 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZeroSumEval: Scaling LLM Evaluation with Inter-Model Competition
Apr 17, 2025



Evaluating the capabilities of Large Language Models (LLMs) has traditionally relied on static benchmark datasets, human assessments, or model-based evaluations - methods that often suffer from overfitting, high costs, and biases. ZeroSumEval is a novel competition-based evaluation protocol that leverages zero-sum games to assess LLMs with dynamic benchmarks that resist saturation. ZeroSumEval encompasses a diverse suite of games, including security challenges (PyJail), classic games (Chess, Liar's Dice, Poker), knowledge tests (MathQuiz), and persuasion challenges (Gandalf, Debate). These games are designed to evaluate a range of AI capabilities such as strategic reasoning, planning, knowledge application, and creativity. Building upon recent studies that highlight the effectiveness of game-based evaluations for LLMs, ZeroSumEval enhances these approaches by providing a standardized and extensible framework. To demonstrate this, we conduct extensive experiments with >7000 simulations across 7 games and 13 models. Our results show that while frontier models from the GPT and Claude families can play common games and answer questions, they struggle to play games that require creating novel and challenging questions. We also observe that models cannot reliably jailbreak each other and fail generally at tasks requiring creativity. We release our code at https://github.com/facebookresearch/ZeroSumEval.
SeizureTransformer: Scaling U-Net with Transformer for Simultaneous Time-Step Level Seizure Detection from Long EEG Recordings
Apr 02, 2025Epilepsy is a common neurological disorder that affects around 65 million people worldwide. Detecting seizures quickly and accurately is vital, given the prevalence and severity of the associated complications. Recently, deep learning-based automated seizure detection methods have emerged as solutions; however, most existing methods require extensive post-processing and do not effectively handle the crucial long-range patterns in EEG data. In this work, we propose SeizureTransformer, a simple model comprised of (i) a deep encoder comprising 1D convolutions (ii) a residual CNN stack and a transformer encoder to embed previous output into high-level representation with contextual information, and (iii) streamlined decoder which converts these features into a sequence of probabilities, directly indicating the presence or absence of seizures at every time step. Extensive experiments on public and private EEG seizure detection datasets demonstrate that our model significantly outperforms existing approaches (ranked in the first place in the 2025 "seizure detection challenge" organized in the International Conference on Artificial Intelligence in Epilepsy and Other Neurological Disorders), underscoring its potential for real-time, precise seizure detection.
Exploiting the Data Gap: Utilizing Non-ignorable Missingness to Manipulate Model Learning
Sep 06, 2024



Missing data is commonly encountered in practice, and when the missingness is non-ignorable, effective remediation depends on knowledge of the missingness mechanism. Learning the underlying missingness mechanism from the data is not possible in general, so adversaries can exploit this fact by maliciously engineering non-ignorable missingness mechanisms. Such Adversarial Missingness (AM) attacks have only recently been motivated and introduced, and then successfully tailored to mislead causal structure learning algorithms into hiding specific cause-and-effect relationships. However, existing AM attacks assume the modeler (victim) uses full-information maximum likelihood methods to handle the missing data, and are of limited applicability when the modeler uses different remediation strategies. In this work we focus on associational learning in the context of AM attacks. We consider (i) complete case analysis, (ii) mean imputation, and (iii) regression-based imputation as alternative strategies used by the modeler. Instead of combinatorially searching for missing entries, we propose a novel probabilistic approximation by deriving the asymptotic forms of these methods used for handling the missing entries. We then formulate the learning of the adversarial missingness mechanism as a bi-level optimization problem. Experiments on generalized linear models show that AM attacks can be used to change the p-values of features from significant to insignificant in real datasets, such as the California-housing dataset, while using relatively moderate amounts of missingness (<20%). Additionally, we assess the robustness of our attacks against defense strategies based on data valuation.
Deception by Omission: Using Adversarial Missingness to Poison Causal Structure Learning
May 31, 2023



Inference of causal structures from observational data is a key component of causal machine learning; in practice, this data may be incompletely observed. Prior work has demonstrated that adversarial perturbations of completely observed training data may be used to force the learning of inaccurate causal structural models (SCMs). However, when the data can be audited for correctness (e.g., it is crytographically signed by its source), this adversarial mechanism is invalidated. This work introduces a novel attack methodology wherein the adversary deceptively omits a portion of the true training data to bias the learned causal structures in a desired manner. Theoretically sound attack mechanisms are derived for the case of arbitrary SCMs, and a sample-efficient learning-based heuristic is given for Gaussian SCMs. Experimental validation of these approaches on real and synthetic data sets demonstrates the effectiveness of adversarial missingness attacks at deceiving popular causal structure learning algorithms.
Missing Value Knockoffs
Feb 26, 2022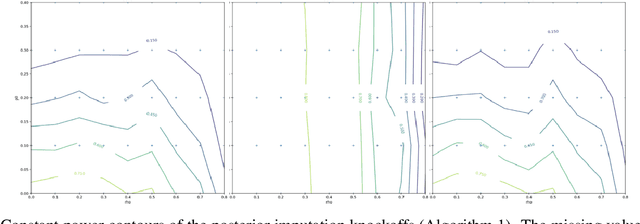
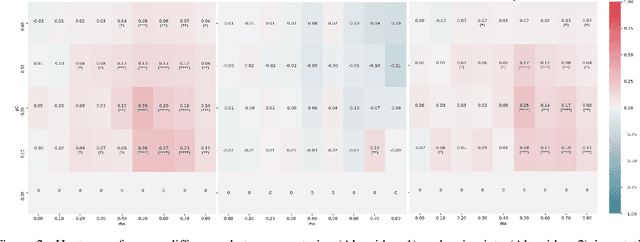
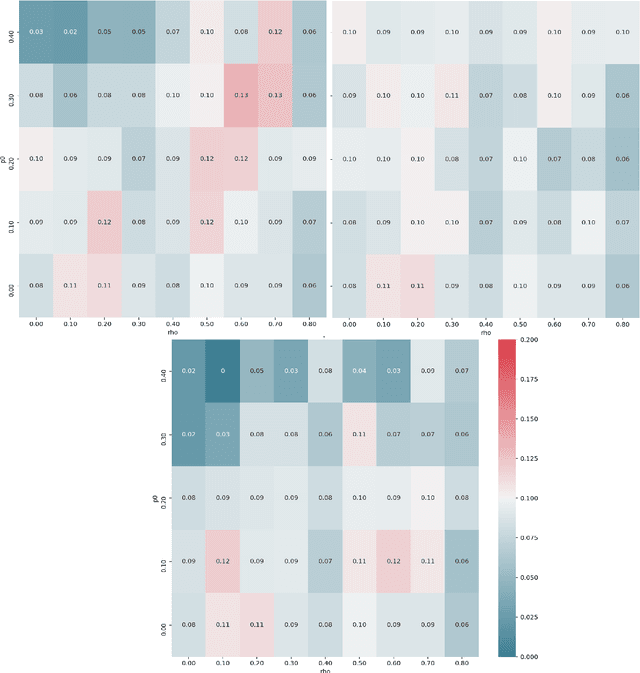
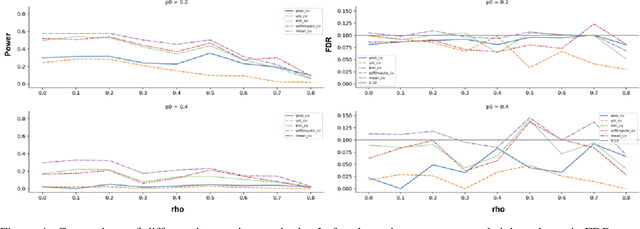
One limitation of the most statistical/machine learning-based variable selection approaches is their inability to control the false selections. A recently introduced framework, model-x knockoffs, provides that to a wide range of models but lacks support for datasets with missing values. In this work, we discuss ways of preserving the theoretical guarantees of the model-x framework in the missing data setting. First, we prove that posterior sampled imputation allows reusing existing knockoff samplers in the presence of missing values. Second, we show that sampling knockoffs only for the observed variables and applying univariate imputation also preserves the false selection guarantees. Third, for the special case of latent variable models, we demonstrate how jointly imputing and sampling knockoffs can reduce the computational complexity. We have verified the theoretical findings with two different exploratory variable distributions and investigated how the missing data pattern, amount of correlation, the number of observations, and missing values affected the statistical power.
Output Randomization: A Novel Defense for both White-box and Black-box Adversarial Models
Jul 08, 2021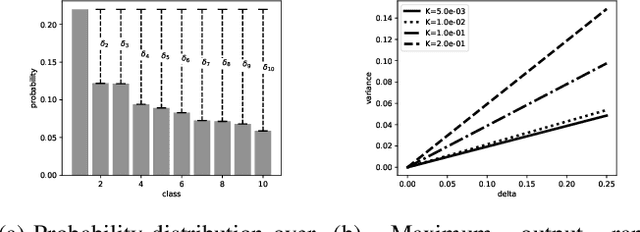
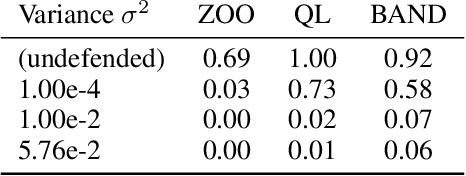
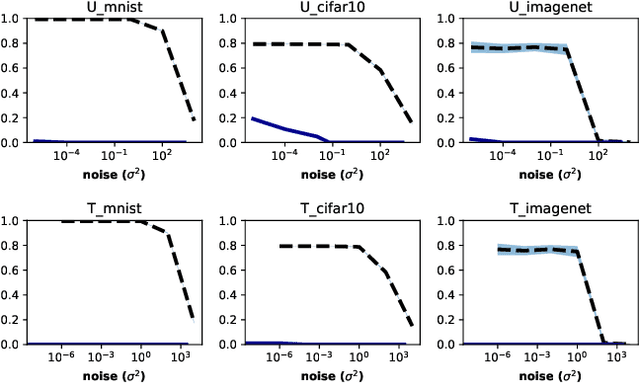
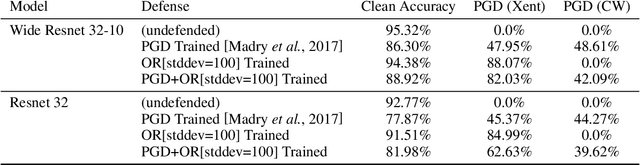
Adversarial examples pose a threat to deep neural network models in a variety of scenarios, from settings where the adversary has complete knowledge of the model in a "white box" setting and to the opposite in a "black box" setting. In this paper, we explore the use of output randomization as a defense against attacks in both the black box and white box models and propose two defenses. In the first defense, we propose output randomization at test time to thwart finite difference attacks in black box settings. Since this type of attack relies on repeated queries to the model to estimate gradients, we investigate the use of randomization to thwart such adversaries from successfully creating adversarial examples. We empirically show that this defense can limit the success rate of a black box adversary using the Zeroth Order Optimization attack to 0%. Secondly, we propose output randomization training as a defense against white box adversaries. Unlike prior approaches that use randomization, our defense does not require its use at test time, eliminating the Backward Pass Differentiable Approximation attack, which was shown to be effective against other randomization defenses. Additionally, this defense has low overhead and is easily implemented, allowing it to be used together with other defenses across various model architectures. We evaluate output randomization training against the Projected Gradient Descent attacker and show that the defense can reduce the PGD attack's success rate down to 12% when using cross-entropy loss.
Patient-Specific Seizure Prediction Using Single Seizure Electroencephalography Recording
Nov 14, 2020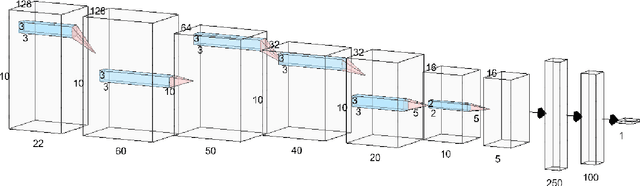
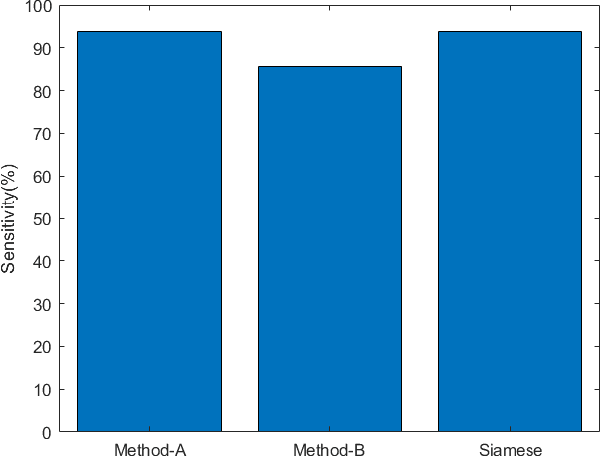
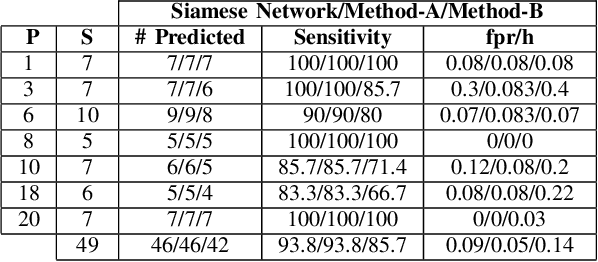
Electroencephalogram (EEG) is a prominent way to measure the brain activity for studying epilepsy, thereby helping in predicting seizures. Seizure prediction is an active research area with many deep learning based approaches dominating the recent literature for solving this problem. But these models require a considerable number of patient-specific seizures to be recorded for extracting the preictal and interictal EEG data for training a classifier. The increase in sensitivity and specificity for seizure prediction using the machine learning models is noteworthy. However, the need for a significant number of patient-specific seizures and periodic retraining of the model because of non-stationary EEG creates difficulties for designing practical device for a patient. To mitigate this process, we propose a Siamese neural network based seizure prediction method that takes a wavelet transformed EEG tensor as an input with convolutional neural network (CNN) as the base network for detecting change-points in EEG. Compared to the solutions in the literature, which utilize days of EEG recordings, our method only needs one seizure for training which translates to less than ten minutes of preictal and interictal data while still getting comparable results to models which utilize multiple seizures for seizure prediction.
Towards Obfuscated Malware Detection for Low Powered IoT Devices
Nov 06, 2020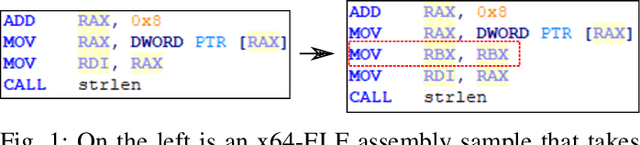
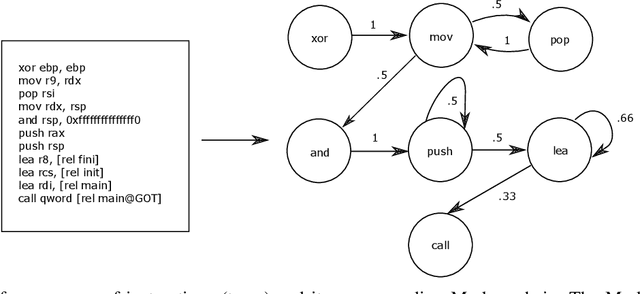
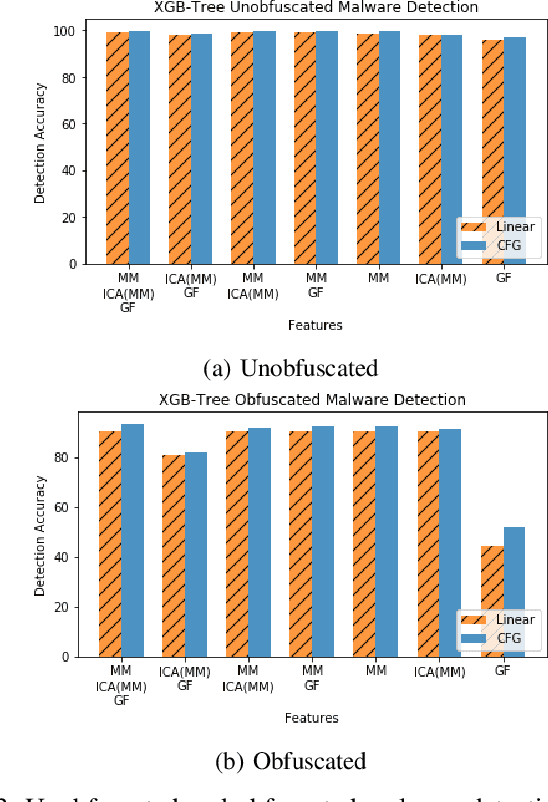
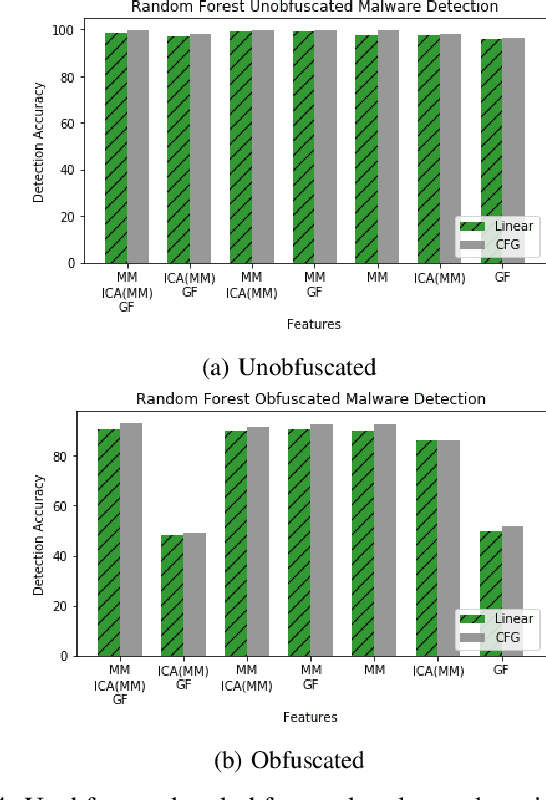
With the increased deployment of IoT and edge devices into commercial and user networks, these devices have become a new threat vector for malware authors. It is imperative to protect these devices as they become more prevalent in commercial and personal networks. However, due to their limited computational power and storage space, especially in the case of battery-powered devices, it is infeasible to deploy state-of-the-art malware detectors onto these systems. In this work, we propose using and extracting features from Markov matrices constructed from opcode traces as a low cost feature for unobfuscated and obfuscated malware detection. We empirically show that our approach maintains a high detection rate while consuming less power than similar work.
A survey on practical adversarial examples for malware classifiers
Nov 06, 2020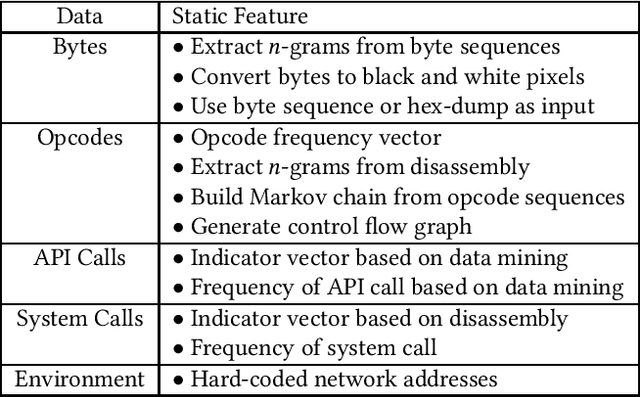
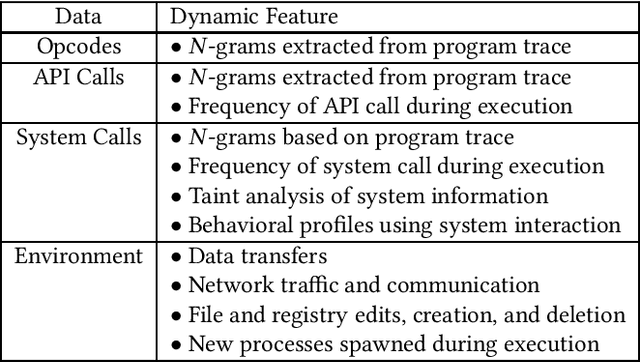
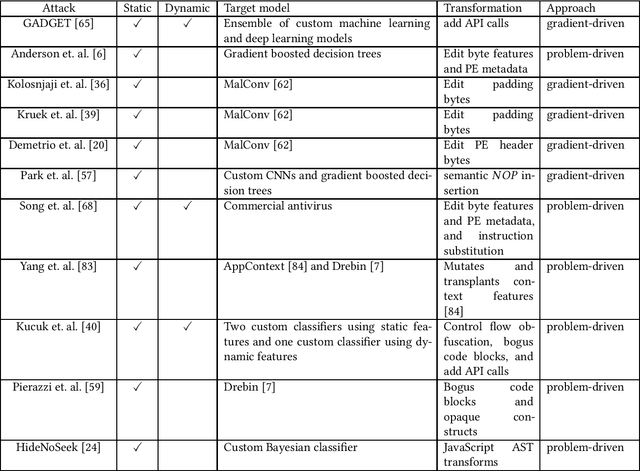
Machine learning based solutions have been very helpful in solving problems that deal with immense amounts of data, such as malware detection and classification. However, deep neural networks have been found to be vulnerable to adversarial examples, or inputs that have been purposefully perturbed to result in an incorrect label. Researchers have shown that this vulnerability can be exploited to create evasive malware samples. However, many proposed attacks do not generate an executable and instead generate a feature vector. To fully understand the impact of adversarial examples on malware detection, we review practical attacks against malware classifiers that generate executable adversarial malware examples. We also discuss current challenges in this area of research, as well as suggestions for improvement and future research directions.
Image-driven discriminative and generative machine learning algorithms for establishing microstructure-processing relationships
Jul 27, 2020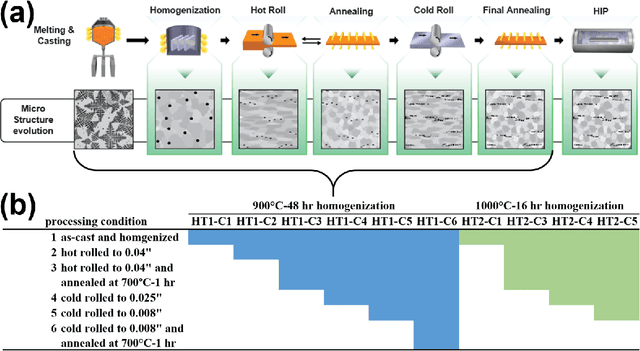

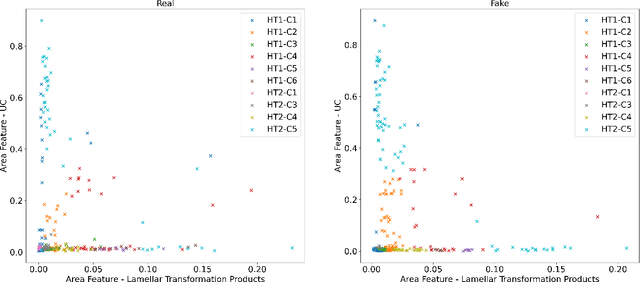
We investigate methods of microstructure representation for the purpose of predicting processing condition from microstructure image data. A binary alloy (uranium-molybdenum) that is currently under development as a nuclear fuel was studied for the purpose of developing an improved machine learning approach to image recognition, characterization, and building predictive capabilities linking microstructure to processing conditions. Here, we test different microstructure representations and evaluate model performance based on the F1 score. A F1 score of 95.1% was achieved for distinguishing between micrographs corresponding to ten different thermo-mechanical material processing conditions. We find that our newly developed microstructure representation describes image data well, and the traditional approach of utilizing area fractions of different phases is insufficient for distinguishing between multiple classes using a relatively small, imbalanced original data set of 272 images. To explore the applicability of generative methods for supplementing such limited data sets, generative adversarial networks were trained to generate artificial microstructure images. Two different generative networks were trained and tested to assess performance. Challenges and best practices associated with applying machine learning to limited microstructure image data sets is also discussed. Our work has implications for quantitative microstructure analysis, and development of microstructure-processing relationships in limited data sets typical of metallurgical process design studies.