 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCerebrovascular morphology in aging and disease -- imaging biomarkers for ischemic stroke and Alzheimers disease
Feb 14, 2022Background and Purpose: Altered brain vasculature is a key phenomenon in several neurologic disorders. This paper presents a quantitative assessment of vascular morphology in healthy and diseased adults including changes during aging and the anatomical variations in the Circle of Willis (CoW). Methods: We used our automatic method to segment and extract novel geometric features of the cerebral vasculature from MRA scans of 175 healthy subjects, 45 AIS, and 50 AD patients after spatial registration. This is followed by quantification and statistical analysis of vascular alterations in acute ischemic stroke (AIS) and Alzheimer's disease (AD), the biggest cerebrovascular and neurodegenerative disorders. Results: We determined that the CoW is fully formed in only 35 percent of healthy adults and found significantly increased tortuosity and fractality, with increasing age and with disease -- both AIS and AD. We also found significantly decreased vessel length, volume and number of branches in AIS patients. Lastly, we found that AD cerebral vessels exhibited significantly smaller diameter and more complex branching patterns, compared to age-matched healthy adults. These changes were significantly heightened with progression of AD from early onset to moderate-severe dementia. Conclusion: Altered vessel geometry in AIS patients shows that there is pathological morphology coupled with stroke. In AD due to pathological alterations in the endothelium or amyloid depositions leading to neuronal damage and hypoperfusion, vessel geometry is significantly altered even in mild or early dementia. The specific geometric features and quantitative comparisons demonstrate potential for using vascular morphology as a non-invasive imaging biomarker for neurologic disorders.
Structural Beauty: A Structure-based Approach to Quantifying the Beauty of an Image
Apr 16, 2021
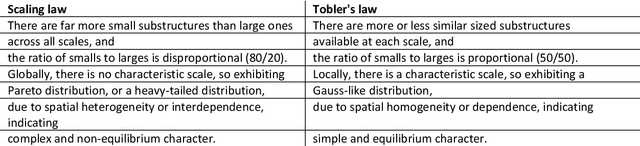
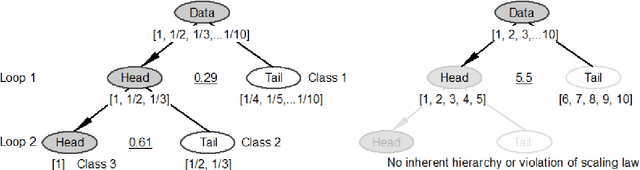

To say that beauty is in the eye of the beholder means that beauty is largely subjective so varies from person to person. While the subjectivity view is commonly held, there is also an objectivity view that seeks to measure beauty or aesthetics in some quantitative manners. Christopher Alexander has long discovered that beauty or coherence highly correlates to the number of subsymmetries or substructures and demonstrated that there is a shared notion of beauty - structural beauty - among people and even different peoples, regardless of their faiths, cultures, and ethnicities. This notion of structural beauty arises directly out of living structure or wholeness, a physical and mathematical structure that underlies all space and matter. Based on the concept of living structure, this paper develops an approach for computing the structural beauty or life of an image (L) based on the number of automatically derived substructures (S) and their inherent hierarchy (H). To verify this approach, we conducted a series of case studies applied to eight pairs of images including Leonardo da Vinci's Mona Lisa and Jackson Pollock's Blue Poles. We discovered among others that Blue Poles is more structurally beautiful than the Mona Lisa, and traditional buildings are in general more structurally beautiful than their modernist counterparts. This finding implies that goodness of things or images is largely a matter of fact rather than an opinion or personal preference as conventionally conceived. The research on structural beauty has deep implications on many disciplines, where beauty or aesthetics is a major concern such as image understanding and computer vision, architecture and urban design, humanities and arts, neurophysiology, and psychology. Keywords: Life; wholeness; figural goodness; head/tail breaks; computer vision
Learning content and context with language bias for Visual Question Answering
Dec 21, 2020
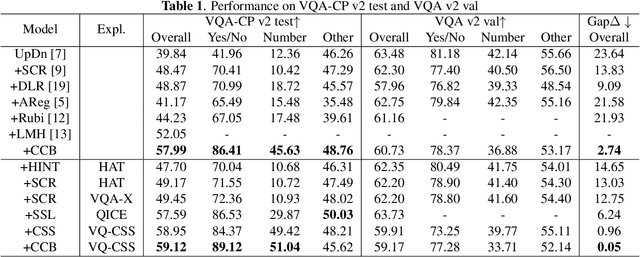
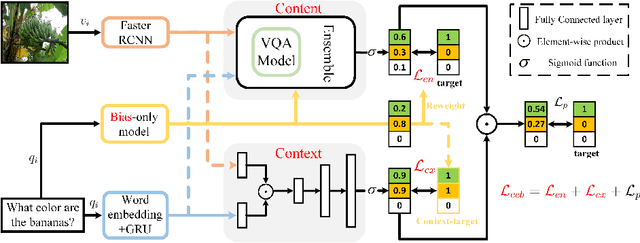

Visual Question Answering (VQA) is a challenging multimodal task to answer questions about an image. Many works concentrate on how to reduce language bias which makes models answer questions ignoring visual content and language context. However, reducing language bias also weakens the ability of VQA models to learn context prior. To address this issue, we propose a novel learning strategy named CCB, which forces VQA models to answer questions relying on Content and Context with language Bias. Specifically, CCB establishes Content and Context branches on top of a base VQA model and forces them to focus on local key content and global effective context respectively. Moreover, a joint loss function is proposed to reduce the importance of biased samples and retain their beneficial influence on answering questions. Experiments show that CCB outperforms the state-of-the-art methods in terms of accuracy on VQA-CP v2.
PPGN: Phrase-Guided Proposal Generation Network For Referring Expression Comprehension
Dec 20, 2020
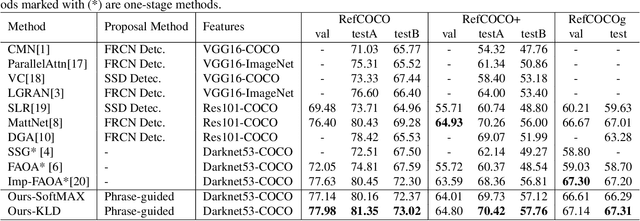
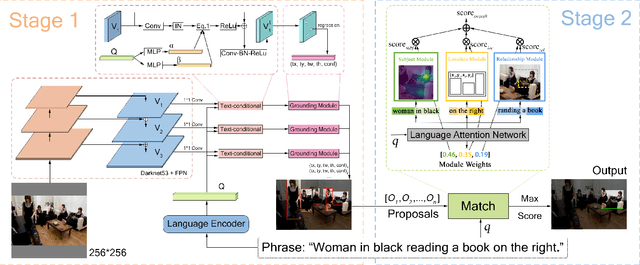
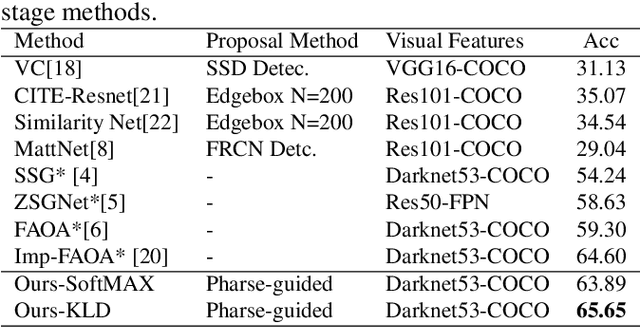
Reference expression comprehension (REC) aims to find the location that the phrase refer to in a given image. Proposal generation and proposal representation are two effective techniques in many two-stage REC methods. However, most of the existing works only focus on proposal representation and neglect the importance of proposal generation. As a result, the low-quality proposals generated by these methods become the performance bottleneck in REC tasks. In this paper, we reconsider the problem of proposal generation, and propose a novel phrase-guided proposal generation network (PPGN). The main implementation principle of PPGN is refining visual features with text and generate proposals through regression. Experiments show that our method is effective and achieve SOTA performance in benchmark datasets.
Rethinking Image Inpainting via a Mutual Encoder-Decoder with Feature Equalizations
Jul 14, 2020
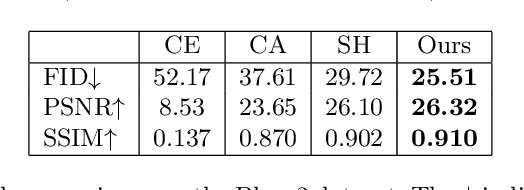
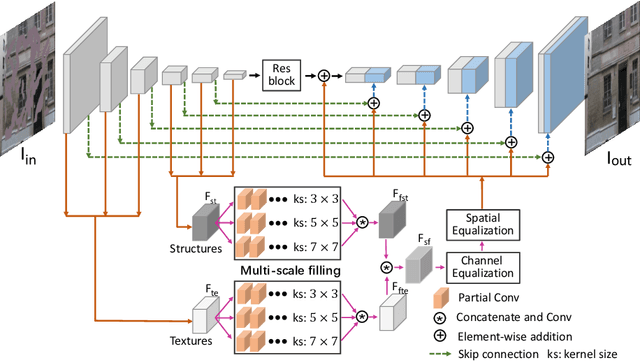
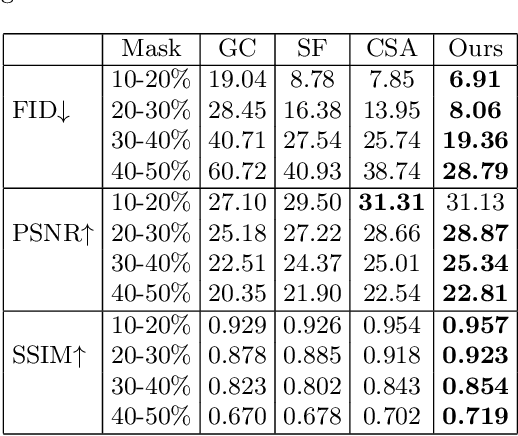
Deep encoder-decoder based CNNs have advanced image inpainting methods for hole filling. While existing methods recover structures and textures step-by-step in the hole regions, they typically use two encoder-decoders for separate recovery. The CNN features of each encoder are learned to capture either missing structures or textures without considering them as a whole. The insufficient utilization of these encoder features limit the performance of recovering both structures and textures. In this paper, we propose a mutual encoder-decoder CNN for joint recovery of both. We use CNN features from the deep and shallow layers of the encoder to represent structures and textures of an input image, respectively. The deep layer features are sent to a structure branch and the shallow layer features are sent to a texture branch. In each branch, we fill holes in multiple scales of the CNN features. The filled CNN features from both branches are concatenated and then equalized. During feature equalization, we reweigh channel attentions first and propose a bilateral propagation activation function to enable spatial equalization. To this end, the filled CNN features of structure and texture mutually benefit each other to represent image content at all feature levels. We use the equalized feature to supplement decoder features for output image generation through skip connections. Experiments on the benchmark datasets show the proposed method is effective to recover structures and textures and performs favorably against state-of-the-art approaches.
Regularized L21-Based Semi-NonNegative Matrix Factorization
May 10, 2020
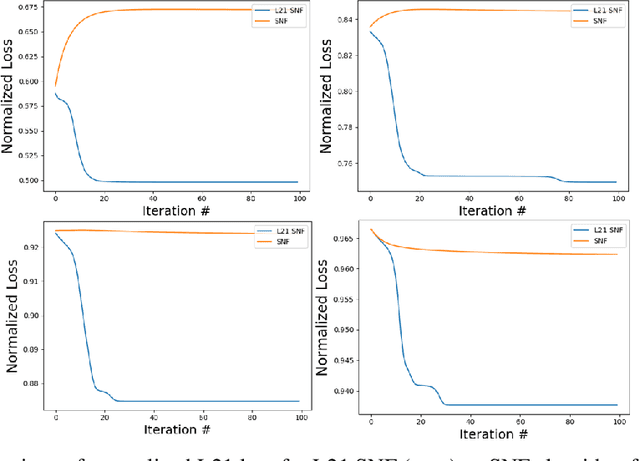

We present a general-purpose data compression algorithm, Regularized L21 Semi-NonNegative Matrix Factorization (L21 SNF). L21 SNF provides robust, parts-based compression applicable to mixed-sign data for which high fidelity, individualdata point reconstruction is paramount. We derive a rigorous proof of convergenceof our algorithm. Through experiments, we show the use-case advantages presentedby L21 SNF, including application to the compression of highly overdeterminedsystems encountered broadly across many general machine learning processes.
One-Stage Inpainting with Bilateral Attention and Pyramid Filling Block
Dec 18, 2019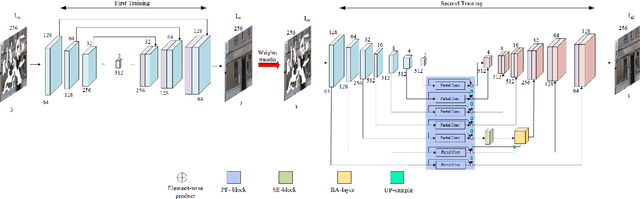
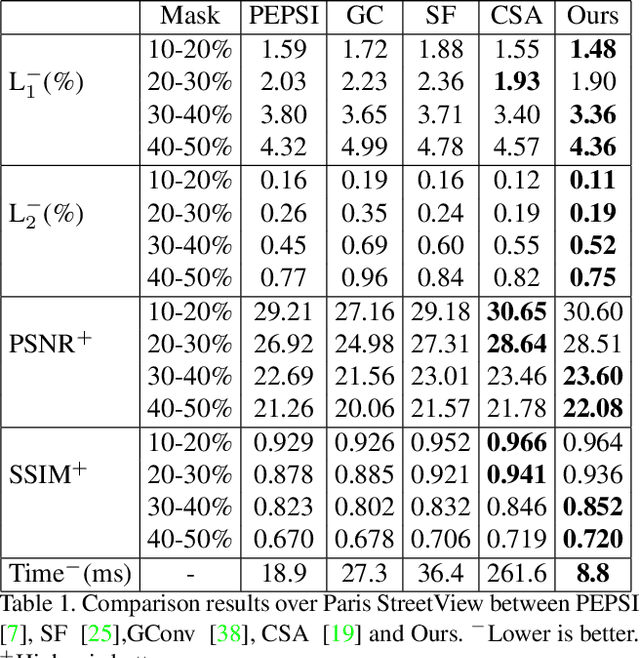
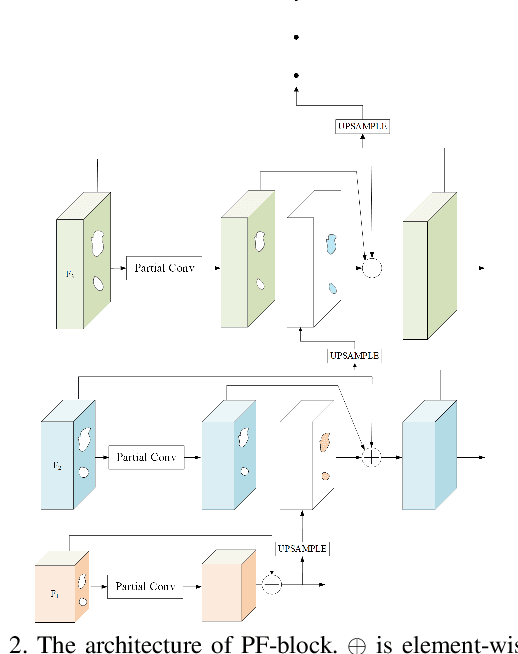
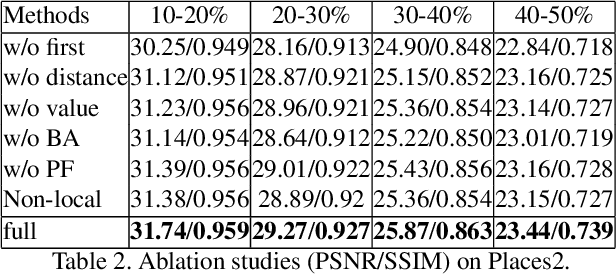
Recent deep learning based image inpainting methods which utilize contextual information and two-stage architecture have exhibited remarkable performance. However, the two-stage architecture is time-consuming, the contextual information lack high-level semantics and ignores both the semantic relevance and distance information of hole's feature patches, these limitations result in blurry textures and distorted structures of final result. Motivated by these observations, we propose a new deep generative model-based approach, which trains a shared network twice with different targets and utilizes a single network during the testing phase, so that we can effectively save inference time. Specifically, the targets of two training steps are structure reconstruction and texture generation respectively. During the second training, we first propose a Pyramid Filling Block (PF-block) to utilize the high-level features that the hole regions has been filled to guide the filling process of low-level features progressively, the missing content can be filled from deep to shallow in a pyramid fashion. Then, inspired by the classical bilateral filter [30], we propose the Bilateral Attention layer (BA-layer) to optimize filled feature map, which synthesizes feature patches at each position by computing weighted sums of the surrounding feature patches, these weights are derived by considering both distance and value relationships between feature patches, thus making the visually plausible inpainting results. Finally, experiments on multiple publicly available datasets show the superior performance of our approach.
Boundary-Aware Salient Object Detection via Recurrent Two-Stream Guided Refinement Network
Dec 11, 2019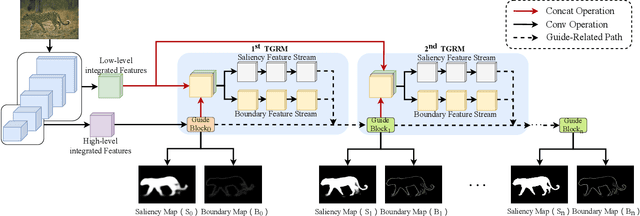
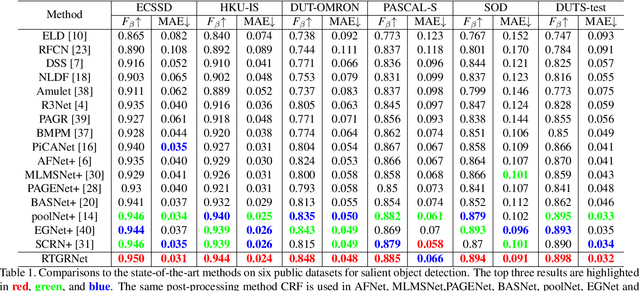

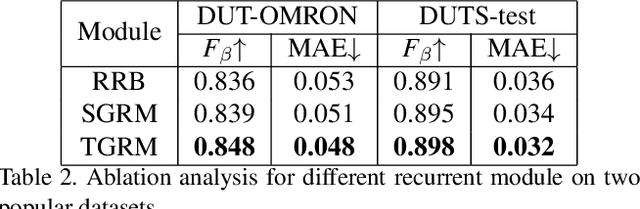
Recent deep learning based salient object detection methods which utilize both saliency and boundary features have achieved remarkable performance. However, most of them ignore the complementarity between saliency features and boundary features, thus get worse predictions in scenes with low contrast between foreground and background. To address this issue, we propose a novel Recurrent Two-Stream Guided Refinement Network (RTGRNet) that consists of iterating Two-Stream Guided Refinement Modules (TGRMs). TGRM consists of a Guide Block and two feature streams: saliency and boundary, the Guide Block utilizes the refined features after previous TGRM to further improve the performance of two feature streams in current TGRM. Meanwhile, the low-level integrated features are also utilized as a reference to get better details. Finally, we progressively refine these features by recurrently stacking more TGRMs. Extensive experiments on six public datasets show that our proposed RTGRNet achieves the state-of-the-art performance in salient object detection.
Constrained R-CNN: A general image manipulation detection model
Nov 25, 2019
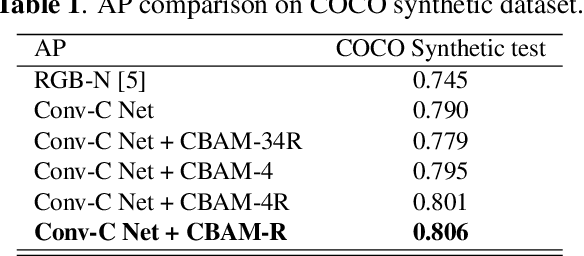
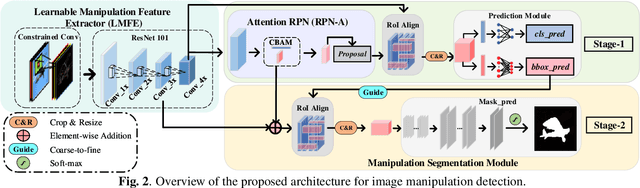
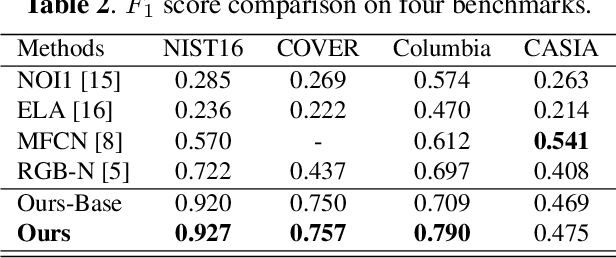
Recently, deep learning-based models have exhibited remarkable performance for image manipulation detection. However, most of them suffer from poor universality of handcrafted or predetermined features. Meanwhile, they only focus on manipulation localization and overlook manipulation classification. To address these issues, we propose a coarse-to-fine architecture named Constrained R-CNN for complete and accurate image forensics. First, the learnable manipulation feature extractor learns a unified feature representation directly from data. Second, the attention region proposal network effectively discriminates manipulated regions for the next manipulation classification and coarse localization. Then, the skip structure fuses low-level and high-level information to refine the global manipulation features. Finally, the coarse localization information guides the model to further learn the finer local features and segment out the tampered region. Experimental results show that our model achieves state-of-the-art performance. Especially, the F1 score is increased by 28.4%, 73.2%, 13.3% on the NIST16, COVERAGE, and Columbia dataset.
Context-Integrated and Feature-Refined Network for Lightweight Urban Scene Parsing
Jul 26, 2019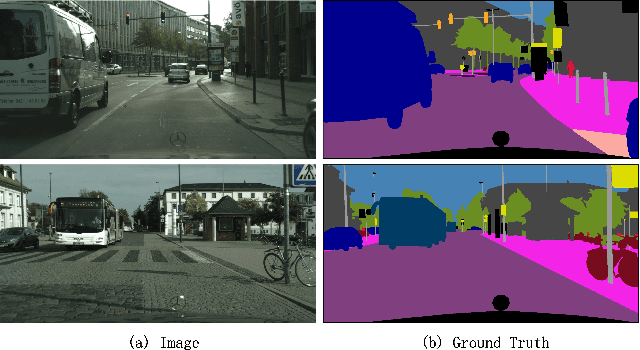
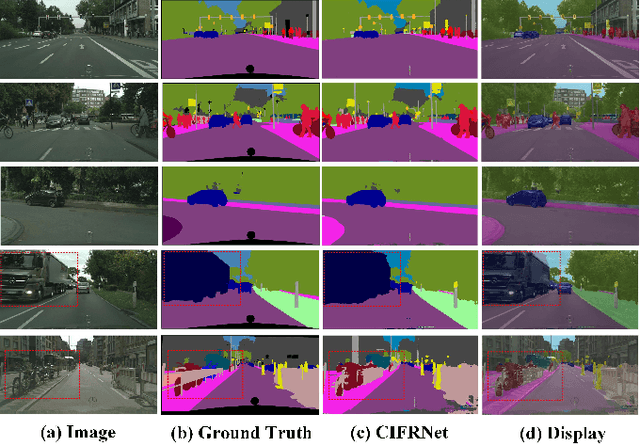

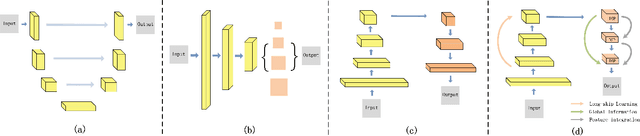
Semantic segmentation for lightweight urban scene parsing is a very challenging task, because both accuracy and efficiency (e.g., execution speed, memory footprint, and computation complexity) should all be taken into account. However, most previous works pay too much attention to one-sided perspective, either accuracy or speed, and ignore others, which poses a great limitation to actual demands of intelligent devices. To tackle this dilemma, we propose a new lightweight architecture named Context-Integrated and Feature-Refined Network (CIFReNet). The core components of our architecture are the Long-skip Refinement Module (LRM) and the Multi-scale Contexts Integration Module (MCIM). With low additional computation cost, LRM is designed to ease the propagation of spatial information and boost the quality of feature refinement. Meanwhile, MCIM consists of three cascaded Dense Semantic Pyramid (DSP) blocks with a global constraint. It makes full use of sub-regions close to the target and enlarges the field of view in an economical yet powerful way. Comprehensive experiments have demonstrated that our proposed method reaches a reasonable trade-off among overall properties on Cityscapes and Camvid dataset. Specifically, with only 7.1 GFLOPs, CIFReNet that contains less than 1.9 M parameters obtains a competitive result of 70.9% MIoU on Cityscapes test set and 64.5% on Camvid test set at a real-time speed of 32.3 FPS, which is more cost-efficient than other state-of-the-art methods.