 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixing Incomplete Value Function Decomposition for Multi-Agent Reinforcement Learning
May 15, 2025Value function decomposition methods for cooperative multi-agent reinforcement learning compose joint values from individual per-agent utilities, and train them using a joint objective. To ensure that the action selection process between individual utilities and joint values remains consistent, it is imperative for the composition to satisfy the individual-global max (IGM) property. Although satisfying IGM itself is straightforward, most existing methods (e.g., VDN, QMIX) have limited representation capabilities and are unable to represent the full class of IGM values, and the one exception that has no such limitation (QPLEX) is unnecessarily complex. In this work, we present a simple formulation of the full class of IGM values that naturally leads to the derivation of QFIX, a novel family of value function decomposition models that expand the representation capabilities of prior models by means of a thin "fixing" layer. We derive multiple variants of QFIX, and implement three variants in two well-known multi-agent frameworks. We perform an empirical evaluation on multiple SMACv2 and Overcooked environments, which confirms that QFIX (i) succeeds in enhancing the performance of prior methods, (ii) learns more stably and performs better than its main competitor QPLEX, and (iii) achieves this while employing the simplest and smallest mixing models.
On Stateful Value Factorization in Multi-Agent Reinforcement Learning
Sep 09, 2024



Value factorization is a popular paradigm for designing scalable multi-agent reinforcement learning algorithms. However, current factorization methods make choices without full justification that may limit their performance. For example, the theory in prior work uses stateless (i.e., history) functions, while the practical implementations use state information -- making the motivating theory a mismatch for the implementation. Also, methods have built off of previous approaches, inheriting their architectures without exploring other, potentially better ones. To address these concerns, we formally analyze the theory of using the state instead of the history in current methods -- reconnecting theory and practice. We then introduce DuelMIX, a factorization algorithm that learns distinct per-agent utility estimators to improve performance and achieve full expressiveness. Experiments on StarCraft II micromanagement and Box Pushing tasks demonstrate the benefits of our intuitions.
Curriculum Learning for Cooperation in Multi-Agent Reinforcement Learning
Dec 19, 2023



While there has been significant progress in curriculum learning and continuous learning for training agents to generalize across a wide variety of environments in the context of single-agent reinforcement learning, it is unclear if these algorithms would still be valid in a multi-agent setting. In a competitive setting, a learning agent can be trained by making it compete with a curriculum of increasingly skilled opponents. However, a general intelligent agent should also be able to learn to act around other agents and cooperate with them to achieve common goals. When cooperating with other agents, the learning agent must (a) learn how to perform the task (or subtask), and (b) increase the overall team reward. In this paper, we aim to answer the question of what kind of cooperative teammate, and a curriculum of teammates should a learning agent be trained with to achieve these two objectives. Our results on the game Overcooked show that a pre-trained teammate who is less skilled is the best teammate for overall team reward but the worst for the learning of the agent. Moreover, somewhat surprisingly, a curriculum of teammates with decreasing skill levels performs better than other types of curricula.
Interpret Your Care: Predicting the Evolution of Symptoms for Cancer Patients
Feb 19, 2023



Cancer treatment is an arduous process for patients and causes many side-effects during and post-treatment. The treatment can affect almost all body systems and result in pain, fatigue, sleep disturbances, cognitive impairments, etc. These conditions are often under-diagnosed or under-treated. In this paper, we use patient data to predict the evolution of their symptoms such that treatment-related impairments can be prevented or effects meaningfully ameliorated. The focus of this study is on predicting the pain and tiredness level of a patient post their diagnosis. We implement an interpretable decision tree based model called LightGBM on real-world patient data consisting of 20163 patients. There exists a class imbalance problem in the dataset which we resolve using the oversampling technique of SMOTE. Our empirical results show that the value of the previous level of a symptom is a key indicator for prediction and the weighted average deviation in prediction of pain level is 3.52 and of tiredness level is 2.27.
A Reinforcement Learning Approach to Jointly Adapt Vehicular Communications and Planning for Optimized Driving
Jul 10, 2018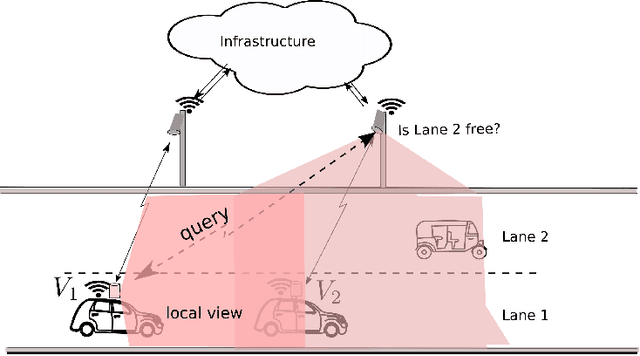
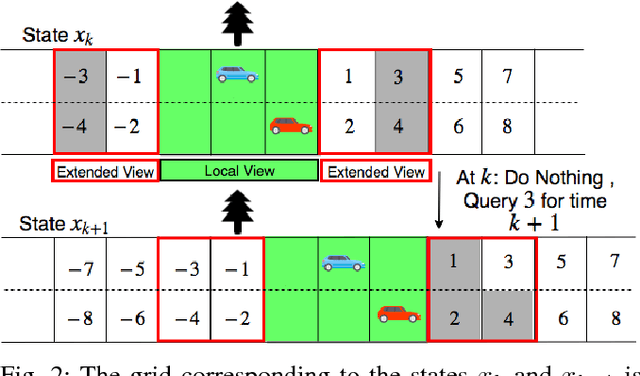
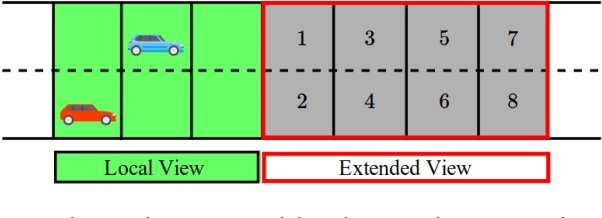
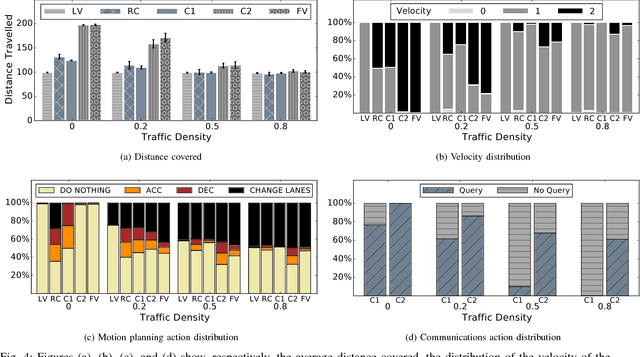
Our premise is that autonomous vehicles must optimize communications and motion planning jointly. Specifically, a vehicle must adapt its motion plan staying cognizant of communications rate related constraints and adapt the use of communications while being cognizant of motion planning related restrictions that may be imposed by the on-road environment. To this end, we formulate a reinforcement learning problem wherein an autonomous vehicle jointly chooses (a) a motion planning action that executes on-road and (b) a communications action of querying sensed information from the infrastructure. The goal is to optimize the driving utility of the autonomous vehicle. We apply the Q-learning algorithm to make the vehicle learn the optimal policy, which makes the optimal choice of planning and communications actions at any given time. We demonstrate the ability of the optimal policy to smartly adapt communications and planning actions, while achieving large driving utilities, using simulations.