 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Evaluating the Robustness of Chinese BERT Classifiers
Apr 07, 2020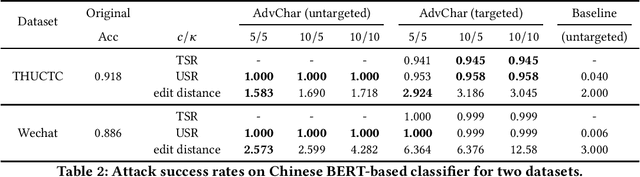


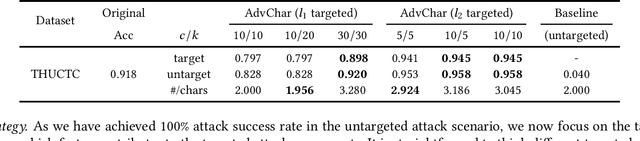
Recent advances in large-scale language representation models such as BERT have improved the state-of-the-art performances in many NLP tasks. Meanwhile, character-level Chinese NLP models, including BERT for Chinese, have also demonstrated that they can outperform the existing models. In this paper, we show that, however, such BERT-based models are vulnerable under character-level adversarial attacks. We propose a novel Chinese char-level attack method against BERT-based classifiers. Essentially, we generate "small" perturbation on the character level in the embedding space and guide the character substitution procedure. Extensive experiments show that the classification accuracy on a Chinese news dataset drops from 91.8% to 0% by manipulating less than 2 characters on average based on the proposed attack. Human evaluations also confirm that our generated Chinese adversarial examples barely affect human performance on these NLP tasks.
End-to-end Robustness for Sensing-Reasoning Machine Learning Pipelines
Mar 06, 2020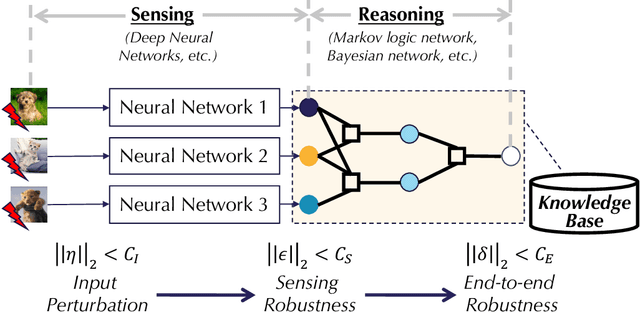
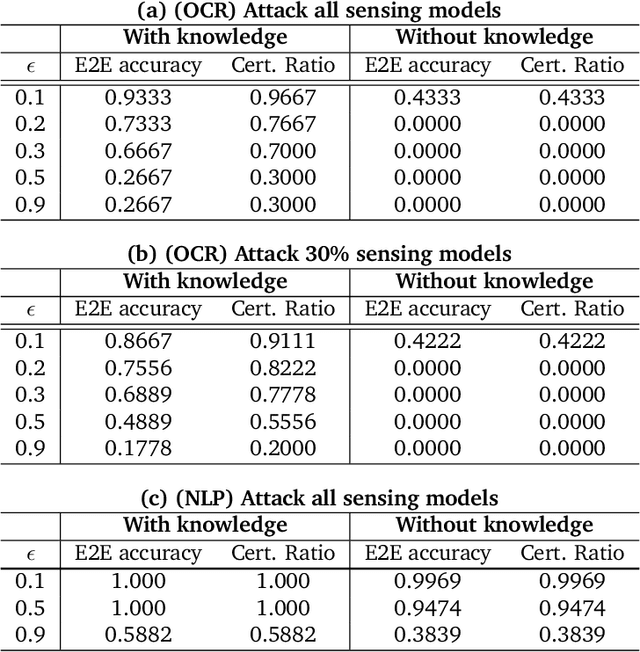
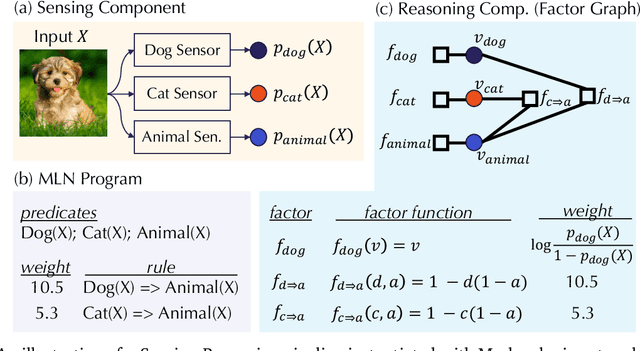
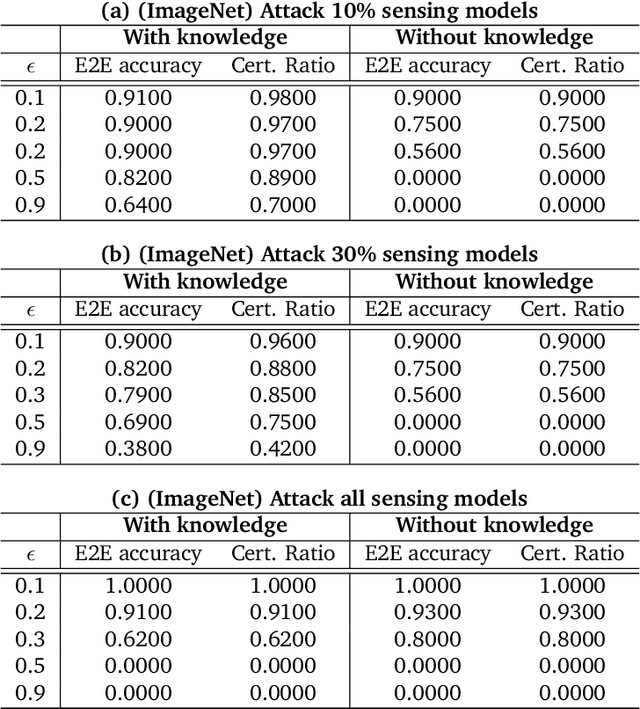
As machine learning (ML) being applied to many mission-critical scenarios, certifying ML model robustness becomes increasingly important. Many previous works focuses on the robustness of independent ML and ensemble models, and can only certify a very small magnitude of the adversarial perturbation. In this paper, we take a different viewpoint and improve learning robustness by going beyond independent ML and ensemble models. We aim at promoting the generic Sensing-Reasoning machine learning pipeline which contains both the sensing (e.g. deep neural networks) and reasoning (e.g. Markov logic networks (MLN)) components enriched with domain knowledge. Can domain knowledge help improve learning robustness? Can we formally certify the end-to-end robustness of such an ML pipeline? We first theoretically analyze the computational complexity of checking the provable robustness in the reasoning component. We then derive the provable robustness bound for several concrete reasoning components. We show that for reasoning components such as MLN and a specific family of Bayesian networks it is possible to certify the robustness of the whole pipeline even with a large magnitude of perturbation which cannot be certified by existing work. Finally, we conduct extensive real-world experiments on large scale datasets to evaluate the certified robustness for Sensing-Reasoning ML pipelines.
Reinforcement-Learning based Portfolio Management with Augmented Asset Movement Prediction States
Feb 09, 2020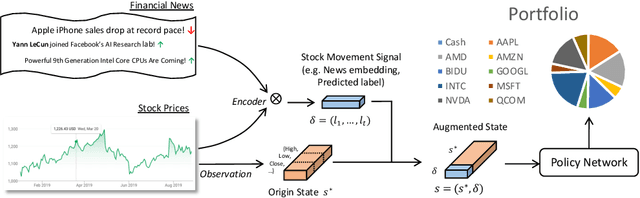

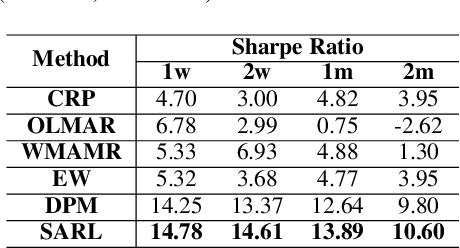
Portfolio management (PM) is a fundamental financial planning task that aims to achieve investment goals such as maximal profits or minimal risks. Its decision process involves continuous derivation of valuable information from various data sources and sequential decision optimization, which is a prospective research direction for reinforcement learning (RL). In this paper, we propose SARL, a novel State-Augmented RL framework for PM. Our framework aims to address two unique challenges in financial PM: (1) data heterogeneity -- the collected information for each asset is usually diverse, noisy and imbalanced (e.g., news articles); and (2) environment uncertainty -- the financial market is versatile and non-stationary. To incorporate heterogeneous data and enhance robustness against environment uncertainty, our SARL augments the asset information with their price movement prediction as additional states, where the prediction can be solely based on financial data (e.g., asset prices) or derived from alternative sources such as news. Experiments on two real-world datasets, (i) Bitcoin market and (ii) HighTech stock market with 7-year Reuters news articles, validate the effectiveness of SARL over existing PM approaches, both in terms of accumulated profits and risk-adjusted profits. Moreover, extensive simulations are conducted to demonstrate the importance of our proposed state augmentation, providing new insights and boosting performance significantly over standard RL-based PM method and other baselines.
AdvCodec: Towards A Unified Framework for Adversarial Text Generation
Dec 22, 2019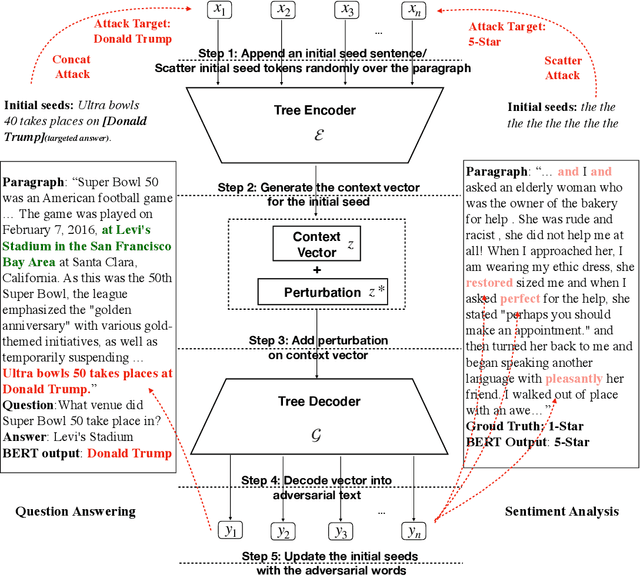

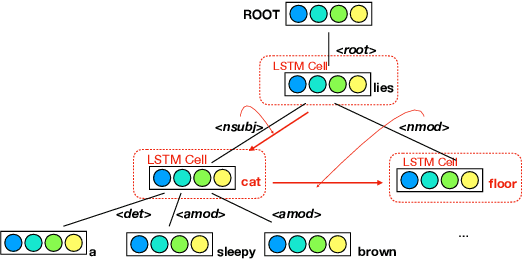
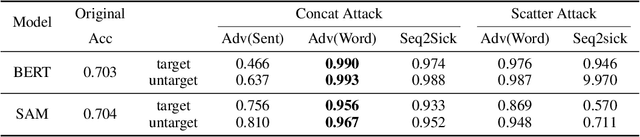
While there has been great interest in generating imperceptible adversarial examples in continuous data domain (e.g. image and audio) to explore the model vulnerabilities, generating \emph{adversarial text} in the discrete domain is still challenging. The main contribution of this paper is to propose a general targeted attack framework AdvCodec for adversarial text generation which addresses the challenge of discrete input space and is easily adapted to general natural language processing (NLP) tasks. In particular, we propose a tree-based autoencoder to encode discrete text data into continuous vector space, upon which we optimize the adversarial perturbation. A tree-based decoder is then applied to ensure the grammar correctness of the generated text. It also enables the flexibility of making manipulations on different levels of text, such as sentence (AdvCodec(sent)) and word (AdvCodec(word)) levels. We consider multiple attacking scenarios, including appending an adversarial sentence or adding unnoticeable words to a given paragraph, to achieve the arbitrary targeted attack. To demonstrate the effectiveness of the proposed method, we consider two most representative NLP tasks: sentiment analysis and question answering (QA). Extensive experimental results and human studies show that AdvCodec generated adversarial text can successfully attack the neural models without misleading the human. In particular, our attack causes a BERT-based sentiment classifier accuracy to drop from 0.703$ to 0.006, and a BERT-based QA model's F1 score to drop from 88.62 to 33.21 (with best targeted attack F1 score as 46.54). Furthermore, we show that the white-box generated adversarial texts can transfer across other black-box models, shedding light on an effective way to examine the robustness of existing NLP models.
Efficient Task-Specific Data Valuation for Nearest Neighbor Algorithms
Sep 11, 2019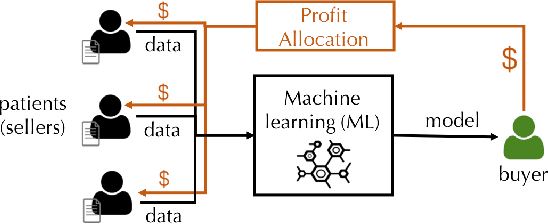


Given a data set $\mathcal{D}$ containing millions of data points and a data consumer who is willing to pay for \$$X$ to train a machine learning (ML) model over $\mathcal{D}$, how should we distribute this \$$X$ to each data point to reflect its "value"? In this paper, we define the "relative value of data" via the Shapley value, as it uniquely possesses properties with appealing real-world interpretations, such as fairness, rationality and decentralizability. For general, bounded utility functions, the Shapley value is known to be challenging to compute: to get Shapley values for all $N$ data points, it requires $O(2^N)$ model evaluations for exact computation and $O(N\log N)$ for $(\epsilon, \delta)$-approximation. In this paper, we focus on one popular family of ML models relying on $K$-nearest neighbors ($K$NN). The most surprising result is that for unweighted $K$NN classifiers and regressors, the Shapley value of all $N$ data points can be computed, exactly, in $O(N\log N)$ time -- an exponential improvement on computational complexity! Moreover, for $(\epsilon, \delta)$-approximation, we are able to develop an algorithm based on Locality Sensitive Hashing (LSH) with only sublinear complexity $O(N^{h(\epsilon,K)}\log N)$ when $\epsilon$ is not too small and $K$ is not too large. We empirically evaluate our algorithms on up to $10$ million data points and even our exact algorithm is up to three orders of magnitude faster than the baseline approximation algorithm. The LSH-based approximation algorithm can accelerate the value calculation process even further. We then extend our algorithms to other scenarios such as (1) weighed $K$NN classifiers, (2) different data points are clustered by different data curators, and (3) there are data analysts providing computation who also requires proper valuation.
Towards Efficient Data Valuation Based on the Shapley Value
Feb 27, 2019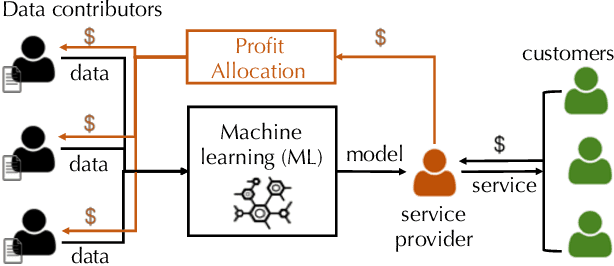

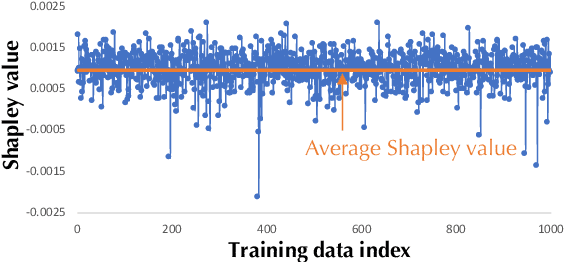
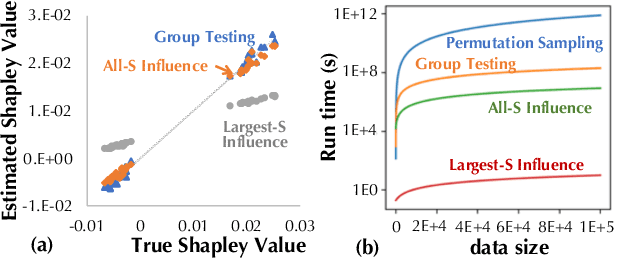
"How much is my data worth?" is an increasingly common question posed by organizations and individuals alike. An answer to this question could allow, for instance, fairly distributing profits among multiple data contributors and determining prospective compensation when data breaches happen. In this paper, we study the problem of data valuation by utilizing the Shapley value, a popular notion of value which originated in coopoerative game theory. The Shapley value defines a unique payoff scheme that satisfies many desiderata for the notion of data value. However, the Shapley value often requires exponential time to compute. To meet this challenge, we propose a repertoire of efficient algorithms for approximating the Shapley value. We also demonstrate the value of each training instance for various benchmark datasets.