 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtreme Meta-Classification for Large-Scale Zero-Shot Retrieval
Jun 23, 2026We develop accurate and efficient solutions for large-scale retrieval tasks where novel (zero-shot) items can arrive continuously at a rapid pace. Conventional Siamese-style approaches embed both queries and items through a small encoder and retrieve the items lying closest to the query. While this approach allows efficient addition and retrieval of novel items, the small encoder lacks sufficient capacity for the necessary world knowledge in complex retrieval tasks. The extreme classification approaches have addressed this by learning a separate classifier for each item observed in the training set which significantly increases the representation capacity of the model. Such classifiers outperform Siamese approaches on observed items, but cannot be trained for novel items due to data and latency constraints. To bridge these gaps, this paper develops: (1) A new algorithmic framework, EMMETT, which efficiently synthesizes classifiers on-the-fly for novel items, by relying on the readily available classifiers for observed items; (2) A new algorithm, IRENE, which is a simple and effective instance of EMMETT that is specifically suited for large-scale deployments, and (3) A new theoretical framework for analyzing the generalization performance in large-scale zero-shot retrieval which guides our algorithm and training related design decisions. Comprehensive experiments are conducted on a wide range of retrieval tasks which demonstrate that IRENE improves the zero-shot retrieval accuracy by up to 15% points in Recall@10 when added on top of leading encoders. Additionally, on an online A/B test in a large-scale ad retrieval task in a major search engine, IRENE improved the ad click-through rate by 4.2%. Lastly, we validate our design choices through extensive ablative experiments. The source code for IRENE is available at https://aka.ms/irene.
* Accepted at KDD 2024, 20 pages
On the Necessity of World Knowledge for Mitigating Missing Labels in Extreme Classification
Aug 18, 2024Extreme Classification (XC) aims to map a query to the most relevant documents from a very large document set. XC algorithms used in real-world applications learn this mapping from datasets curated from implicit feedback, such as user clicks. However, these datasets inevitably suffer from missing labels. In this work, we observe that systematic missing labels lead to missing knowledge, which is critical for accurately modelling relevance between queries and documents. We formally show that this absence of knowledge cannot be recovered using existing methods such as propensity weighting and data imputation strategies that solely rely on the training dataset. While LLMs provide an attractive solution to augment the missing knowledge, leveraging them in applications with low latency requirements and large document sets is challenging. To incorporate missing knowledge at scale, we propose SKIM (Scalable Knowledge Infusion for Missing Labels), an algorithm that leverages a combination of small LM and abundant unstructured meta-data to effectively mitigate the missing label problem. We show the efficacy of our method on large-scale public datasets through exhaustive unbiased evaluation ranging from human annotations to simulations inspired from industrial settings. SKIM outperforms existing methods on Recall@100 by more than 10 absolute points. Additionally, SKIM scales to proprietary query-ad retrieval datasets containing 10 million documents, outperforming contemporary methods by 12% in offline evaluation and increased ad click-yield by 1.23% in an online A/B test conducted on a popular search engine. We release our code, prompts, trained XC models and finetuned SLMs at: https://github.com/bicycleman15/skim
DSFormer: Effective Compression of Text-Transformers by Dense-Sparse Weight Factorization
Dec 20, 2023With the tremendous success of large transformer models in natural language understanding, down-sizing them for cost-effective deployments has become critical. Recent studies have explored the low-rank weight factorization techniques which are efficient to train, and apply out-of-the-box to any transformer architecture. Unfortunately, the low-rank assumption tends to be over-restrictive and hinders the expressiveness of the compressed model. This paper proposes, DSFormer, a simple alternative factorization scheme which expresses a target weight matrix as the product of a small dense and a semi-structured sparse matrix. The resulting approximation is more faithful to the weight distribution in transformers and therefore achieves a stronger efficiency-accuracy trade-off. Another concern with existing factorizers is their dependence on a task-unaware initialization step which degrades the accuracy of the resulting model. DSFormer addresses this issue through a novel Straight-Through Factorizer (STF) algorithm that jointly learns all the weight factorizations to directly maximize the final task accuracy. Extensive experiments on multiple natural language understanding benchmarks demonstrate that DSFormer obtains up to 40% better compression than the state-of-the-art low-rank factorizers, leading semi-structured sparsity baselines and popular knowledge distillation approaches. Our approach is also orthogonal to mainstream compressors and offers up to 50% additional compression when added to popular distilled, layer-shared and quantized transformers. We empirically evaluate the benefits of STF over conventional optimization practices.
Extreme Regression for Dynamic Search Advertising
Jan 20, 2020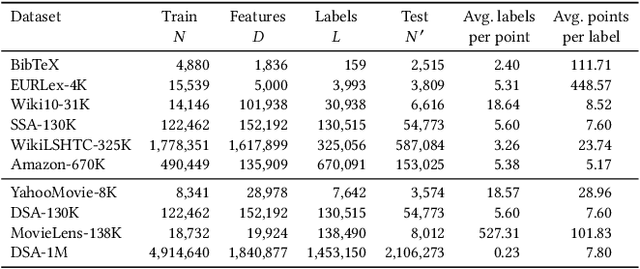
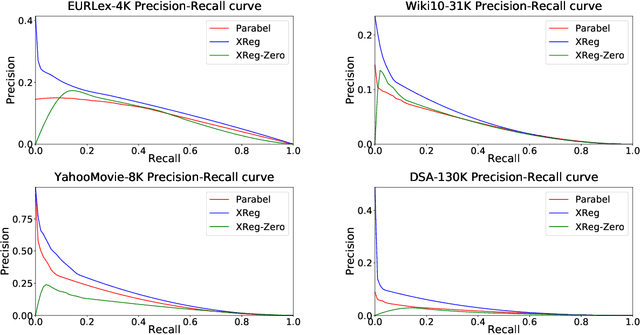
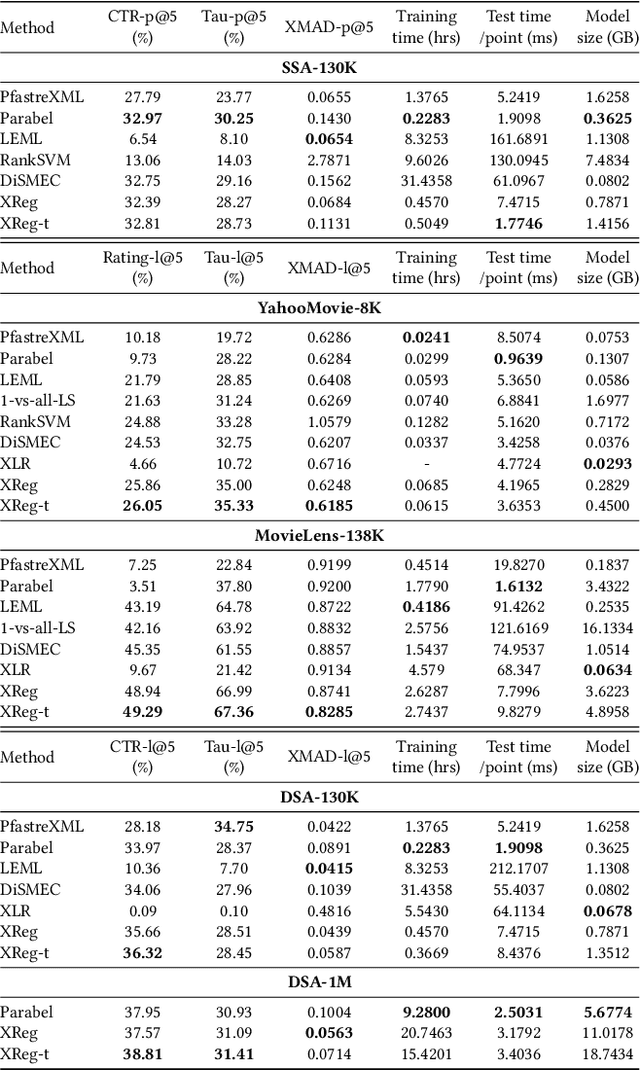
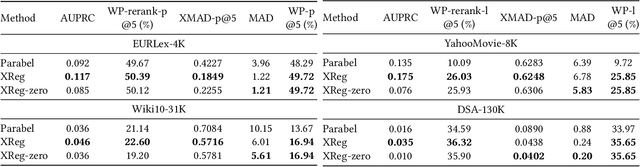
This paper introduces a new learning paradigm called eXtreme Regression (XR) whose objective is to accurately predict the numerical degrees of relevance of an extremely large number of labels to a data point. XR can provide elegant solutions to many large-scale ranking and recommendation applications including Dynamic Search Advertising (DSA). XR can learn more accurate models than the recently popular extreme classifiers which incorrectly assume strictly binary-valued label relevances. Traditional regression metrics which sum the errors over all the labels are unsuitable for XR problems since they could give extremely loose bounds for the label ranking quality. Also, the existing regression algorithms won't efficiently scale to millions of labels. This paper addresses these limitations through: (1) new evaluation metrics for XR which sum only the k largest regression errors; (2) a new algorithm called XReg which decomposes XR task into a hierarchy of much smaller regression problems thus leading to highly efficient training and prediction. This paper also introduces a (3) new labelwise prediction algorithm in XReg useful for DSA and other recommendation tasks. Experiments on benchmark datasets demonstrated that XReg can outperform the state-of-the-art extreme classifiers as well as large-scale regressors and rankers by up to 50% reduction in the new XR error metric, and up to 2% and 2.4% improvements in terms of the propensity-scored precision metric used in extreme classification and the click-through rate metric used in DSA respectively. Deployment of XReg on DSA in Bing resulted in a relative gain of 27% in query coverage. XReg's source code can be downloaded from http://manikvarma.org/code/XReg/download.html.