 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModularized Reinforcement Learning on LLMs: From MDP Creation to Exploration and Learning
Jun 20, 2026Reinforcement learning (RL) has become central to LLM post-training, yet the methods that dominate current pipelines, PPO and GRPO, represent only a narrow slice of what RL offers. Understanding why these methods prevail, and what alternatives exist, requires a principled examination of the design decisions that underlie any RL algorithm. This survey organizes that examination around three stages of algorithm construction. We begin with MDP creation: how the reward function, state space, action space, termination condition, and discount factor are, or could be, defined for LLM training. We then turn to exploration, covering temperature sampling, entropy regularization, intrinsic motivation, tree search, and curriculum learning. Finally, we address learning along four classical RL dimensions: model-free versus model-based, value-based versus policy-based versus actor-critic, on-policy versus off-policy, and credit assignment, including both Monte Carlo methods, which rely on full return estimates, and bootstrapping methods, which update estimates using other learned predictions. Mapping the LLM literature onto this taxonomy reveals a strikingly non-uniform distribution of research effort. Critic-free policy gradients and Monte Carlo credit assignment are densely populated, while value-based methods, off-policy actor-critic training, and bootstrapping-based credit assignment remain largely unexplored despite well-established counterparts in classical RL. These gaps represent concrete opportunities for transferring proven RL techniques to LLM training. By making these gaps explicit alongside the methods that have proven effective, this survey offers researchers in both RL and LLMs a shared framework for understanding current practice and identifying promising directions for future work.
Towards a Deeper Understanding of Reasoning Capabilities in Large Language Models
May 15, 2025



While large language models demonstrate impressive performance on static benchmarks, the true potential of large language models as self-learning and reasoning agents in dynamic environments remains unclear. This study systematically evaluates the efficacy of self-reflection, heuristic mutation, and planning as prompting techniques to test the adaptive capabilities of agents. We conduct experiments with various open-source language models in dynamic environments and find that larger models generally outperform smaller ones, but that strategic prompting can close this performance gap. Second, a too-long prompt can negatively impact smaller models on basic reactive tasks, while larger models show more robust behaviour. Third, advanced prompting techniques primarily benefit smaller models on complex games, but offer less improvement for already high-performing large language models. Yet, we find that advanced reasoning methods yield highly variable outcomes: while capable of significantly improving performance when reasoning and decision-making align, they also introduce instability and can lead to big performance drops. Compared to human performance, our findings reveal little evidence of true emergent reasoning. Instead, large language model performance exhibits persistent limitations in crucial areas such as planning, reasoning, and spatial coordination, suggesting that current-generation large language models still suffer fundamental shortcomings that may not be fully overcome through self-reflective prompting alone. Reasoning is a multi-faceted task, and while reasoning methods like Chain of thought improves multi-step reasoning on math word problems, our findings using dynamic benchmarks highlight important shortcomings in general reasoning capabilities, indicating a need to move beyond static benchmarks to capture the complexity of reasoning.
Reasoning with Large Language Models, a Survey
Jul 16, 2024



Scaling up language models to billions of parameters has opened up possibilities for in-context learning, allowing instruction tuning and few-shot learning on tasks that the model was not specifically trained for. This has achieved breakthrough performance on language tasks such as translation, summarization, and question-answering. Furthermore, in addition to these associative "System 1" tasks, recent advances in Chain-of-thought prompt learning have demonstrated strong "System 2" reasoning abilities, answering a question in the field of artificial general intelligence whether LLMs can reason. The field started with the question whether LLMs can solve grade school math word problems. This paper reviews the rapidly expanding field of prompt-based reasoning with LLMs. Our taxonomy identifies different ways to generate, evaluate, and control multi-step reasoning. We provide an in-depth coverage of core approaches and open problems, and we propose a research agenda for the near future. Finally, we highlight the relation between reasoning and prompt-based learning, and we discuss the relation between reasoning, sequential decision processes, and reinforcement learning. We find that self-improvement, self-reflection, and some metacognitive abilities of the reasoning processes are possible through the judicious use of prompts. True self-improvement and self-reasoning, to go from reasoning with LLMs to reasoning by LLMs, remains future work.
Solving Deep Reinforcement Learning Benchmarks with Linear Policy Networks
Feb 10, 2024



Although Deep Reinforcement Learning (DRL) methods can learn effective policies for challenging problems such as Atari games and robotics tasks, algorithms are complex and training times are often long. This study investigates how evolution strategies (ES) perform compared to gradient-based deep reinforcement learning methods. We use ES to optimize the weights of a neural network via neuroevolution, performing direct policy search. We benchmark both regular networks and policy networks consisting of a single linear layer from observations to actions; for three classical ES methods and for three gradient-based methods such as PPO. Our results reveal that ES can find effective linear policies for many RL benchmark tasks, in contrast to DRL methods that can only find successful policies using much larger networks, suggesting that current benchmarks are easier to solve than previously assumed. Interestingly, also for higher complexity tasks, ES achieves results comparable to gradient-based DRL algorithms. Furthermore, we find that by directly accessing the memory state of the game, ES are able to find successful policies in Atari, outperforming DQN. While gradient-based methods have dominated the field in recent years, ES offers an alternative that is easy to implement, parallelize, understand, and tune.
Multiagent Deep Reinforcement Learning: Challenges and Directions Towards Human-Like Approaches
Jun 29, 2021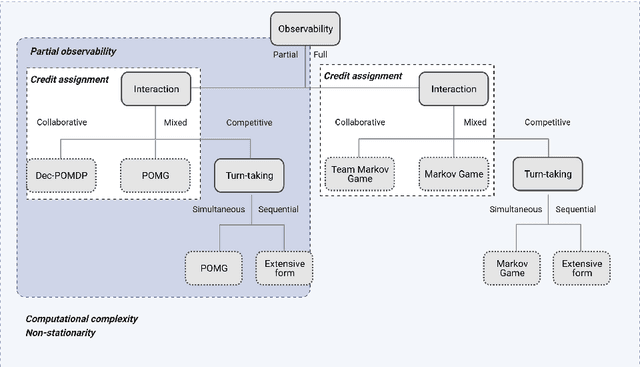
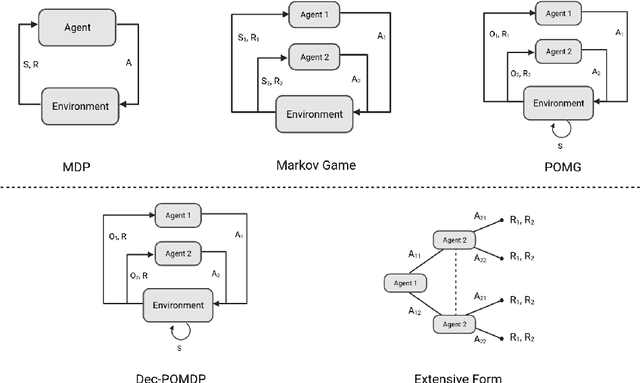

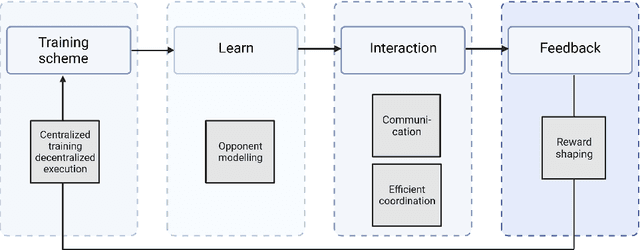
This paper surveys the field of multiagent deep reinforcement learning. The combination of deep neural networks with reinforcement learning has gained increased traction in recent years and is slowly shifting the focus from single-agent to multiagent environments. Dealing with multiple agents is inherently more complex as (a) the future rewards depend on the joint actions of multiple players and (b) the computational complexity of functions increases. We present the most common multiagent problem representations and their main challenges, and identify five research areas that address one or more of these challenges: centralised training and decentralised execution, opponent modelling, communication, efficient coordination, and reward shaping. We find that many computational studies rely on unrealistic assumptions or are not generalisable to other settings; they struggle to overcome the curse of dimensionality or nonstationarity. Approaches from psychology and sociology capture promising relevant behaviours such as communication and coordination. We suggest that, for multiagent reinforcement learning to be successful, future research addresses these challenges with an interdisciplinary approach to open up new possibilities for more human-oriented solutions in multiagent reinforcement learning.