 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Trajectory Generation for Goal-Oriented Spacecraft Rendezvous
Dec 11, 2025Reliable real-time trajectory generation is essential for future autonomous spacecraft. While recent progress in nonconvex guidance and control is paving the way for onboard autonomous trajectory optimization, these methods still rely on extensive expert input (e.g., waypoints, constraints, mission timelines, etc.), which limits the operational scalability in real rendezvous missions. This paper introduces SAGES (Semantic Autonomous Guidance Engine for Space), a trajectory-generation framework that translates natural-language commands into spacecraft trajectories that reflect high-level intent while respecting nonconvex constraints. Experiments in two settings -- fault-tolerant proximity operations with continuous-time constraint enforcement and a free-flying robotic platform -- demonstrate that SAGES reliably produces trajectories aligned with human commands, achieving over 90% semantic-behavioral consistency across diverse behavior modes. Ultimately, this work marks an initial step toward language-conditioned, constraint-aware spacecraft trajectory generation, enabling operators to interactively guide both safety and behavior through intuitive natural-language commands with reduced expert burden.
Is this bug severe? A text-cum-graph based model for bug severity prediction
Jul 01, 2022

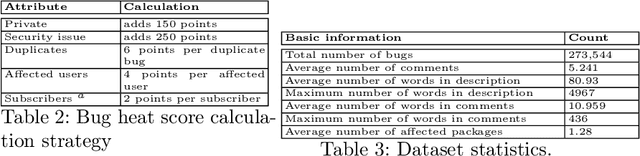
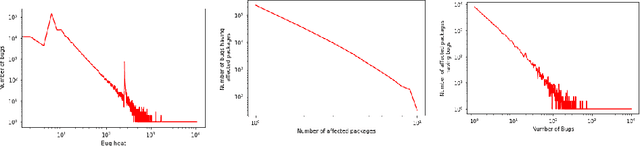
Repositories of large software systems have become commonplace. This massive expansion has resulted in the emergence of various problems in these software platforms including identification of (i) bug-prone packages, (ii) critical bugs, and (iii) severity of bugs. One of the important goals would be to mine these bugs and recommend them to the developers to resolve them. The first step to this is that one has to accurately detect the extent of severity of the bugs. In this paper, we take up this task of predicting the severity of bugs in the near future. Contextualized neural models built on the text description of a bug and the user comments about the bug help to achieve reasonably good performance. Further information on how the bugs are related to each other in terms of the ways they affect packages can be summarised in the form of a graph and used along with the text to get additional benefits.
CORAL: Contextual Response Retrievability Loss Function for Training Dialog Generation Models
May 21, 2022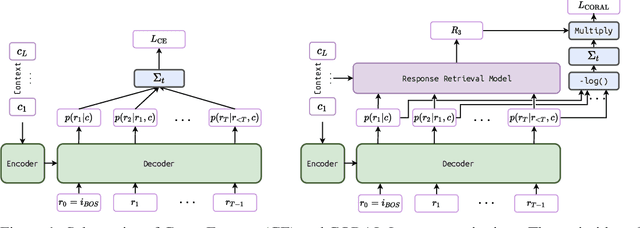

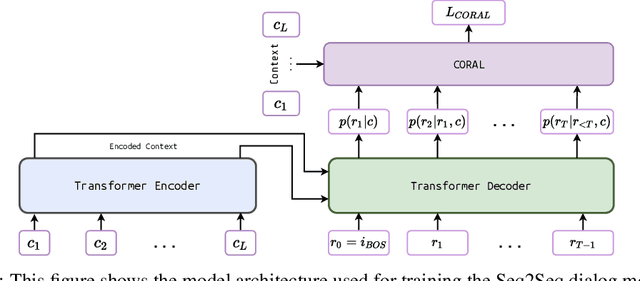
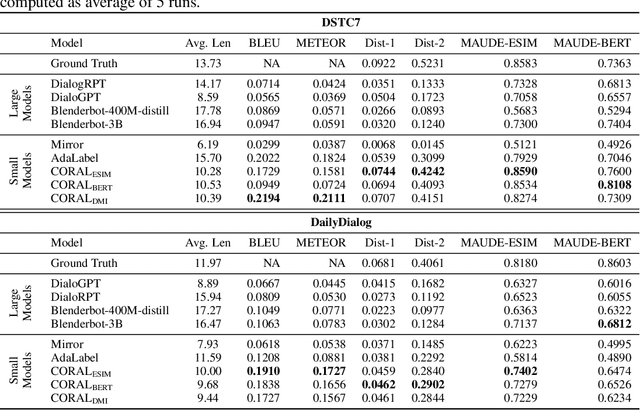
Natural Language Generation (NLG) represents a large collection of tasks in the field of NLP. While many of these tasks have been tackled well by the cross-entropy (CE) loss, the task of dialog generation poses a few unique challenges for this loss function. First, CE loss assumes that for any given input, the only possible output is the one available as the ground truth in the training dataset. In general, this is not true for any task, as there can be multiple semantically equivalent sentences, each with a different surface form. This problem gets exaggerated further for the dialog generation task, as there can be multiple valid responses (for a given context) that not only have different surface forms but are also not semantically equivalent. Second, CE loss does not take the context into consideration while processing the response and, hence, it treats all ground truths with equal importance irrespective of the context. But, we may want our final agent to avoid certain classes of responses (e.g. bland, non-informative or biased responses) and give relatively higher weightage for more context-specific responses. To circumvent these shortcomings of the CE loss, in this paper, we propose a novel loss function, CORAL, that directly optimizes recently proposed estimates of human preference for generated responses. Using CORAL, we can train dialog generation models without assuming non-existence of response other than the ground-truth. Also, the CORAL loss is computed based on both the context and the response. Extensive comparisons on two benchmark datasets show that the proposed methods outperform strong state-of-the-art baseline models of different sizes.