 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplETR: Reducing the cost of annotations for object detection in dense scenes with vision transformers
Sep 13, 2022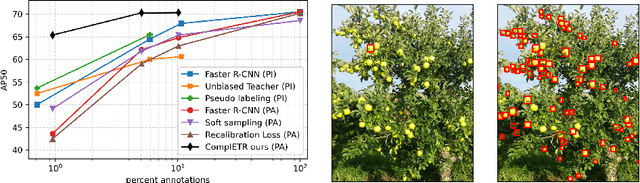
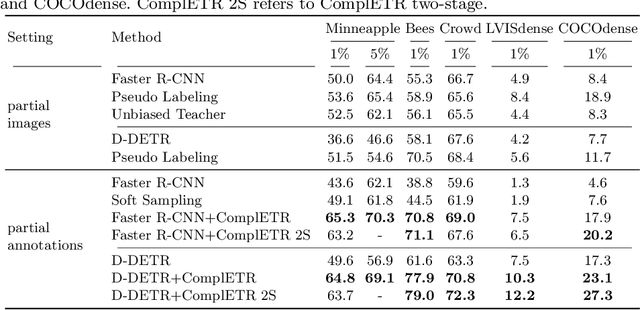
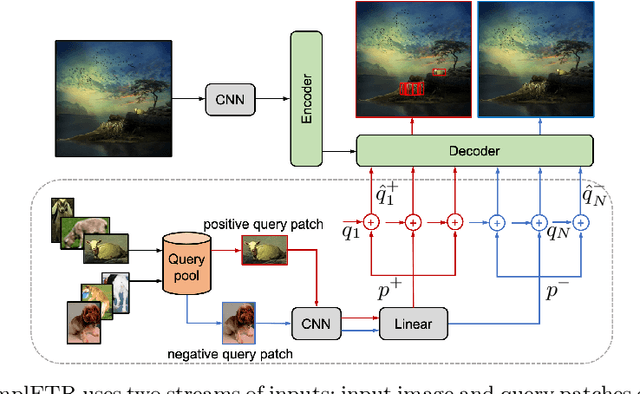
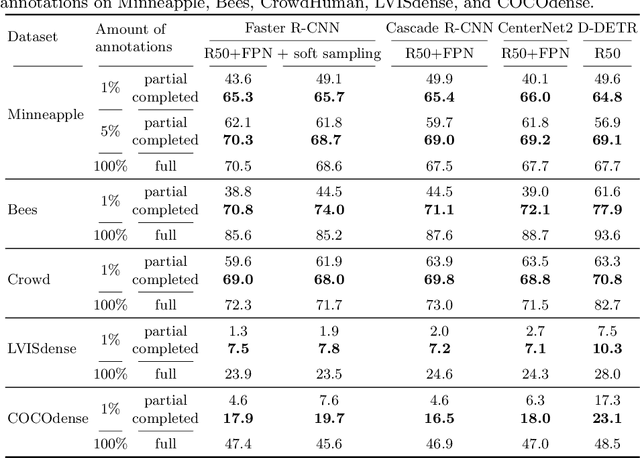
Annotating bounding boxes for object detection is expensive, time-consuming, and error-prone. In this work, we propose a DETR based framework called ComplETR that is designed to explicitly complete missing annotations in partially annotated dense scene datasets. This reduces the need to annotate every object instance in the scene thereby reducing annotation cost. ComplETR augments object queries in DETR decoder with patch information of objects in the image. Combined with a matching loss, it can effectively find objects that are similar to the input patch and complete the missing annotations. We show that our framework outperforms the state-of-the-art methods such as Soft Sampling and Unbiased Teacher by itself, while at the same time can be used in conjunction with these methods to further improve their performance. Our framework is also agnostic to the choice of the downstream object detectors; we show performance improvement for several popular detectors such as Faster R-CNN, Cascade R-CNN, CenterNet2, and Deformable DETR on multiple dense scene datasets.
Semi-supervised Vision Transformers at Scale
Aug 11, 2022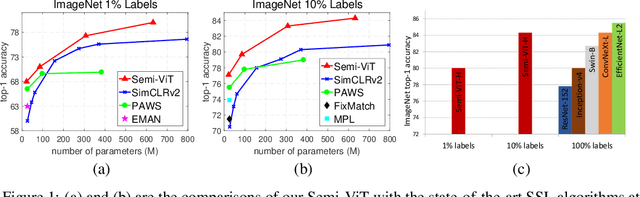
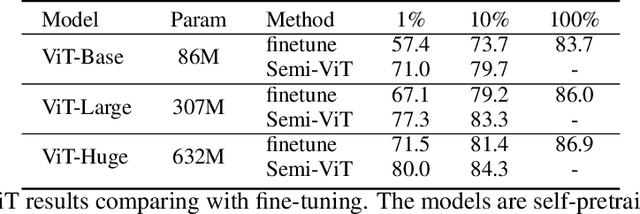
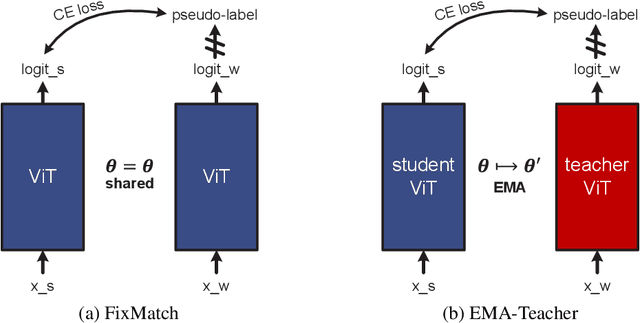
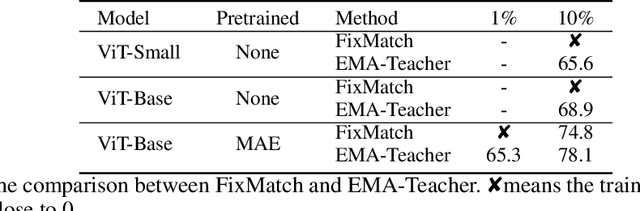
We study semi-supervised learning (SSL) for vision transformers (ViT), an under-explored topic despite the wide adoption of the ViT architectures to different tasks. To tackle this problem, we propose a new SSL pipeline, consisting of first un/self-supervised pre-training, followed by supervised fine-tuning, and finally semi-supervised fine-tuning. At the semi-supervised fine-tuning stage, we adopt an exponential moving average (EMA)-Teacher framework instead of the popular FixMatch, since the former is more stable and delivers higher accuracy for semi-supervised vision transformers. In addition, we propose a probabilistic pseudo mixup mechanism to interpolate unlabeled samples and their pseudo labels for improved regularization, which is important for training ViTs with weak inductive bias. Our proposed method, dubbed Semi-ViT, achieves comparable or better performance than the CNN counterparts in the semi-supervised classification setting. Semi-ViT also enjoys the scalability benefits of ViTs that can be readily scaled up to large-size models with increasing accuracies. For example, Semi-ViT-Huge achieves an impressive 80% top-1 accuracy on ImageNet using only 1% labels, which is comparable with Inception-v4 using 100% ImageNet labels.
Masked Vision and Language Modeling for Multi-modal Representation Learning
Aug 03, 2022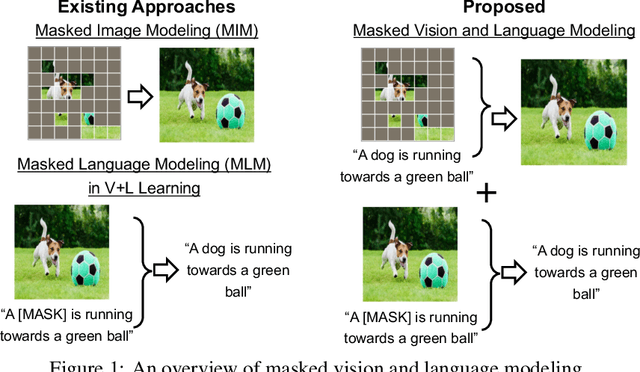
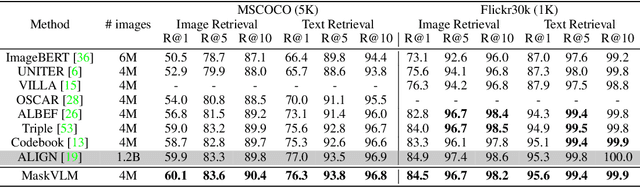
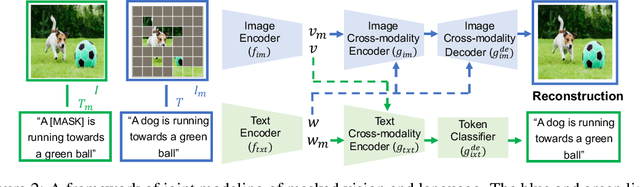
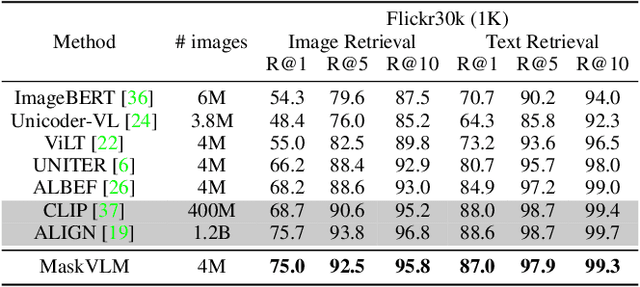
In this paper, we study how to use masked signal modeling in vision and language (V+L) representation learning. Instead of developing masked language modeling (MLM) and masked image modeling (MIM) independently, we propose to build joint masked vision and language modeling, where the masked signal of one modality is reconstructed with the help from another modality. This is motivated by the nature of image-text paired data that both of the image and the text convey almost the same information but in different formats. The masked signal reconstruction of one modality conditioned on another modality can also implicitly learn cross-modal alignment between language tokens and image patches. Our experiments on various V+L tasks show that the proposed method not only achieves state-of-the-art performances by using a large amount of data, but also outperforms the other competitors by a significant margin in the regimes of limited training data.
Rethinking Few-Shot Object Detection on a Multi-Domain Benchmark
Jul 22, 2022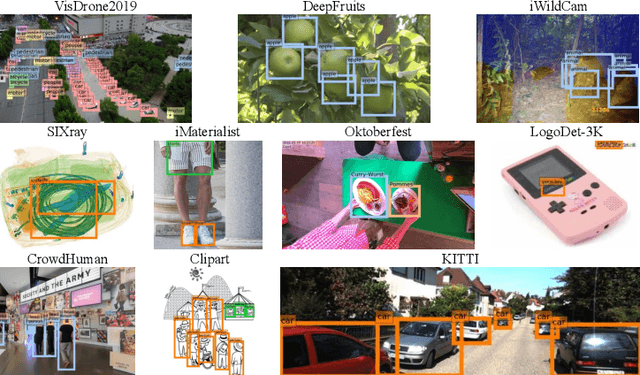
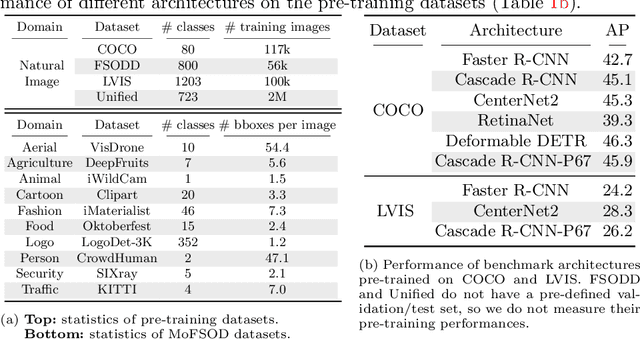
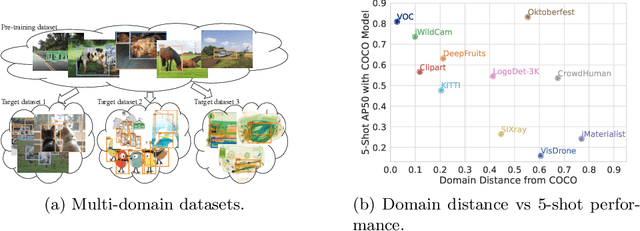
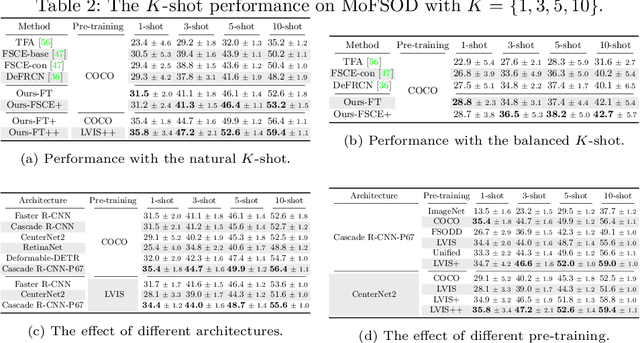
Most existing works on few-shot object detection (FSOD) focus on a setting where both pre-training and few-shot learning datasets are from a similar domain. However, few-shot algorithms are important in multiple domains; hence evaluation needs to reflect the broad applications. We propose a Multi-dOmain Few-Shot Object Detection (MoFSOD) benchmark consisting of 10 datasets from a wide range of domains to evaluate FSOD algorithms. We comprehensively analyze the impacts of freezing layers, different architectures, and different pre-training datasets on FSOD performance. Our empirical results show several key factors that have not been explored in previous works: 1) contrary to previous belief, on a multi-domain benchmark, fine-tuning (FT) is a strong baseline for FSOD, performing on par or better than the state-of-the-art (SOTA) algorithms; 2) utilizing FT as the baseline allows us to explore multiple architectures, and we found them to have a significant impact on down-stream few-shot tasks, even with similar pre-training performances; 3) by decoupling pre-training and few-shot learning, MoFSOD allows us to explore the impact of different pre-training datasets, and the right choice can boost the performance of the down-stream tasks significantly. Based on these findings, we list possible avenues of investigation for improving FSOD performance and propose two simple modifications to existing algorithms that lead to SOTA performance on the MoFSOD benchmark. The code is available at https://github.com/amazon-research/few-shot-object-detection-benchmark.
X-DETR: A Versatile Architecture for Instance-wise Vision-Language Tasks
Apr 12, 2022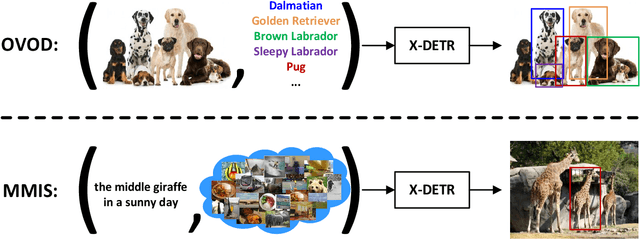
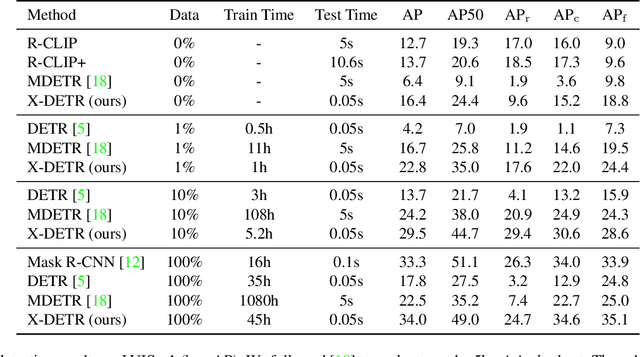
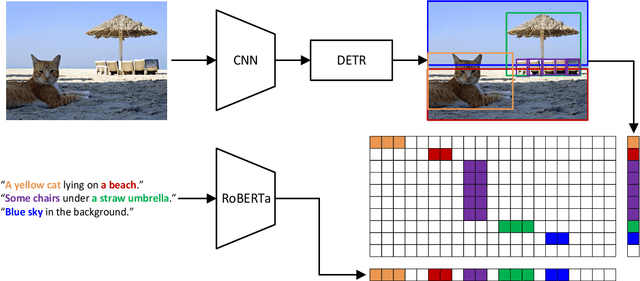
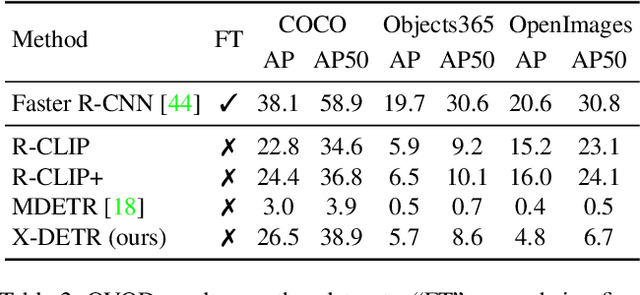
In this paper, we study the challenging instance-wise vision-language tasks, where the free-form language is required to align with the objects instead of the whole image. To address these tasks, we propose X-DETR, whose architecture has three major components: an object detector, a language encoder, and vision-language alignment. The vision and language streams are independent until the end and they are aligned using an efficient dot-product operation. The whole network is trained end-to-end, such that the detector is optimized for the vision-language tasks instead of an off-the-shelf component. To overcome the limited size of paired object-language annotations, we leverage other weak types of supervision to expand the knowledge coverage. This simple yet effective architecture of X-DETR shows good accuracy and fast speeds for multiple instance-wise vision-language tasks, e.g., 16.4 AP on LVIS detection of 1.2K categories at ~20 frames per second without using any LVIS annotation during training.
Class-Incremental Learning with Strong Pre-trained Models
Apr 07, 2022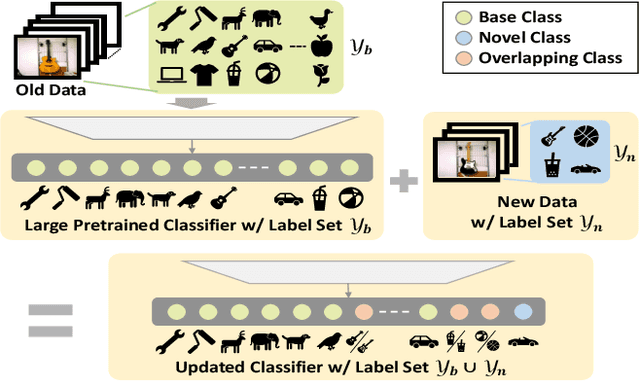
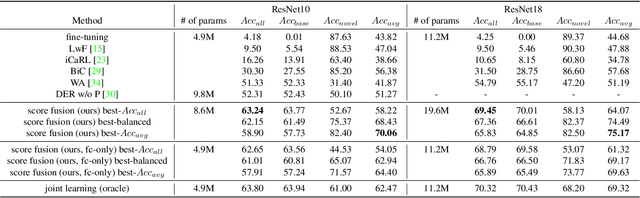
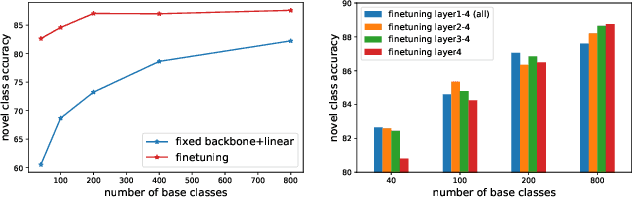
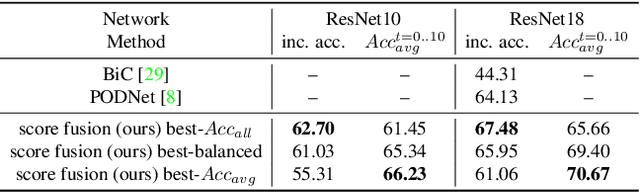
Class-incremental learning (CIL) has been widely studied under the setting of starting from a small number of classes (base classes). Instead, we explore an understudied real-world setting of CIL that starts with a strong model pre-trained on a large number of base classes. We hypothesize that a strong base model can provide a good representation for novel classes and incremental learning can be done with small adaptations. We propose a 2-stage training scheme, i) feature augmentation -- cloning part of the backbone and fine-tuning it on the novel data, and ii) fusion -- combining the base and novel classifiers into a unified classifier. Experiments show that the proposed method significantly outperforms state-of-the-art CIL methods on the large-scale ImageNet dataset (e.g. +10% overall accuracy than the best). We also propose and analyze understudied practical CIL scenarios, such as base-novel overlap with distribution shift. Our proposed method is robust and generalizes to all analyzed CIL settings.
Task Adaptive Parameter Sharing for Multi-Task Learning
Mar 30, 2022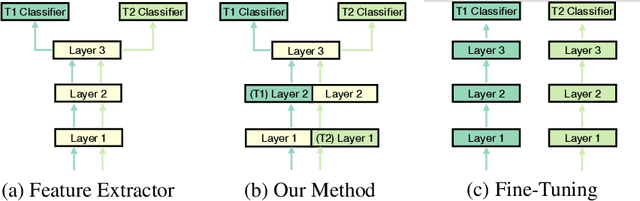
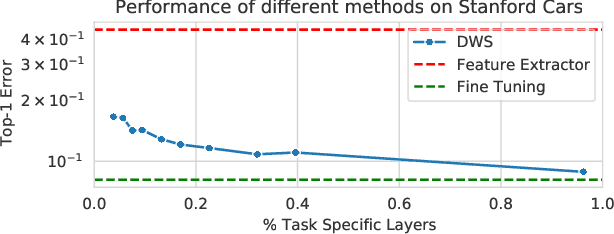
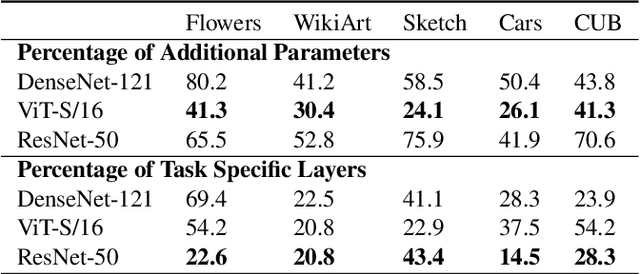
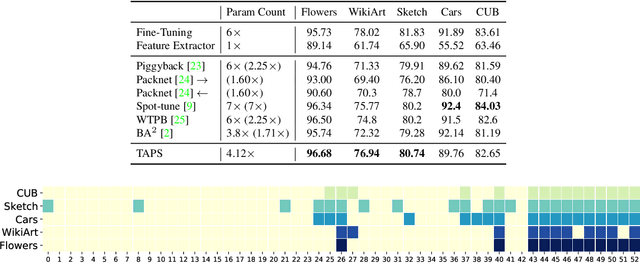
Adapting pre-trained models with broad capabilities has become standard practice for learning a wide range of downstream tasks. The typical approach of fine-tuning different models for each task is performant, but incurs a substantial memory cost. To efficiently learn multiple downstream tasks we introduce Task Adaptive Parameter Sharing (TAPS), a general method for tuning a base model to a new task by adaptively modifying a small, task-specific subset of layers. This enables multi-task learning while minimizing resources used and competition between tasks. TAPS solves a joint optimization problem which determines which layers to share with the base model and the value of the task-specific weights. Further, a sparsity penalty on the number of active layers encourages weight sharing with the base model. Compared to other methods, TAPS retains high accuracy on downstream tasks while introducing few task-specific parameters. Moreover, TAPS is agnostic to the model architecture and requires only minor changes to the training scheme. We evaluate our method on a suite of fine-tuning tasks and architectures (ResNet, DenseNet, ViT) and show that it achieves state-of-the-art performance while being simple to implement.
DIVA: Dataset Derivative of a Learning Task
Nov 18, 2021
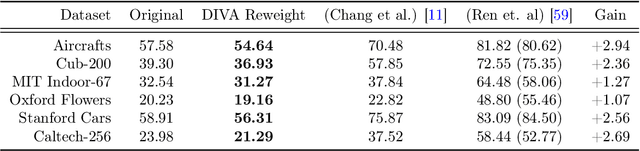

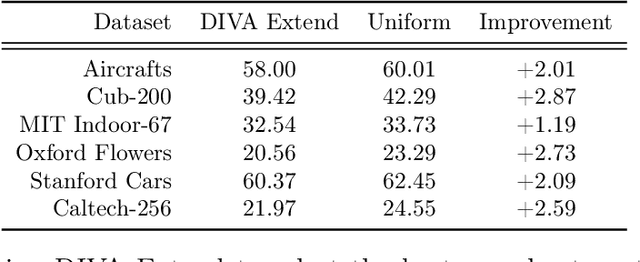
We present a method to compute the derivative of a learning task with respect to a dataset. A learning task is a function from a training set to the validation error, which can be represented by a trained deep neural network (DNN). The "dataset derivative" is a linear operator, computed around the trained model, that informs how perturbations of the weight of each training sample affect the validation error, usually computed on a separate validation dataset. Our method, DIVA (Differentiable Validation) hinges on a closed-form differentiable expression of the leave-one-out cross-validation error around a pre-trained DNN. Such expression constitutes the dataset derivative. DIVA could be used for dataset auto-curation, for example removing samples with faulty annotations, augmenting a dataset with additional relevant samples, or rebalancing. More generally, DIVA can be used to optimize the dataset, along with the parameters of the model, as part of the training process without the need for a separate validation dataset, unlike bi-level optimization methods customary in AutoML. To illustrate the flexibility of DIVA, we report experiments on sample auto-curation tasks such as outlier rejection, dataset extension, and automatic aggregation of multi-modal data.
Uniform Sampling over Episode Difficulty
Aug 03, 2021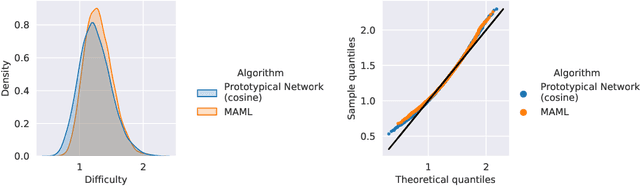
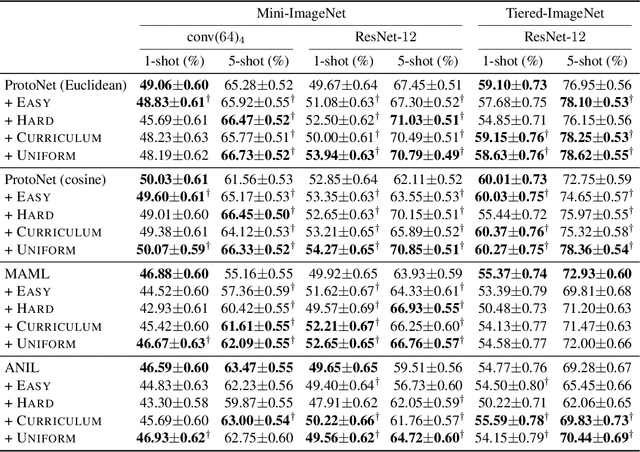
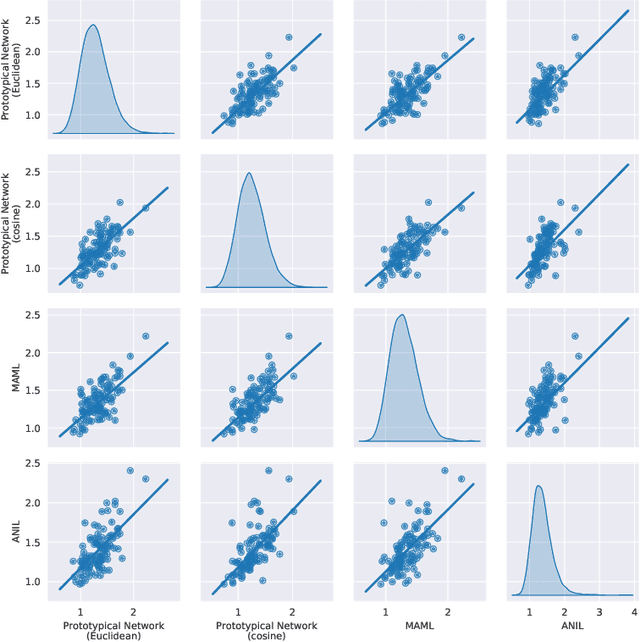
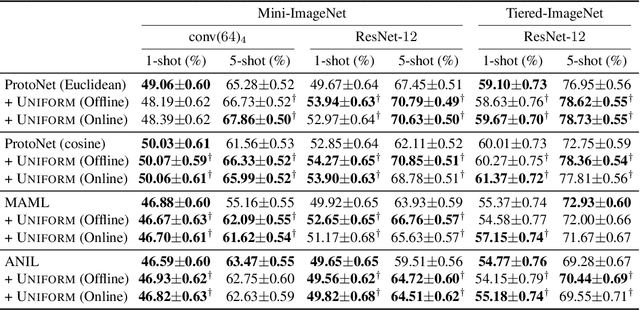
Episodic training is a core ingredient of few-shot learning to train models on tasks with limited labelled data. Despite its success, episodic training remains largely understudied, prompting us to ask the question: what is the best way to sample episodes? In this paper, we first propose a method to approximate episode sampling distributions based on their difficulty. Building on this method, we perform an extensive analysis and find that sampling uniformly over episode difficulty outperforms other sampling schemes, including curriculum and easy-/hard-mining. As the proposed sampling method is algorithm agnostic, we can leverage these insights to improve few-shot learning accuracies across many episodic training algorithms. We demonstrate the efficacy of our method across popular few-shot learning datasets, algorithms, network architectures, and protocols.
Representation Consolidation for Training Expert Students
Jul 16, 2021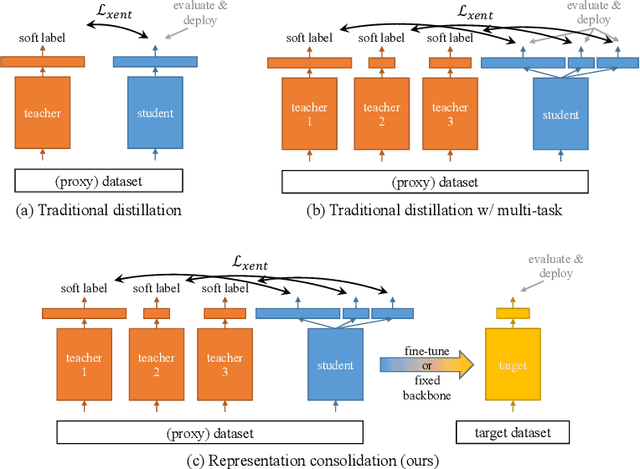

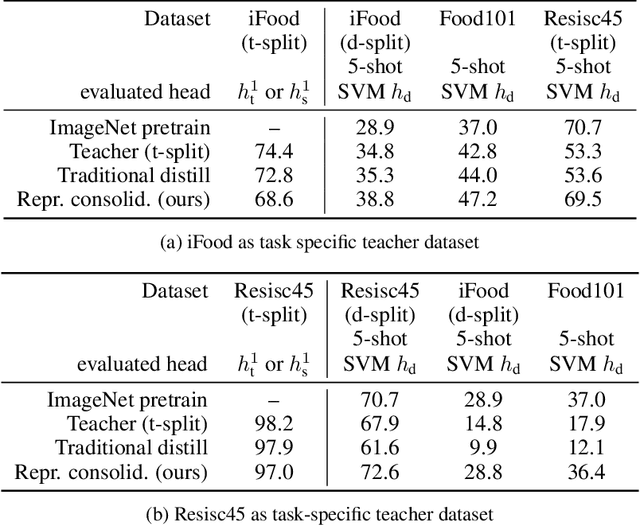

Traditionally, distillation has been used to train a student model to emulate the input/output functionality of a teacher. A more useful goal than emulation, yet under-explored, is for the student to learn feature representations that transfer well to future tasks. However, we observe that standard distillation of task-specific teachers actually *reduces* the transferability of student representations to downstream tasks. We show that a multi-head, multi-task distillation method using an unlabeled proxy dataset and a generalist teacher is sufficient to consolidate representations from task-specific teacher(s) and improve downstream performance, outperforming the teacher(s) and the strong baseline of ImageNet pretrained features. Our method can also combine the representational knowledge of multiple teachers trained on one or multiple domains into a single model, whose representation is improved on all teachers' domain(s).