 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Multi-View ICA: Estimation of noise levels for optimal inference
Feb 22, 2021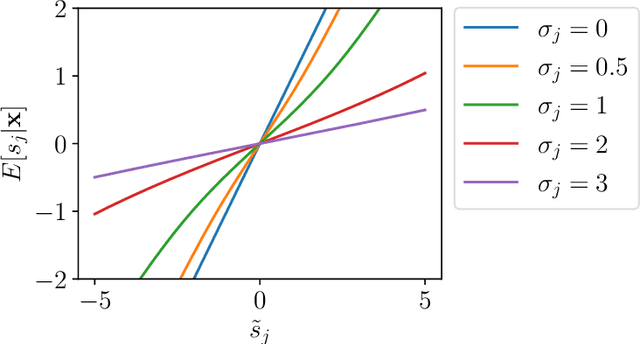
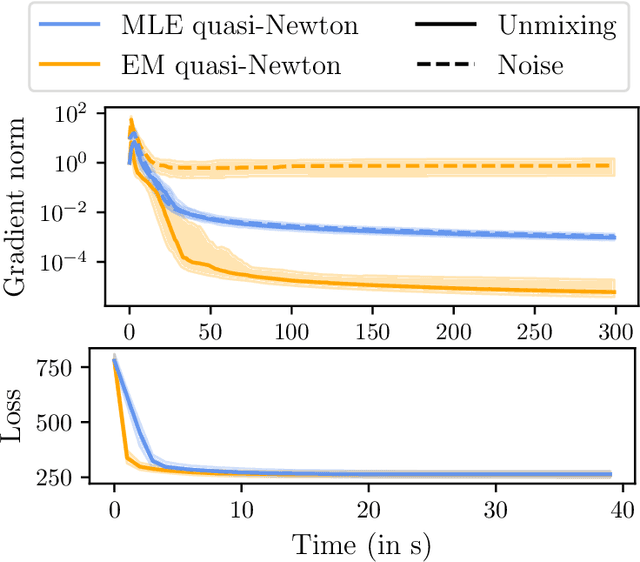
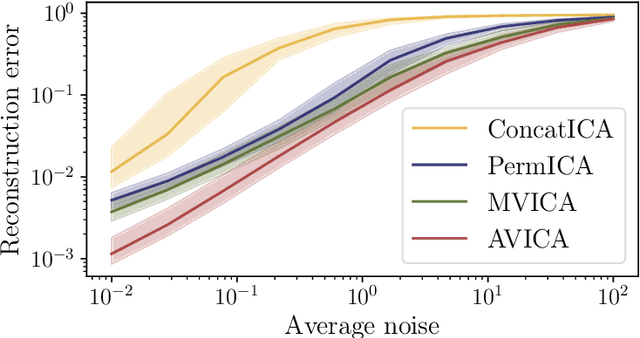
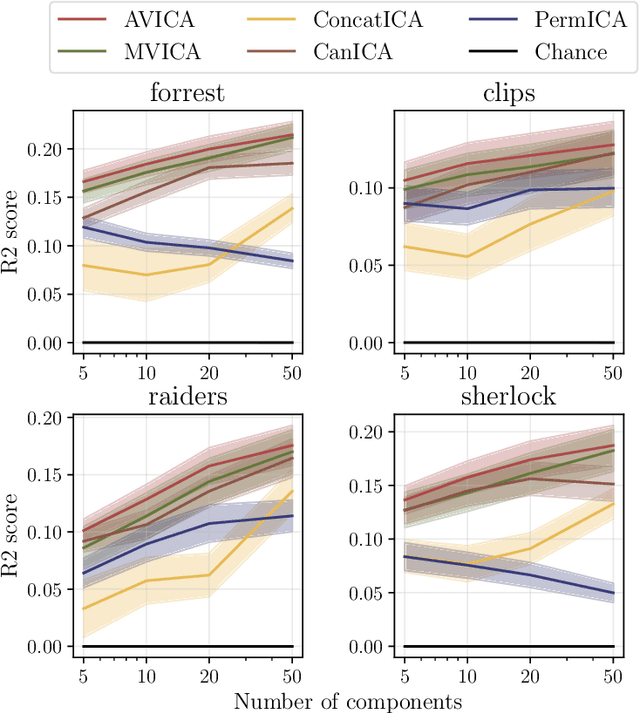
We consider a multi-view learning problem known as group independent component analysis (group ICA), where the goal is to recover shared independent sources from many views. The statistical modeling of this problem requires to take noise into account. When the model includes additive noise on the observations, the likelihood is intractable. By contrast, we propose Adaptive multiView ICA (AVICA), a noisy ICA model where each view is a linear mixture of shared independent sources with additive noise on the sources. In this setting, the likelihood has a tractable expression, which enables either direct optimization of the log-likelihood using a quasi-Newton method, or generalized EM. Importantly, we consider that the noise levels are also parameters that are learned from the data. This enables sources estimation with a closed-form Minimum Mean Squared Error (MMSE) estimator which weights each view according to its relative noise level. On synthetic data, AVICA yields better sources estimates than other group ICA methods thanks to its explicit MMSE estimator. On real magnetoencephalograpy (MEG) data, we provide evidence that the decomposition is less sensitive to sampling noise and that the noise variance estimates are biologically plausible. Lastly, on functional magnetic resonance imaging (fMRI) data, AVICA exhibits best performance in transferring information across views.
Statistical control for spatio-temporal MEG/EEG source imaging with desparsified multi-task Lasso
Sep 29, 2020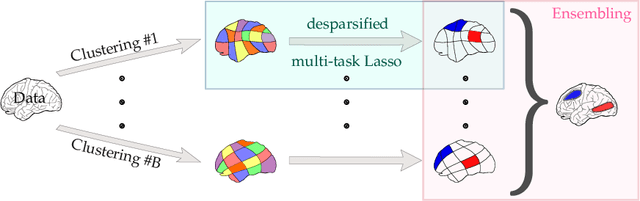
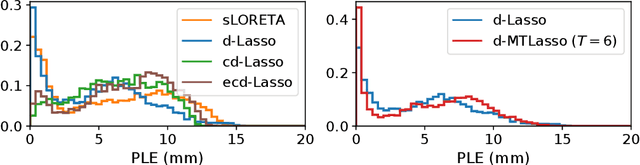
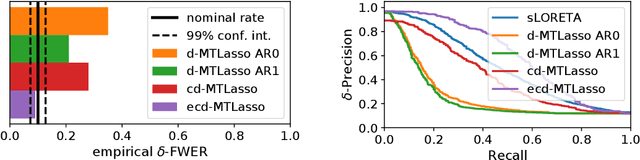
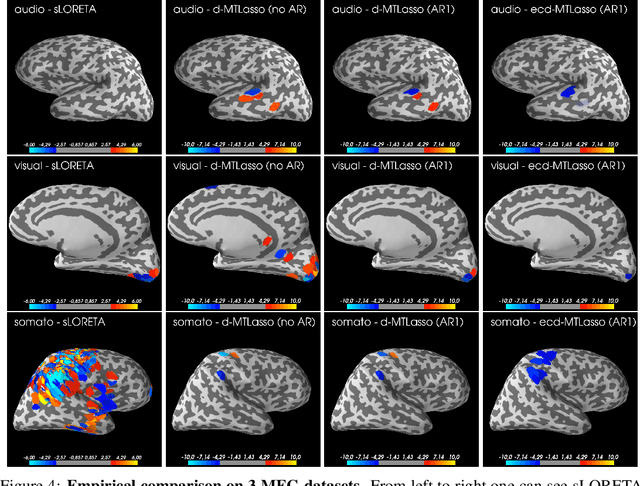
Detecting where and when brain regions activate in a cognitive task or in a given clinical condition is the promise of non-invasive techniques like magnetoencephalography (MEG) or electroencephalography (EEG). This problem, referred to as source localization, or source imaging, poses however a high-dimensional statistical inference challenge. While sparsity promoting regularizations have been proposed to address the regression problem, it remains unclear how to ensure statistical control of false detections. Moreover, M/EEG source imaging requires to work with spatio-temporal data and autocorrelated noise. To deal with this, we adapt the desparsified Lasso estimator -- an estimator tailored for high dimensional linear model that asymptotically follows a Gaussian distribution under sparsity and moderate feature correlation assumptions -- to temporal data corrupted with autocorrelated noise. We call it the desparsified multi-task Lasso (d-MTLasso). We combine d-MTLasso with spatially constrained clustering to reduce data dimension and with ensembling to mitigate the arbitrary choice of clustering; the resulting estimator is called ensemble of clustered desparsified multi-task Lasso (ecd-MTLasso). With respect to the current procedures, the two advantages of ecd-MTLasso are that i)it offers statistical guarantees and ii)it allows to trade spatial specificity for sensitivity, leading to a powerful adaptive method. Extensive simulations on realistic head geometries, as well as empirical results on various MEG datasets, demonstrate the high recovery performance of ecd-MTLasso and its primary practical benefit: offer a statistically principled way to threshold MEG/EEG source maps.
Modeling Shared Responses in Neuroimaging Studies through MultiView ICA
Jun 12, 2020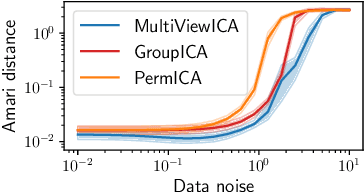
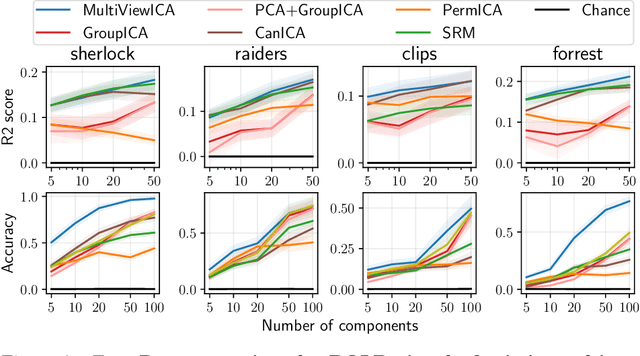
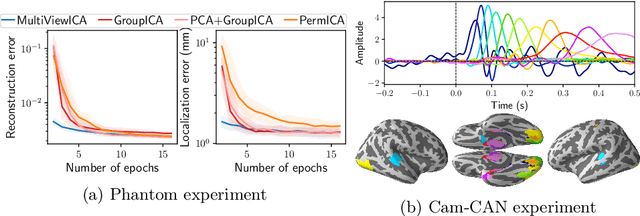
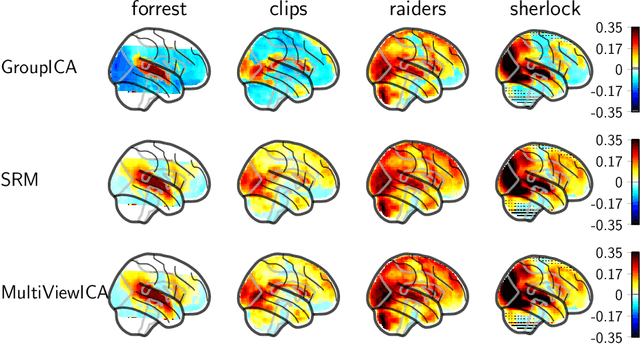
Group studies involving large cohorts of subjects are important to draw general conclusions about brain functional organization. However, the aggregation of data coming from multiple subjects is challenging, since it requires accounting for large variability in anatomy, functional topography and stimulus response across individuals. Data modeling is especially hard for ecologically relevant conditions such as movie watching, where the experimental setup does not imply well-defined cognitive operations. We propose a novel MultiView Independent Component Analysis (ICA) model for group studies, where data from each subject are modeled as a linear combination of shared independent sources plus noise. Contrary to most group-ICA procedures, the likelihood of the model is available in closed form. We develop an alternate quasi-Newton method for maximizing the likelihood, which is robust and converges quickly. We demonstrate the usefulness of our approach first on fMRI data, where our model demonstrates improved sensitivity in identifying common sources among subjects. Moreover, the sources recovered by our model exhibit lower between-session variability than other methods.On magnetoencephalography (MEG) data, our method yields more accurate source localization on phantom data. Applied on 200 subjects from the Cam-CAN dataset it reveals a clear sequence of evoked activity in sensor and source space. The code is freely available at https://github.com/hugorichard/multiviewica.
Fine-grain atlases of functional modes for fMRI analysis
Mar 05, 2020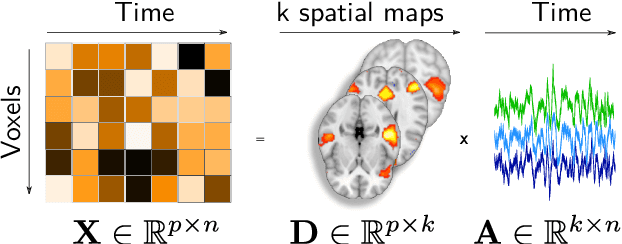
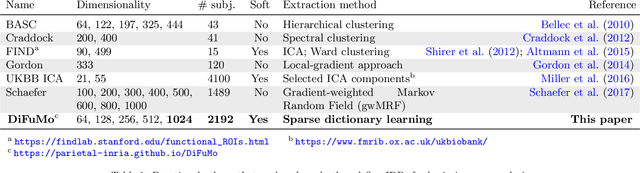
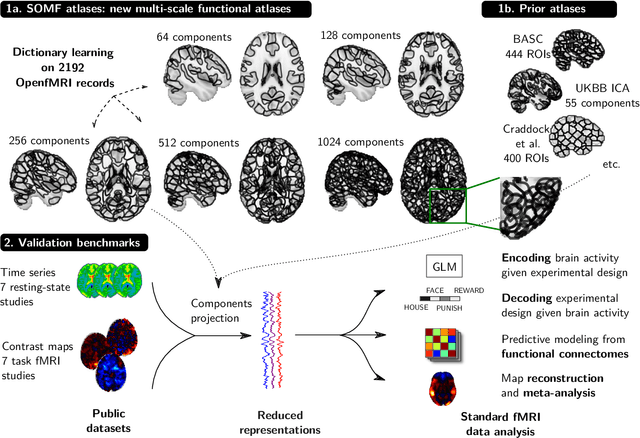
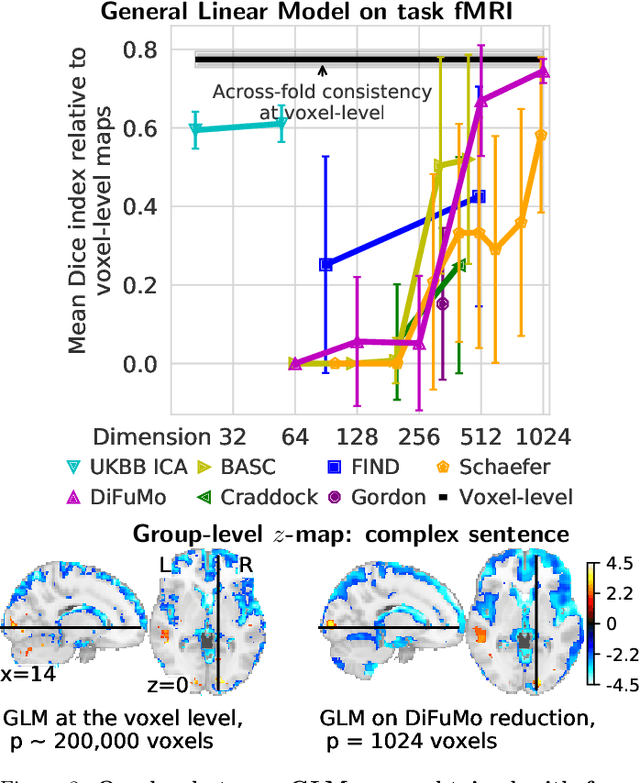
Population imaging markedly increased the size of functional-imaging datasets, shedding new light on the neural basis of inter-individual differences. Analyzing these large data entails new scalability challenges, computational and statistical. For this reason, brain images are typically summarized in a few signals, for instance reducing voxel-level measures with brain atlases or functional modes. A good choice of the corresponding brain networks is important, as most data analyses start from these reduced signals. We contribute finely-resolved atlases of functional modes, comprising from 64 to 1024 networks. These dictionaries of functional modes (DiFuMo) are trained on millions of fMRI functional brain volumes of total size 2.4TB, spanned over 27 studies and many research groups. We demonstrate the benefits of extracting reduced signals on our fine-grain atlases for many classic functional data analysis pipelines: stimuli decoding from 12,334 brain responses, standard GLM analysis of fMRI across sessions and individuals, extraction of resting-state functional-connectomes biomarkers for 2,500 individuals, data compression and meta-analysis over more than 15,000 statistical maps. In each of these analysis scenarii, we compare the performance of our functional atlases with that of other popular references, and to a simple voxel-level analysis. Results highlight the importance of using high-dimensional "soft" functional atlases, to represent and analyse brain activity while capturing its functional gradients. Analyses on high-dimensional modes achieve similar statistical performance as at the voxel level, but with much reduced computational cost and higher interpretability. In addition to making them available, we provide meaningful names for these modes, based on their anatomical location. It will facilitate reporting of results.
Aggregation of Multiple Knockoffs
Feb 21, 2020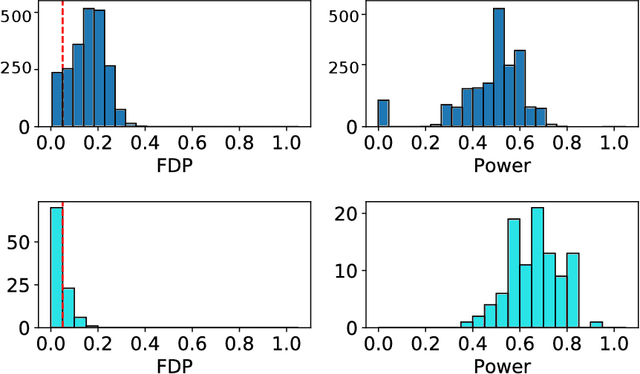

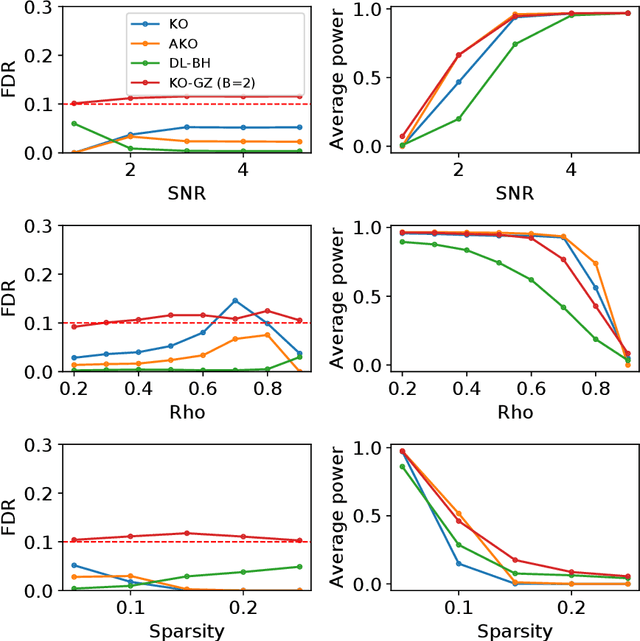
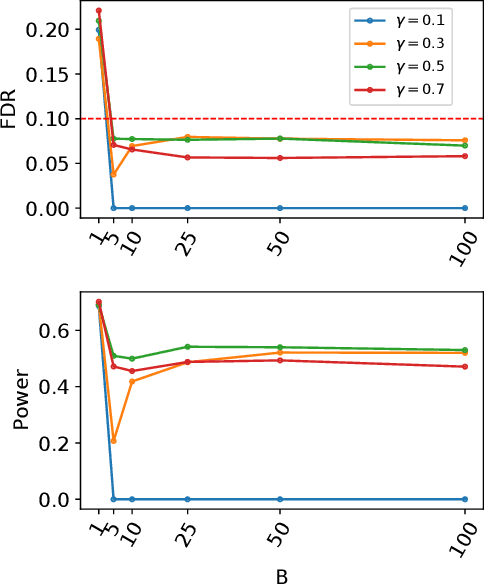
We develop an extension of the Knockoff Inference procedure, introduced by Barber and Candes (2015). This new method, called Aggregation of Multiple Knockoffs (AKO), addresses the instability inherent to the random nature of Knockoff-based inference. Specifically, AKO improves both the stability and power compared with the original Knockoff algorithm while still maintaining guarantees for False Discovery Rate control. We provide a new inference procedure, prove its core properties, and demonstrate its benefits in a set of experiments on synthetic and real datasets.
NeuroQuery: comprehensive meta-analysis of human brain mapping
Feb 21, 2020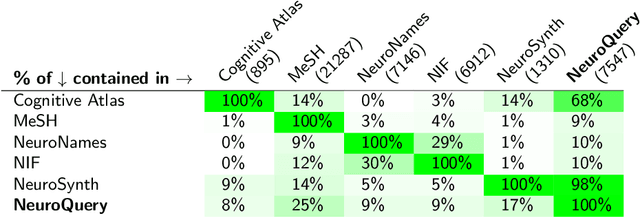
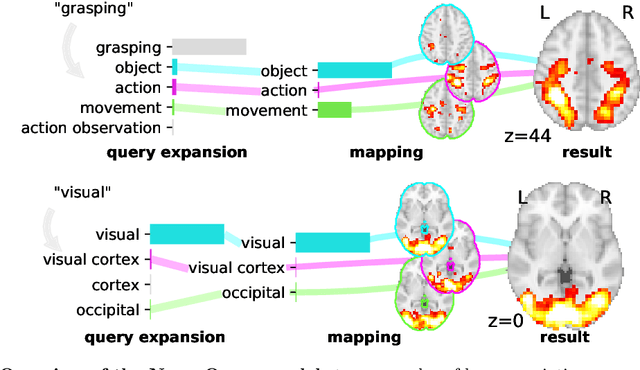
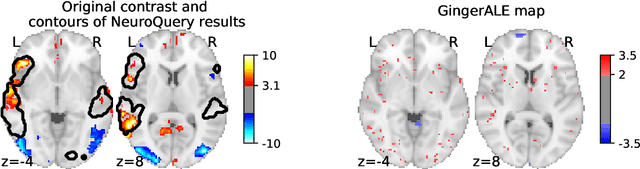
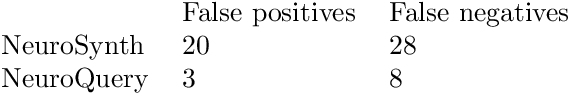
Reaching a global view of brain organization requires assembling evidence on widely different mental processes and mechanisms. The variety of human neuroscience concepts and terminology poses a fundamental challenge to relating brain imaging results across the scientific literature. Existing meta-analysis methods perform statistical tests on sets of publications associated with a particular concept. Thus, large-scale meta-analyses only tackle single terms that occur frequently. We propose a new paradigm, focusing on prediction rather than inference. Our multivariate model predicts the spatial distribution of neurological observations, given text describing an experiment, cognitive process, or disease. This approach handles text of arbitrary length and terms that are too rare for standard meta-analysis. We capture the relationships and neural correlates of 7 547 neuroscience terms across 13 459 neuroimaging publications. The resulting meta-analytic tool, neuroquery.org, can ground hypothesis generation and data-analysis priors on a comprehensive view of published findings on the brain.
Multi-subject MEG/EEG source imaging with sparse multi-task regression
Oct 14, 2019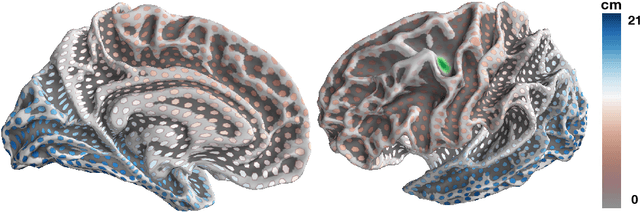
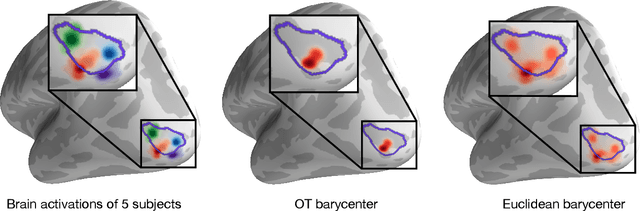
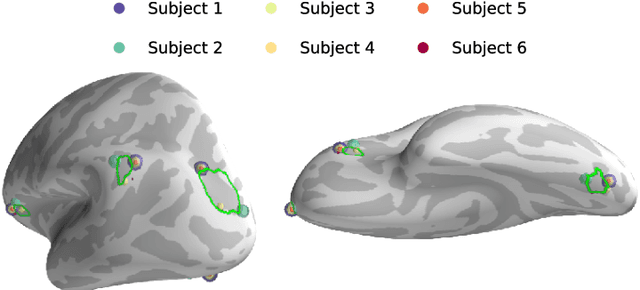
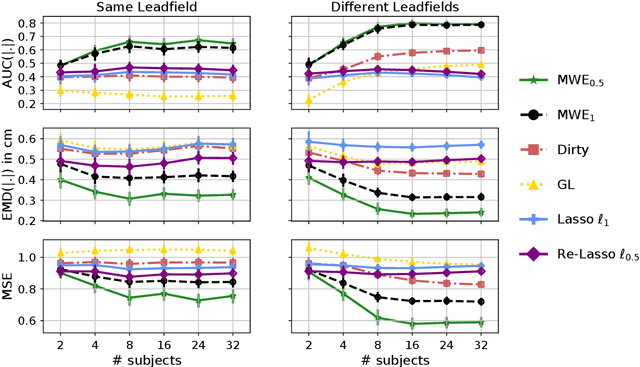
Magnetoencephalography and electroencephalography (M/EEG) are non-invasive modalities that measure the weak electromagnetic fields generated by neural activity. Estimating the location and magnitude of the current sources that generated these electromagnetic fields is a challenging ill-posed regression problem known as \emph{source imaging}. When considering a group study, a common approach consists in carrying out the regression tasks independently for each subject. An alternative is to jointly localize sources for all subjects taken together, while enforcing some similarity between them. By pooling all measurements in a single multi-task regression, one makes the problem better posed, offering the ability to identify more sources and with greater precision. The Minimum Wasserstein Estimates (MWE) promotes focal activations that do not perfectly overlap for all subjects, thanks to a regularizer based on Optimal Transport (OT) metrics. MWE promotes spatial proximity on the cortical mantel while coping with the varying noise levels across subjects. On realistic simulations, MWE decreases the localization error by up to 4 mm per source compared to individual solutions. Experiments on the Cam-CAN dataset show a considerable improvement in spatial specificity in population imaging. Our analysis of a multimodal dataset shows how multi-subject source localization closes the gap between MEG and fMRI for brain mapping.
Fast shared response model for fMRI data
Sep 27, 2019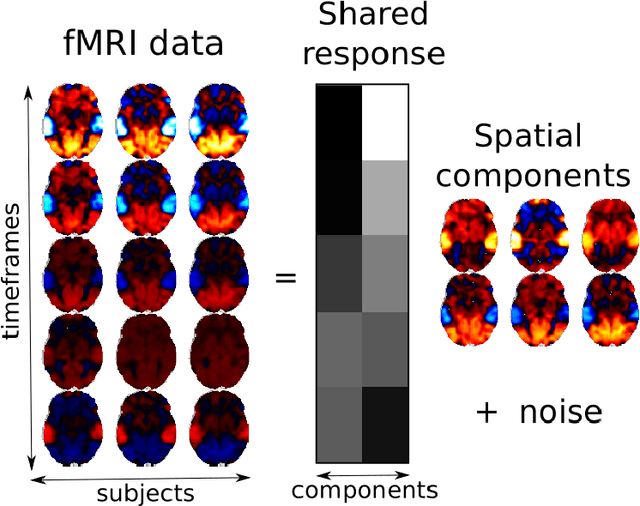
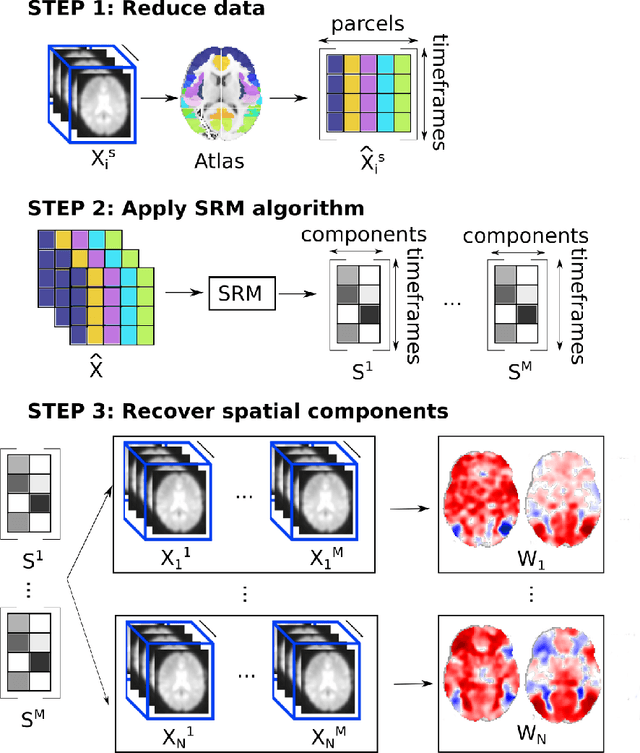
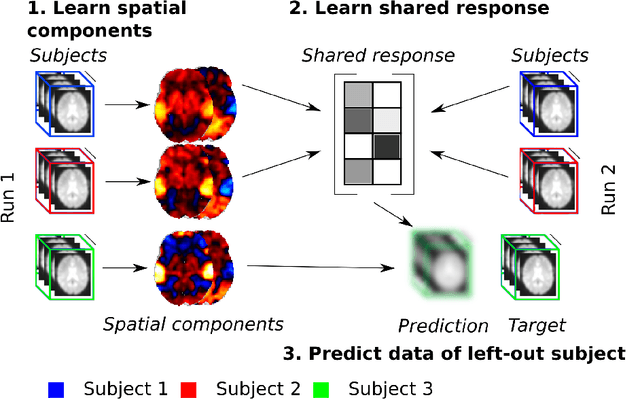
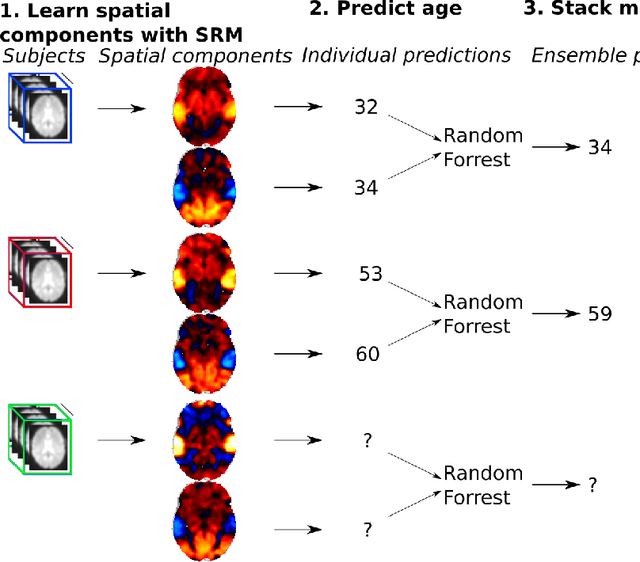
The shared response model provides a simple but effective framework toanalyse fMRI data of subjects exposed to naturalistic stimuli. However whenthe number of subjects or runs is large, fitting the model requires a large amountof memory and computational power, which limits its use in practice. In thiswork, we introduce the FastSRM algorithm that relies on an intermediate atlas-based representation. It provides considerable speed-up in time and memoryusage, hence it allows easy and fast large-scale analysis of naturalistic-stimulusfMRI data. Using four different datasets, we show that our method outperformsthe original SRM algorithm while being about 5x faster and 20x to 40x morememory efficient. Based on this contribution, we use FastSRM to predict agefrom movie watching data on the CamCAN sample. Besides delivering accuratepredictions (mean absolute error of 7.5 years), FastSRM extracts topographicpatterns that are predictive of age, demonstrating that brain activity duringfree perception reflects age.
Group level MEG/EEG source imaging via optimal transport: minimum Wasserstein estimates
Feb 13, 2019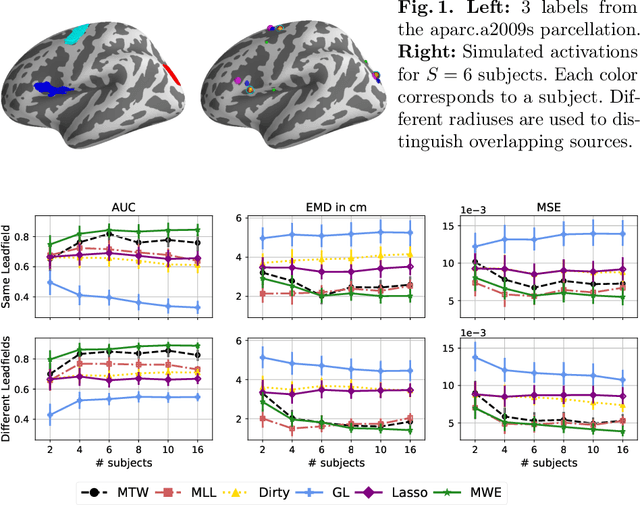
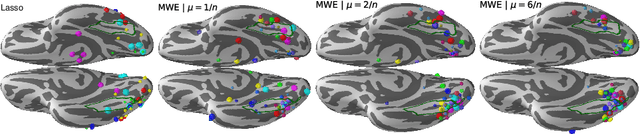
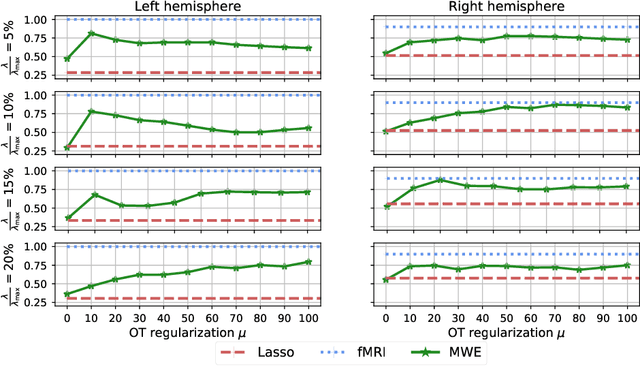
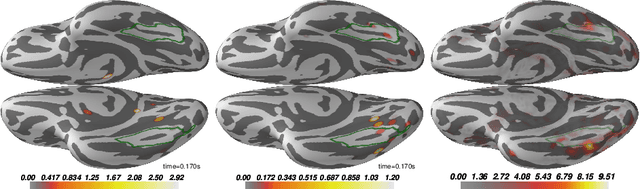
Magnetoencephalography (MEG) and electroencephalogra-phy (EEG) are non-invasive modalities that measure the weak electromagnetic fields generated by neural activity. Inferring the location of the current sources that generated these magnetic fields is an ill-posed inverse problem known as source imaging. When considering a group study, a baseline approach consists in carrying out the estimation of these sources independently for each subject. The ill-posedness of each problem is typically addressed using sparsity promoting regularizations. A straightforward way to define a common pattern for these sources is then to average them. A more advanced alternative relies on a joint localization of sources for all subjects taken together, by enforcing some similarity across all estimated sources. An important advantage of this approach is that it consists in a single estimation in which all measurements are pooled together, making the inverse problem better posed. Such a joint estimation poses however a few challenges, notably the selection of a valid regularizer that can quantify such spatial similarities. We propose in this work a new procedure that can do so while taking into account the geometrical structure of the cortex. We call this procedure Minimum Wasserstein Estimates (MWE). The benefits of this model are twofold. First, joint inference allows to pool together the data of different brain geometries, accumulating more spatial information. Second, MWE are defined through Optimal Transport (OT) metrics which provide a tool to model spatial proximity between cortical sources of different subjects, hence not enforcing identical source location in the group. These benefits allow MWE to be more accurate than standard MEG source localization techniques. To support these claims, we perform source localization on realistic MEG simulations based on forward operators derived from MRI scans. On a visual task dataset, we demonstrate how MWE infer neural patterns similar to functional Magnetic Resonance Imaging (fMRI) maps.
Extracting Universal Representations of Cognition across Brain-Imaging Studies
Oct 19, 2018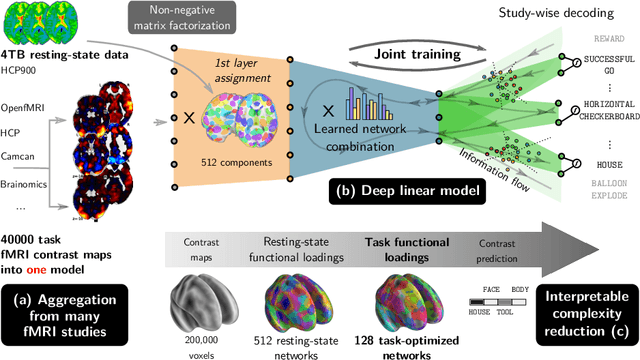
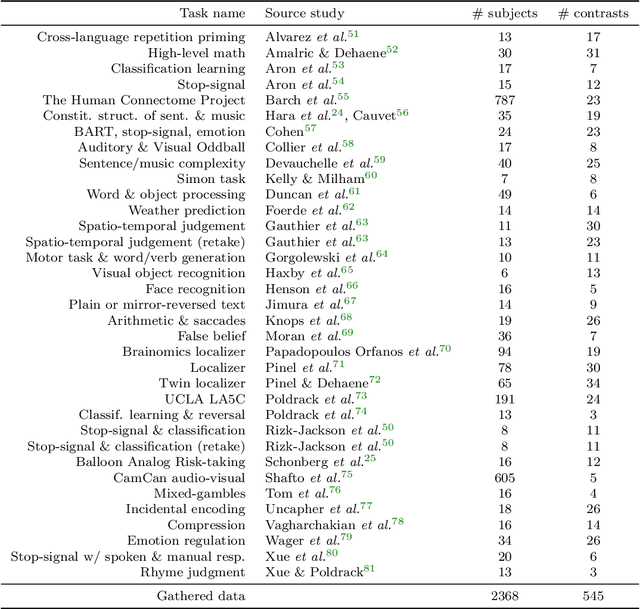
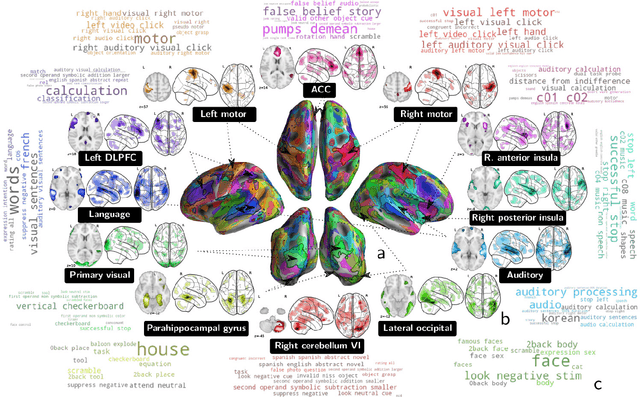
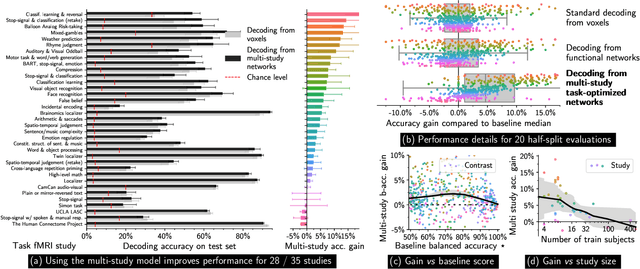
We show in this paper how to extract shared brain representations that predict mental processes across many cognitive neuroimaging studies. Focused cognitive-neuroimaging experiments study precise mental processes with carefully-designed cognitive paradigms; however the cost of imaging limits their statistical power. On the other hand, large-scale databasing efforts increase considerably the sample sizes, but cannot ask precise cognitive questions. To address this tension, we develop new methods that turn the heterogeneous cognitive information held in different task-fMRI studies into common-universal-cognitive models. Our approach does not assume any prior knowledge of the commonalities shared by the studies in the corpus; those are inferred during model training. The method uses deep-learning techniques to extract representations - task-optimized networks - that form a set of basis cognitive dimensions relevant to the psychological manipulations. In this sense, it forms a novel kind of functional atlas, optimized to capture mental state across many functional-imaging experiments. As it bridges information on the neural support of mental processes, this representation improves decoding performance for 80% of the 35 widely-different functional imaging studies that we consider. Our approach opens new ways of extracting information from brain maps, increasing statistical power even for focused cognitive neuroimaging studies, in particular for those with few subjects.