 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeqRRT: Quality-Biased Incremental RRT for Optimal Motion Planning in Non-Holonomic Systems
Jan 07, 2021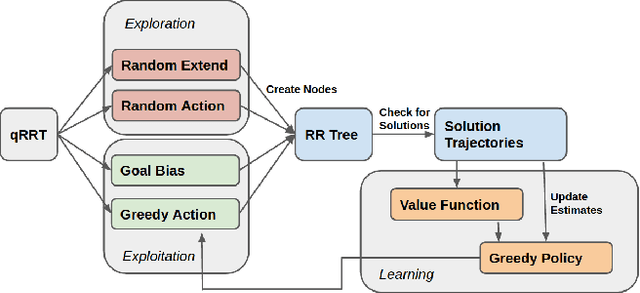
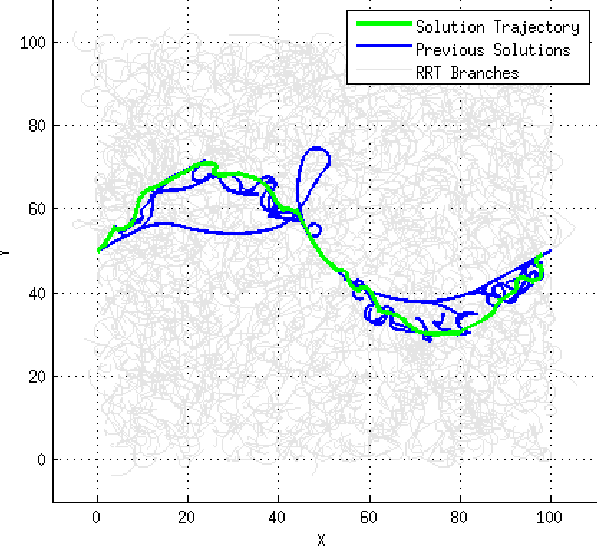
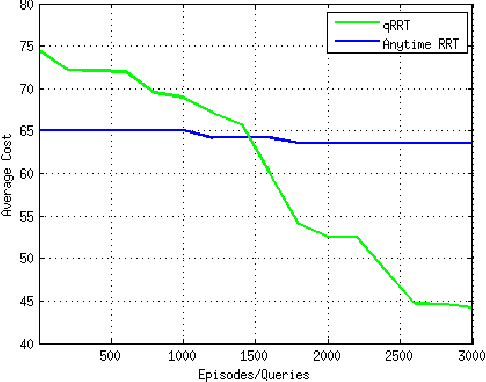
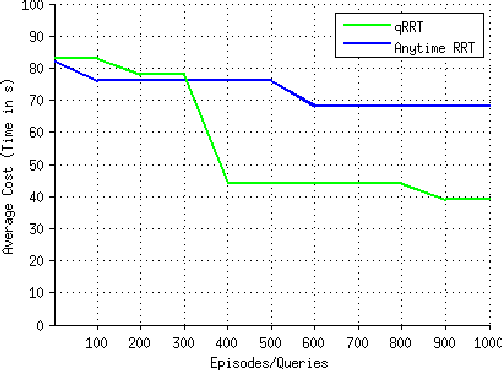
This paper presents a sampling-based method for optimal motion planning in non-holonomic systems in the absence of known cost functions. It uses the principle of learning through experience to deduce the cost-to-go of regions within the workspace. This cost information is used to bias an incremental graph-based search algorithm that produces solution trajectories. Iterative improvement of cost information and search biasing produces solutions that are proven to be asymptotically optimal. The proposed framework builds on incremental Rapidly-exploring Random Trees (RRT) for random sampling-based search and Reinforcement Learning (RL) to learn workspace costs. A series of experiments were performed to evaluate and demonstrate the performance of the proposed method.
Neural Fitted Q Iteration based Optimal Bidding Strategy in Real Time Reactive Power Market_1
Jan 07, 2021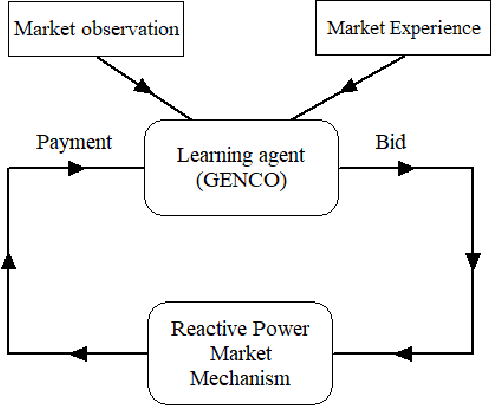
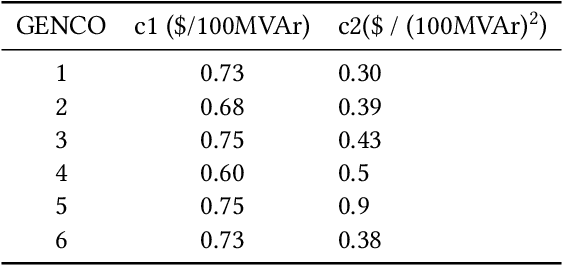
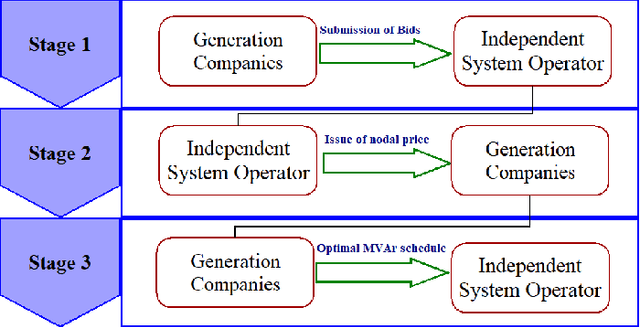
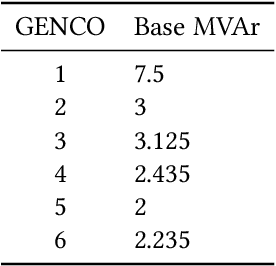
In real time electricity markets, the objective of generation companies while bidding is to maximize their profit. The strategies for learning optimal bidding have been formulated through game theoretical approaches and stochastic optimization problems. Similar studies in reactive power markets have not been reported so far because the network voltage operating conditions have an increased impact on reactive power markets than on active power markets. Contrary to active power markets, the bids of rivals are not directly related to fuel costs in reactive power markets. Hence, the assumption of a suitable probability distribution function is unrealistic, making the strategies adopted in active power markets unsuitable for learning optimal bids in reactive power market mechanisms. Therefore, a bidding strategy is to be learnt from market observations and experience in imperfect oligopolistic competition-based markets. In this paper, a pioneer work on learning optimal bidding strategies from observation and experience in a three-stage reactive power market is reported.
Relational Boosted Bandits
Dec 16, 2020
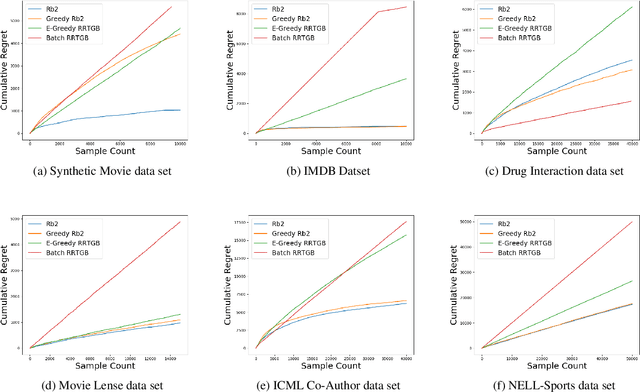
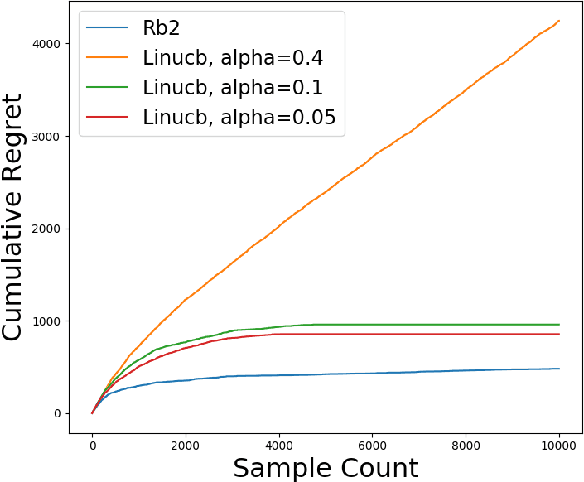
Contextual bandits algorithms have become essential in real-world user interaction problems in recent years. However, these algorithms rely on context as attribute value representation, which makes them unfeasible for real-world domains like social networks are inherently relational. We propose Relational Boosted Bandits(RB2), acontextual bandits algorithm for relational domains based on (relational) boosted trees. RB2 enables us to learn interpretable and explainable models due to the more descriptive nature of the relational representation. We empirically demonstrate the effectiveness and interpretability of RB2 on tasks such as link prediction, relational classification, and recommendations.
Hypergraph Partitioning using Tensor Eigenvalue Decomposition
Nov 16, 2020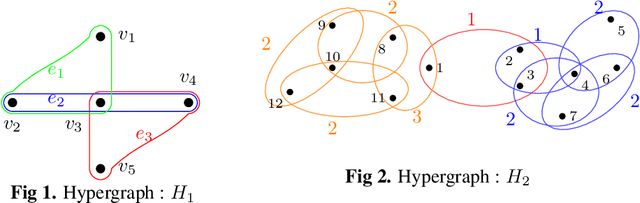
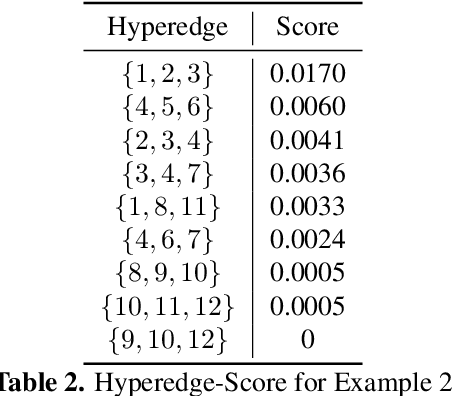
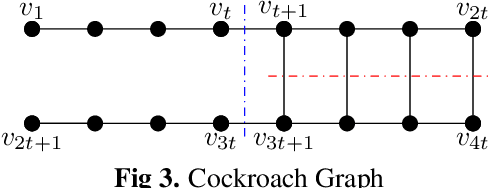

Hypergraphs have gained increasing attention in the machine learning community lately due to their superiority over graphs in capturing super-dyadic interactions among entities. In this work, we propose a novel approach for the partitioning of k-uniform hypergraphs. Most of the existing methods work by reducing the hypergraph to a graph followed by applying standard graph partitioning algorithms. The reduction step restricts the algorithms to capturing only some weighted pairwise interactions and hence loses essential information about the original hypergraph. We overcome this issue by utilizing the tensor-based representation of hypergraphs, which enables us to capture actual super-dyadic interactions. We prove that the hypergraph to graph reduction is a special case of tensor contraction. We extend the notion of minimum ratio-cut and normalized-cut from graphs to hypergraphs and show the relaxed optimization problem is equivalent to tensor eigenvalue decomposition. This novel formulation also enables us to capture different ways of cutting a hyperedge, unlike the existing reduction approaches. We propose a hypergraph partitioning algorithm inspired from spectral graph theory that can accommodate this notion of hyperedge cuts. We also derive a tighter upper bound on the minimum positive eigenvalue of even-order hypergraph Laplacian tensor in terms of its conductance, which is utilized in the partitioning algorithm to approximate the normalized cut. The efficacy of the proposed method is demonstrated numerically on simple hypergraphs. We also show improvement for the min-cut solution on 2-uniform hypergraphs (graphs) over the standard spectral partitioning algorithm.
Goal directed molecule generation using Monte Carlo Tree Search
Oct 30, 2020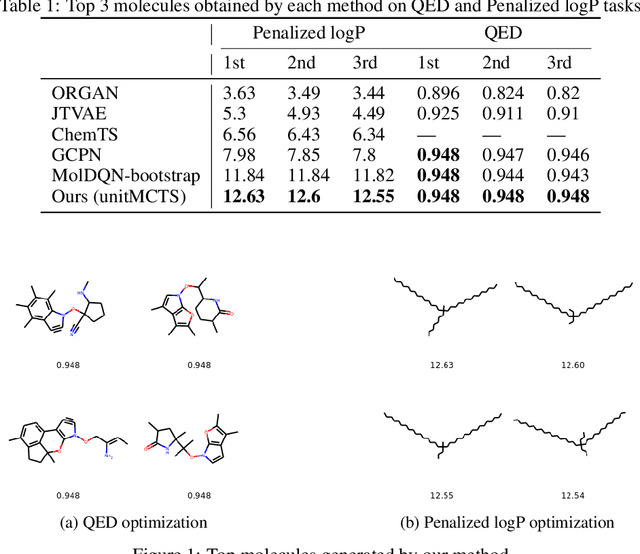
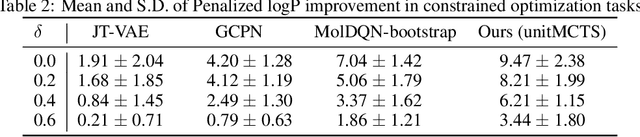
One challenging and essential task in biochemistry is the generation of novel molecules with desired properties. Novel molecule generation remains a challenge since the molecule space is difficult to navigate through, and the generated molecules should obey the rules of chemical valency. Through this work, we propose a novel method, which we call unitMCTS, to perform molecule generation by making a unit change to the molecule at every step using Monte Carlo Tree Search. We show that this method outperforms the recently published techniques on benchmark molecular optimization tasks such as QED and penalized logP. We also demonstrate the usefulness of this method in improving molecule properties while being similar to the starting molecule. Given that there is no learning involved, our method finds desired molecules within a shorter amount of time.
MADRaS : Multi Agent Driving Simulator
Oct 02, 2020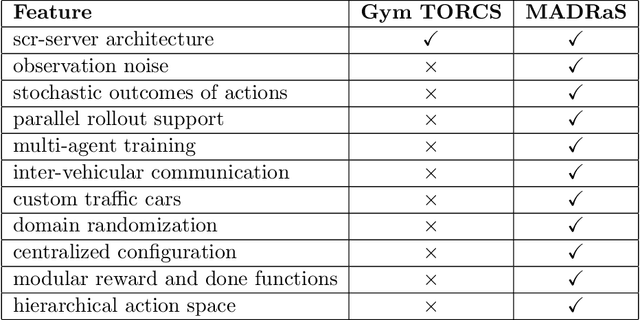
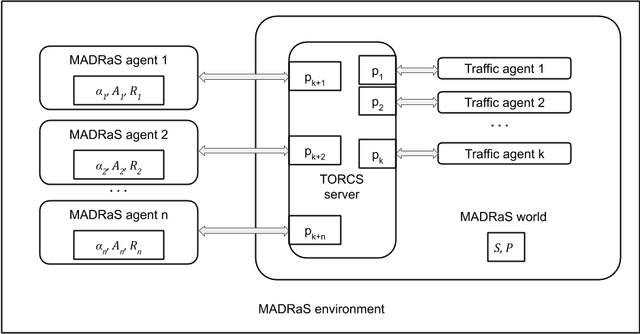

In this work, we present MADRaS, an open-source multi-agent driving simulator for use in the design and evaluation of motion planning algorithms for autonomous driving. MADRaS provides a platform for constructing a wide variety of highway and track driving scenarios where multiple driving agents can train for motion planning tasks using reinforcement learning and other machine learning algorithms. MADRaS is built on TORCS, an open-source car-racing simulator. TORCS offers a variety of cars with different dynamic properties and driving tracks with different geometries and surface properties. MADRaS inherits these functionalities from TORCS and introduces support for multi-agent training, inter-vehicular communication, noisy observations, stochastic actions, and custom traffic cars whose behaviours can be programmed to simulate challenging traffic conditions encountered in the real world. MADRaS can be used to create driving tasks whose complexities can be tuned along eight axes in well-defined steps. This makes it particularly suited for curriculum and continual learning. MADRaS is lightweight and it provides a convenient OpenAI Gym interface for independent control of each car. Apart from the primitive steering-acceleration-brake control mode of TORCS, MADRaS offers a hierarchical track-position -- speed control that can potentially be used to achieve better generalization. MADRaS uses multiprocessing to run each agent as a parallel process for efficiency and integrates well with popular reinforcement learning libraries like RLLib.
Reinforcement Learning for Improving Object Detection
Aug 18, 2020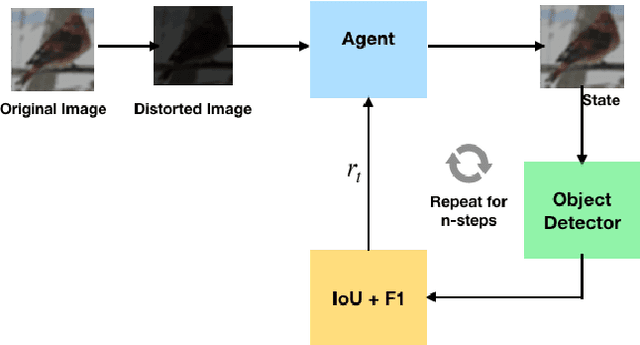
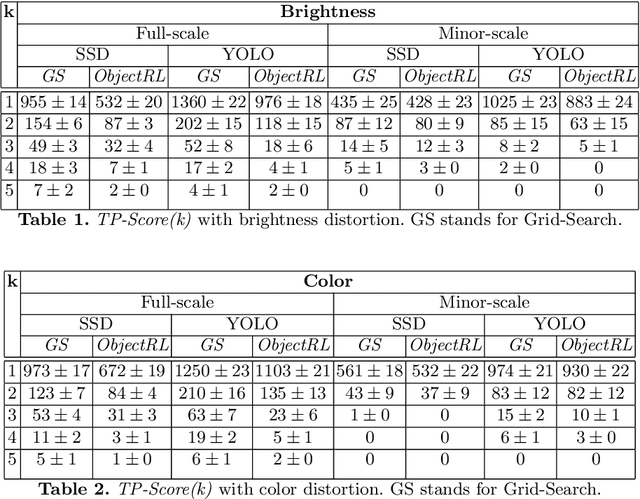


The performance of a trained object detection neural network depends a lot on the image quality. Generally, images are pre-processed before feeding them into the neural network and domain knowledge about the image dataset is used to choose the pre-processing techniques. In this paper, we introduce an algorithm called ObjectRL to choose the amount of a particular pre-processing to be applied to improve the object detection performances of pre-trained networks. The main motivation for ObjectRL is that an image which looks good to a human eye may not necessarily be the optimal one for a pre-trained object detector to detect objects.
A Causal Linear Model to Quantify Edge Unfairness for Unfair Edge Prioritization and Discrimination Removal
Jul 16, 2020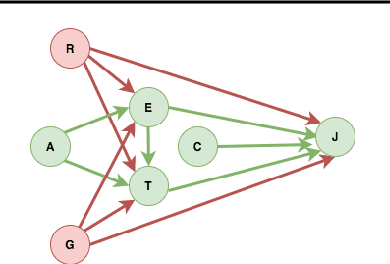
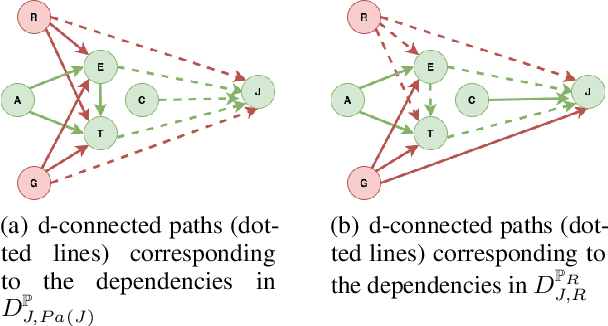
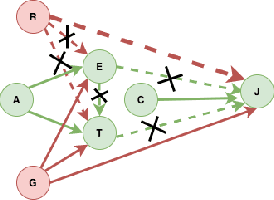
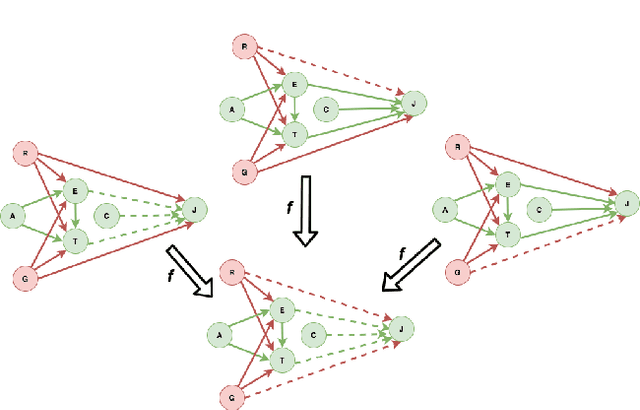
The dataset can be generated by an unfair mechanism in numerous settings. For instance, a judicial system is unfair if it rejects the bail plea of an accused based on the race. To mitigate the unfairness in the procedure generating the dataset, we need to know and quantify where the unfairness is originating from, how it affects the overall unfairness, and how to prioritize these sources of unfairness to address the real-world issues underlying these sources. Prior work of (Zhang, et al., 2017) identifies and removes discrimination after data is generated but does not suggest a methodology to mitigate unfairness in the data generation phase. We use the notion of an unfair edge, same as (Chiappa, et al., 2018), to be a source of discrimination and quantify unfairness along an unfair edge. We also quantify overall unfairness in a particular decision towards a subset of sensitive attributes in terms of edge unfairness and measure the sensitivity of the former when the latter is varied. Using the formulation of cumulative unfairness in terms of edge unfairness, we alter the discrimination removal methodology discussed in (Zhang, et al., 2017) by not formulating it as an optimization problem. This helps in getting rid of constraints that grow exponentially in the number of sensitive attributes and values taken by them. Finally, we discuss a priority algorithm for policymakers to address the real-world issues underlying the edges that result in unfairness. The experimental section validates the linear model assumption made to quantify edge unfairness.
Missed calls, Automated Calls and Health Support: Using AI to improve maternal health outcomes by increasing program engagement
Jul 06, 2020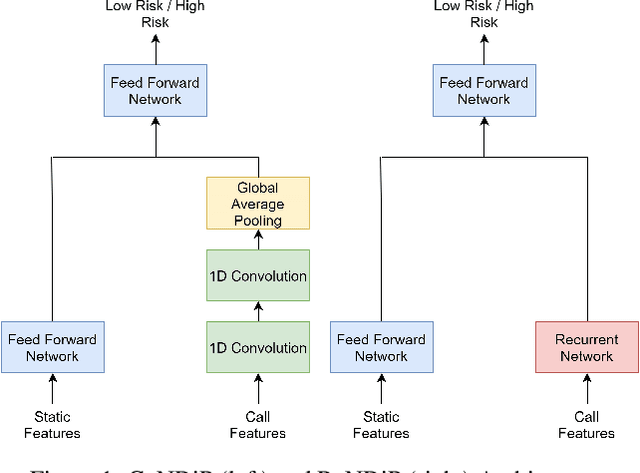
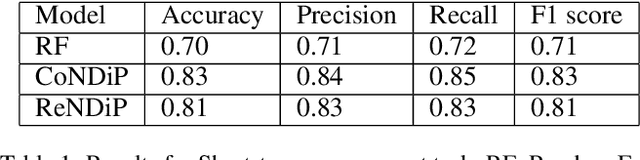
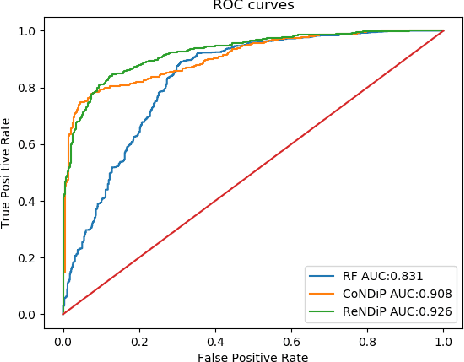
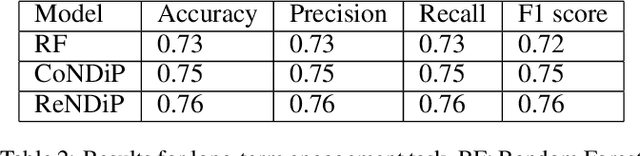
India accounts for 11% of maternal deaths globally where a woman dies in childbirth every fifteen minutes. Lack of access to preventive care information is a significant problem contributing to high maternal morbidity and mortality numbers, especially in low-income households. We work with ARMMAN, a non-profit based in India, to further the use of call-based information programs by early-on identifying women who might not engage on these programs that are proven to affect health parameters positively.We analyzed anonymized call-records of over 300,000 women registered in an awareness program created by ARMMAN that uses cellphone calls to regularly disseminate health related information. We built robust deep learning based models to predict short term and long term dropout risk from call logs and beneficiaries' demographic information. Our model performs 13% better than competitive baselines for short-term forecasting and 7% better for long term forecasting. We also discuss the applicability of this method in the real world through a pilot validation that uses our method to perform targeted interventions.
Reinforcement Learning for Multi-Product Multi-Node Inventory Management in Supply Chains
Jun 07, 2020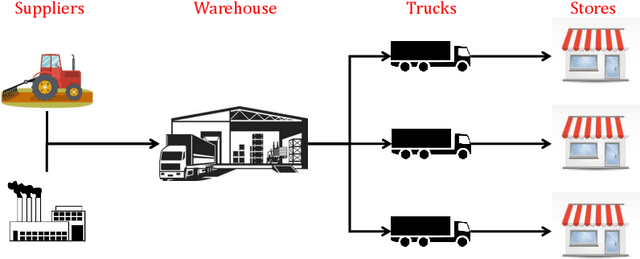

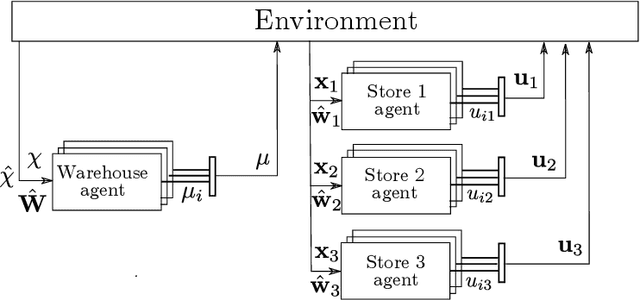
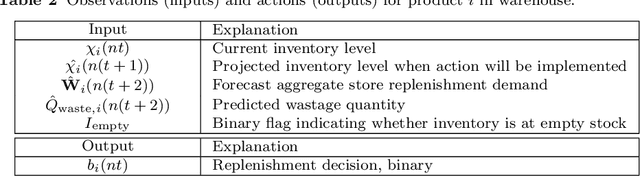
This paper describes the application of reinforcement learning (RL) to multi-product inventory management in supply chains. The problem description and solution are both adapted from a real-world business solution. The novelty of this problem with respect to supply chain literature is (i) we consider concurrent inventory management of a large number (50 to 1000) of products with shared capacity, (ii) we consider a multi-node supply chain consisting of a warehouse which supplies three stores, (iii) the warehouse, stores, and transportation from warehouse to stores have finite capacities, (iv) warehouse and store replenishment happen at different time scales and with realistic time lags, and (v) demand for products at the stores is stochastic. We describe a novel formulation in a multi-agent (hierarchical) reinforcement learning framework that can be used for parallelised decision-making, and use the advantage actor critic (A2C) algorithm with quantised action spaces to solve the problem. Experiments show that the proposed approach is able to handle a multi-objective reward comprised of maximising product sales and minimising wastage of perishable products.