. We present empirical results that show significant improvements in mixing rates relative to both non-interacting PMCMC samplers, and a single PMCMC sampler with an equivalent memory and computational budget. An additional advantage of the iPMCMC method is that it is suitable for distributed and multi-core architectures.
Grammar Variational Autoencoder
Mar 06, 2017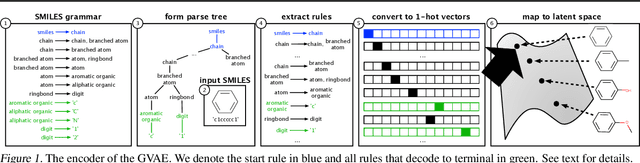

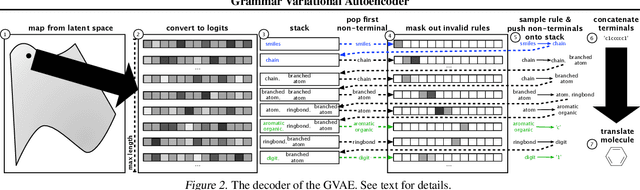
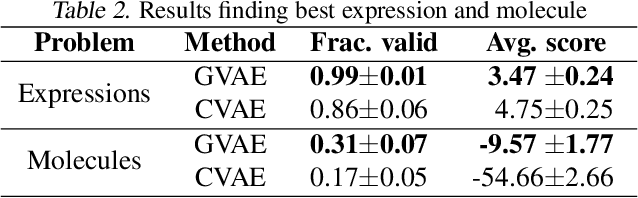
Deep generative models have been wildly successful at learning coherent latent representations for continuous data such as video and audio. However, generative modeling of discrete data such as arithmetic expressions and molecular structures still poses significant challenges. Crucially, state-of-the-art methods often produce outputs that are not valid. We make the key observation that frequently, discrete data can be represented as a parse tree from a context-free grammar. We propose a variational autoencoder which encodes and decodes directly to and from these parse trees, ensuring the generated outputs are always valid. Surprisingly, we show that not only does our model more often generate valid outputs, it also learns a more coherent latent space in which nearby points decode to similar discrete outputs. We demonstrate the effectiveness of our learned models by showing their improved performance in Bayesian optimization for symbolic regression and molecular synthesis.
Inducing Interpretable Representations with Variational Autoencoders
Nov 22, 2016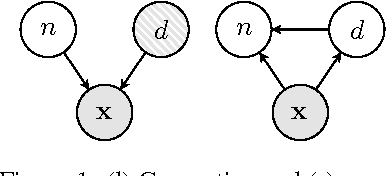
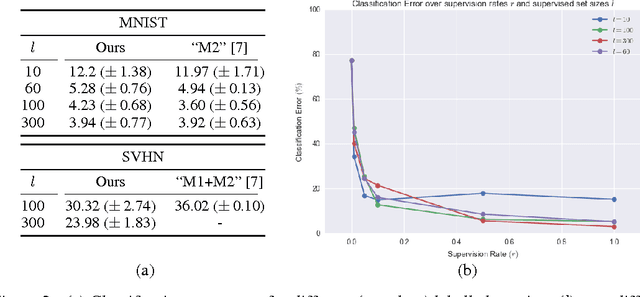

We develop a framework for incorporating structured graphical models in the \emph{encoders} of variational autoencoders (VAEs) that allows us to induce interpretable representations through approximate variational inference. This allows us to both perform reasoning (e.g. classification) under the structural constraints of a given graphical model, and use deep generative models to deal with messy, high-dimensional domains where it is often difficult to model all the variation. Learning in this framework is carried out end-to-end with a variational objective, applying to both unsupervised and semi-supervised schemes.
Probabilistic structure discovery in time series data
Nov 21, 2016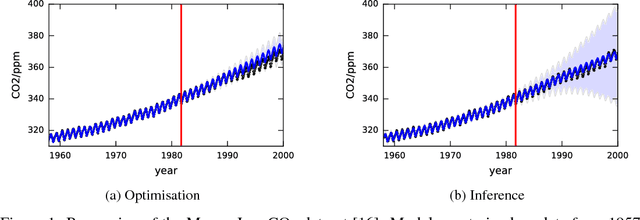
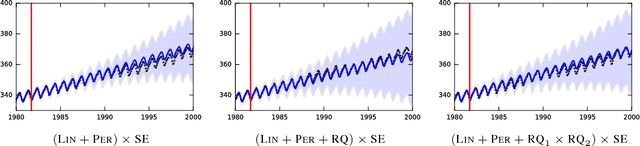
Existing methods for structure discovery in time series data construct interpretable, compositional kernels for Gaussian process regression models. While the learned Gaussian process model provides posterior mean and variance estimates, typically the structure is learned via a greedy optimization procedure. This restricts the space of possible solutions and leads to over-confident uncertainty estimates. We introduce a fully Bayesian approach, inferring a full posterior over structures, which more reliably captures the uncertainty of the model.
Black-Box Policy Search with Probabilistic Programs
Aug 04, 2016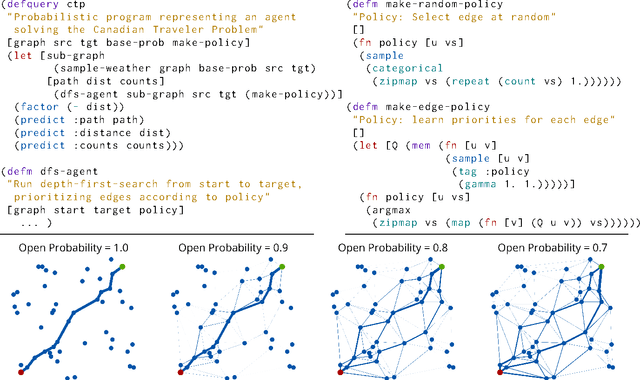
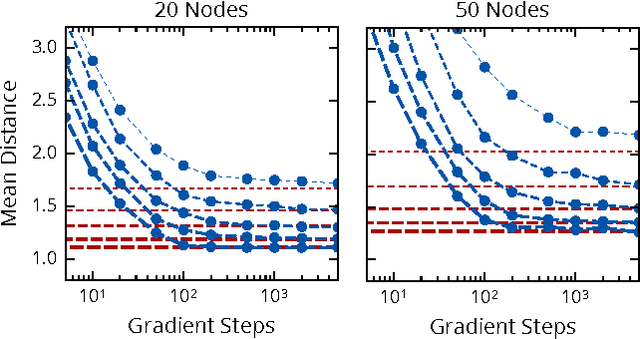
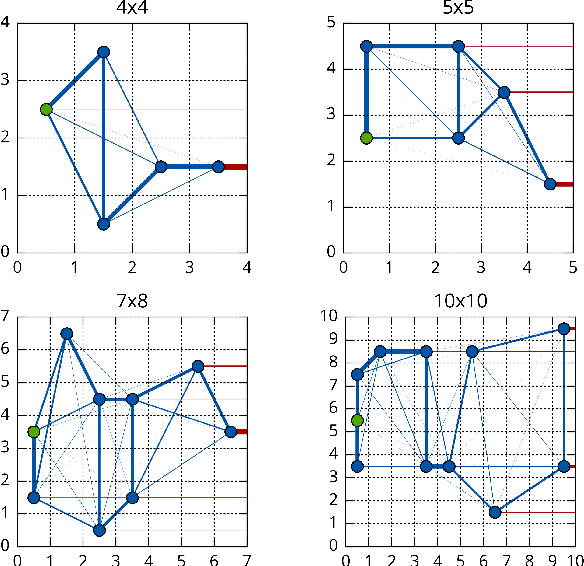
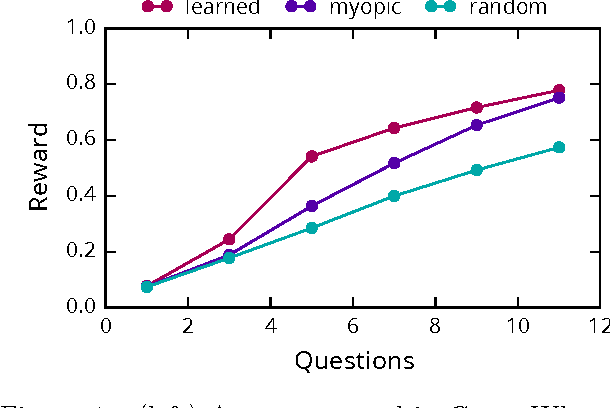
In this work, we explore how probabilistic programs can be used to represent policies in sequential decision problems. In this formulation, a probabilistic program is a black-box stochastic simulator for both the problem domain and the agent. We relate classic policy gradient techniques to recently introduced black-box variational methods which generalize to probabilistic program inference. We present case studies in the Canadian traveler problem, Rock Sample, and a benchmark for optimal diagnosis inspired by Guess Who. Each study illustrates how programs can efficiently represent policies using moderate numbers of parameters.
Path Finding under Uncertainty through Probabilistic Inference
Jun 08, 2015We introduce a new approach to solving path-finding problems under uncertainty by representing them as probabilistic models and applying domain-independent inference algorithms to the models. This approach separates problem representation from the inference algorithm and provides a framework for efficient learning of path-finding policies. We evaluate the new approach on the Canadian Traveler Problem, which we formulate as a probabilistic model, and show how probabilistic inference allows high performance stochastic policies to be obtained for this problem.
Output-Sensitive Adaptive Metropolis-Hastings for Probabilistic Programs
May 05, 2015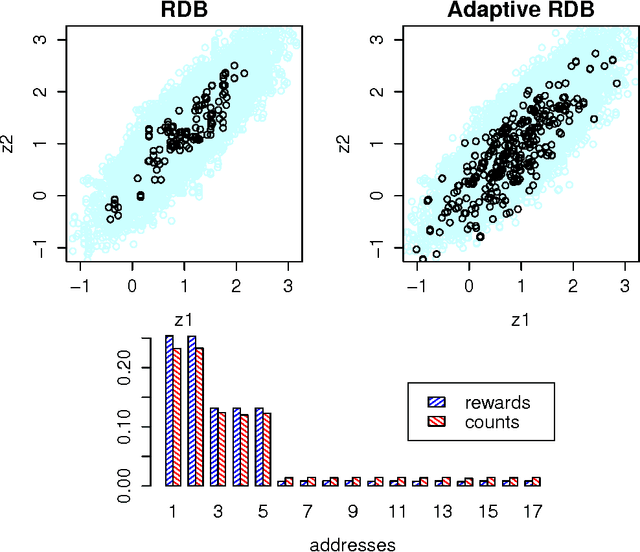
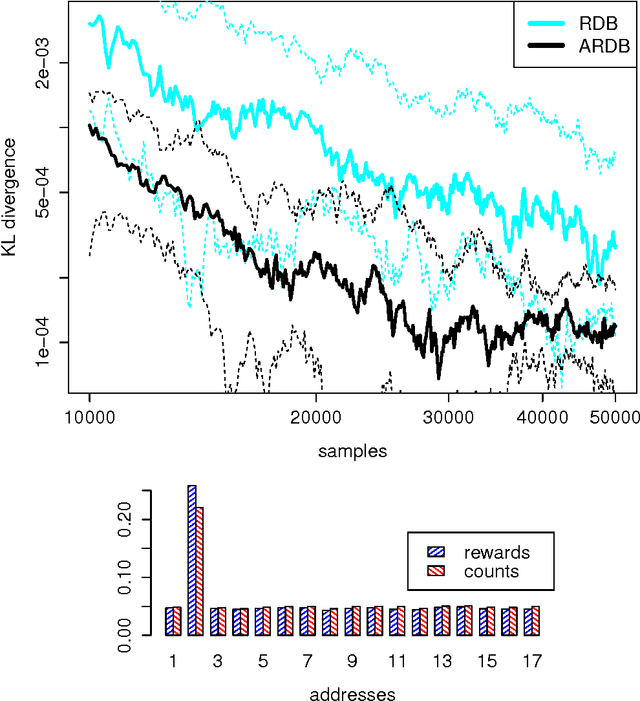
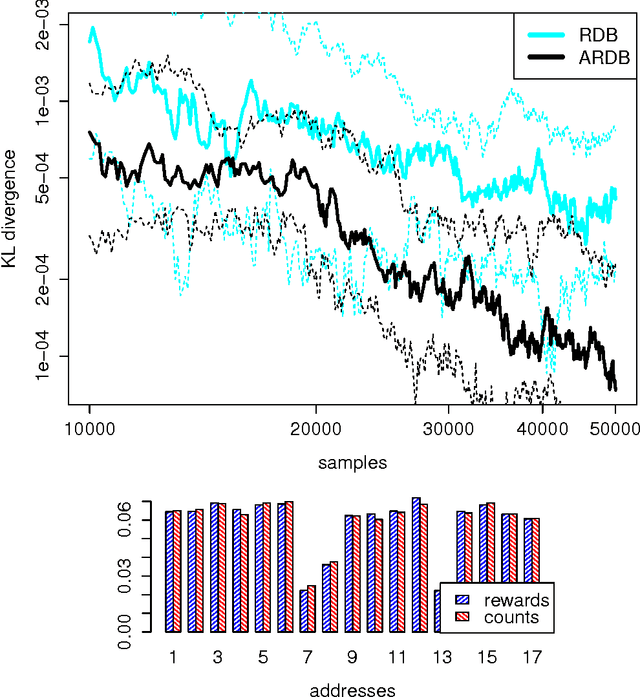
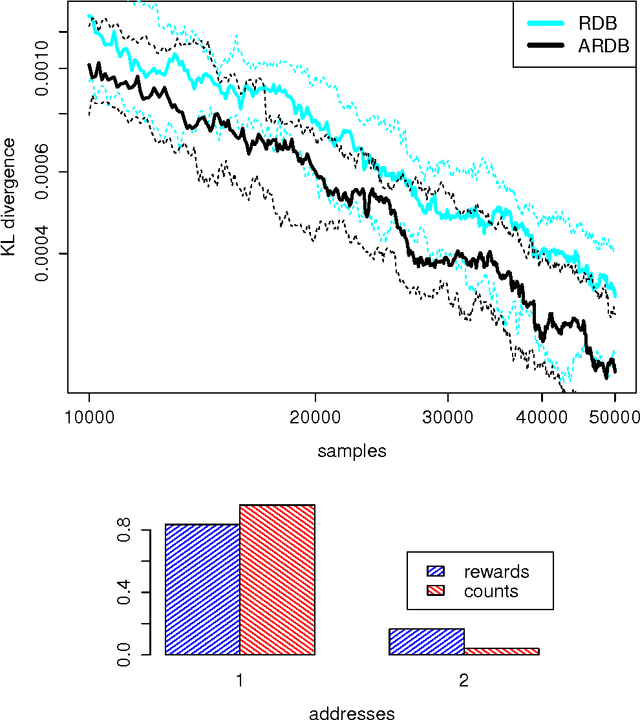
We introduce an adaptive output-sensitive Metropolis-Hastings algorithm for probabilistic models expressed as programs, Adaptive Lightweight Metropolis-Hastings (AdLMH). The algorithm extends Lightweight Metropolis-Hastings (LMH) by adjusting the probabilities of proposing random variables for modification to improve convergence of the program output. We show that AdLMH converges to the correct equilibrium distribution and compare convergence of AdLMH to that of LMH on several test problems to highlight different aspects of the adaptation scheme. We observe consistent improvement in convergence on the test problems.