 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePessimistic Off-Policy Optimization for Learning to Rank
Jun 06, 2022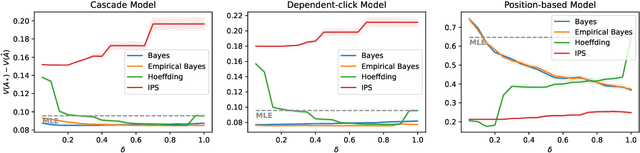
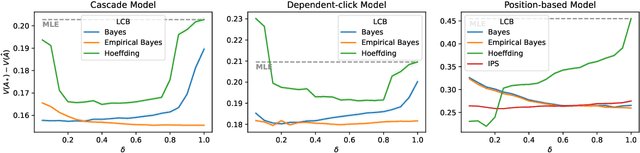
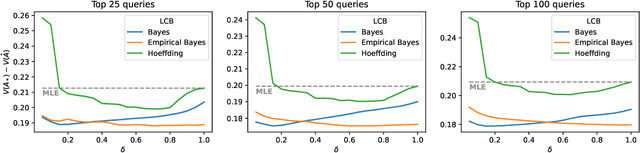
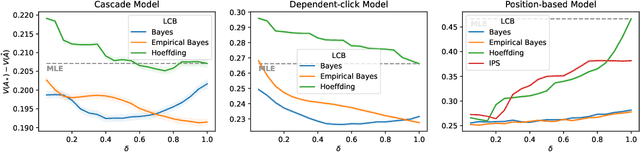
Off-policy learning is a framework for optimizing policies without deploying them, using data collected by another policy. In recommender systems, this is especially challenging due to the imbalance in logged data: some items are recommended and thus logged much more frequently than others. This is further perpetuated when recommending a list of items, as the action space is combinatorial. To address this challenge, we study pessimistic off-policy optimization for learning to rank. The key idea is to compute lower confidence bounds on parameters of click models and then return the list with the highest pessimistic estimate of its value. This approach is computationally efficient and we analyze it. We study its Bayesian and frequentist variants, and overcome the limitation of unknown prior by incorporating empirical Bayes. To show the empirical effectiveness of our approach, we compare it to off-policy optimizers that use inverse propensity scores or neglect uncertainty. Our approach outperforms all baselines, is robust, and is also general.
Generalizing Hierarchical Bayesian Bandits
May 30, 2022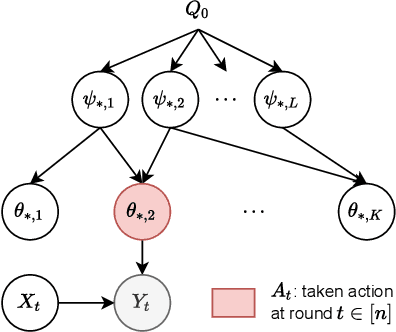
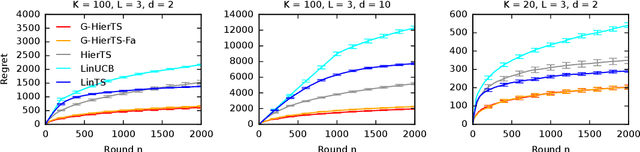
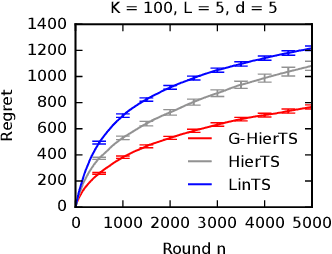
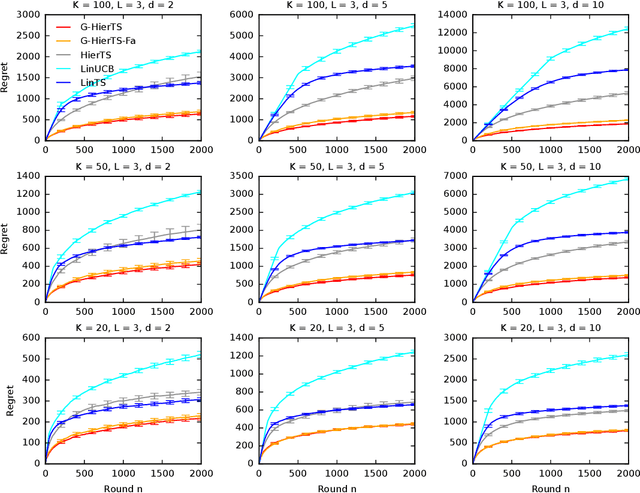
A contextual bandit is a popular and practical framework for online learning to act under uncertainty. In many problems, the number of actions is huge and their mean rewards are correlated. In this work, we introduce a general framework for capturing such correlations through a two-level graphical model where actions are related through multiple shared latent parameters. We propose a Thompson sampling algorithm G-HierTS that uses this structure to explore efficiently and bound its Bayes regret. The regret has two terms, one for learning action parameters and the other for learning the shared latent parameters. The terms reflect the structure of our model as well as the quality of priors. Our theoretical findings are validated empirically using both synthetic and real-world problems. We also experiment with G-HierTS that maintains a factored posterior over latent parameters. While this approximation does not come with guarantees, it improves computational efficiency with a minimal impact on empirical regret.
Safe Exploration for Efficient Policy Evaluation and Comparison
Feb 26, 2022

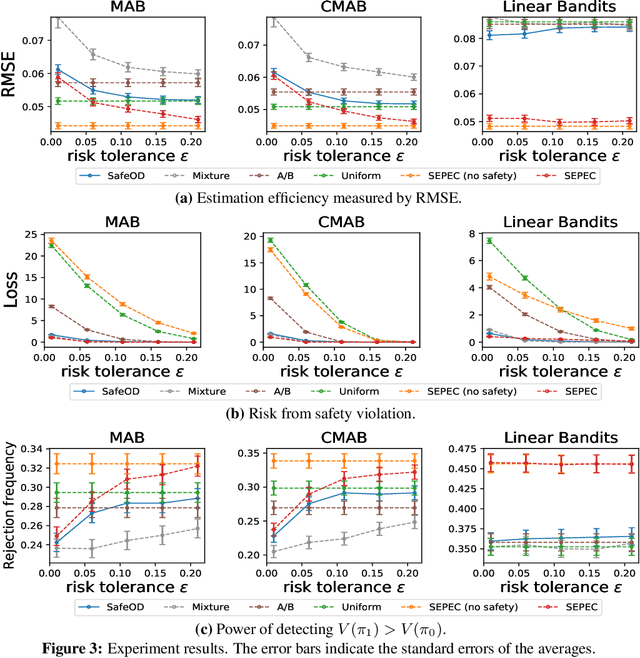
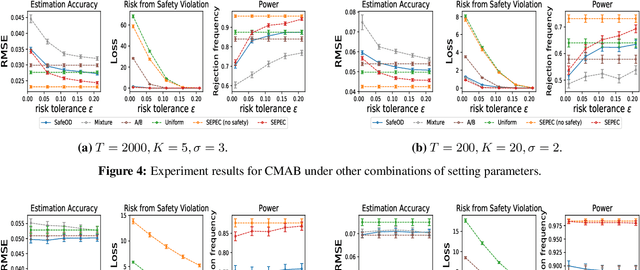
High-quality data plays a central role in ensuring the accuracy of policy evaluation. This paper initiates the study of efficient and safe data collection for bandit policy evaluation. We formulate the problem and investigate its several representative variants. For each variant, we analyze its statistical properties, derive the corresponding exploration policy, and design an efficient algorithm for computing it. Both theoretical analysis and experiments support the usefulness of the proposed methods.
Meta-Learning for Simple Regret Minimization
Feb 25, 2022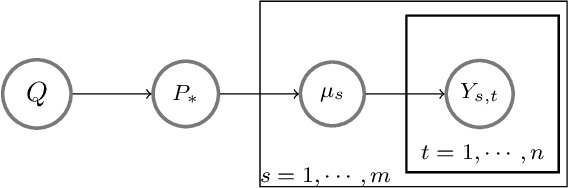
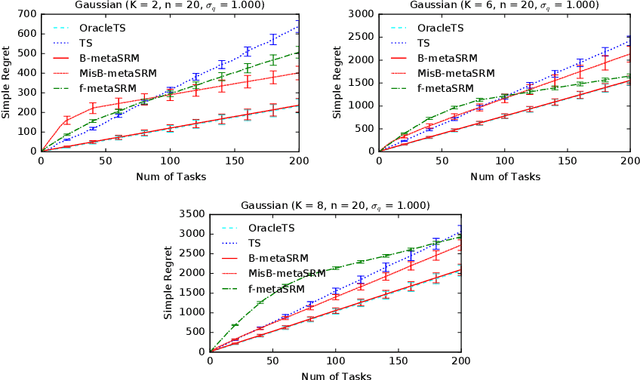
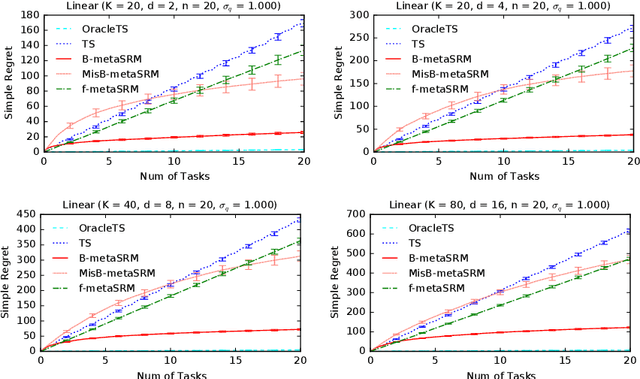
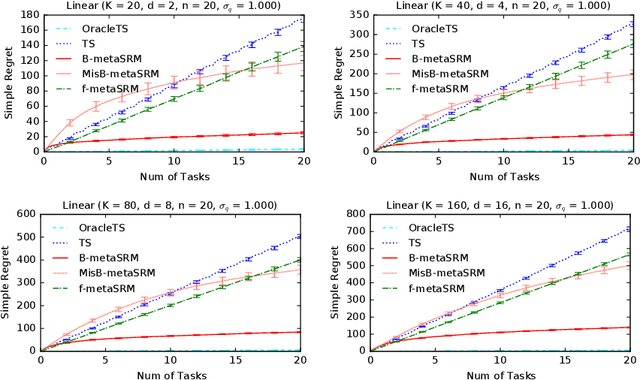
We develop a meta-learning framework for simple regret minimization in bandits. In this framework, a learning agent interacts with a sequence of bandit tasks, which are sampled i.i.d.\ from an unknown prior distribution, and learns its meta-parameters to perform better on future tasks. We propose the first Bayesian and frequentist algorithms for this meta-learning problem. The Bayesian algorithm has access to a prior distribution over the meta-parameters and its meta simple regret over $m$ bandit tasks with horizon $n$ is mere $\tilde{O}(m / \sqrt{n})$. This is while we show that the meta simple regret of the frequentist algorithm is $\tilde{O}(\sqrt{m} n + m/ \sqrt{n})$, and thus, worse. However, the algorithm is more general, because it does not need a prior distribution over the meta-parameters, and is easier to implement for various distributions. We instantiate our algorithms for several classes of bandit problems. Our algorithms are general and we complement our theory by evaluating them empirically in several environments.
Deep Hierarchy in Bandits
Feb 03, 2022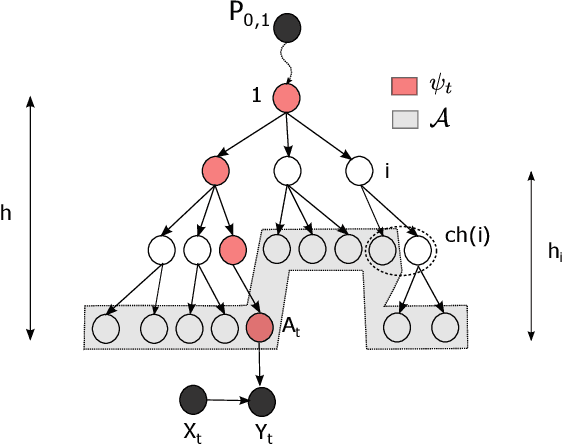
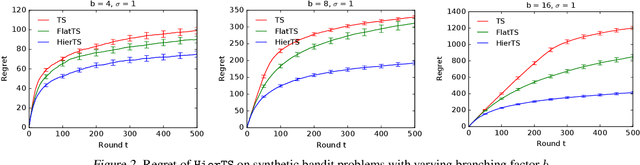
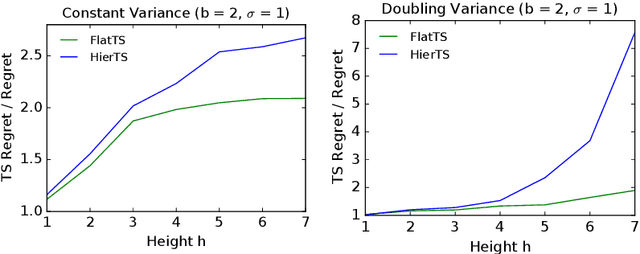
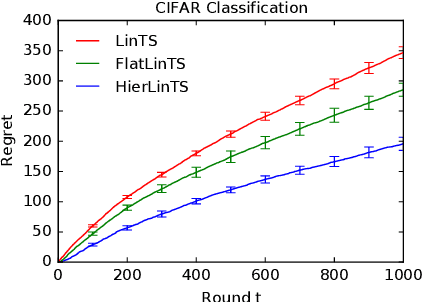
Mean rewards of actions are often correlated. The form of these correlations may be complex and unknown a priori, such as the preferences of a user for recommended products and their categories. To maximize statistical efficiency, it is important to leverage these correlations when learning. We formulate a bandit variant of this problem where the correlations of mean action rewards are represented by a hierarchical Bayesian model with latent variables. Since the hierarchy can have multiple layers, we call it deep. We propose a hierarchical Thompson sampling algorithm (HierTS) for this problem, and show how to implement it efficiently for Gaussian hierarchies. The efficient implementation is possible due to a novel exact hierarchical representation of the posterior, which itself is of independent interest. We use this exact posterior to analyze the Bayes regret of HierTS in Gaussian bandits. Our analysis reflects the structure of the problem, that the regret decreases with the prior width, and also shows that hierarchies reduce the regret by non-constant factors in the number of actions. We confirm these theoretical findings empirically, in both synthetic and real-world experiments.
IMO$^3$: Interactive Multi-Objective Off-Policy Optimization
Jan 25, 2022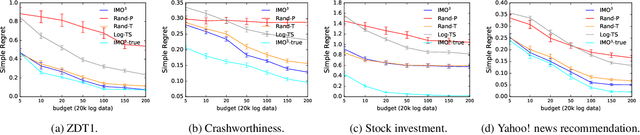
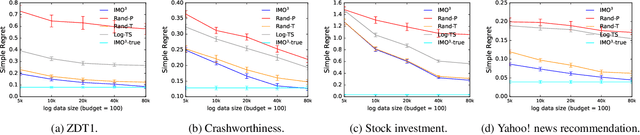
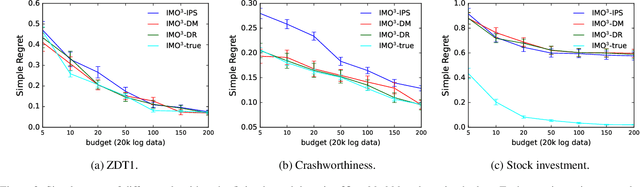
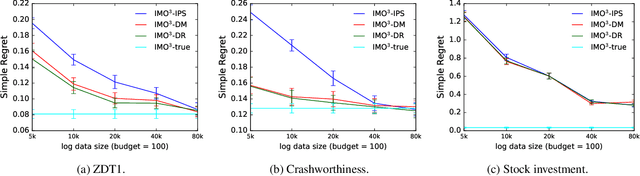
Most real-world optimization problems have multiple objectives. A system designer needs to find a policy that trades off these objectives to reach a desired operating point. This problem has been studied extensively in the setting of known objective functions. We consider a more practical but challenging setting of unknown objective functions. In industry, this problem is mostly approached with online A/B testing, which is often costly and inefficient. As an alternative, we propose interactive multi-objective off-policy optimization (IMO$^3$). The key idea in our approach is to interact with a system designer using policies evaluated in an off-policy fashion to uncover which policy maximizes her unknown utility function. We theoretically show that IMO$^3$ identifies a near-optimal policy with high probability, depending on the amount of feedback from the designer and training data for off-policy estimation. We demonstrate its effectiveness empirically on multiple multi-objective optimization problems.
Hierarchical Bayesian Bandits
Nov 12, 2021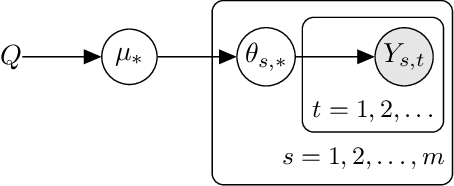
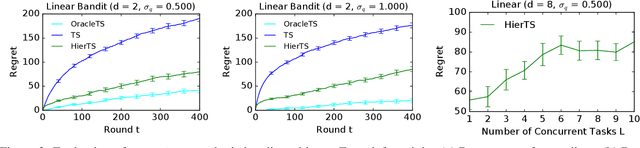
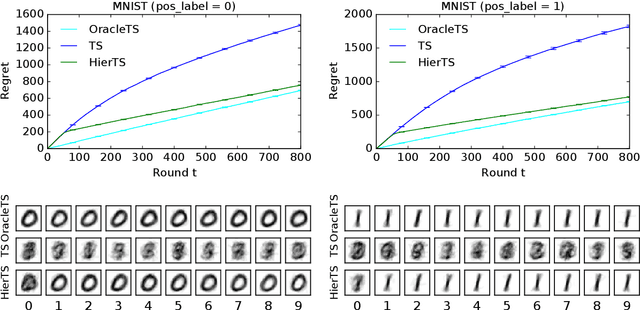
Meta-, multi-task, and federated learning can be all viewed as solving similar tasks, drawn from an unknown distribution that reflects task similarities. In this work, we provide a unified view of all these problems, as learning to act in a hierarchical Bayesian bandit. We analyze a natural hierarchical Thompson sampling algorithm (hierTS) that can be applied to any problem in this class. Our regret bounds hold under many instances of such problems, including when the tasks are solved sequentially or in parallel; and capture the structure of the problems, such that the regret decreases with the width of the task prior. Our proofs rely on novel total variance decompositions, which can be applied to other graphical model structures. Finally, our theory is complemented by experiments, which show that the hierarchical structure helps with knowledge sharing among the tasks. This confirms that hierarchical Bayesian bandits are a universal and statistically-efficient tool for learning to act with similar bandit tasks.
Safe Optimal Design with Applications in Policy Learning
Nov 08, 2021
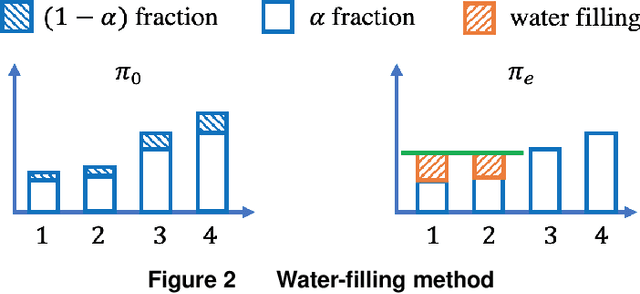
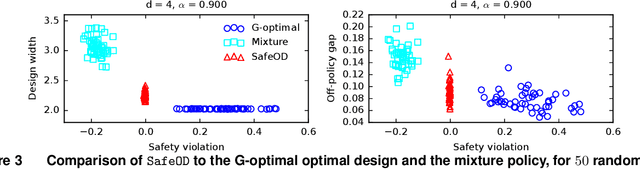
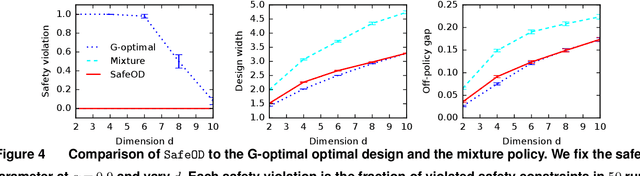
Motivated by practical needs in online experimentation and off-policy learning, we study the problem of safe optimal design, where we develop a data logging policy that efficiently explores while achieving competitive rewards with a baseline production policy. We first show, perhaps surprisingly, that a common practice of mixing the production policy with uniform exploration, despite being safe, is sub-optimal in maximizing information gain. Then we propose a safe optimal logging policy for the case when no side information about the actions' expected rewards is available. We improve upon this design by considering side information and also extend both approaches to a large number of actions with a linear reward model. We analyze how our data logging policies impact errors in off-policy learning. Finally, we empirically validate the benefit of our designs by conducting extensive experiments.
Optimal Probing with Statistical Guarantees for Network Monitoring at Scale
Sep 16, 2021
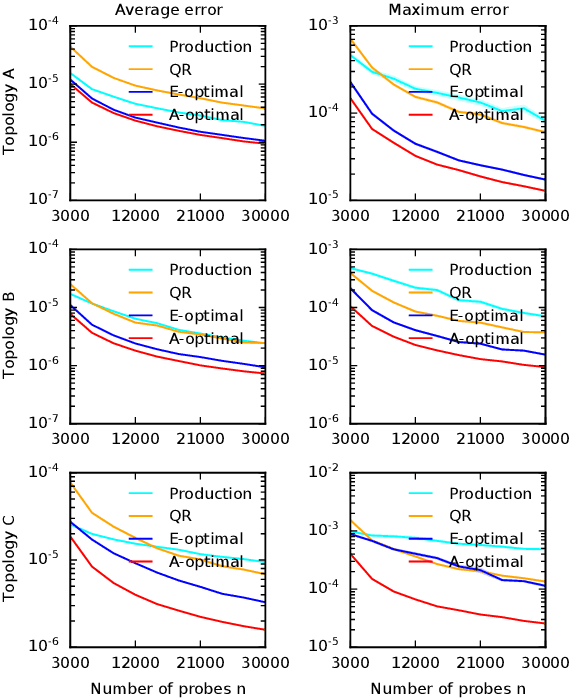
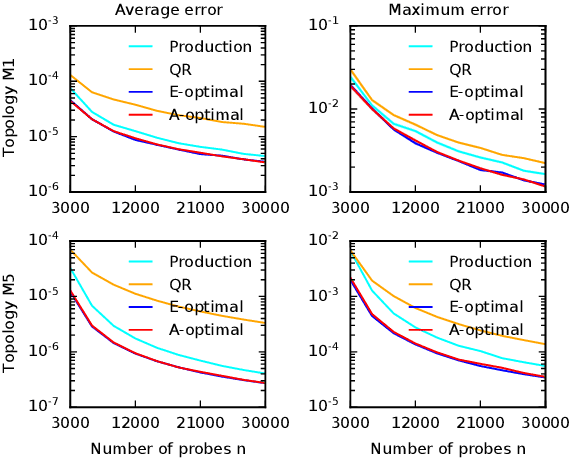
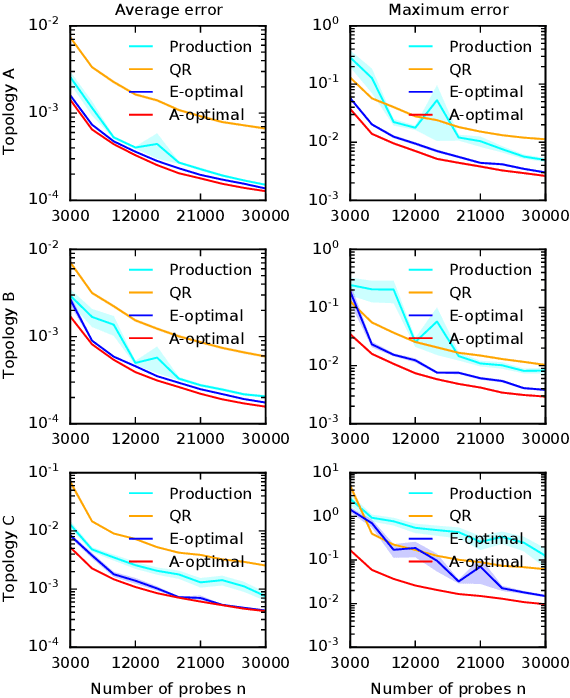
Cloud networks are difficult to monitor because they grow rapidly and the budgets for monitoring them are limited. We propose a framework for estimating network metrics, such as latency and packet loss, with guarantees on estimation errors for a fixed monitoring budget. Our proposed algorithms produce a distribution of probes across network paths, which we then monitor; and are based on A- and E-optimal experimental designs in statistics. Unfortunately, these designs are too computationally costly to use at production scale. We propose their scalable and near-optimal approximations based on the Frank-Wolfe algorithm. We validate our approaches in simulation on real network topologies, and also using a production probing system in a real cloud network. We show major gains in reducing the probing budget compared to both production and academic baselines, while maintaining low estimation errors, even with very low probing budgets.
No Regrets for Learning the Prior in Bandits
Jul 13, 2021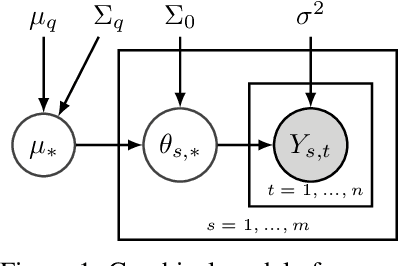
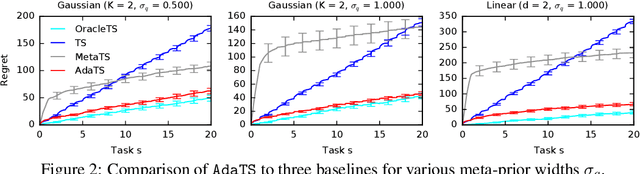

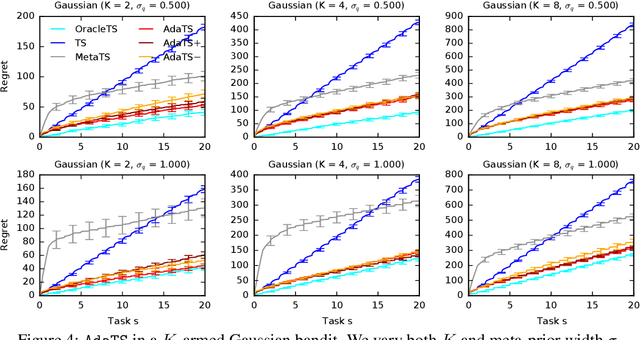
We propose ${\tt AdaTS}$, a Thompson sampling algorithm that adapts sequentially to bandit tasks that it interacts with. The key idea in ${\tt AdaTS}$ is to adapt to an unknown task prior distribution by maintaining a distribution over its parameters. When solving a bandit task, that uncertainty is marginalized out and properly accounted for. ${\tt AdaTS}$ is a fully-Bayesian algorithm that can be implemented efficiently in several classes of bandit problems. We derive upper bounds on its Bayes regret that quantify the loss due to not knowing the task prior, and show that it is small. Our theory is supported by experiments, where ${\tt AdaTS}$ outperforms prior algorithms and works well even in challenging real-world problems.