 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Compression with Neural Architecture Search
Oct 09, 2024



Large language models (LLMs) exhibit remarkable reasoning abilities, allowing them to generalize across a wide range of downstream tasks, such as commonsense reasoning or instruction following. However, as LLMs scale, inference costs become increasingly prohibitive, accumulating significantly over their life cycle. This poses the question: Can we compress pre-trained LLMs to meet diverse size and latency requirements? We leverage Neural Architecture Search (NAS) to compress LLMs by pruning structural components, such as attention heads, neurons, and layers, aiming to achieve a Pareto-optimal balance between performance and efficiency. While NAS already achieved promising results on small language models in previous work, in this paper we propose various extensions that allow us to scale to LLMs. Compared to structural pruning baselines, we show that NAS improves performance up to 3.4% on MMLU with an on-device latency speedup.
HW-GPT-Bench: Hardware-Aware Architecture Benchmark for Language Models
May 16, 2024The expanding size of language models has created the necessity for a comprehensive examination across various dimensions that reflect the desiderata with respect to the tradeoffs between various hardware metrics, such as latency, energy consumption, GPU memory usage, and performance. There is a growing interest in establishing Pareto frontiers for different language model configurations to identify optimal models with specified hardware constraints. Notably, architectures that excel in latency on one device may not perform optimally on another. However, exhaustive training and evaluation of numerous architectures across diverse hardware configurations is computationally prohibitive. To this end, we propose HW-GPT-Bench, a hardware-aware language model surrogate benchmark, where we leverage weight-sharing techniques from Neural Architecture Search (NAS) to efficiently train a supernet proxy, encompassing language models of varying scales in a single model. We conduct profiling of these models across 13 devices, considering 5 hardware metrics and 3 distinct model scales. Finally, we showcase the usability of HW-GPT-Bench using 8 different multi-objective NAS algorithms and evaluate the quality of the resultant Pareto fronts. Through this benchmark, our objective is to propel and expedite research in the advancement of multi-objective methods for NAS and structural pruning in large language models.
Multi-objective Differentiable Neural Architecture Search
Feb 28, 2024Pareto front profiling in multi-objective optimization (MOO), i.e. finding a diverse set of Pareto optimal solutions, is challenging, especially with expensive objectives like neural network training. Typically, in MOO neural architecture search (NAS), we aim to balance performance and hardware metrics across devices. Prior NAS approaches simplify this task by incorporating hardware constraints into the objective function, but profiling the Pareto front necessitates a search for each constraint. In this work, we propose a novel NAS algorithm that encodes user preferences for the trade-off between performance and hardware metrics, and yields representative and diverse architectures across multiple devices in just one search run. To this end, we parameterize the joint architectural distribution across devices and multiple objectives via a hypernetwork that can be conditioned on hardware features and preference vectors, enabling zero-shot transferability to new devices. Extensive experiments with up to 19 hardware devices and 3 objectives showcase the effectiveness and scalability of our method. Finally, we show that, without additional costs, our method outperforms existing MOO NAS methods across qualitatively different search spaces and datasets, including MobileNetV3 on ImageNet-1k and a Transformer space on machine translation.
Neural Architecture Search for Dense Prediction Tasks in Computer Vision
Feb 15, 2022The success of deep learning in recent years has lead to a rising demand for neural network architecture engineering. As a consequence, neural architecture search (NAS), which aims at automatically designing neural network architectures in a data-driven manner rather than manually, has evolved as a popular field of research. With the advent of weight sharing strategies across architectures, NAS has become applicable to a much wider range of problems. In particular, there are now many publications for dense prediction tasks in computer vision that require pixel-level predictions, such as semantic segmentation or object detection. These tasks come with novel challenges, such as higher memory footprints due to high-resolution data, learning multi-scale representations, longer training times, and more complex and larger neural architectures. In this manuscript, we provide an overview of NAS for dense prediction tasks by elaborating on these novel challenges and surveying ways to address them to ease future research and application of existing methods to novel problems.
Bag of Tricks for Neural Architecture Search
Jul 08, 2021While neural architecture search methods have been successful in previous years and led to new state-of-the-art performance on various problems, they have also been criticized for being unstable, being highly sensitive with respect to their hyperparameters, and often not performing better than random search. To shed some light on this issue, we discuss some practical considerations that help improve the stability, efficiency and overall performance.
Meta-Learning of Neural Architectures for Few-Shot Learning
Nov 25, 2019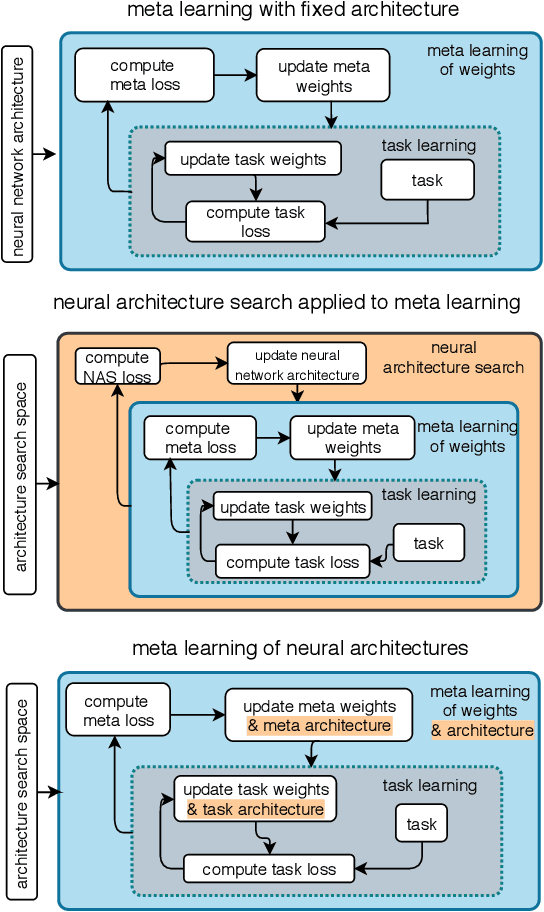
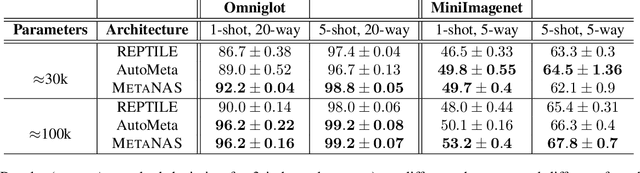
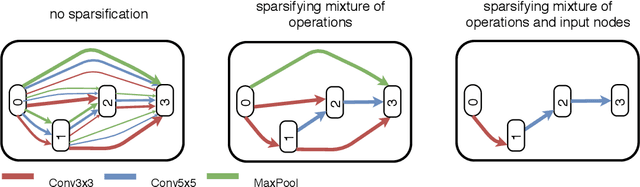
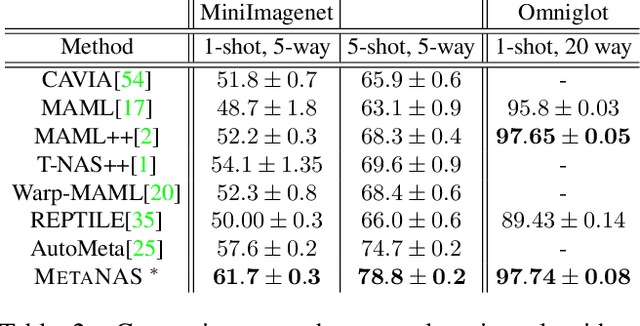
The recent progress in neural architectures search (NAS) has allowed scaling the automated design of neural architectures to real-world domains such as object detection and semantic segmentation. However, one prerequisite for the application of NAS are large amounts of labeled data and compute resources. This renders its application challenging in few-shot learning scenarios, where many related tasks need to be learned, each with limited amounts of data and compute time. Thus, few-shot learning is typically done with a fixed neural architecture. To improve upon this, we propose MetaNAS, the first method which fully integrates NAS with gradient-based meta-learning. MetaNAS optimizes a meta-architecture along with the meta-weights during meta-training. During meta-testing, architectures can be adapted to a novel task with a few steps of the task optimizer, that is: task adaptation becomes computationally cheap and requires only little data per task. Moreover, MetaNAS is agnostic in that it can be used with arbitrary model-agnostic meta-learning algorithms and arbitrary gradient-based NAS methods. Empirical results on standard few-shot classification benchmarks show that MetaNAS with a combination of DARTS and REPTILE yields state-of-the-art results.
Detecting Synapse Location and Connectivity by Signed Proximity Estimation and Pruning with Deep Nets
Oct 25, 2018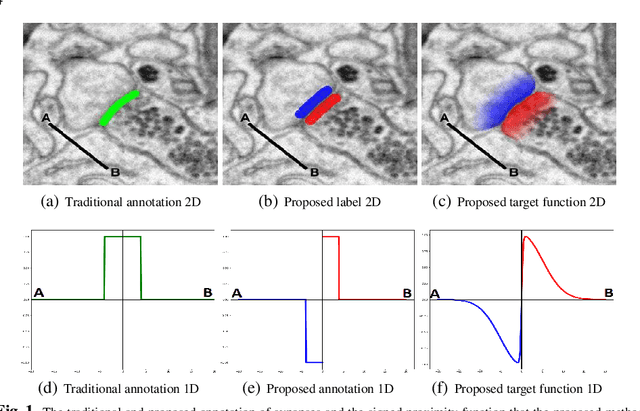
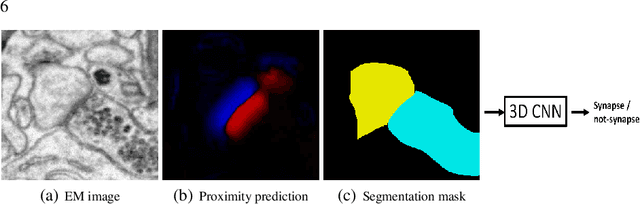
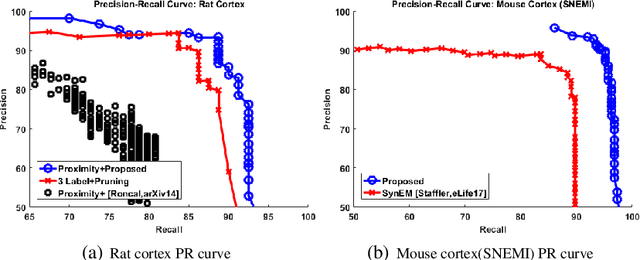
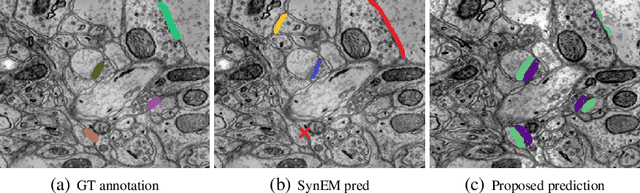
Synaptic connectivity detection is a critical task for neural reconstruction from Electron Microscopy (EM) data. Most of the existing algorithms for synapse detection do not identify the cleft location and direction of connectivity simultaneously. The few methods that computes direction along with contact location have only been demonstrated to work on either dyadic (most common in vertebrate brain) or polyadic (found in fruit fly brain) synapses, but not on both types. In this paper, we present an algorithm to automatically predict the location as well as the direction of both dyadic and polyadic synapses. The proposed algorithm first generates candidate synaptic connections from voxelwise predictions of signed proximity generated by a 3D U-net. A second 3D CNN then prunes the set of candidates to produce the final detection of cleft and connectivity orientation. Experimental results demonstrate that the proposed method outperforms the existing methods for determining synapses in both rodent and fruit fly brain.