 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffect of Haptic Feedback on Avoidance Behavior and Visual Exploration in Dynamic VR Pedestrian Environment
Jun 26, 2025Human crowd simulation in virtual reality (VR) is a powerful tool with potential applications including emergency evacuation training and assessment of building layout. While haptic feedback in VR enhances immersive experience, its effect on walking behavior in dense and dynamic pedestrian flows is unknown. Through a user study, we investigated how haptic feedback changes user walking motion in crowded pedestrian flows in VR. The results indicate that haptic feedback changed users' collision avoidance movements, as measured by increased walking trajectory length and change in pelvis angle. The displacements of users' lateral position and pelvis angle were also increased in the instantaneous response to a collision with a non-player character (NPC), even when the NPC was inside the field of view. Haptic feedback also enhanced users' awareness and visual exploration when an NPC approached from the side and back. Furthermore, variation in walking speed was increased by the haptic feedback. These results suggested that the haptic feedback enhanced users' sensitivity to a collision in VR environment.
Eagle and Finch: RWKV with Matrix-Valued States and Dynamic Recurrence
Apr 10, 2024



We present Eagle (RWKV-5) and Finch (RWKV-6), sequence models improving upon the RWKV (RWKV-4) architecture. Our architectural design advancements include multi-headed matrix-valued states and a dynamic recurrence mechanism that improve expressivity while maintaining the inference efficiency characteristics of RNNs. We introduce a new multilingual corpus with 1.12 trillion tokens and a fast tokenizer based on greedy matching for enhanced multilinguality. We trained four Eagle models, ranging from 0.46 to 7.5 billion parameters, and two Finch models with 1.6 and 3.1 billion parameters and find that they achieve competitive performance across a wide variety of benchmarks. We release all our models on HuggingFace under the Apache 2.0 license. Models at: https://huggingface.co/RWKV Training code at: https://github.com/RWKV/RWKV-LM Inference code at: https://github.com/RWKV/ChatRWKV Time-parallel training code at: https://github.com/RWKV/RWKV-infctx-trainer
RWKV: Reinventing RNNs for the Transformer Era
May 22, 2023



Transformers have revolutionized almost all natural language processing (NLP) tasks but suffer from memory and computational complexity that scales quadratically with sequence length. In contrast, recurrent neural networks (RNNs) exhibit linear scaling in memory and computational requirements but struggle to match the same performance as Transformers due to limitations in parallelization and scalability. We propose a novel model architecture, Receptance Weighted Key Value (RWKV), that combines the efficient parallelizable training of Transformers with the efficient inference of RNNs. Our approach leverages a linear attention mechanism and allows us to formulate the model as either a Transformer or an RNN, which parallelizes computations during training and maintains constant computational and memory complexity during inference, leading to the first non-transformer architecture to be scaled to tens of billions of parameters. Our experiments reveal that RWKV performs on par with similarly sized Transformers, suggesting that future work can leverage this architecture to create more efficient models. This work presents a significant step towards reconciling the trade-offs between computational efficiency and model performance in sequence processing tasks.
Particle Filter on Episode
Apr 18, 2019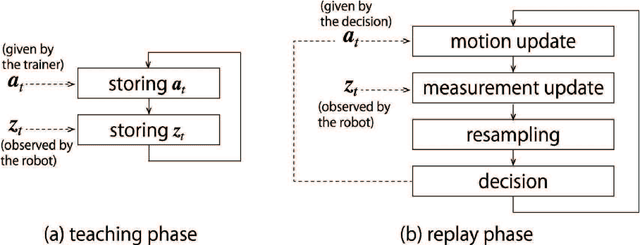
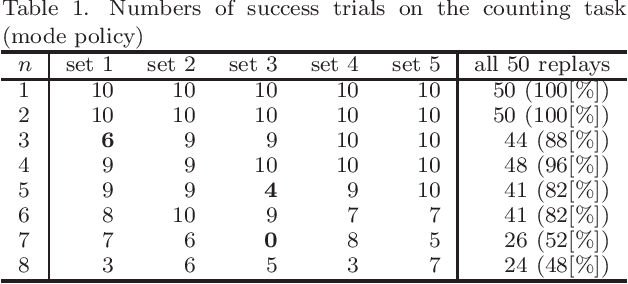
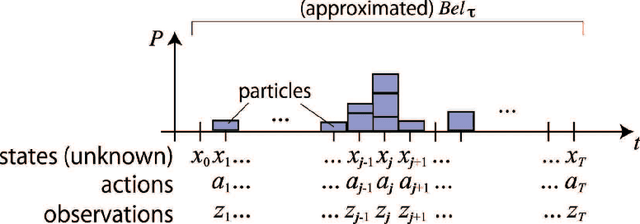
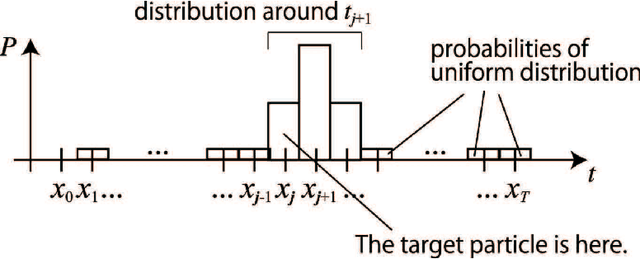
Differently from animals, robots can record its experience correctly for long time. We propose a novel algorithm that runs a particle filter on the time sequence of the experience. It can be applied to some teach-and-replay tasks. In a task, the trainer controls a robot, and the robot records its sensor readings and its actions. We name the sequence of the record an episode, which is derived from the episodic memory of animals. After that, the robot executes the particle filter so as to find a similar situation with the current one from the episode. If the robot chooses the action taken in the similar situation, it can replay the taught behavior. We name this algorithm the particle filter on episode (PFoE). The robot with PFoE shows not only a simple replay of a behavior but also recovery motion from skids and interruption. In this paper, we evaluate the properties of PFoE with a small mobile robot.