 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWAPTS: A Weighted Allocation Probability Adjusted Thompson Sampling Algorithm for High-Dimensional and Sparse Experiment Settings
Jan 07, 2025Aiming for more effective experiment design, such as in video content advertising where different content options compete for user engagement, these scenarios can be modeled as multi-arm bandit problems. In cases where limited interactions are available due to external factors, such as the cost of conducting experiments, recommenders often face constraints due to the small number of user interactions. In addition, there is a trade-off between selecting the best treatment and the ability to personalize and contextualize based on individual factors. A popular solution to this dilemma is the Contextual Bandit framework. It aims to maximize outcomes while incorporating personalization (contextual) factors, customizing treatments such as a user's profile to individual preferences. Despite their advantages, Contextual Bandit algorithms face challenges like measurement bias and the 'curse of dimensionality.' These issues complicate the management of numerous interventions and often lead to data sparsity through participant segmentation. To address these problems, we introduce the Weighted Allocation Probability Adjusted Thompson Sampling (WAPTS) algorithm. WAPTS builds on the contextual Thompson Sampling method by using a dynamic weighting parameter. This improves the allocation process for interventions and enables rapid optimization in data-sparse environments. We demonstrate the performance of our approach on different numbers of arms and effect sizes.
Physics-Informed Deep Learning to Reduce the Bias in Joint Prediction of Nitrogen Oxides
Aug 14, 2023



Atmospheric nitrogen oxides (NOx) primarily from fuel combustion have recognized acute and chronic health and environmental effects. Machine learning (ML) methods have significantly enhanced our capacity to predict NOx concentrations at ground-level with high spatiotemporal resolution but may suffer from high estimation bias since they lack physical and chemical knowledge about air pollution dynamics. Chemical transport models (CTMs) leverage this knowledge; however, accurate predictions of ground-level concentrations typically necessitate extensive post-calibration. Here, we present a physics-informed deep learning framework that encodes advection-diffusion mechanisms and fluid dynamics constraints to jointly predict NO2 and NOx and reduce ML model bias by 21-42%. Our approach captures fine-scale transport of NO2 and NOx, generates robust spatial extrapolation, and provides explicit uncertainty estimation. The framework fuses knowledge-driven physicochemical principles of CTMs with the predictive power of ML for air quality exposure, health, and policy applications. Our approach offers significant improvements over purely data-driven ML methods and has unprecedented bias reduction in joint NO2 and NOx prediction.
Quantile Extreme Gradient Boosting for Uncertainty Quantification
Apr 23, 2023



As the availability, size and complexity of data have increased in recent years, machine learning (ML) techniques have become popular for modeling. Predictions resulting from applying ML models are often used for inference, decision-making, and downstream applications. A crucial yet often overlooked aspect of ML is uncertainty quantification, which can significantly impact how predictions from models are used and interpreted. Extreme Gradient Boosting (XGBoost) is one of the most popular ML methods given its simple implementation, fast computation, and sequential learning, which make its predictions highly accurate compared to other methods. However, techniques for uncertainty determination in ML models such as XGBoost have not yet been universally agreed among its varying applications. We propose enhancements to XGBoost whereby a modified quantile regression is used as the objective function to estimate uncertainty (QXGBoost). Specifically, we included the Huber norm in the quantile regression model to construct a differentiable approximation to the quantile regression error function. This key step allows XGBoost, which uses a gradient-based optimization algorithm, to make probabilistic predictions efficiently. QXGBoost was applied to create 90\% prediction intervals for one simulated dataset and one real-world environmental dataset of measured traffic noise. Our proposed method had comparable or better performance than the uncertainty estimates generated for regular and quantile light gradient boosting. For both the simulated and traffic noise datasets, the overall performance of the prediction intervals from QXGBoost were better than other models based on coverage width-based criterion.
Building Autocorrelation-Aware Representations for Fine-Scale Spatiotemporal Prediction
Dec 10, 2021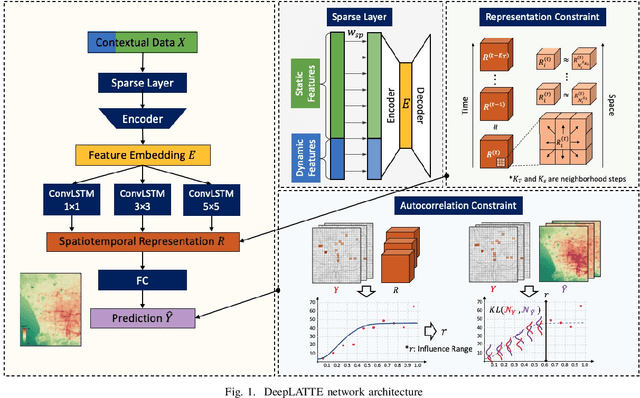
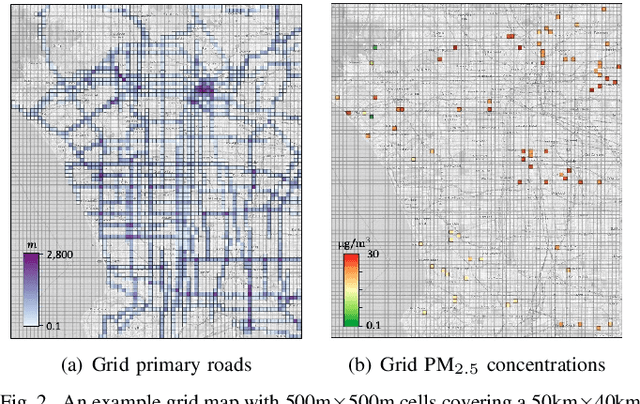
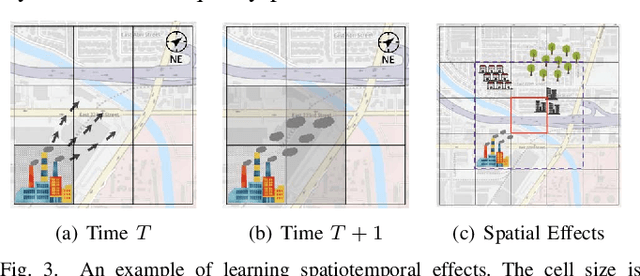
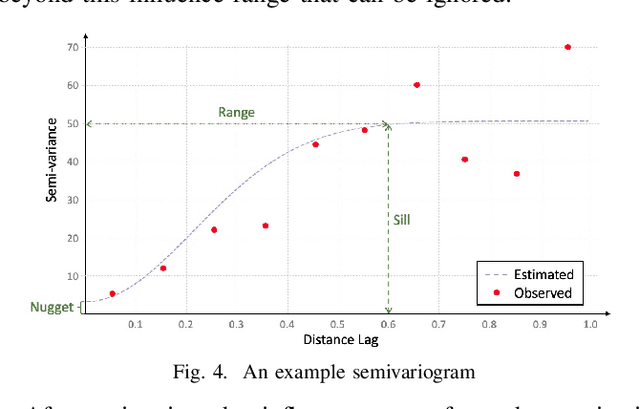
Many scientific prediction problems have spatiotemporal data- and modeling-related challenges in handling complex variations in space and time using only sparse and unevenly distributed observations. This paper presents a novel deep learning architecture, Deep learning predictions for LocATion-dependent Time-sEries data (DeepLATTE), that explicitly incorporates theories of spatial statistics into neural networks to address these challenges. In addition to a feature selection module and a spatiotemporal learning module, DeepLATTE contains an autocorrelation-guided semi-supervised learning strategy to enforce both local autocorrelation patterns and global autocorrelation trends of the predictions in the learned spatiotemporal embedding space to be consistent with the observed data, overcoming the limitation of sparse and unevenly distributed observations. During the training process, both supervised and semi-supervised losses guide the updates of the entire network to: 1) prevent overfitting, 2) refine feature selection, 3) learn useful spatiotemporal representations, and 4) improve overall prediction. We conduct a demonstration of DeepLATTE using publicly available data for an important public health topic, air quality prediction, in a well-studied, complex physical environment - Los Angeles. The experiment demonstrates that the proposed approach provides accurate fine-spatial-scale air quality predictions and reveals the critical environmental factors affecting the results.