 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-resolution Face Swapping via Latent Semantics Disentanglement
Mar 30, 2022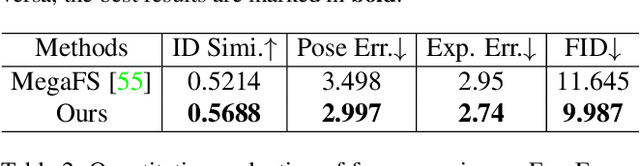
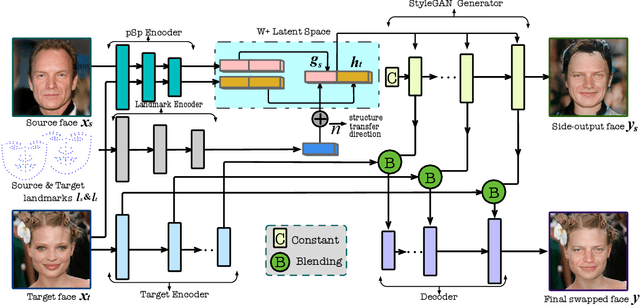
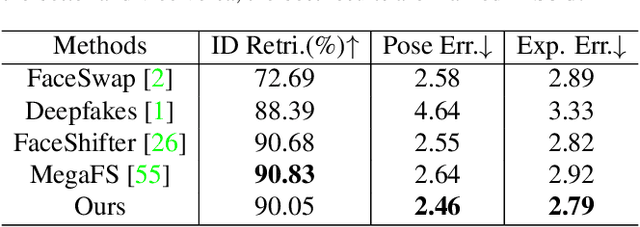

We present a novel high-resolution face swapping method using the inherent prior knowledge of a pre-trained GAN model. Although previous research can leverage generative priors to produce high-resolution results, their quality can suffer from the entangled semantics of the latent space. We explicitly disentangle the latent semantics by utilizing the progressive nature of the generator, deriving structure attributes from the shallow layers and appearance attributes from the deeper ones. Identity and pose information within the structure attributes are further separated by introducing a landmark-driven structure transfer latent direction. The disentangled latent code produces rich generative features that incorporate feature blending to produce a plausible swapping result. We further extend our method to video face swapping by enforcing two spatio-temporal constraints on the latent space and the image space. Extensive experiments demonstrate that the proposed method outperforms state-of-the-art image/video face swapping methods in terms of hallucination quality and consistency. Code can be found at: https://github.com/cnnlstm/FSLSD_HiRes.
A Survey of Non-Rigid 3D Registration
Mar 16, 2022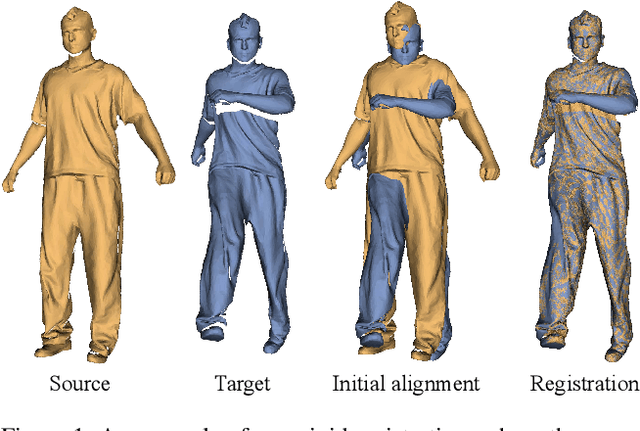
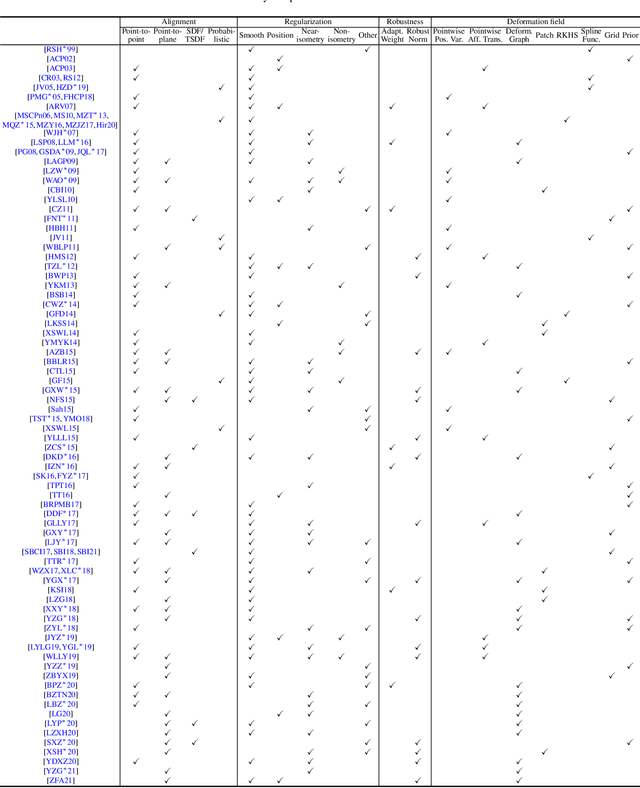

Non-rigid registration computes an alignment between a source surface with a target surface in a non-rigid manner. In the past decade, with the advances in 3D sensing technologies that can measure time-varying surfaces, non-rigid registration has been applied for the acquisition of deformable shapes and has a wide range of applications. This survey presents a comprehensive review of non-rigid registration methods for 3D shapes, focusing on techniques related to dynamic shape acquisition and reconstruction. In particular, we review different approaches for representing the deformation field, and the methods for computing the desired deformation. Both optimization-based and learning-based methods are covered. We also review benchmarks and datasets for evaluating non-rigid registration methods, and discuss potential future research directions.
Sketch2PQ: Freeform Planar Quadrilateral Mesh Design via a Single Sketch
Jan 23, 2022
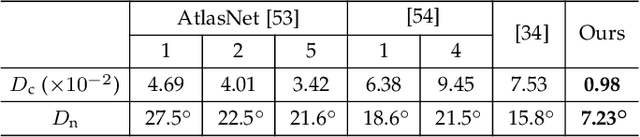
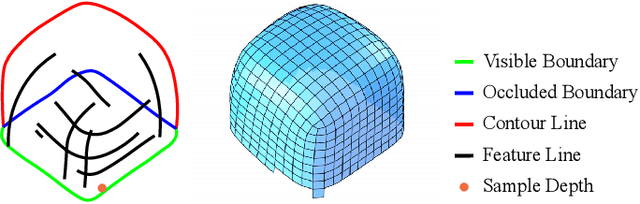
The freeform architectural modeling process often involves two important stages: concept design and digital modeling. In the first stage, architects usually sketch the overall 3D shape and the panel layout on a physical or digital paper briefly. In the second stage, a digital 3D model is created using the sketching as the reference. The digital model needs to incorporate geometric requirements for its components, such as planarity of panels due to consideration of construction costs, which can make the modeling process more challenging. In this work, we present a novel sketch-based system to bridge the concept design and digital modeling of freeform roof-like shapes represented as planar quadrilateral (PQ) meshes. Our system allows the user to sketch the surface boundary and contour lines under axonometric projection and supports the sketching of occluded regions. In addition, the user can sketch feature lines to provide directional guidance to the PQ mesh layout. Given the 2D sketch input, we propose a deep neural network to infer in real-time the underlying surface shape along with a dense conjugate direction field, both of which are used to extract the final PQ mesh. To train and validate our network, we generate a large synthetic dataset that mimics architect sketching of freeform quadrilateral patches. The effectiveness and usability of our system are demonstrated with quantitative and qualitative evaluation as well as user studies.
A Robust Loss for Point Cloud Registration
Aug 26, 2021
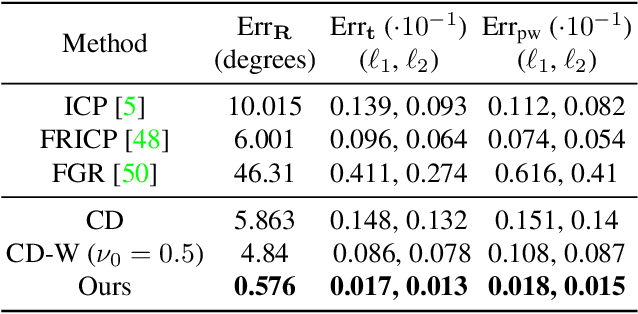
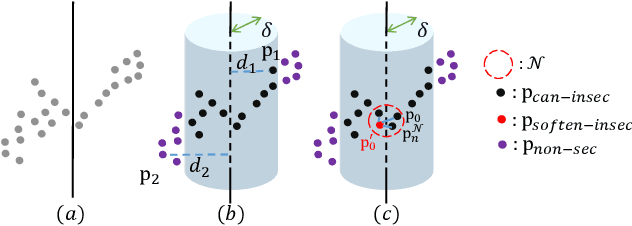
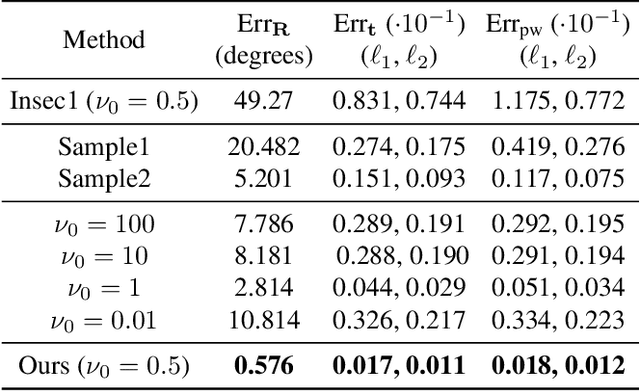
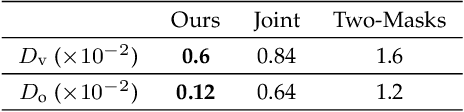
The performance of surface registration relies heavily on the metric used for the alignment error between the source and target shapes. Traditionally, such a metric is based on the point-to-point or point-to-plane distance from the points on the source surface to their closest points on the target surface, which is susceptible to failure due to instability of the closest-point correspondence. In this paper, we propose a novel metric based on the intersection points between the two shapes and a random straight line, which does not assume a specific correspondence. We verify the effectiveness of this metric by extensive experiments, including its direct optimization for a single registration problem as well as unsupervised learning for a set of registration problems. The results demonstrate that the algorithms utilizing our proposed metric outperforms the state-of-the-art optimization-based and unsupervised learning-based methods.
Regularization of Persistent Homology Gradient Computation
Nov 14, 2020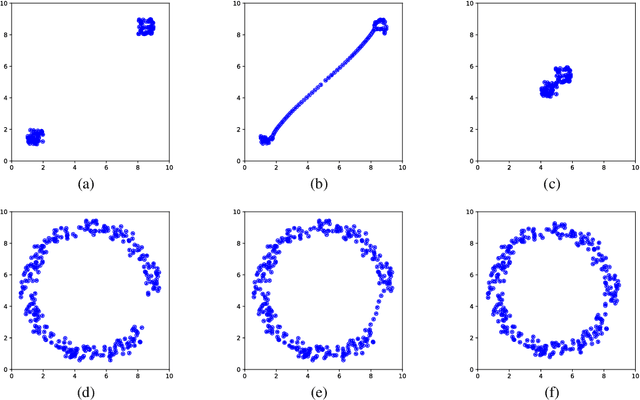
Persistent homology is a method for computing the topological features present in a given data. Recently, there has been much interest in the integration of persistent homology as a computational step in neural networks or deep learning. In order for a given computation to be integrated in such a way, the computation in question must be differentiable. Computing the gradients of persistent homology is an ill-posed inverse problem with infinitely many solutions. Consequently, it is important to perform regularization so that the solution obtained agrees with known priors. In this work we propose a novel method for regularizing persistent homology gradient computation through the addition of a grouping term. This has the effect of helping to ensure gradients are defined with respect to larger entities and not individual points.
Fast and Robust Iterative Closet Point
Jul 15, 2020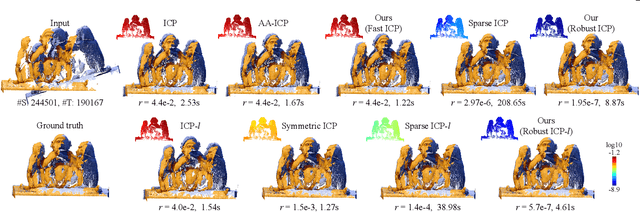
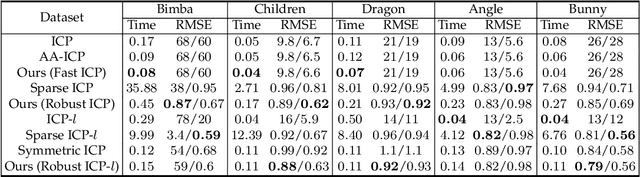
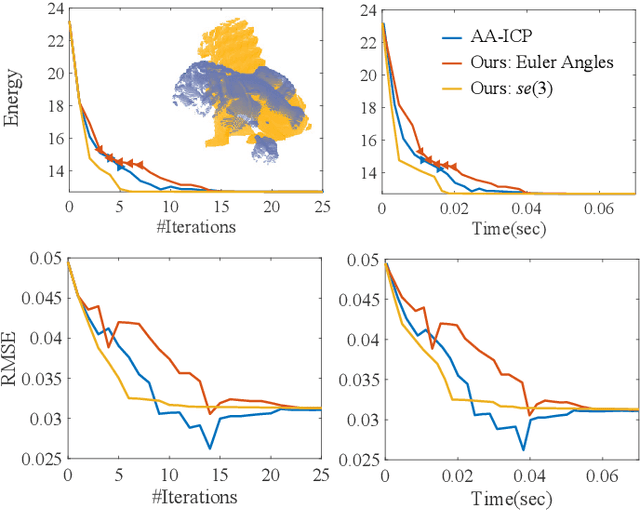
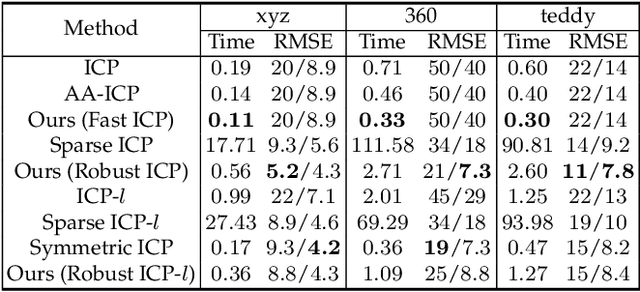
The Iterative Closest Point (ICP) algorithm and its variants are a fundamental technique for rigid registration between two point sets, with wide applications in different areas from robotics to 3D reconstruction. The main drawbacks for ICP are its slow convergence as well as its sensitivity to outliers, missing data, and partial overlaps. Recent work such as Sparse ICP achieves robustness via sparsity optimization at the cost of computational speed. In this paper, we propose a new method for robust registration with fast convergence. First, we show that the classical point-to-point ICP can be treated as a majorization-minimization (MM) algorithm, and propose an Anderson acceleration approach to improve its convergence. In addition, we introduce a robust error metric based on the Welsch's function, which is minimized efficiently using the MM algorithm with Anderson acceleration. On challenging datasets with noises and partial overlaps, we achieve similar or better accuracy than Sparse ICP while being at least an order of magnitude faster. Finally, we extend the robust formulation to point-to-plane ICP, and solve the resulting problem using a similar Anderson-accelerated MM strategy. Our robust ICP methods improve the registration accuracy on benchmark datasets while being competitive in computational time.
Quasi-Newton Solver for Robust Non-Rigid Registration
Apr 09, 2020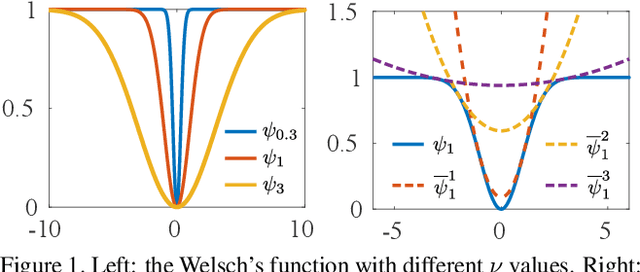
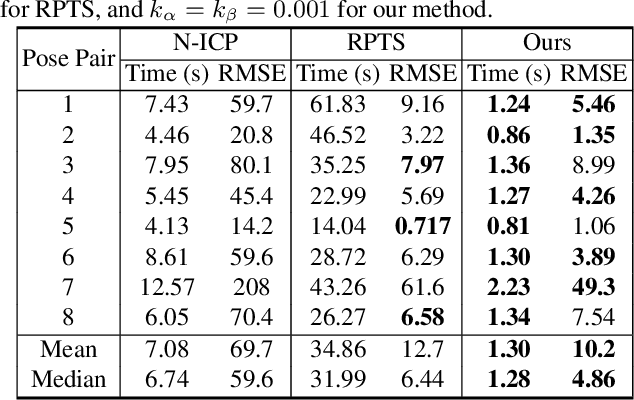
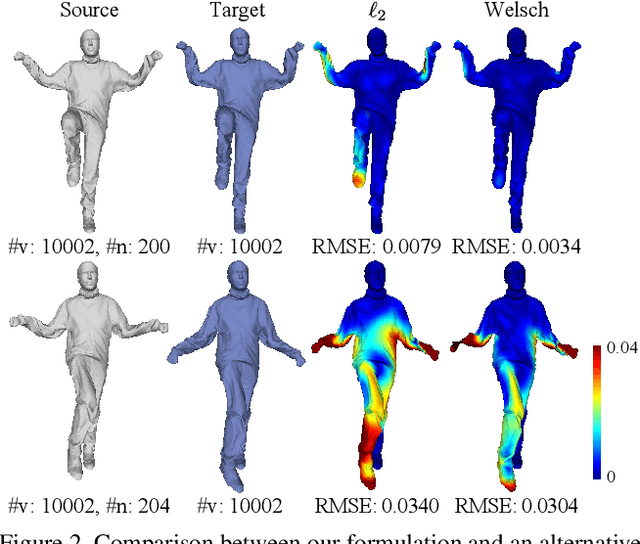
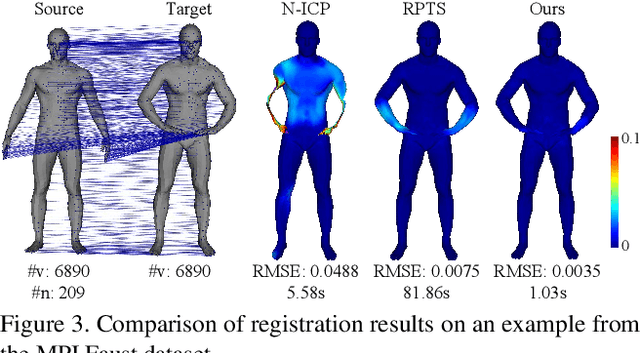
Imperfect data (noise, outliers and partial overlap) and high degrees of freedom make non-rigid registration a classical challenging problem in computer vision. Existing methods typically adopt the $\ell_{p}$ type robust estimator to regularize the fitting and smoothness, and the proximal operator is used to solve the resulting non-smooth problem. However, the slow convergence of these algorithms limits its wide applications. In this paper, we propose a formulation for robust non-rigid registration based on a globally smooth robust estimator for data fitting and regularization, which can handle outliers and partial overlaps. We apply the majorization-minimization algorithm to the problem, which reduces each iteration to solving a simple least-squares problem with L-BFGS. Extensive experiments demonstrate the effectiveness of our method for non-rigid alignment between two shapes with outliers and partial overlap, with quantitative evaluation showing that it outperforms state-of-the-art methods in terms of registration accuracy and computational speed. The source code is available at https://github.com/Juyong/Fast_RNRR.
Lightweight Photometric Stereo for Facial Details Recovery
Mar 27, 2020

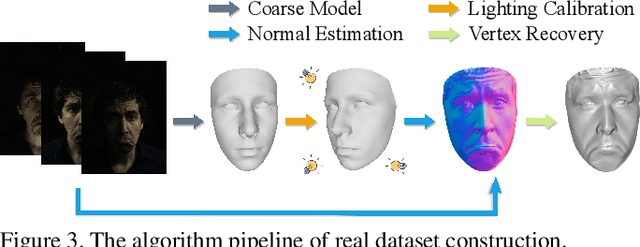
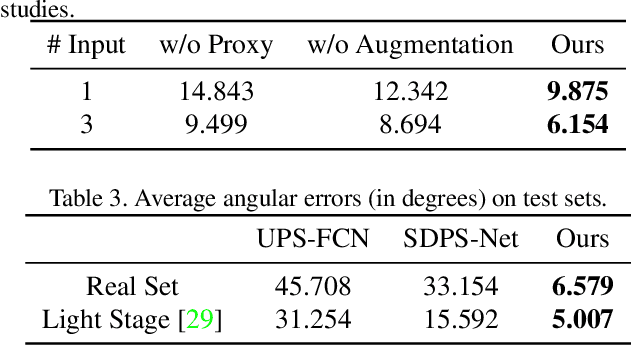
Recently, 3D face reconstruction from a single image has achieved great success with the help of deep learning and shape prior knowledge, but they often fail to produce accurate geometry details. On the other hand, photometric stereo methods can recover reliable geometry details, but require dense inputs and need to solve a complex optimization problem. In this paper, we present a lightweight strategy that only requires sparse inputs or even a single image to recover high-fidelity face shapes with images captured under near-field lights. To this end, we construct a dataset containing 84 different subjects with 29 expressions under 3 different lights. Data augmentation is applied to enrich the data in terms of diversity in identity, lighting, expression, etc. With this constructed dataset, we propose a novel neural network specially designed for photometric stereo based 3D face reconstruction. Extensive experiments and comparisons demonstrate that our method can generate high-quality reconstruction results with one to three facial images captured under near-field lights. Our full framework is available at https://github.com/Juyong/FacePSNet.
Robust RGB-D Face Recognition Using Attribute-Aware Loss
Nov 24, 2018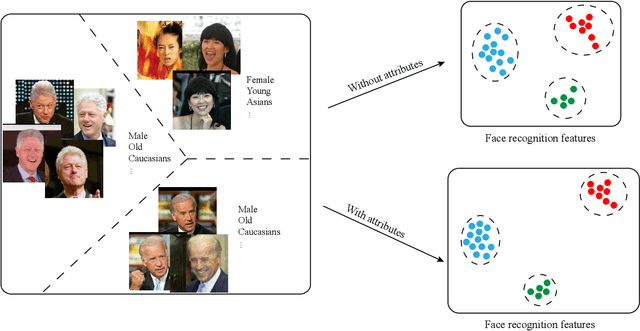
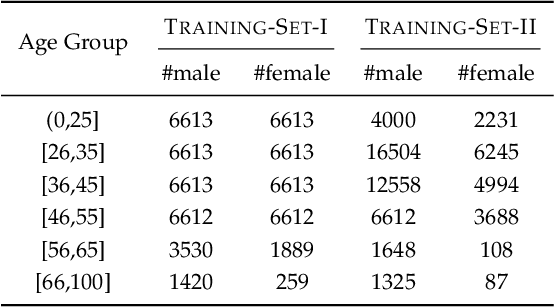
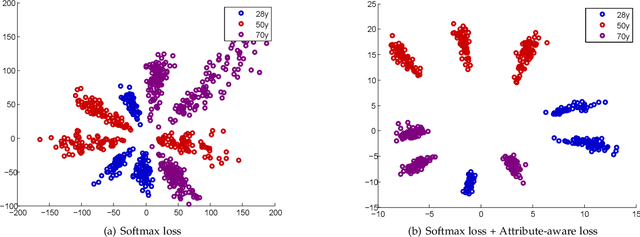
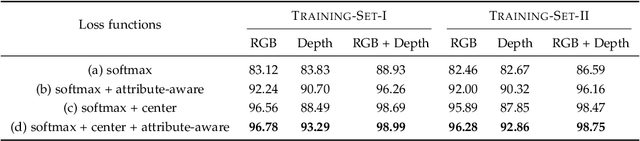
Existing convolutional neural network (CNN) based face recognition algorithms typically learn a discriminative feature mapping, using a loss function that enforces separation of features from different classes and/or aggregation of features within the same class. However, they may suffer from bias in the training data such as uneven sampling density, because they optimize the adjacency relationship of the learned features without considering the proximity of the underlying faces. Moreover, since they only use facial images for training, the learned feature mapping may not correctly indicate the relationship of other attributes such as gender and ethnicity, which can be important for some face recognition applications. In this paper, we propose a new CNN-based face recognition approach that incorporates such attributes into the training process. Using an attribute-aware loss function that regularizes the feature mapping using attribute proximity, our approach learns more discriminative features that are correlated with the attributes. We train our face recognition model on a large-scale RGB-D data set with over 100K identities captured under real application conditions. By comparing our approach with other methods on a variety of experiments, we demonstrate that depth channel and attribute-aware loss greatly improve the accuracy and robustness of face recognition.
3D Face Reconstruction with Geometry Details from a Single Image
Jun 11, 2018
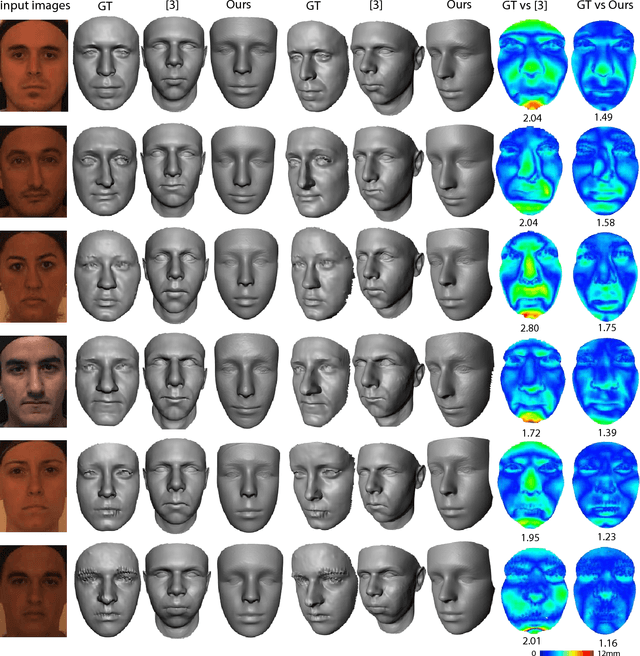


3D face reconstruction from a single image is a classical and challenging problem, with wide applications in many areas. Inspired by recent works in face animation from RGB-D or monocular video inputs, we develop a novel method for reconstructing 3D faces from unconstrained 2D images, using a coarse-to-fine optimization strategy. First, a smooth coarse 3D face is generated from an example-based bilinear face model, by aligning the projection of 3D face landmarks with 2D landmarks detected from the input image. Afterwards, using local corrective deformation fields, the coarse 3D face is refined using photometric consistency constraints, resulting in a medium face shape. Finally, a shape-from-shading method is applied on the medium face to recover fine geometric details. Our method outperforms state-of-the-art approaches in terms of accuracy and detail recovery, which is demonstrated in extensive experiments using real world models and publicly available datasets.