 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEconoJax: A Fast & Scalable Economic Simulation in Jax
Oct 29, 2024



Accurate economic simulations often require many experimental runs, particularly when combined with reinforcement learning. Unfortunately, training reinforcement learning agents in multi-agent economic environments can be slow. This paper introduces EconoJax, a fast simulated economy, based on the AI economist. EconoJax, and its training pipeline, are completely written in JAX. This allows EconoJax to scale to large population sizes and perform large experiments, while keeping training times within minutes. Through experiments with populations of 100 agents, we show how real-world economic behavior emerges through training within 15 minutes, in contrast to previous work that required several days. To aid and inspire researchers to build more rich and dynamic economic simulations, we open-source EconoJax on Github at: https://github.com/ponseko/econojax.
World Models Increase Autonomy in Reinforcement Learning
Aug 20, 2024



Reinforcement learning (RL) is an appealing paradigm for training intelligent agents, enabling policy acquisition from the agent's own autonomously acquired experience. However, the training process of RL is far from automatic, requiring extensive human effort to reset the agent and environments. To tackle the challenging reset-free setting, we first demonstrate the superiority of model-based (MB) RL methods in such setting, showing that a straightforward adaptation of MBRL can outperform all the prior state-of-the-art methods while requiring less supervision. We then identify limitations inherent to this direct extension and propose a solution called model-based reset-free (MoReFree) agent, which further enhances the performance. MoReFree adapts two key mechanisms, exploration and policy learning, to handle reset-free tasks by prioritizing task-relevant states. It exhibits superior data-efficiency across various reset-free tasks without access to environmental reward or demonstrations while significantly outperforming privileged baselines that require supervision. Our findings suggest model-based methods hold significant promise for reducing human effort in RL. Website: https://sites.google.com/view/morefree
Towards General Negotiation Strategies with End-to-End Reinforcement Learning
Jun 21, 2024The research field of automated negotiation has a long history of designing agents that can negotiate with other agents. Such negotiation strategies are traditionally based on manual design and heuristics. More recently, reinforcement learning approaches have also been used to train agents to negotiate. However, negotiation problems are diverse, causing observation and action dimensions to change, which cannot be handled by default linear policy networks. Previous work on this topic has circumvented this issue either by fixing the negotiation problem, causing policies to be non-transferable between negotiation problems or by abstracting the observations and actions into fixed-size representations, causing loss of information and expressiveness due to feature design. We developed an end-to-end reinforcement learning method for diverse negotiation problems by representing observations and actions as a graph and applying graph neural networks in the policy. With empirical evaluations, we show that our method is effective and that we can learn to negotiate with other agents on never-before-seen negotiation problems. Our result opens up new opportunities for reinforcement learning in negotiation agents.
Explicitly Disentangled Representations in Object-Centric Learning
Jan 18, 2024



Extracting structured representations from raw visual data is an important and long-standing challenge in machine learning. Recently, techniques for unsupervised learning of object-centric representations have raised growing interest. In this context, enhancing the robustness of the latent features can improve the efficiency and effectiveness of the training of downstream tasks. A promising step in this direction is to disentangle the factors that cause variation in the data. Previously, Invariant Slot Attention disentangled position, scale, and orientation from the remaining features. Extending this approach, we focus on separating the shape and texture components. In particular, we propose a novel architecture that biases object-centric models toward disentangling shape and texture components into two non-overlapping subsets of the latent space dimensions. These subsets are known a priori, hence before the training process. Experiments on a range of object-centric benchmarks reveal that our approach achieves the desired disentanglement while also numerically improving baseline performance in most cases. In addition, we show that our method can generate novel textures for a specific object or transfer textures between objects with distinct shapes.
EduGym: An Environment Suite for Reinforcement Learning Education
Nov 17, 2023



Due to the empirical success of reinforcement learning, an increasing number of students study the subject. However, from our practical teaching experience, we see students entering the field (bachelor, master and early PhD) often struggle. On the one hand, textbooks and (online) lectures provide the fundamentals, but students find it hard to translate between equations and code. On the other hand, public codebases do provide practical examples, but the implemented algorithms tend to be complex, and the underlying test environments contain multiple reinforcement learning challenges at once. Although this is realistic from a research perspective, it often hinders educational conceptual understanding. To solve this issue we introduce EduGym, a set of educational reinforcement learning environments and associated interactive notebooks tailored for education. Each EduGym environment is specifically designed to illustrate a certain aspect/challenge of reinforcement learning (e.g., exploration, partial observability, stochasticity, etc.), while the associated interactive notebook explains the challenge and its possible solution approaches, connecting equations and code in a single document. An evaluation among RL students and researchers shows 86% of them think EduGym is a useful tool for reinforcement learning education. All notebooks are available from https://sites.google.com/view/edu-gym/home, while the full software package can be installed from https://github.com/RLG-Leiden/edugym.
Are LSTMs Good Few-Shot Learners?
Oct 22, 2023Deep learning requires large amounts of data to learn new tasks well, limiting its applicability to domains where such data is available. Meta-learning overcomes this limitation by learning how to learn. In 2001, Hochreiter et al. showed that an LSTM trained with backpropagation across different tasks is capable of meta-learning. Despite promising results of this approach on small problems, and more recently, also on reinforcement learning problems, the approach has received little attention in the supervised few-shot learning setting. We revisit this approach and test it on modern few-shot learning benchmarks. We find that LSTM, surprisingly, outperform the popular meta-learning technique MAML on a simple few-shot sine wave regression benchmark, but that LSTM, expectedly, fall short on more complex few-shot image classification benchmarks. We identify two potential causes and propose a new method called Outer Product LSTM (OP-LSTM) that resolves these issues and displays substantial performance gains over the plain LSTM. Compared to popular meta-learning baselines, OP-LSTM yields competitive performance on within-domain few-shot image classification, and performs better in cross-domain settings by 0.5% to 1.9% in accuracy score. While these results alone do not set a new state-of-the-art, the advances of OP-LSTM are orthogonal to other advances in the field of meta-learning, yield new insights in how LSTM work in image classification, allowing for a whole range of new research directions. For reproducibility purposes, we publish all our research code publicly.
What model does MuZero learn?
Jun 01, 2023



Model-based reinforcement learning has drawn considerable interest in recent years, given its promise to improve sample efficiency. Moreover, when using deep-learned models, it is potentially possible to learn compact models from complex sensor data. However, the effectiveness of these learned models, particularly their capacity to plan, i.e., to improve the current policy, remains unclear. In this work, we study MuZero, a well-known deep model-based reinforcement learning algorithm, and explore how far it achieves its learning objective of a value-equivalent model and how useful the learned models are for policy improvement. Amongst various other insights, we conclude that the model learned by MuZero cannot effectively generalize to evaluate unseen policies, which limits the extent to which we can additionally improve the current policy by planning with the model.
First Go, then Post-Explore: the Benefits of Post-Exploration in Intrinsic Motivation
Dec 06, 2022



Go-Explore achieved breakthrough performance on challenging reinforcement learning (RL) tasks with sparse rewards. The key insight of Go-Explore was that successful exploration requires an agent to first return to an interesting state ('Go'), and only then explore into unknown terrain ('Explore'). We refer to such exploration after a goal is reached as 'post-exploration'. In this paper, we present a clear ablation study of post-exploration in a general intrinsically motivated goal exploration process (IMGEP) framework, that the Go-Explore paper did not show. We study the isolated potential of post-exploration, by turning it on and off within the same algorithm under both tabular and deep RL settings on both discrete navigation and continuous control tasks. Experiments on a range of MiniGrid and Mujoco environments show that post-exploration indeed helps IMGEP agents reach more diverse states and boosts their performance. In short, our work suggests that RL researchers should consider to use post-exploration in IMGEP when possible since it is effective, method-agnostic and easy to implement.
Continuous Episodic Control
Nov 28, 2022



Non-parametric episodic memory can be used to quickly latch onto high-reward experience in reinforcement learning tasks. In contrast to parametric deep reinforcement learning approaches, these methods only need to discover the solution once, and may then repeatedly solve the task. However, episodic control solutions are stored in discrete tables, and this approach has so far only been applied to discrete action space problems. Therefore, this paper introduces Continuous Episodic Control (CEC), a novel non-parametric episodic memory algorithm for sequential decision making in problems with a continuous action space. Results on several sparse-reward continuous control environments show that our proposed method learns faster than state-of-the-art model-free RL and memory-augmented RL algorithms, while maintaining good long-run performance as well. In short, CEC can be a fast approach for learning in continuous control tasks, and a useful addition to parametric RL methods in a hybrid approach as well.
When to Go, and When to Explore: The Benefit of Post-Exploration in Intrinsic Motivation
Apr 13, 2022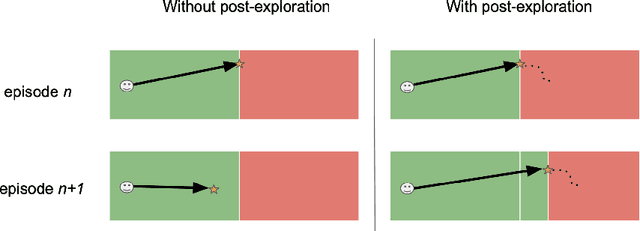

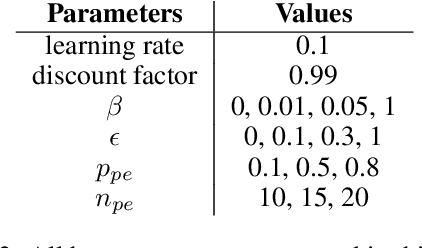
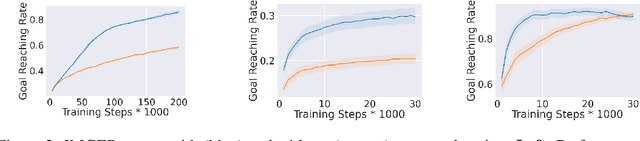
Go-Explore achieved breakthrough performance on challenging reinforcement learning (RL) tasks with sparse rewards. The key insight of Go-Explore was that successful exploration requires an agent to first return to an interesting state ('Go'), and only then explore into unknown terrain ('Explore'). We refer to such exploration after a goal is reached as 'post-exploration'. In this paper we present a systematic study of post-exploration, answering open questions that the Go-Explore paper did not answer yet. First, we study the isolated potential of post-exploration, by turning it on and off within the same algorithm. Subsequently, we introduce new methodology to adaptively decide when to post-explore and for how long to post-explore. Experiments on a range of MiniGrid environments show that post-exploration indeed boosts performance (with a bigger impact than tuning regular exploration parameters), and this effect is further enhanced by adaptively deciding when and for how long to post-explore. In short, our work identifies adaptive post-exploration as a promising direction for RL exploration research.