 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrain, Diagnose and Fix: Interpretable Approach for Fine-grained Action Recognition
Nov 22, 2017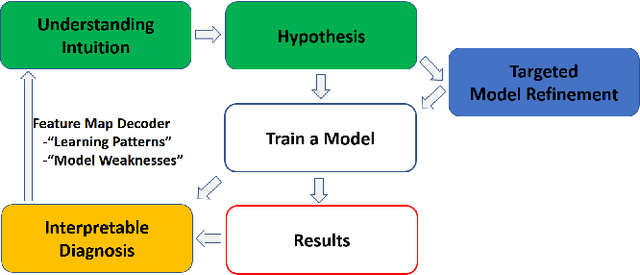
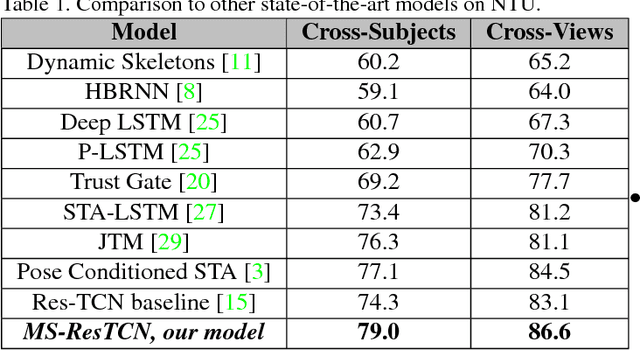
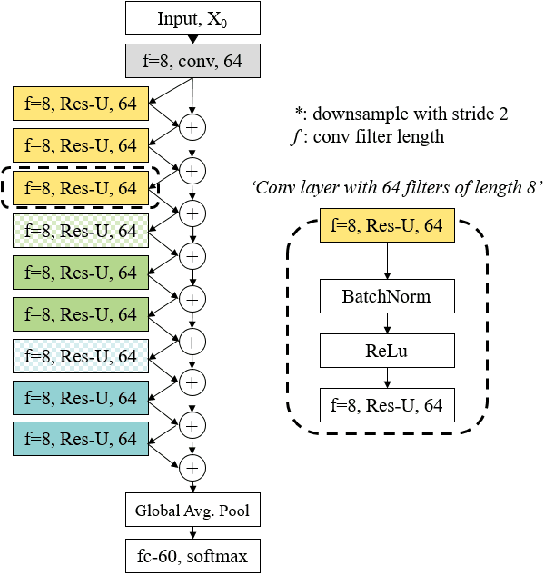
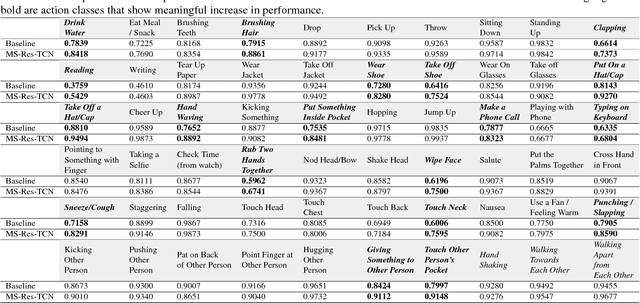
Despite the growing discriminative capabilities of modern deep learning methods for recognition tasks, the inner workings of the state-of-art models still remain mostly black-boxes. In this paper, we propose a systematic interpretation of model parameters and hidden representations of Residual Temporal Convolutional Networks (Res-TCN) for action recognition in time-series data. We also propose a Feature Map Decoder as part of the interpretation analysis, which outputs a representation of model's hidden variables in the same domain as the input. Such analysis empowers us to expose model's characteristic learning patterns in an interpretable way. For example, through the diagnosis analysis, we discovered that our model has learned to achieve view-point invariance by implicitly learning to perform rotational normalization of the input to a more discriminative view. Based on the findings from the model interpretation analysis, we propose a targeted refinement technique, which can generalize to various other recognition models. The proposed work introduces a three-stage paradigm for model learning: training, interpretable diagnosis and targeted refinement. We validate our approach on skeleton based 3D human action recognition benchmark of NTU RGB+D. We show that the proposed workflow is an effective model learning strategy and the resulting Multi-stream Residual Temporal Convolutional Network (MS-Res-TCN) achieves the state-of-the-art performance on NTU RGB+D.
Regularizing Face Verification Nets For Pain Intensity Regression
Jun 01, 2017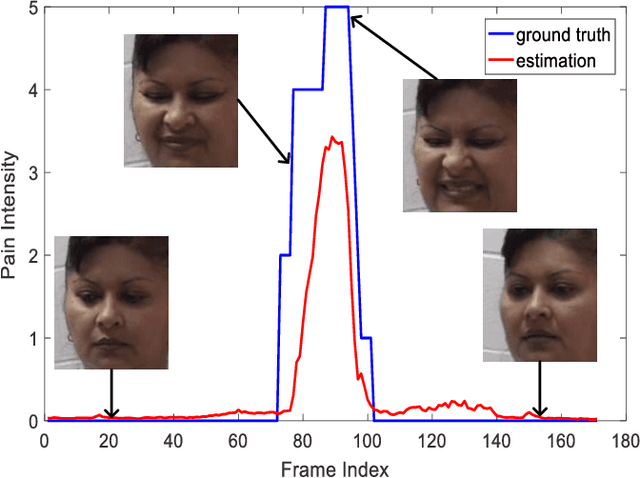
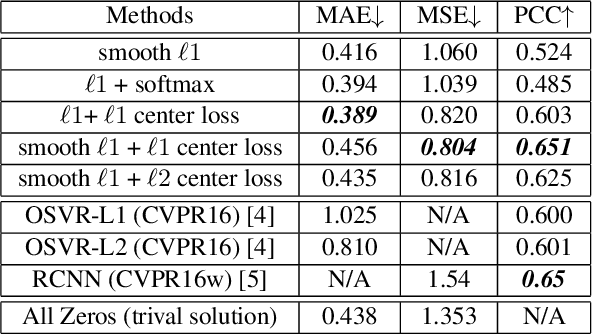
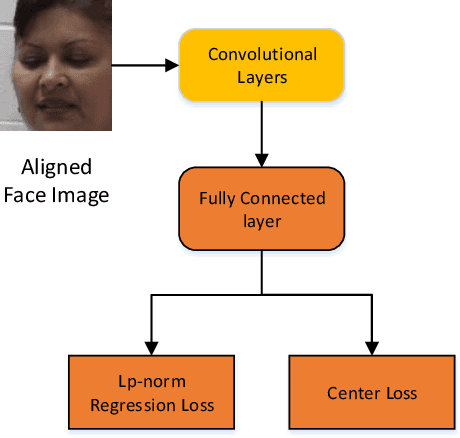
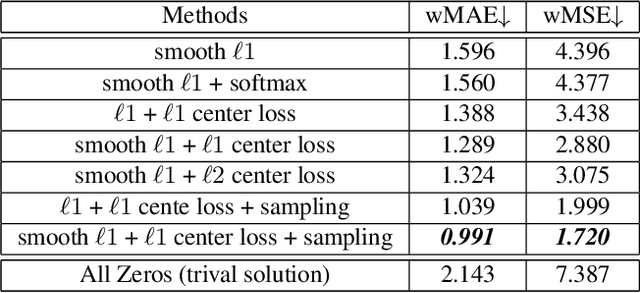
Limited labeled data are available for the research of estimating facial expression intensities. For instance, the ability to train deep networks for automated pain assessment is limited by small datasets with labels of patient-reported pain intensities. Fortunately, fine-tuning from a data-extensive pre-trained domain, such as face verification, can alleviate this problem. In this paper, we propose a network that fine-tunes a state-of-the-art face verification network using a regularized regression loss and additional data with expression labels. In this way, the expression intensity regression task can benefit from the rich feature representations trained on a huge amount of data for face verification. The proposed regularized deep regressor is applied to estimate the pain expression intensity and verified on the widely-used UNBC-McMaster Shoulder-Pain dataset, achieving the state-of-the-art performance. A weighted evaluation metric is also proposed to address the imbalance issue of different pain intensities.
Temporal Convolutional Networks for Action Segmentation and Detection
Nov 16, 2016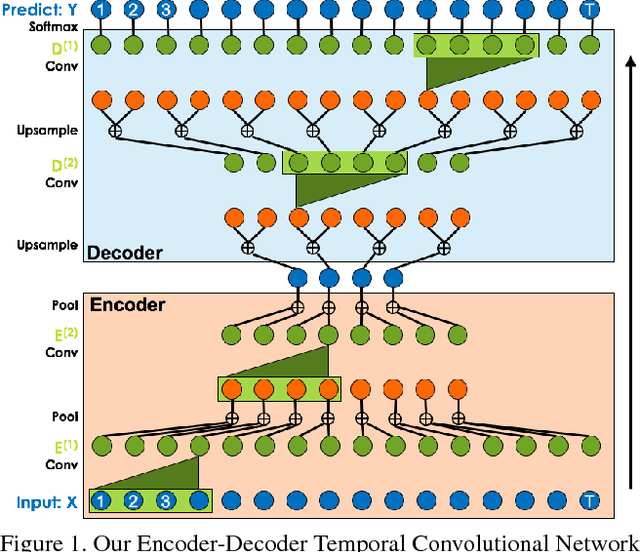
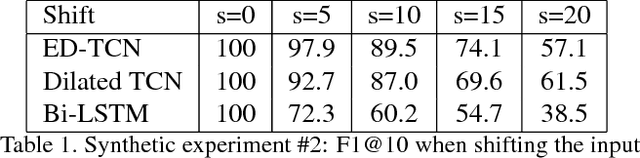
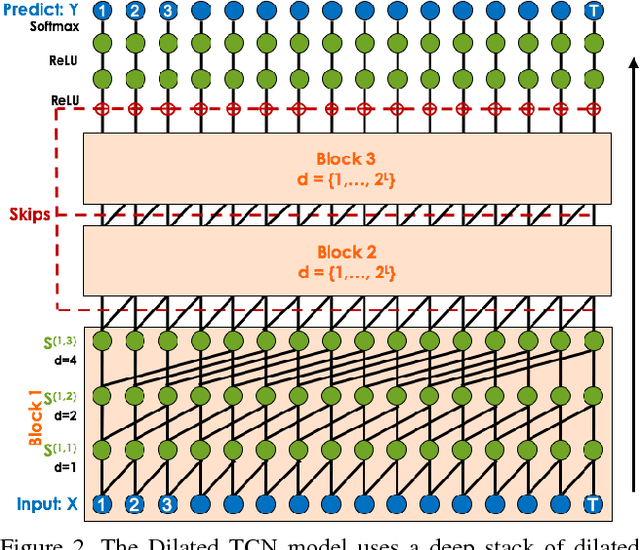
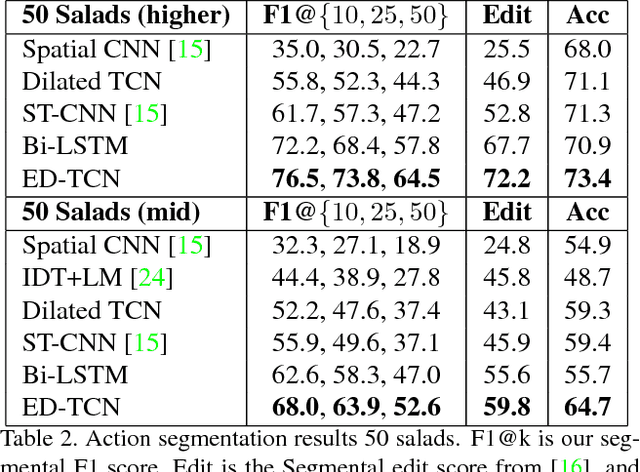
The ability to identify and temporally segment fine-grained human actions throughout a video is crucial for robotics, surveillance, education, and beyond. Typical approaches decouple this problem by first extracting local spatiotemporal features from video frames and then feeding them into a temporal classifier that captures high-level temporal patterns. We introduce a new class of temporal models, which we call Temporal Convolutional Networks (TCNs), that use a hierarchy of temporal convolutions to perform fine-grained action segmentation or detection. Our Encoder-Decoder TCN uses pooling and upsampling to efficiently capture long-range temporal patterns whereas our Dilated TCN uses dilated convolutions. We show that TCNs are capable of capturing action compositions, segment durations, and long-range dependencies, and are over a magnitude faster to train than competing LSTM-based Recurrent Neural Networks. We apply these models to three challenging fine-grained datasets and show large improvements over the state of the art.
Anatomically Constrained Video-CT Registration via the V-IMLOP Algorithm
Oct 25, 2016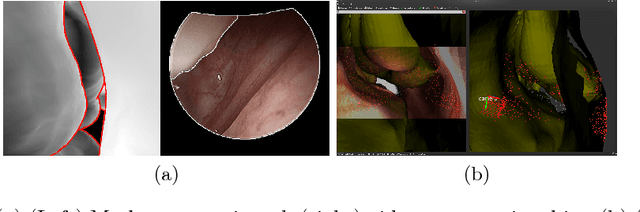
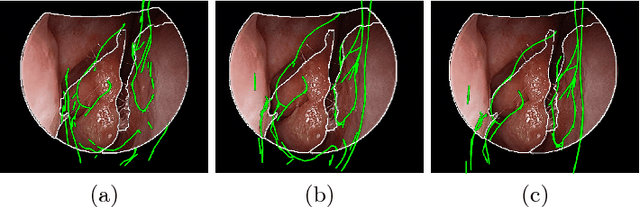
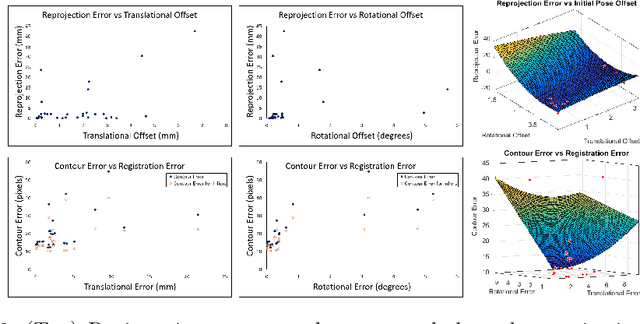
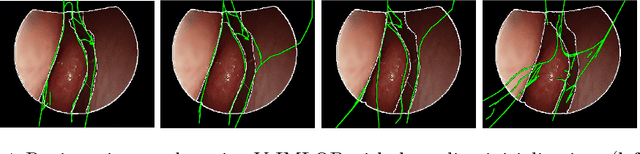
Functional endoscopic sinus surgery (FESS) is a surgical procedure used to treat acute cases of sinusitis and other sinus diseases. FESS is fast becoming the preferred choice of treatment due to its minimally invasive nature. However, due to the limited field of view of the endoscope, surgeons rely on navigation systems to guide them within the nasal cavity. State of the art navigation systems report registration accuracy of over 1mm, which is large compared to the size of the nasal airways. We present an anatomically constrained video-CT registration algorithm that incorporates multiple video features. Our algorithm is robust in the presence of outliers. We also test our algorithm on simulated and in-vivo data, and test its accuracy against degrading initializations.
* 8 pages, 4 figures, MICCAI
Segmental Spatiotemporal CNNs for Fine-grained Action Segmentation
Sep 30, 2016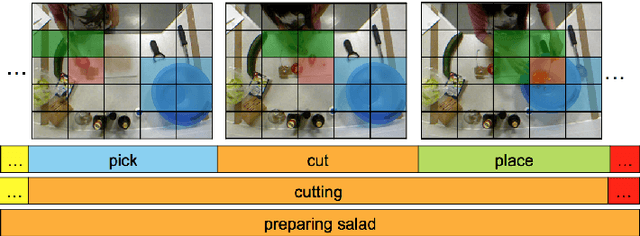
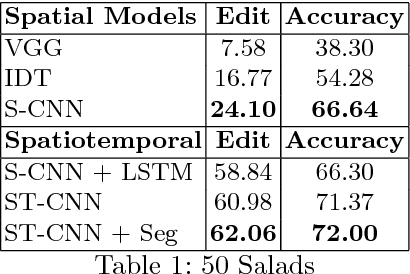
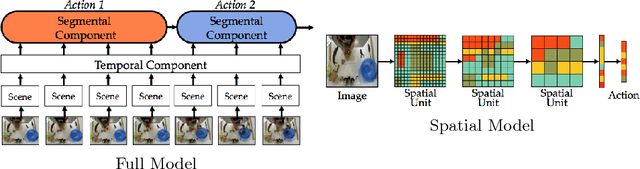
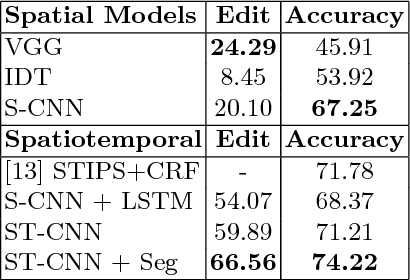
Joint segmentation and classification of fine-grained actions is important for applications of human-robot interaction, video surveillance, and human skill evaluation. However, despite substantial recent progress in large-scale action classification, the performance of state-of-the-art fine-grained action recognition approaches remains low. We propose a model for action segmentation which combines low-level spatiotemporal features with a high-level segmental classifier. Our spatiotemporal CNN is comprised of a spatial component that uses convolutional filters to capture information about objects and their relationships, and a temporal component that uses large 1D convolutional filters to capture information about how object relationships change across time. These features are used in tandem with a semi-Markov model that models transitions from one action to another. We introduce an efficient constrained segmental inference algorithm for this model that is orders of magnitude faster than the current approach. We highlight the effectiveness of our Segmental Spatiotemporal CNN on cooking and surgical action datasets for which we observe substantially improved performance relative to recent baseline methods.
Temporal Convolutional Networks: A Unified Approach to Action Segmentation
Aug 29, 2016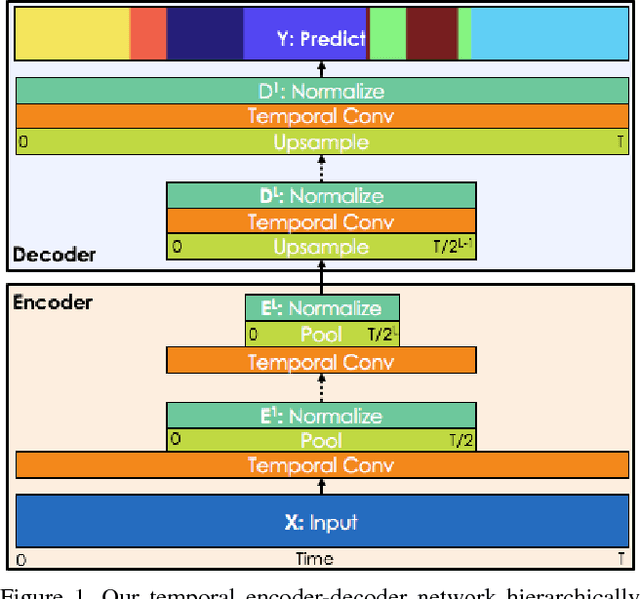
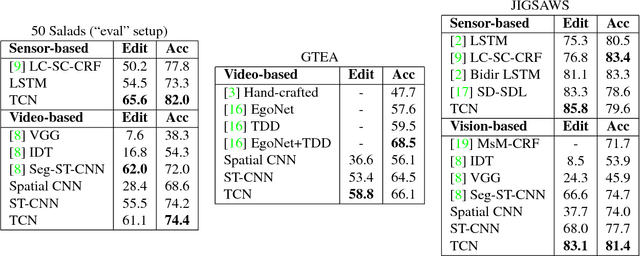
The dominant paradigm for video-based action segmentation is composed of two steps: first, for each frame, compute low-level features using Dense Trajectories or a Convolutional Neural Network that encode spatiotemporal information locally, and second, input these features into a classifier that captures high-level temporal relationships, such as a Recurrent Neural Network (RNN). While often effective, this decoupling requires specifying two separate models, each with their own complexities, and prevents capturing more nuanced long-range spatiotemporal relationships. We propose a unified approach, as demonstrated by our Temporal Convolutional Network (TCN), that hierarchically captures relationships at low-, intermediate-, and high-level time-scales. Our model achieves superior or competitive performance using video or sensor data on three public action segmentation datasets and can be trained in a fraction of the time it takes to train an RNN.