 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHARDMath2: A Benchmark for Applied Mathematics Built by Students as Part of a Graduate Class
May 17, 2025Large language models (LLMs) have shown remarkable progress in mathematical problem-solving, but evaluation has largely focused on problems that have exact analytical solutions or involve formal proofs, often overlooking approximation-based problems ubiquitous in applied science and engineering. To fill this gap, we build on prior work and present HARDMath2, a dataset of 211 original problems covering the core topics in an introductory graduate applied math class, including boundary-layer analysis, WKB methods, asymptotic solutions of nonlinear partial differential equations, and the asymptotics of oscillatory integrals. This dataset was designed and verified by the students and instructors of a core graduate applied mathematics course at Harvard. We build the dataset through a novel collaborative environment that challenges students to write and refine difficult problems consistent with the class syllabus, peer-validate solutions, test different models, and automatically check LLM-generated solutions against their own answers and numerical ground truths. Evaluation results show that leading frontier models still struggle with many of the problems in the dataset, highlighting a gap in the mathematical reasoning skills of current LLMs. Importantly, students identified strategies to create increasingly difficult problems by interacting with the models and exploiting common failure modes. This back-and-forth with the models not only resulted in a richer and more challenging benchmark but also led to qualitative improvements in the students' understanding of the course material, which is increasingly important as we enter an age where state-of-the-art language models can solve many challenging problems across a wide domain of fields.
Fast shared response model for fMRI data
Sep 27, 2019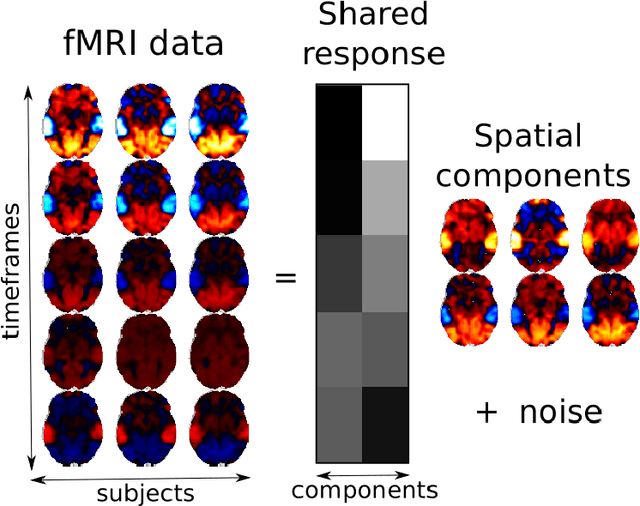
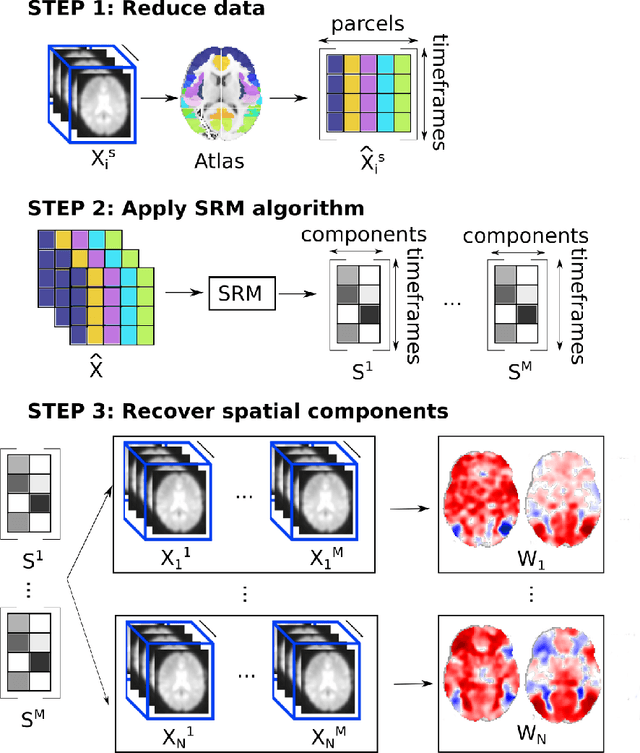
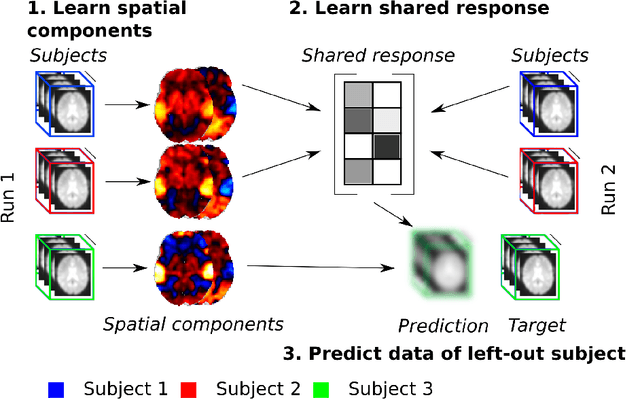
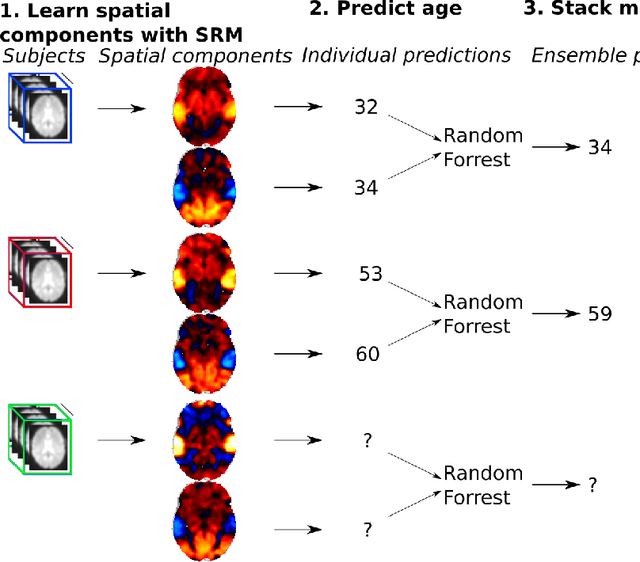
The shared response model provides a simple but effective framework toanalyse fMRI data of subjects exposed to naturalistic stimuli. However whenthe number of subjects or runs is large, fitting the model requires a large amountof memory and computational power, which limits its use in practice. In thiswork, we introduce the FastSRM algorithm that relies on an intermediate atlas-based representation. It provides considerable speed-up in time and memoryusage, hence it allows easy and fast large-scale analysis of naturalistic-stimulusfMRI data. Using four different datasets, we show that our method outperformsthe original SRM algorithm while being about 5x faster and 20x to 40x morememory efficient. Based on this contribution, we use FastSRM to predict agefrom movie watching data on the CamCAN sample. Besides delivering accuratepredictions (mean absolute error of 7.5 years), FastSRM extracts topographicpatterns that are predictive of age, demonstrating that brain activity duringfree perception reflects age.