 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEALing the Gap: A Reference Framework for LLM Inference Carbon Estimation via Multi-Benchmark Driven Embodiment
Mar 03, 2026Large Language Models are rapidly gaining traction in software engineering, yet their growing carbon footprint raises pressing sustainability concerns. While training emissions are substantial, inference quickly surpasses them due to the sheer volume of prompts processed. This shift underscores the urgent need for accurate, prompt-level carbon measurement during inference to enable informed, sustainability-focused decision-making. To address the limitations of existing approaches, in this paper, we outline the guiding principles for a novel reference framework for LLM inference carbon estimation that can guide the design of future tools and provide a systematic foundation for advancing sustainability research in this domain. We also introduce SEAL, an early embodiment of these principles that leverages a multi-benchmark-driven approach for per-prompt carbon estimation. Its initial validation shows promising results, positioning SEAL as a foundation for standardized sustainability assessment across the LLM ecosystem.
Benchmarking the Energy Savings with Speculative Decoding Strategies
Feb 09, 2026Speculative decoding has emerged as an effective method to reduce latency and inference cost of LLM inferences. However, there has been inadequate attention towards the energy requirements of these models. To address this gap, this paper presents a comprehensive survey of energy requirements of speculative decoding strategies, with detailed analysis on how various factors -- model size and family, speculative decoding strategies, and dataset characteristics -- influence the energy optimizations.
Breaking the ICE: Exploring promises and challenges of benchmarks for Inference Carbon & Energy estimation for LLMs
Jun 10, 2025While Generative AI stands to be one of the fastest adopted technologies ever, studies have made evident that the usage of Large Language Models (LLMs) puts significant burden on energy grids and our environment. It may prove a hindrance to the Sustainability goals of any organization. A crucial step in any Sustainability strategy is monitoring or estimating the energy consumption of various components. While there exist multiple tools for monitoring energy consumption, there is a dearth of tools/frameworks for estimating the consumption or carbon emissions. Current drawbacks of both monitoring and estimation tools include high input data points, intrusive nature, high error margin, etc. We posit that leveraging emerging LLM benchmarks and related data points can help overcome aforementioned challenges while balancing accuracy of the emission estimations. To that extent, we discuss the challenges of current approaches and present our evolving framework, R-ICE, which estimates prompt level inference carbon emissions by leveraging existing state-of-the-art(SOTA) benchmark. This direction provides a more practical and non-intrusive way to enable emerging use-cases like dynamic LLM routing, carbon accounting, etc. Our promising validation results suggest that benchmark-based modelling holds great potential for inference emission estimation and warrants further exploration from the scientific community.
Do Generative AI Tools Ensure Green Code? An Investigative Study
Jun 10, 2025Software sustainability is emerging as a primary concern, aiming to optimize resource utilization, minimize environmental impact, and promote a greener, more resilient digital ecosystem. The sustainability or "greenness" of software is typically determined by the adoption of sustainable coding practices. With a maturing ecosystem around generative AI, many software developers now rely on these tools to generate code using natural language prompts. Despite their potential advantages, there is a significant lack of studies on the sustainability aspects of AI-generated code. Specifically, how environmentally friendly is the AI-generated code based upon its adoption of sustainable coding practices? In this paper, we present the results of an early investigation into the sustainability aspects of AI-generated code across three popular generative AI tools - ChatGPT, BARD, and Copilot. The results highlight the default non-green behavior of tools for generating code, across multiple rules and scenarios. It underscores the need for further in-depth investigations and effective remediation strategies.
Brevity is the soul of sustainability: Characterizing LLM response lengths
Jun 10, 2025



A significant portion of the energy consumed by Large Language Models (LLMs) arises from their inference processes; hence developing energy-efficient methods for inference is crucial. While several techniques exist for inference optimization, output compression remains relatively unexplored, with only a few preliminary efforts addressing this aspect. In this work, we first benchmark 12 decoder-only LLMs across 5 datasets, revealing that these models often produce responses that are substantially longer than necessary. We then conduct a comprehensive quality assessment of LLM responses, formally defining six information categories present in LLM responses. We show that LLMs often tend to include redundant or additional information besides the minimal answer. To address this issue of long responses by LLMs, we explore several simple and intuitive prompt-engineering strategies. Empirical evaluation shows that appropriate prompts targeting length reduction and controlling information content can achieve significant energy optimization between 25-60\% by reducing the response length while preserving the quality of LLM responses.
Metamorphic Testing of a Deep Learning based Forecaster
Jul 13, 2019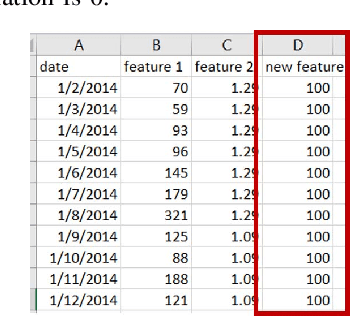
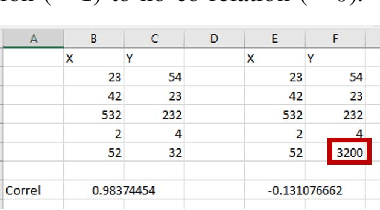
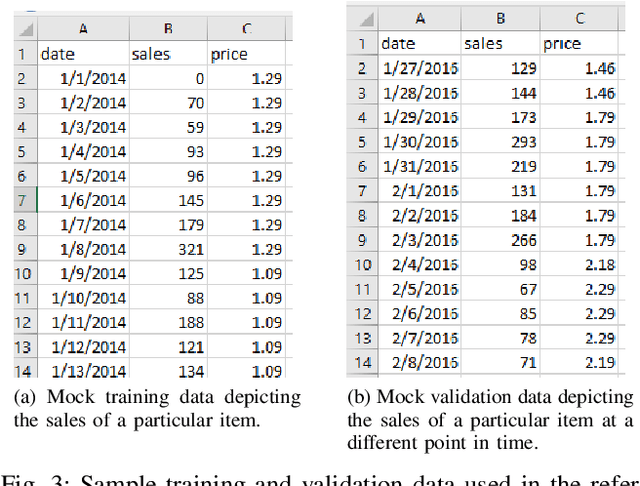
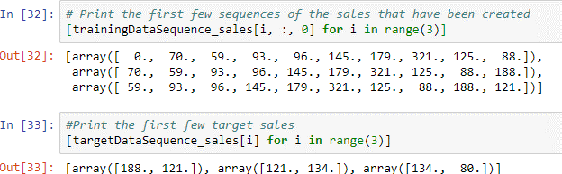
In this paper, we present the Metamorphic Testing of an in-use deep learning based forecasting application. The application looks at the past data of system characteristics (e.g. `memory allocation') to predict outages in the future. We focus on two statistical / machine learning based components - a) detection of co-relation between system characteristics and b) estimating the future value of a system characteristic using an LSTM (a deep learning architecture). In total, 19 Metamorphic Relations have been developed and we provide proofs & algorithms where applicable. We evaluated our method through two settings. In the first, we executed the relations on the actual application and uncovered 8 issues not known before. Second, we generated hypothetical bugs, through Mutation Testing, on a reference implementation of the LSTM based forecaster and found that 65.9% of the bugs were caught through the relations.
Identifying Implementation Bugs in Machine Learning based Image Classifiers using Metamorphic Testing
Aug 16, 2018
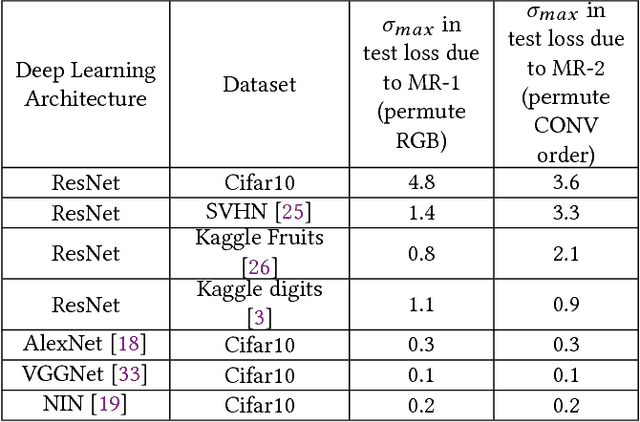

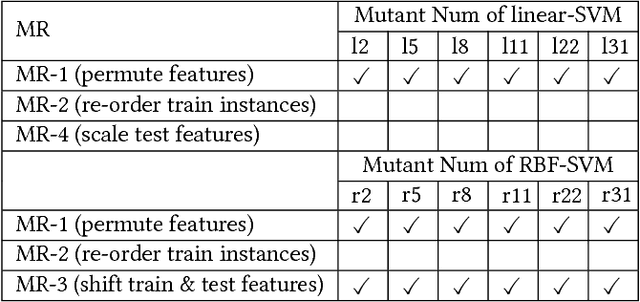
We have recently witnessed tremendous success of Machine Learning (ML) in practical applications. Computer vision, speech recognition and language translation have all seen a near human level performance. We expect, in the near future, most business applications will have some form of ML. However, testing such applications is extremely challenging and would be very expensive if we follow today's methodologies. In this work, we present an articulation of the challenges in testing ML based applications. We then present our solution approach, based on the concept of Metamorphic Testing, which aims to identify implementation bugs in ML based image classifiers. We have developed metamorphic relations for an application based on Support Vector Machine and a Deep Learning based application. Empirical validation showed that our approach was able to catch 71% of the implementation bugs in the ML applications.
A Neural Architecture Mimicking Humans End-to-End for Natural Language Inference
Jan 27, 2017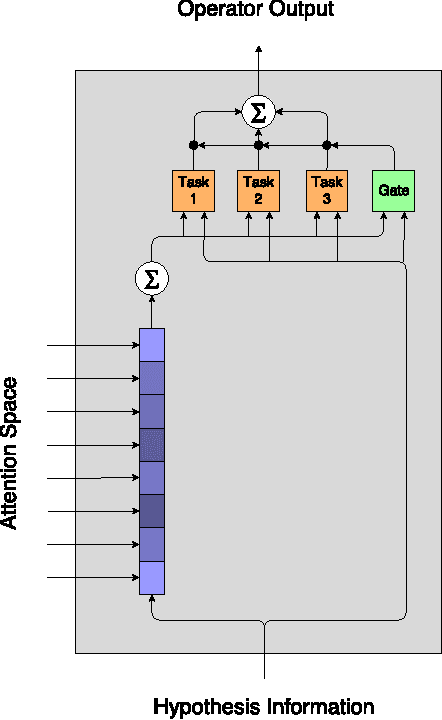
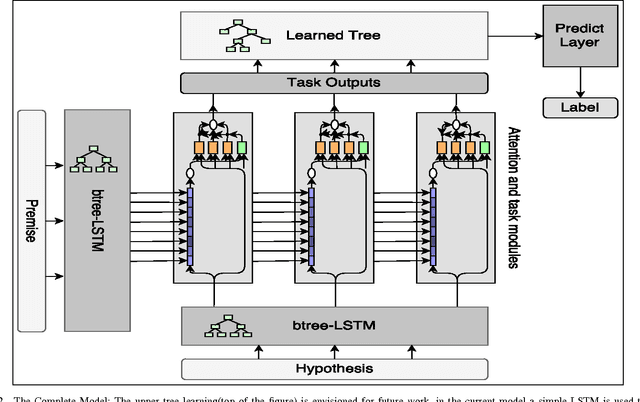

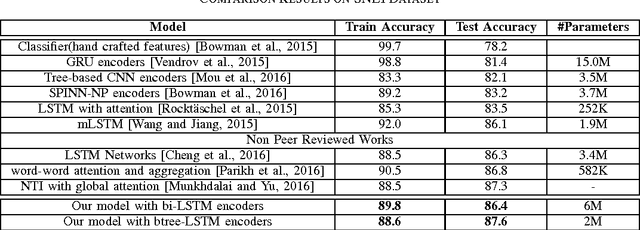
In this work we use the recent advances in representation learning to propose a neural architecture for the problem of natural language inference. Our approach is aligned to mimic how a human does the natural language inference process given two statements. The model uses variants of Long Short Term Memory (LSTM), attention mechanism and composable neural networks, to carry out the task. Each part of our model can be mapped to a clear functionality humans do for carrying out the overall task of natural language inference. The model is end-to-end differentiable enabling training by stochastic gradient descent. On Stanford Natural Language Inference(SNLI) dataset, the proposed model achieves better accuracy numbers than all published models in literature.
Designing Intelligent Automation based Solutions for Complex Social Problems
Jun 16, 2016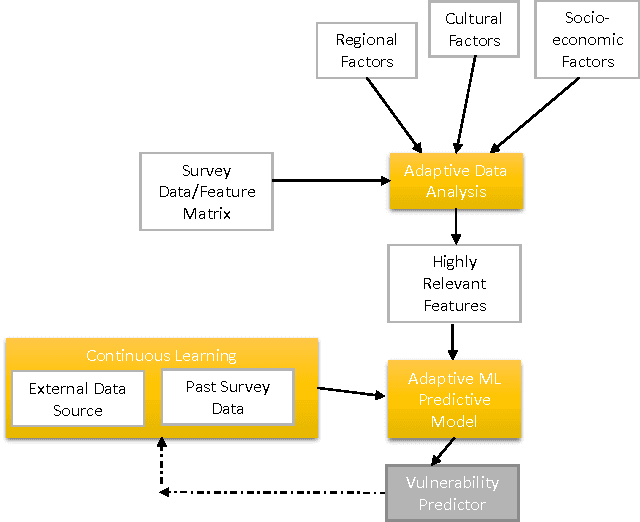

Deciding effective and timely preventive measures against complex social problems affecting relatively low income geographies is a difficult challenge. There is a strong need to adopt intelligent automation based solutions with low cost imprints to tackle these problems at larger scales. Starting with the hypothesis that analytical modelling and analysis of social phenomena with high accuracy is in general inherently hard, in this paper we propose design framework to enable data-driven machine learning based adaptive solution approach towards enabling more effective preventive measures. We use survey data collected from a socio-economically backward region of India about adolescent girls to illustrate the design approach.