 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Inference Approach To Question Answering Over Knowledge Graphs
Dec 21, 2021
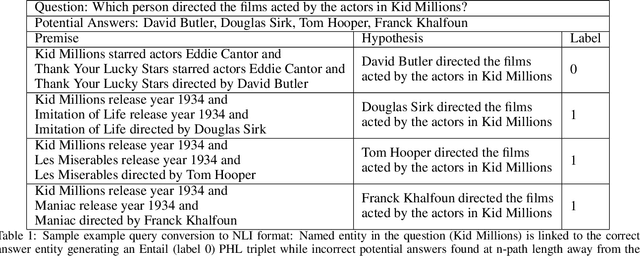
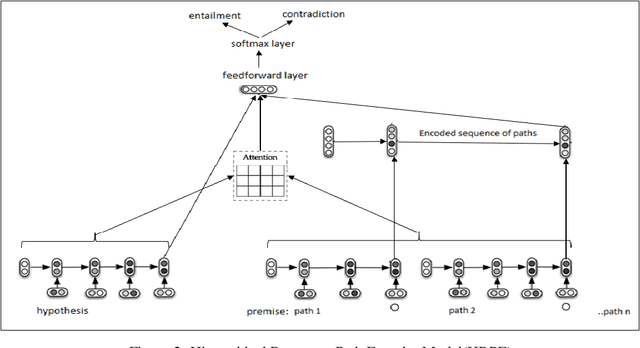
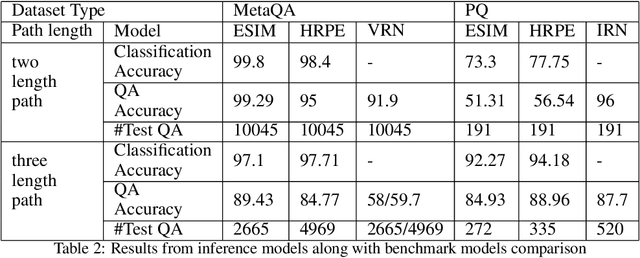
Knowledge Graphs (KG) act as a great tool for holding distilled information from large natural language text corpora. The problem of natural language querying over knowledge graphs is essential for the human consumption of this information. This problem is typically addressed by converting the natural language query to a structured query and then firing the structured query on the KG. Direct answering models over knowledge graphs in literature are very few. The query conversion models and direct models both require specific training data pertaining to the domain of the knowledge graph. In this work, we convert the problem of natural language querying over knowledge graphs to an inference problem over premise-hypothesis pairs. Using trained deep learning models for the converted proxy inferencing problem, we provide the solution for the original natural language querying problem. Our method achieves over 90% accuracy on MetaQA dataset, beating the existing state-of-the-art. We also propose a model for inferencing called Hierarchical Recurrent Path Encoder(HRPE). The inferencing models can be fine-tuned to be used across domains with less training data. Our approach does not require large domain-specific training data for querying on new knowledge graphs from different domains.
ActKnow: Active External Knowledge Infusion Learning for Question Answering in Low Data Regime
Dec 17, 2021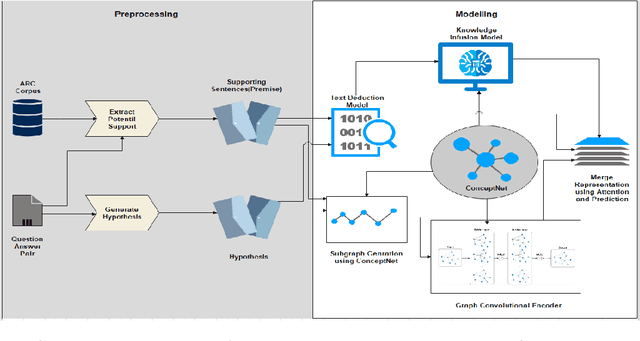
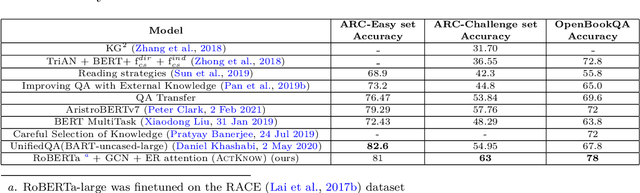
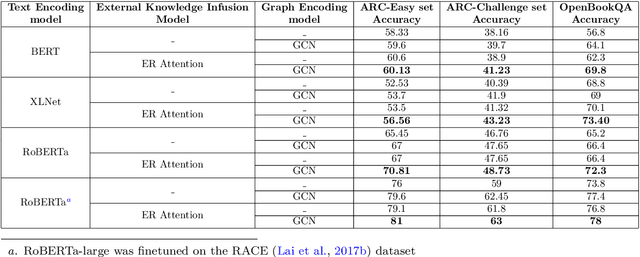
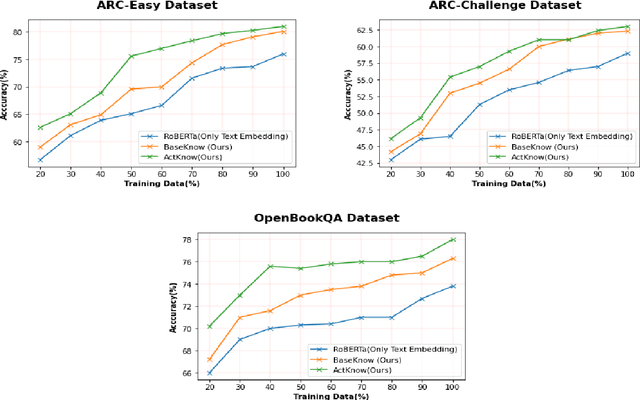
Deep learning models have set benchmark results in various Natural Language Processing tasks. However, these models require an enormous amount of training data, which is infeasible in many practical problems. While various techniques like domain adaptation, fewshot learning techniques address this problem, we introduce a new technique of actively infusing external knowledge into learning to solve low data regime problems. We propose a technique called ActKnow that actively infuses knowledge from Knowledge Graphs (KG) based "on-demand" into learning for Question Answering (QA). By infusing world knowledge from Concept-Net, we show significant improvements on the ARC Challenge-set benchmark over purely text-based transformer models like RoBERTa in the low data regime. For example, by using only 20% training examples, we demonstrate a 4% improvement in the accuracy for both ARC-challenge and OpenBookQA, respectively.
A Neural Architecture Mimicking Humans End-to-End for Natural Language Inference
Jan 27, 2017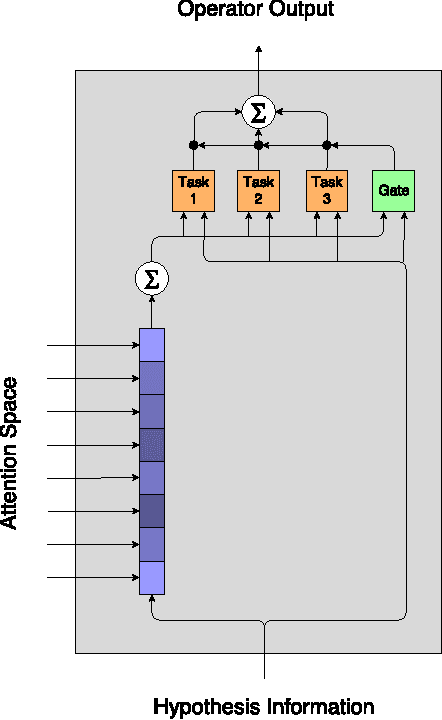
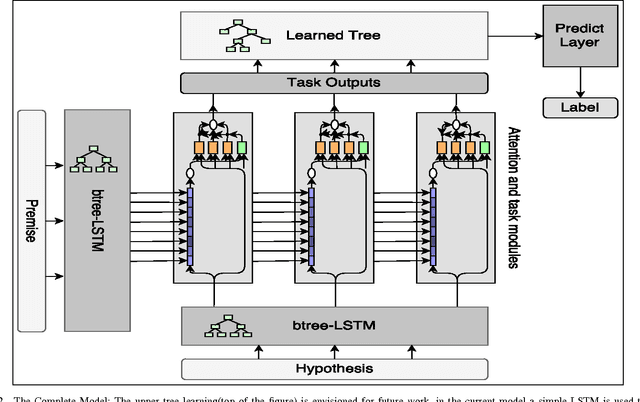

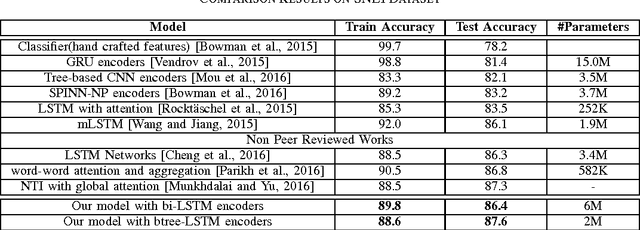
In this work we use the recent advances in representation learning to propose a neural architecture for the problem of natural language inference. Our approach is aligned to mimic how a human does the natural language inference process given two statements. The model uses variants of Long Short Term Memory (LSTM), attention mechanism and composable neural networks, to carry out the task. Each part of our model can be mapped to a clear functionality humans do for carrying out the overall task of natural language inference. The model is end-to-end differentiable enabling training by stochastic gradient descent. On Stanford Natural Language Inference(SNLI) dataset, the proposed model achieves better accuracy numbers than all published models in literature.