 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactify 2: A Multimodal Fake News and Satire News Dataset
Apr 08, 2023



The internet gives the world an open platform to express their views and share their stories. While this is very valuable, it makes fake news one of our society's most pressing problems. Manual fact checking process is time consuming, which makes it challenging to disprove misleading assertions before they cause significant harm. This is he driving interest in automatic fact or claim verification. Some of the existing datasets aim to support development of automating fact-checking techniques, however, most of them are text based. Multi-modal fact verification has received relatively scant attention. In this paper, we provide a multi-modal fact-checking dataset called FACTIFY 2, improving Factify 1 by using new data sources and adding satire articles. Factify 2 has 50,000 new data instances. Similar to FACTIFY 1.0, we have three broad categories - support, no-evidence, and refute, with sub-categories based on the entailment of visual and textual data. We also provide a BERT and Vison Transformer based baseline, which acheives 65% F1 score in the test set. The baseline codes and the dataset will be made available at https://github.com/surya1701/Factify-2.0.
Memotion 3: Dataset on Sentiment and Emotion Analysis of Codemixed Hindi-English Memes
Mar 23, 2023



Memes are the new-age conveyance mechanism for humor on social media sites. Memes often include an image and some text. Memes can be used to promote disinformation or hatred, thus it is crucial to investigate in details. We introduce Memotion 3, a new dataset with 10,000 annotated memes. Unlike other prevalent datasets in the domain, including prior iterations of Memotion, Memotion 3 introduces Hindi-English Codemixed memes while prior works in the area were limited to only the English memes. We describe the Memotion task, the data collection and the dataset creation methodologies. We also provide a baseline for the task. The baseline code and dataset will be made available at https://github.com/Shreyashm16/Memotion-3.0
Knowledge Graph -- Deep Learning: A Case Study in Question Answering in Aviation Safety Domain
May 31, 2022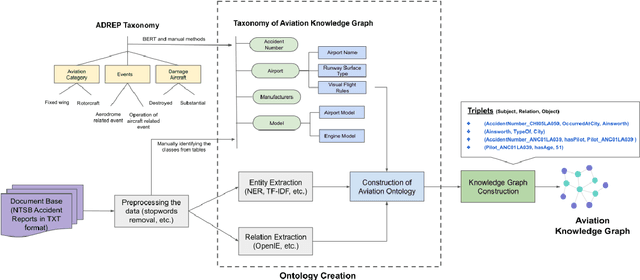
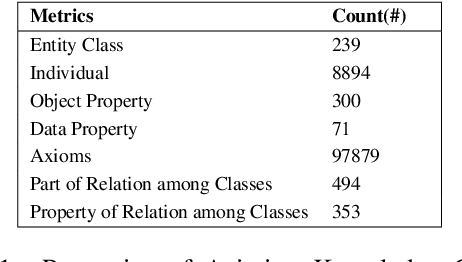
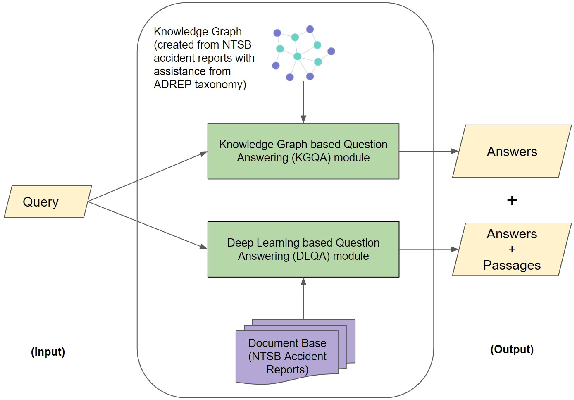
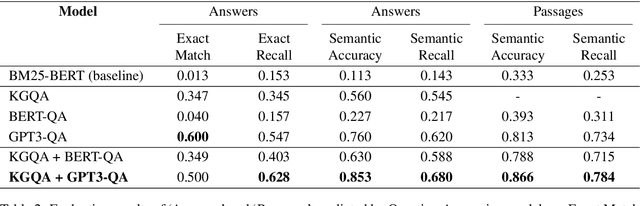
In the commercial aviation domain, there are a large number of documents, like, accident reports (NTSB, ASRS) and regulatory directives (ADs). There is a need for a system to access these diverse repositories efficiently in order to service needs in the aviation industry, like maintenance, compliance, and safety. In this paper, we propose a Knowledge Graph (KG) guided Deep Learning (DL) based Question Answering (QA) system for aviation safety. We construct a Knowledge Graph from Aircraft Accident reports and contribute this resource to the community of researchers. The efficacy of this resource is tested and proved by the aforesaid QA system. Natural Language Queries constructed from the documents mentioned above are converted into SPARQL (the interface language of the RDF graph database) queries and answered. On the DL side, we have two different QA models: (i) BERT QA which is a pipeline of Passage Retrieval (Sentence-BERT based) and Question Answering (BERT based), and (ii) the recently released GPT-3. We evaluate our system on a set of queries created from the accident reports. Our combined QA system achieves 9.3% increase in accuracy over GPT-3 and 40.3% increase over BERT QA. Thus, we infer that KG-DL performs better than either singly.
Commonsense and Named Entity Aware Knowledge Grounded Dialogue Generation
May 27, 2022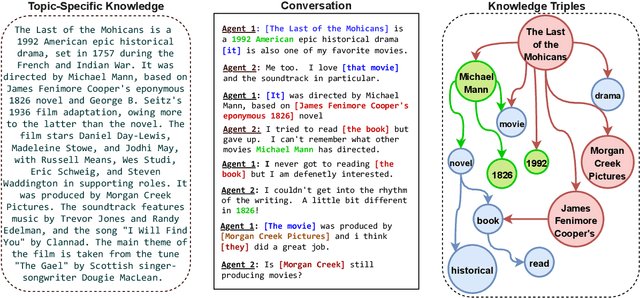
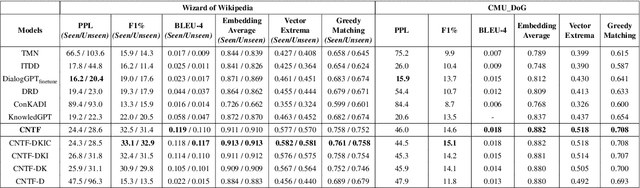
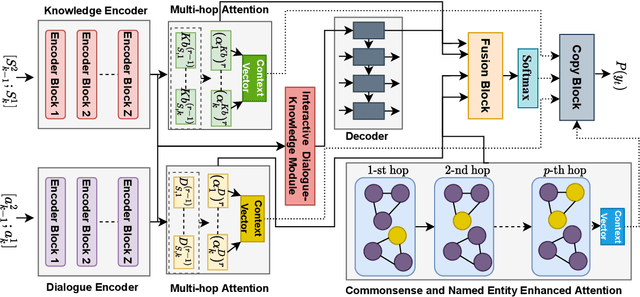
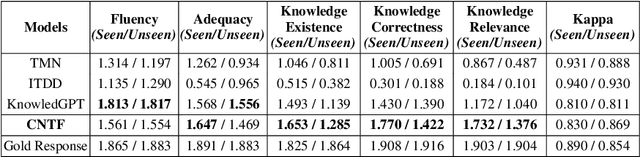
Grounding dialogue on external knowledge and interpreting linguistic patterns in dialogue history context, such as ellipsis, anaphora, and co-references is critical for dialogue comprehension and generation. In this paper, we present a novel open-domain dialogue generation model which effectively utilizes the large-scale commonsense and named entity based knowledge in addition to the unstructured topic-specific knowledge associated with each utterance. We enhance the commonsense knowledge with named entity-aware structures using co-references. Our proposed model utilizes a multi-hop attention layer to preserve the most accurate and critical parts of the dialogue history and the associated knowledge. In addition, we employ a Commonsense and Named Entity Enhanced Attention Module, which starts with the extracted triples from various sources and gradually finds the relevant supporting set of triples using multi-hop attention with the query vector obtained from the interactive dialogue-knowledge module. Empirical results on two benchmark dataset demonstrate that our model significantly outperforms the state-of-the-art methods in terms of both automatic evaluation metrics and human judgment. Our code is publicly available at \href{https://github.com/deekshaVarshney/CNTF}{https://github.com/deekshaVarshney/CNTF}; \href{https://www.iitp.ac.in/~ai-nlp-ml/resources/codes/CNTF.zip}{https://www.iitp.ac.in/-ai-nlp-ml/resources/ codes/CNTF.zip}.
EmoInHindi: A Multi-label Emotion and Intensity Annotated Dataset in Hindi for Emotion Recognition in Dialogues
May 27, 2022
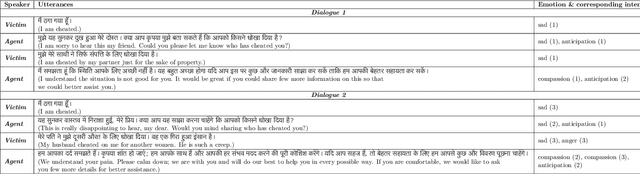
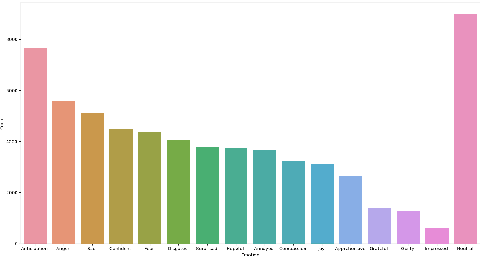
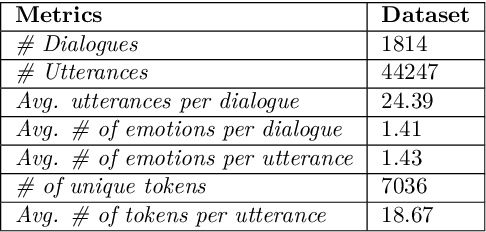
The long-standing goal of Artificial Intelligence (AI) has been to create human-like conversational systems. Such systems should have the ability to develop an emotional connection with the users, hence emotion recognition in dialogues is an important task. Emotion detection in dialogues is a challenging task because humans usually convey multiple emotions with varying degrees of intensities in a single utterance. Moreover, emotion in an utterance of a dialogue may be dependent on previous utterances making the task more complex. Emotion recognition has always been in great demand. However, most of the existing datasets for multi-label emotion and intensity detection in conversations are in English. To this end, we create a large conversational dataset in Hindi named EmoInHindi for multi-label emotion and intensity recognition in conversations containing 1,814 dialogues with a total of 44,247 utterances. We prepare our dataset in a Wizard-of-Oz manner for mental health and legal counselling of crime victims. Each utterance of the dialogue is annotated with one or more emotion categories from the 16 emotion classes including neutral, and their corresponding intensity values. We further propose strong contextual baselines that can detect emotion(s) and the corresponding intensity of an utterance given the conversational context.
COVIDRead: A Large-scale Question Answering Dataset on COVID-19
Oct 05, 2021

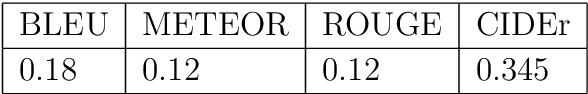
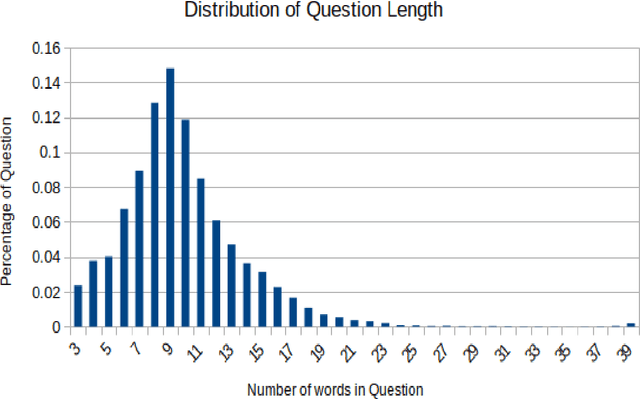
During this pandemic situation, extracting any relevant information related to COVID-19 will be immensely beneficial to the community at large. In this paper, we present a very important resource, COVIDRead, a Stanford Question Answering Dataset (SQuAD) like dataset over more than 100k question-answer pairs. The dataset consists of Context-Answer-Question triples. Primarily the questions from the context are constructed in an automated way. After that, the system-generated questions are manually checked by hu-mans annotators. This is a precious resource that could serve many purposes, ranging from common people queries regarding this very uncommon disease to managing articles by editors/associate editors of a journal. We establish several end-to-end neural network based baseline models that attain the lowest F1 of 32.03% and the highest F1 of 37.19%. To the best of our knowledge, we are the first to provide this kind of QA dataset in such a large volume on COVID-19. This dataset creates a new avenue of carrying out research on COVID-19 by providing a benchmark dataset and a baseline model.
Towards Developing a Multilingual and Code-Mixed Visual Question Answering System by Knowledge Distillation
Sep 10, 2021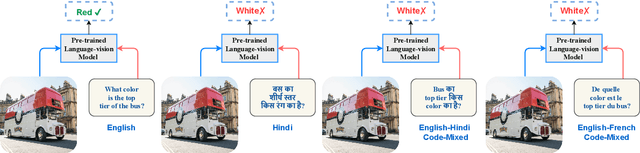
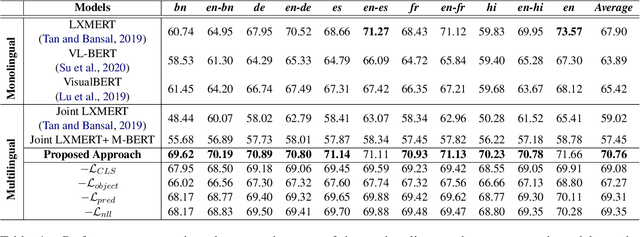
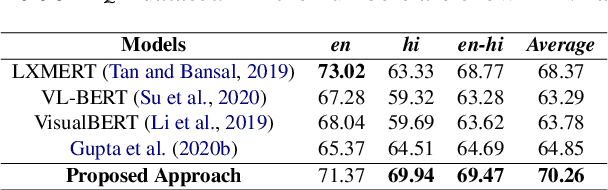
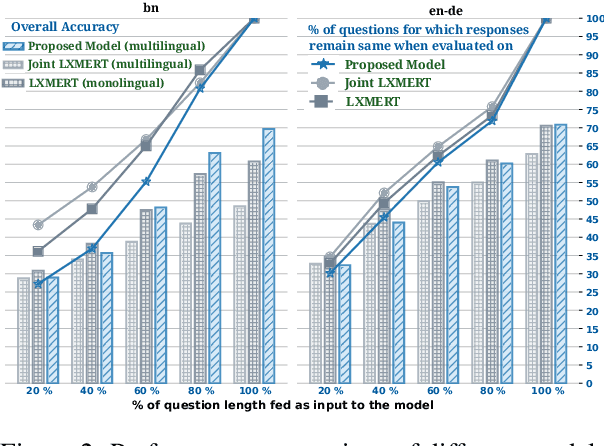
Pre-trained language-vision models have shown remarkable performance on the visual question answering (VQA) task. However, most pre-trained models are trained by only considering monolingual learning, especially the resource-rich language like English. Training such models for multilingual setups demand high computing resources and multilingual language-vision dataset which hinders their application in practice. To alleviate these challenges, we propose a knowledge distillation approach to extend an English language-vision model (teacher) into an equally effective multilingual and code-mixed model (student). Unlike the existing knowledge distillation methods, which only use the output from the last layer of the teacher network for distillation, our student model learns and imitates the teacher from multiple intermediate layers (language and vision encoders) with appropriately designed distillation objectives for incremental knowledge extraction. We also create the large-scale multilingual and code-mixed VQA dataset in eleven different language setups considering the multiple Indian and European languages. Experimental results and in-depth analysis show the effectiveness of the proposed VQA model over the pre-trained language-vision models on eleven diverse language setups.
M2H2: A Multimodal Multiparty Hindi Dataset For Humor Recognition in Conversations
Aug 03, 2021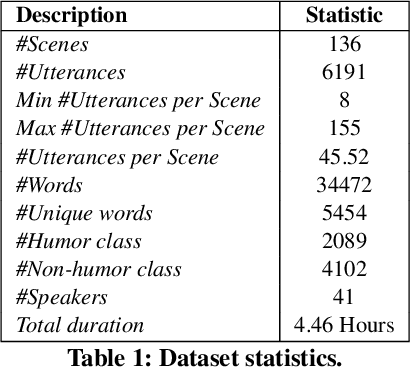


Humor recognition in conversations is a challenging task that has recently gained popularity due to its importance in dialogue understanding, including in multimodal settings (i.e., text, acoustics, and visual). The few existing datasets for humor are mostly in English. However, due to the tremendous growth in multilingual content, there is a great demand to build models and systems that support multilingual information access. To this end, we propose a dataset for Multimodal Multiparty Hindi Humor (M2H2) recognition in conversations containing 6,191 utterances from 13 episodes of a very popular TV series "Shrimaan Shrimati Phir Se". Each utterance is annotated with humor/non-humor labels and encompasses acoustic, visual, and textual modalities. We propose several strong multimodal baselines and show the importance of contextual and multimodal information for humor recognition in conversations. The empirical results on M2H2 dataset demonstrate that multimodal information complements unimodal information for humor recognition. The dataset and the baselines are available at http://www.iitp.ac.in/~ai-nlp-ml/resources.html and https://github.com/declare-lab/M2H2-dataset.
IITP at WAT 2021: System description for English-Hindi Multimodal Translation Task
Jul 04, 2021


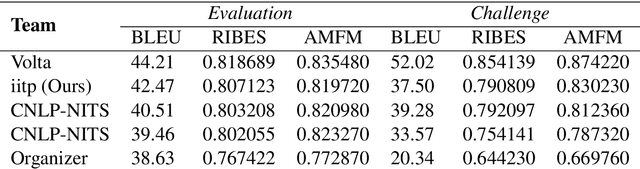
Neural Machine Translation (NMT) is a predominant machine translation technology nowadays because of its end-to-end trainable flexibility. However, NMT still struggles to translate properly in low-resource settings specifically on distant language pairs. One way to overcome this is to use the information from other modalities if available. The idea is that despite differences in languages, both the source and target language speakers see the same thing and the visual representation of both the source and target is the same, which can positively assist the system. Multimodal information can help the NMT system to improve the translation by removing ambiguity on some phrases or words. We participate in the 8th Workshop on Asian Translation (WAT - 2021) for English-Hindi multimodal translation task and achieve 42.47 and 37.50 BLEU points for Evaluation and Challenge subset, respectively.
IITP at AILA 2019: System Report for Artificial Intelligence for Legal Assistance Shared Task
May 24, 2021
In this article, we present a description of our systems as a part of our participation in the shared task namely Artificial Intelligence for Legal Assistance (AILA 2019). This is an integral event of Forum for Information Retrieval Evaluation-2019. The outcomes of this track would be helpful for the automation of the working process of the Indian Judiciary System. The manual working procedures and documentation at any level (from lower to higher court) of the judiciary system are very complex in nature. The systems produced as a part of this track would assist the law practitioners. It would be helpful for common men too. This kind of track also opens the path of research of Natural Language Processing (NLP) in the judicial domain. This track defined two problems such as Task 1: Identifying relevant prior cases for a given situation and Task 2: Identifying the most relevant statutes for a given situation. We tackled both of them. Our proposed approaches are based on BM25 and Doc2Vec. As per the results declared by the task organizers, we are in 3rd and a modest position in Task 1 and Task 2 respectively.