 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting the Data Gap: Utilizing Non-ignorable Missingness to Manipulate Model Learning
Sep 06, 2024



Missing data is commonly encountered in practice, and when the missingness is non-ignorable, effective remediation depends on knowledge of the missingness mechanism. Learning the underlying missingness mechanism from the data is not possible in general, so adversaries can exploit this fact by maliciously engineering non-ignorable missingness mechanisms. Such Adversarial Missingness (AM) attacks have only recently been motivated and introduced, and then successfully tailored to mislead causal structure learning algorithms into hiding specific cause-and-effect relationships. However, existing AM attacks assume the modeler (victim) uses full-information maximum likelihood methods to handle the missing data, and are of limited applicability when the modeler uses different remediation strategies. In this work we focus on associational learning in the context of AM attacks. We consider (i) complete case analysis, (ii) mean imputation, and (iii) regression-based imputation as alternative strategies used by the modeler. Instead of combinatorially searching for missing entries, we propose a novel probabilistic approximation by deriving the asymptotic forms of these methods used for handling the missing entries. We then formulate the learning of the adversarial missingness mechanism as a bi-level optimization problem. Experiments on generalized linear models show that AM attacks can be used to change the p-values of features from significant to insignificant in real datasets, such as the California-housing dataset, while using relatively moderate amounts of missingness (<20%). Additionally, we assess the robustness of our attacks against defense strategies based on data valuation.
Deception by Omission: Using Adversarial Missingness to Poison Causal Structure Learning
May 31, 2023



Inference of causal structures from observational data is a key component of causal machine learning; in practice, this data may be incompletely observed. Prior work has demonstrated that adversarial perturbations of completely observed training data may be used to force the learning of inaccurate causal structural models (SCMs). However, when the data can be audited for correctness (e.g., it is crytographically signed by its source), this adversarial mechanism is invalidated. This work introduces a novel attack methodology wherein the adversary deceptively omits a portion of the true training data to bias the learned causal structures in a desired manner. Theoretically sound attack mechanisms are derived for the case of arbitrary SCMs, and a sample-efficient learning-based heuristic is given for Gaussian SCMs. Experimental validation of these approaches on real and synthetic data sets demonstrates the effectiveness of adversarial missingness attacks at deceiving popular causal structure learning algorithms.
Differentially-Private "Draw and Discard" Machine Learning
Oct 10, 2018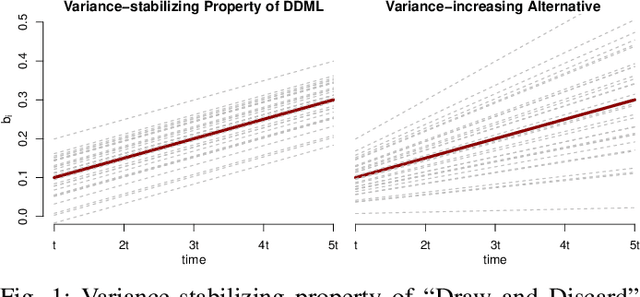
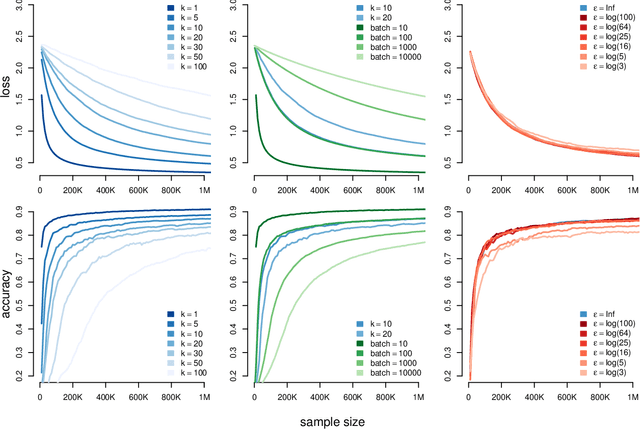
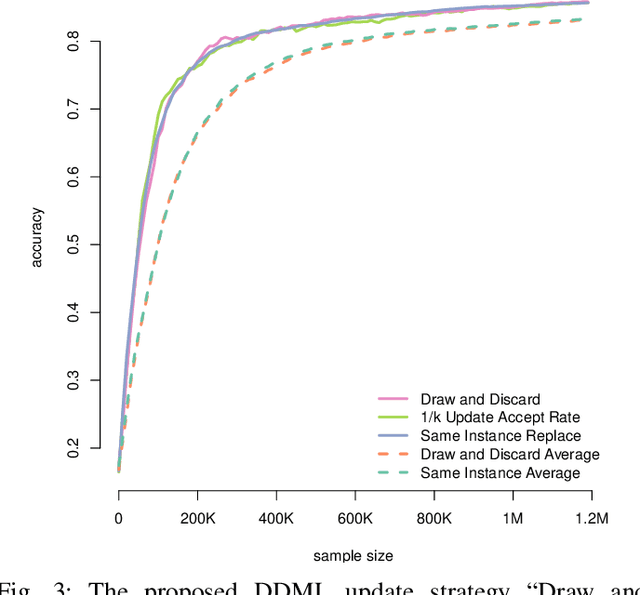
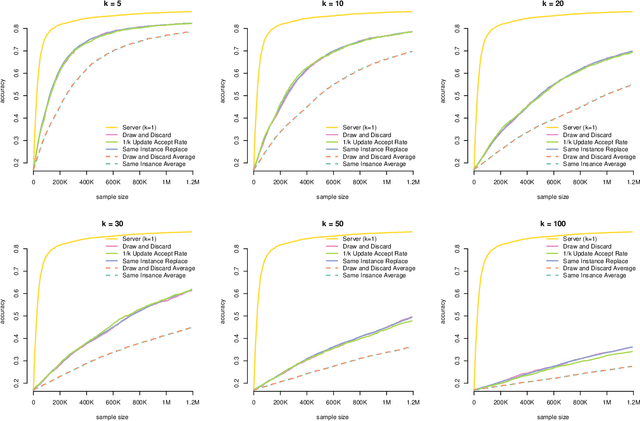
In this work, we propose a novel framework for privacy-preserving client-distributed machine learning. It is motivated by the desire to achieve differential privacy guarantees in the local model of privacy in a way that satisfies all systems constraints using asynchronous client-server communication and provides attractive model learning properties. We call it "Draw and Discard" because it relies on random sampling of models for load distribution (scalability), which also provides additional server-side privacy protections and improved model quality through averaging. We present the mechanics of client and server components of "Draw and Discard" and demonstrate how the framework can be applied to learning Generalized Linear models. We then analyze the privacy guarantees provided by our approach against several types of adversaries and showcase experimental results that provide evidence for the framework's viability in practical deployments.