 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoundary-Aware Salient Object Detection via Recurrent Two-Stream Guided Refinement Network
Dec 11, 2019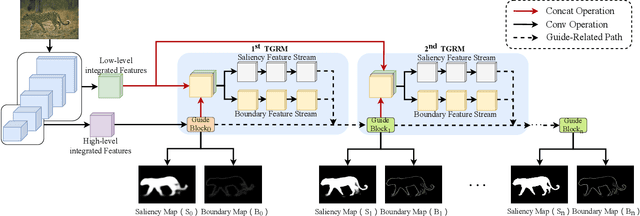
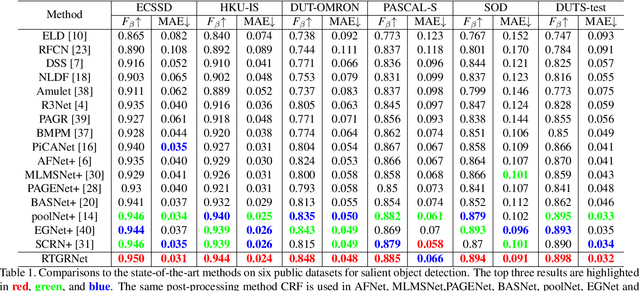

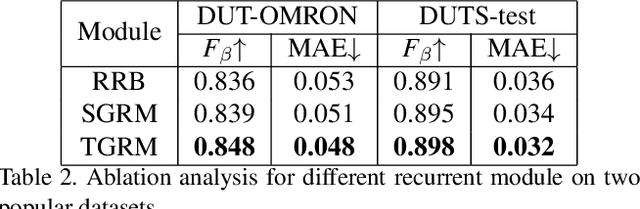
Recent deep learning based salient object detection methods which utilize both saliency and boundary features have achieved remarkable performance. However, most of them ignore the complementarity between saliency features and boundary features, thus get worse predictions in scenes with low contrast between foreground and background. To address this issue, we propose a novel Recurrent Two-Stream Guided Refinement Network (RTGRNet) that consists of iterating Two-Stream Guided Refinement Modules (TGRMs). TGRM consists of a Guide Block and two feature streams: saliency and boundary, the Guide Block utilizes the refined features after previous TGRM to further improve the performance of two feature streams in current TGRM. Meanwhile, the low-level integrated features are also utilized as a reference to get better details. Finally, we progressively refine these features by recurrently stacking more TGRMs. Extensive experiments on six public datasets show that our proposed RTGRNet achieves the state-of-the-art performance in salient object detection.
Constrained R-CNN: A general image manipulation detection model
Nov 25, 2019
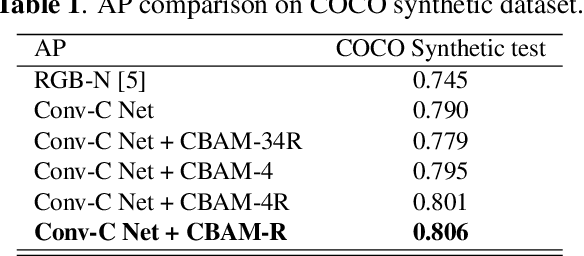
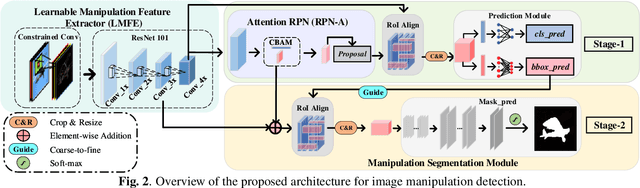
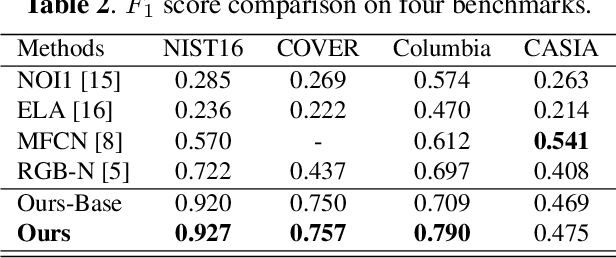
Recently, deep learning-based models have exhibited remarkable performance for image manipulation detection. However, most of them suffer from poor universality of handcrafted or predetermined features. Meanwhile, they only focus on manipulation localization and overlook manipulation classification. To address these issues, we propose a coarse-to-fine architecture named Constrained R-CNN for complete and accurate image forensics. First, the learnable manipulation feature extractor learns a unified feature representation directly from data. Second, the attention region proposal network effectively discriminates manipulated regions for the next manipulation classification and coarse localization. Then, the skip structure fuses low-level and high-level information to refine the global manipulation features. Finally, the coarse localization information guides the model to further learn the finer local features and segment out the tampered region. Experimental results show that our model achieves state-of-the-art performance. Especially, the F1 score is increased by 28.4%, 73.2%, 13.3% on the NIST16, COVERAGE, and Columbia dataset.