 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Debiased MDI Feature Importance Measure for Random Forests
Jun 26, 2019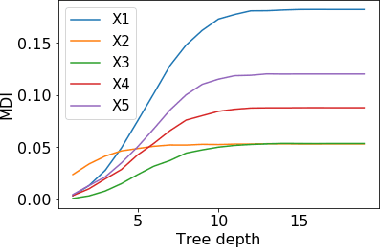
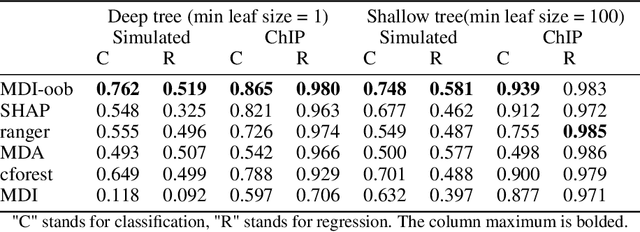
Tree ensembles such as Random Forests have achieved impressive empirical success across a wide variety of applications. To understand how these models make predictions, people routinely turn to feature importance measures calculated from tree ensembles. It has long been known that Mean Decrease Impurity (MDI), one of the most widely used measures of feature importance, incorrectly assigns high importance to noisy features, leading to systematic bias in feature selection. In this paper, we address the feature selection bias of MDI from both theoretical and methodological perspectives. Based on the original definition of MDI by Breiman et al. for a single tree, we derive a tight non-asymptotic bound on the expected bias of MDI importance of noisy features, showing that deep trees have higher (expected) feature selection bias than shallow ones. However, it is not clear how to reduce the bias of MDI using its existing analytical expression. We derive a new analytical expression for MDI, and based on this new expression, we are able to propose a debiased MDI feature importance measure using out-of-bag samples, called MDI-oob. For both the simulated data and a genomic ChIP dataset, MDI-oob achieves state-of-the-art performance in feature selection from Random Forests for both deep and shallow trees.
CharBot: A Simple and Effective Method for Evading DGA Classifiers
May 30, 2019
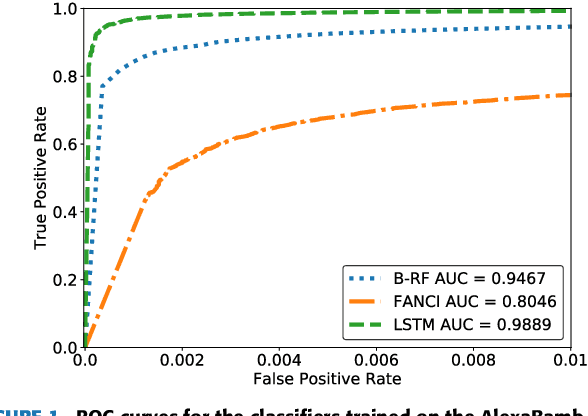

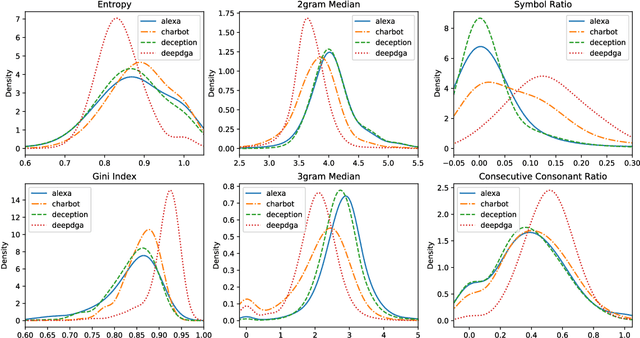
Domain generation algorithms (DGAs) are commonly leveraged by malware to create lists of domain names which can be used for command and control (C&C) purposes. Approaches based on machine learning have recently been developed to automatically detect generated domain names in real-time. In this work, we present a novel DGA called CharBot which is capable of producing large numbers of unregistered domain names that are not detected by state-of-the-art classifiers for real-time detection of DGAs, including the recently published methods FANCI (a random forest based on human-engineered features) and LSTM.MI (a deep learning approach). CharBot is very simple, effective and requires no knowledge of the targeted DGA classifiers. We show that retraining the classifiers on CharBot samples is not a viable defense strategy. We believe these findings show that DGA classifiers are inherently vulnerable to adversarial attacks if they rely only on the domain name string to make a decision. Designing a robust DGA classifier may, therefore, necessitate the use of additional information besides the domain name alone. To the best of our knowledge, CharBot is the simplest and most efficient black-box adversarial attack against DGA classifiers proposed to date.
Fast mixing of Metropolized Hamiltonian Monte Carlo: Benefits of multi-step gradients
May 29, 2019
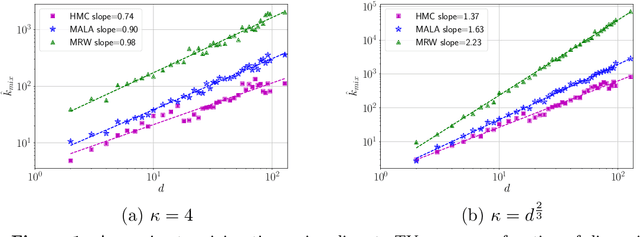


Hamiltonian Monte Carlo (HMC) is a state-of-the-art Markov chain Monte Carlo sampling algorithm for drawing samples from smooth probability densities over continuous spaces. We study the variant most widely used in practice, Metropolized HMC with the St\"{o}rmer-Verlet or leapfrog integrator, and make two primary contributions. First, we provide a non-asymptotic upper bound on the mixing time of the Metropolized HMC with explicit choices of stepsize and number of leapfrog steps. This bound gives a precise quantification of the faster convergence of Metropolized HMC relative to simpler MCMC algorithms such as the Metropolized random walk, or Metropolized Langevin algorithm. Second, we provide a general framework for sharpening mixing time bounds Markov chains initialized at a substantial distance from the target distribution over continuous spaces. We apply this sharpening device to the Metropolized random walk and Langevin algorithms, thereby obtaining improved mixing time bounds from a non-warm initial distribution.
Disentangled Attribution Curves for Interpreting Random Forests and Boosted Trees
May 18, 2019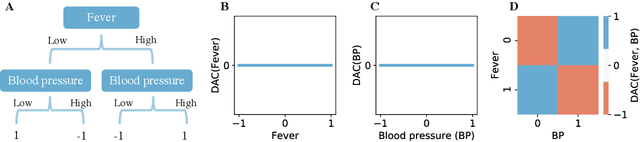
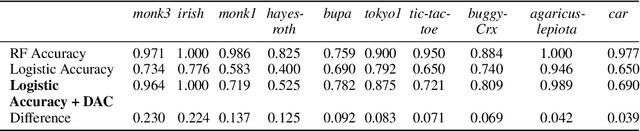


Tree ensembles, such as random forests and AdaBoost, are ubiquitous machine learning models known for achieving strong predictive performance across a wide variety of domains. However, this strong performance comes at the cost of interpretability (i.e. users are unable to understand the relationships a trained random forest has learned and why it is making its predictions). In particular, it is challenging to understand how the contribution of a particular feature, or group of features, varies as their value changes. To address this, we introduce Disentangled Attribution Curves (DAC), a method to provide interpretations of tree ensemble methods in the form of (multivariate) feature importance curves. For a given variable, or group of variables, DAC plots the importance of a variable(s) as their value changes. We validate DAC on real data by showing that the curves can be used to increase the accuracy of logistic regression while maintaining interpretability, by including DAC as an additional feature. In simulation studies, DAC is shown to out-perform competing methods in the recovery of conditional expectations. Finally, through a case-study on the bike-sharing dataset, we demonstrate the use of DAC to uncover novel insights into a dataset.
Unique Sharp Local Minimum in $\ell_1$-minimization Complete Dictionary Learning
Feb 22, 2019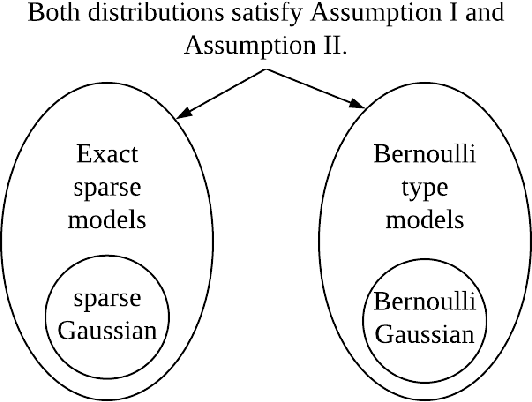
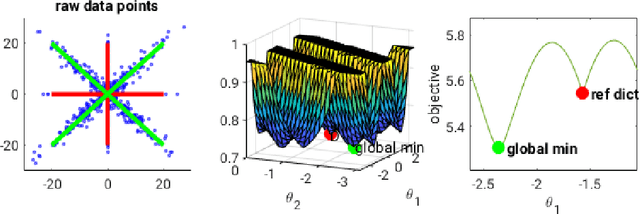
We study the problem of globally recovering a dictionary from a set of signals via $\ell_1$-minimization. We assume that the signals are generated as i.i.d. random linear combinations of the $K$ atoms from a complete reference dictionary $D^*\in \mathbb R^{K\times K}$, where the linear combination coefficients are from either a Bernoulli type model or exact sparse model. First, we obtain a necessary and sufficient norm condition for the reference dictionary $D^*$ to be a sharp local minimum of the expected $\ell_1$ objective function. Our result substantially extends that of Wu and Yu (2015) and allows the combination coefficient to be non-negative. Secondly, we obtain an explicit bound on the region within which the objective value of the reference dictionary is minimal. Thirdly, we show that the reference dictionary is the unique sharp local minimum, thus establishing the first known global property of $\ell_1$-minimization dictionary learning. Motivated by the theoretical results, we introduce a perturbation-based test to determine whether a dictionary is a sharp local minimum of the objective function. In addition, we also propose a new dictionary learning algorithm based on Block Coordinate Descent, called DL-BCD, which is guaranteed to have monotonic convergence. Simulation studies show that DL-BCD has competitive performance in terms of recovery rate compared to many state-of-the-art dictionary learning algorithms.
Challenges with EM in application to weakly identifiable mixture models
Feb 01, 2019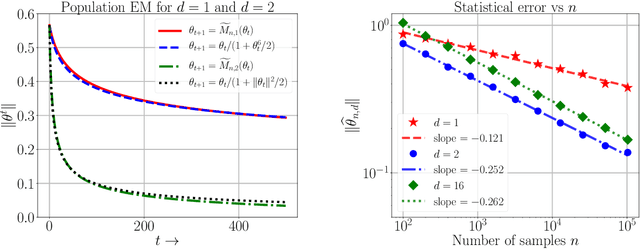

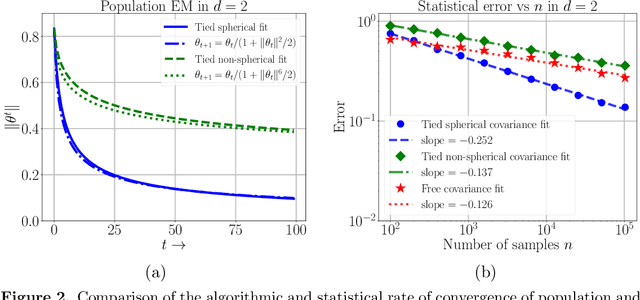
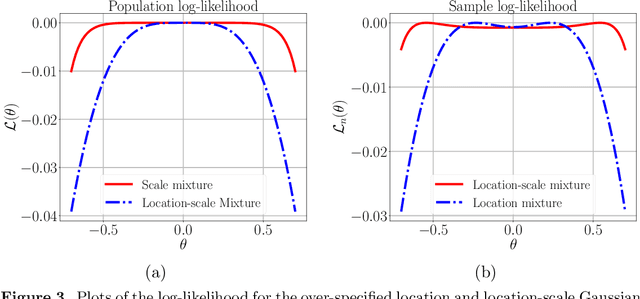
We study a class of weakly identifiable location-scale mixture models for which the maximum likelihood estimates based on $n$ i.i.d. samples are known to have lower accuracy than the classical $n^{- \frac{1}{2}}$ error. We investigate whether the Expectation-Maximization (EM) algorithm also converges slowly for these models. We first demonstrate via simulation studies a broad range of over-specified mixture models for which the EM algorithm converges very slowly, both in one and higher dimensions. We provide a complete analytical characterization of this behavior for fitting data generated from a multivariate standard normal distribution using two-component Gaussian mixture with varying location and scale parameters. Our results reveal distinct regimes in the convergence behavior of EM as a function of the dimension $d$. In the multivariate setting ($d \geq 2$), when the covariance matrix is constrained to a multiple of the identity matrix, the EM algorithm converges in order $(n/d)^{\frac{1}{2}}$ steps and returns estimates that are at a Euclidean distance of order ${(n/d)^{-\frac{1}{4}}}$ and ${ (n d)^{- \frac{1}{2}}}$ from the true location and scale parameter respectively. On the other hand, in the univariate setting ($d = 1$), the EM algorithm converges in order $n^{\frac{3}{4} }$ steps and returns estimates that are at a Euclidean distance of order ${ n^{- \frac{1}{8}}}$ and ${ n^{-\frac{1} {4}}}$ from the true location and scale parameter respectively. Establishing the slow rates in the univariate setting requires a novel localization argument with two stages, with each stage involving an epoch-based argument applied to a different surrogate EM operator at the population level. We also show multivariate ($d \geq 2$) examples, involving more general covariance matrices, that exhibit the same slow rates as the univariate case.
Three principles of data science: predictability, computability, and stability (PCS)
Jan 23, 2019
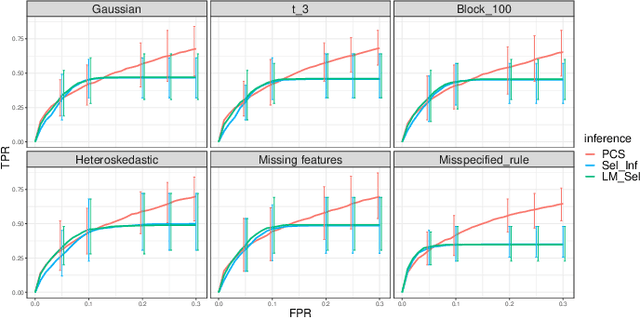
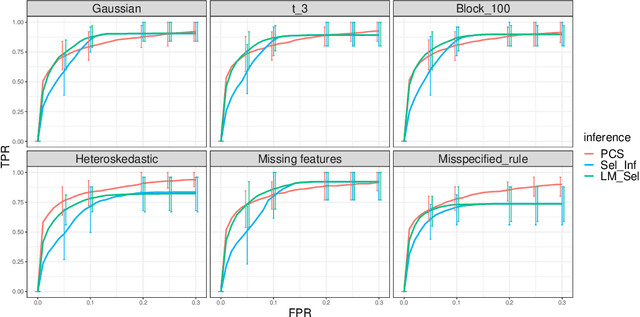
We propose the predictability, computability, and stability (PCS) framework to extract reproducible knowledge from data that can guide scientific hypothesis generation and experimental design. The PCS framework builds on key ideas in machine learning, using predictability as a reality check and evaluating computational considerations in data collection, data storage, and algorithm design. It augments PC with an overarching stability principle, which largely expands traditional statistical uncertainty considerations. In particular, stability assesses how results vary with respect to choices (or perturbations) made across the data science life cycle, including problem formulation, pre-processing, modeling (data and algorithm perturbations), and exploratory data analysis (EDA) before and after modeling. Furthermore, we develop PCS inference to investigate the stability of data results and identify when models are consistent with relatively simple phenomena. We compare PCS inference with existing methods, such as selective inference, in high-dimensional sparse linear model simulations to demonstrate that our methods consistently outperform others in terms of ROC curves over a wide range of simulation settings. Finally, we propose a PCS documentation based on Rmarkdown, iPython, or Jupyter Notebook, with publicly available, reproducible codes and narratives to back up human choices made throughout an analysis. The PCS workflow and documentation are demonstrated in a genomics case study available on Zenodo.
Interpretable machine learning: definitions, methods, and applications
Jan 14, 2019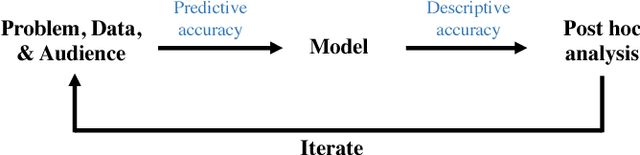
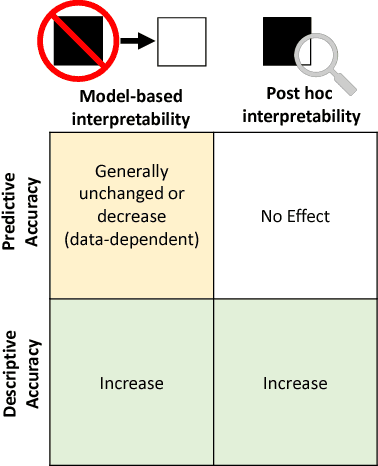
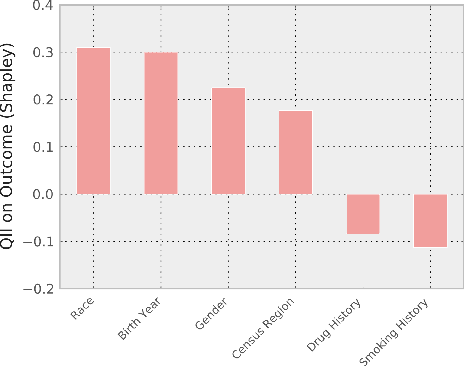
Machine-learning models have demonstrated great success in learning complex patterns that enable them to make predictions about unobserved data. In addition to using models for prediction, the ability to interpret what a model has learned is receiving an increasing amount of attention. However, this increased focus has led to considerable confusion about the notion of interpretability. In particular, it is unclear how the wide array of proposed interpretation methods are related, and what common concepts can be used to evaluate them. We aim to address these concerns by defining interpretability in the context of machine learning and introducing the Predictive, Descriptive, Relevant (PDR) framework for discussing interpretations. The PDR framework provides three overarching desiderata for evaluation: predictive accuracy, descriptive accuracy and relevancy, with relevancy judged relative to a human audience. Moreover, to help manage the deluge of interpretation methods, we introduce a categorization of existing techniques into model-based and post-hoc categories, with sub-groups including sparsity, modularity and simulatability. To demonstrate how practitioners can use the PDR framework to evaluate and understand interpretations, we provide numerous real-world examples. These examples highlight the often under-appreciated role played by human audiences in discussions of interpretability. Finally, based on our framework, we discuss limitations of existing methods and directions for future work. We hope that this work will provide a common vocabulary that will make it easier for both practitioners and researchers to discuss and choose from the full range of interpretation methods.
Mobile Robot Localisation and Navigation Using LEGO NXT and Ultrasonic Sensor
Oct 20, 2018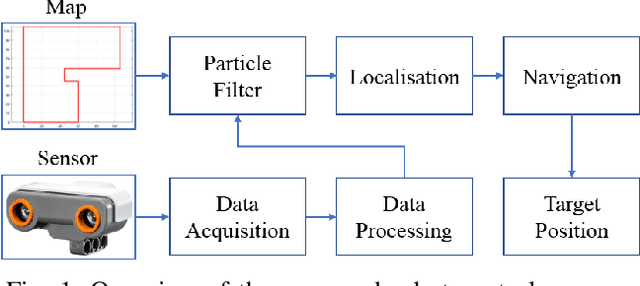

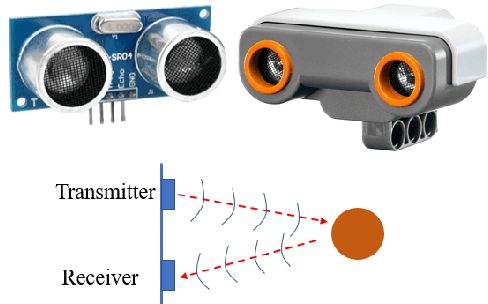
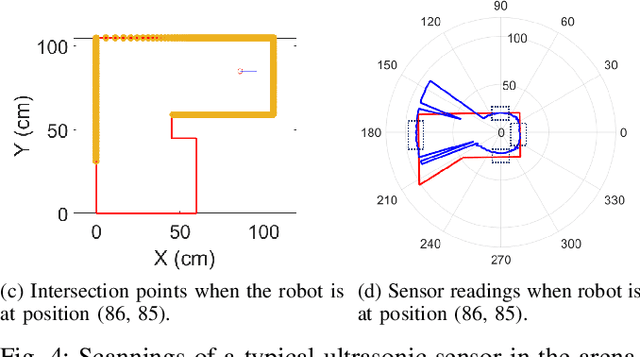
Mobile robots are becoming increasingly important both for individuals and industries. Mobile robotic technology is not only utilised by experts in this field but is also very popular among amateurs. However, implementing a mobile robot to perform tasks autonomously can be expensive because of the need for various types of sensors and the high price of robot platforms. Hence, in this paper we present a mobile robot localisation and navigation system which uses a LEGO ultrasonic sensor in an indoor map based on the LEGO MINDSTORM NXT. This provides an affordable and ready-to-use option for most robot fans. In this paper, an effective method is proposed to extract useful information from the distorted readings collected by the ultrasonic sensor. Then, the particle filter is used to localise the robot. After robot's position is estimated, a sampling-based path planning method is proposed for the robot navigation. This method reduces the robot accumulative motion error by minimising robot turning times and covering distances. The robot localisation and navigation algorithms are implemented in MATLAB. Simulation results show an average accuracy between 1 and 3 cm for three different indoor map locations. Furthermore, experiments performed in a real setup show the effectiveness of the proposed methods.
Refining interaction search through signed iterative Random Forests
Oct 16, 2018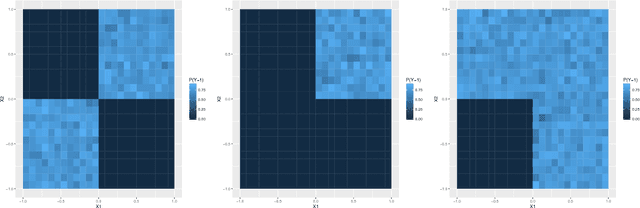
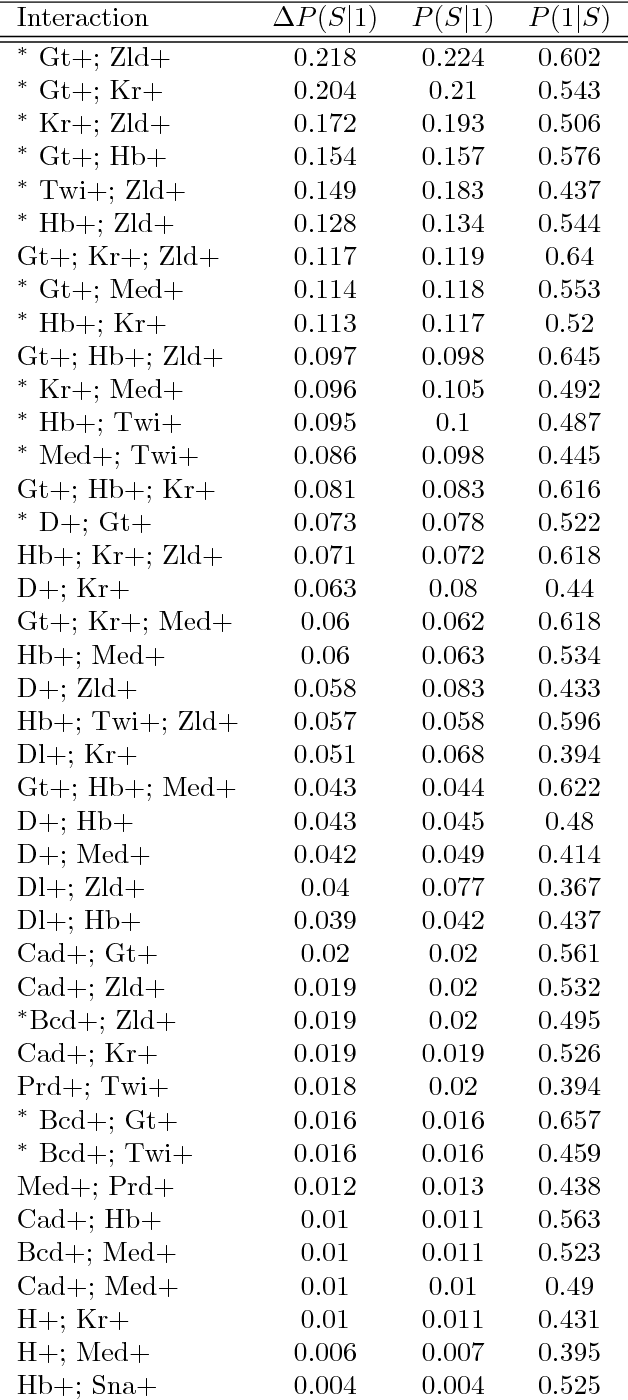
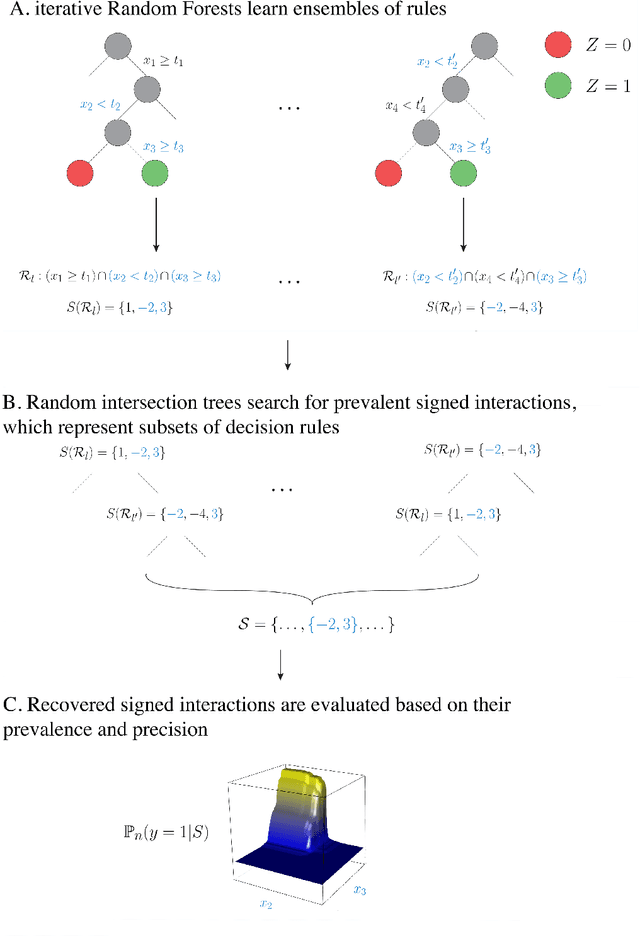
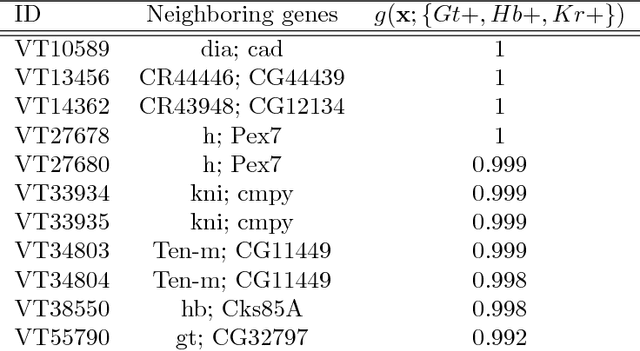
Advances in supervised learning have enabled accurate prediction in biological systems governed by complex interactions among biomolecules. However, state-of-the-art predictive algorithms are typically black-boxes, learning statistical interactions that are difficult to translate into testable hypotheses. The iterative Random Forest algorithm took a step towards bridging this gap by providing a computationally tractable procedure to identify the stable, high-order feature interactions that drive the predictive accuracy of Random Forests (RF). Here we refine the interactions identified by iRF to explicitly map responses as a function of interacting features. Our method, signed iRF, describes subsets of rules that frequently occur on RF decision paths. We refer to these rule subsets as signed interactions. Signed interactions share not only the same set of interacting features but also exhibit similar thresholding behavior, and thus describe a consistent functional relationship between interacting features and responses. We describe stable and predictive importance metrics to rank signed interactions. For each SPIM, we define null importance metrics that characterize its expected behavior under known structure. We evaluate our proposed approach in biologically inspired simulations and two case studies: predicting enhancer activity and spatial gene expression patterns. In the case of enhancer activity, s-iRF recovers one of the few experimentally validated high-order interactions and suggests novel enhancer elements where this interaction may be active. In the case of spatial gene expression patterns, s-iRF recovers all 11 reported links in the gap gene network. By refining the process of interaction recovery, our approach has the potential to guide mechanistic inquiry into systems whose scale and complexity is beyond human comprehension.