 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Optimistic Methods for Convex-Concave Saddle Point Problems
Feb 19, 2022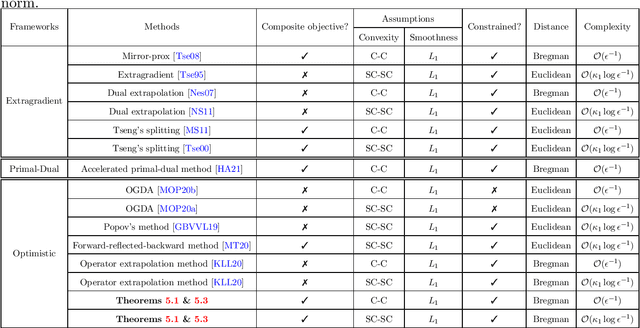
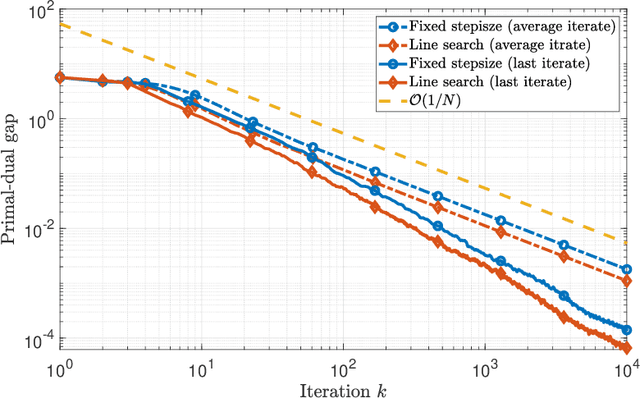
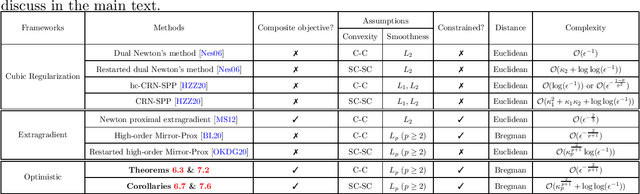
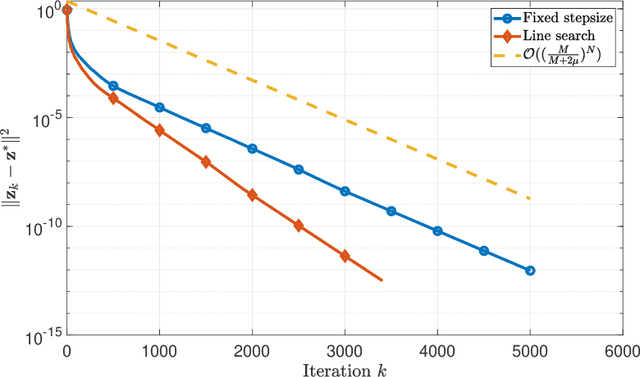
The optimistic gradient method has seen increasing popularity as an efficient first-order method for solving convex-concave saddle point problems. To analyze its iteration complexity, a recent work [arXiv:1901.08511] proposed an interesting perspective that interprets the optimistic gradient method as an approximation to the proximal point method. In this paper, we follow this approach and distill the underlying idea of optimism to propose a generalized optimistic method, which encompasses the optimistic gradient method as a special case. Our general framework can handle constrained saddle point problems with composite objective functions and can work with arbitrary norms with compatible Bregman distances. Moreover, we also develop an adaptive line search scheme to select the stepsizes without knowledge of the smoothness coefficients. We instantiate our method with first-order, second-order and higher-order oracles and give sharp global iteration complexity bounds. When the objective function is convex-concave, we show that the averaged iterates of our $p$-th-order method ($p\geq 1$) converge at a rate of $\mathcal{O}(1/N^\frac{p+1}{2})$. When the objective function is further strongly-convex-strongly-concave, we prove a complexity bound of $\mathcal{O}(\frac{L_1}{\mu}\log\frac{1}{\epsilon})$ for our first-order method and a bound of $\mathcal{O}((L_p D^\frac{p-1}{2}/\mu)^{\frac{2}{p+1}}+\log\log\frac{1}{\epsilon})$ for our $p$-th-order method ($p\geq 2$) respectively, where $L_p$ ($p\geq 1$) is the Lipschitz constant of the $p$-th-order derivative, $\mu$ is the strongly-convex parameter, and $D$ is the initial Bregman distance to the saddle point. Moreover, our line search scheme provably only requires an almost constant number of calls to a subproblem solver per iteration on average, making our first-order and second-order methods particularly amenable to implementation.
The Power of Adaptivity in SGD: Self-Tuning Step Sizes with Unbounded Gradients and Affine Variance
Feb 11, 2022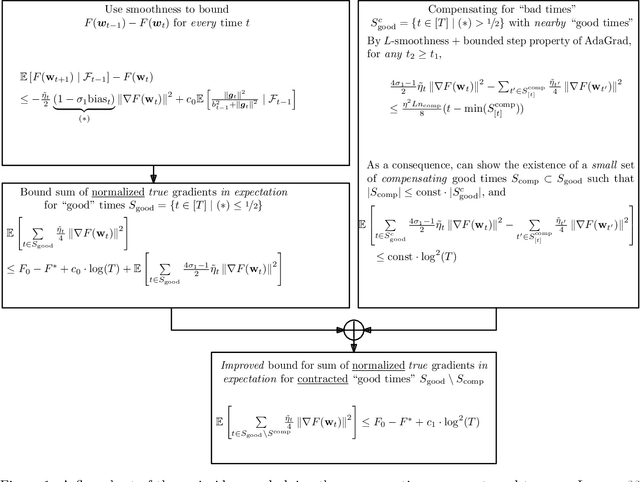

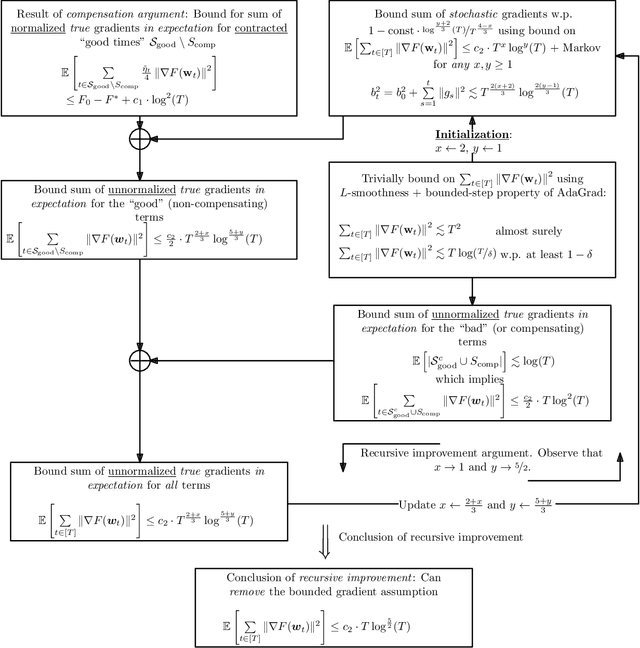
We study convergence rates of AdaGrad-Norm as an exemplar of adaptive stochastic gradient methods (SGD), where the step sizes change based on observed stochastic gradients, for minimizing non-convex, smooth objectives. Despite their popularity, the analysis of adaptive SGD lags behind that of non adaptive methods in this setting. Specifically, all prior works rely on some subset of the following assumptions: (i) uniformly-bounded gradient norms, (ii) uniformly-bounded stochastic gradient variance (or even noise support), (iii) conditional independence between the step size and stochastic gradient. In this work, we show that AdaGrad-Norm exhibits an order optimal convergence rate of $\mathcal{O}\left(\frac{\mathrm{poly}\log(T)}{\sqrt{T}}\right)$ after $T$ iterations under the same assumptions as optimally-tuned non adaptive SGD (unbounded gradient norms and affine noise variance scaling), and crucially, without needing any tuning parameters. We thus establish that adaptive gradient methods exhibit order-optimal convergence in much broader regimes than previously understood.
MAML and ANIL Provably Learn Representations
Feb 07, 2022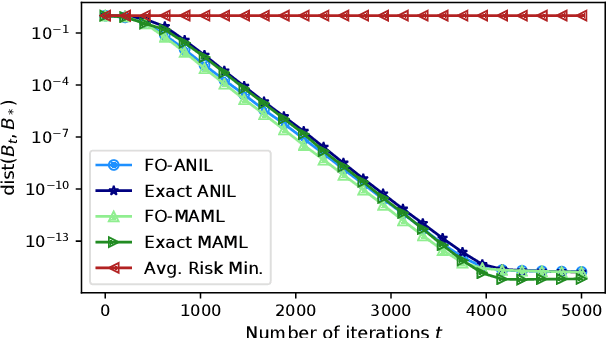
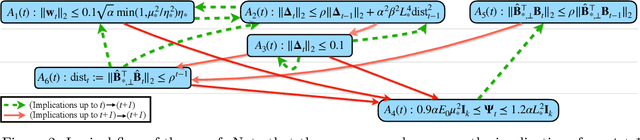
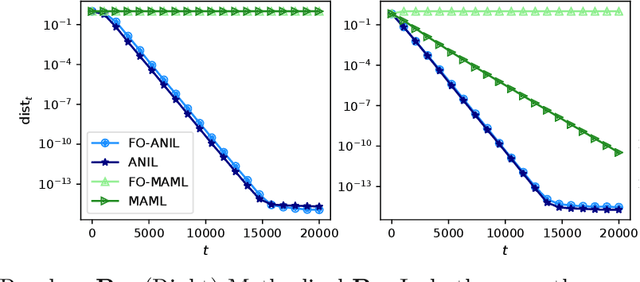
Recent empirical evidence has driven conventional wisdom to believe that gradient-based meta-learning (GBML) methods perform well at few-shot learning because they learn an expressive data representation that is shared across tasks. However, the mechanics of GBML have remained largely mysterious from a theoretical perspective. In this paper, we prove that two well-known GBML methods, MAML and ANIL, as well as their first-order approximations, are capable of learning common representation among a set of given tasks. Specifically, in the well-known multi-task linear representation learning setting, they are able to recover the ground-truth representation at an exponentially fast rate. Moreover, our analysis illuminates that the driving force causing MAML and ANIL to recover the underlying representation is that they adapt the final layer of their model, which harnesses the underlying task diversity to improve the representation in all directions of interest. To the best of our knowledge, these are the first results to show that MAML and/or ANIL learn expressive representations and to rigorously explain why they do so.
Minimax Optimization: The Case of Convex-Submodular
Nov 01, 2021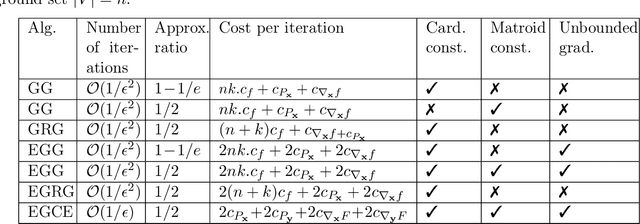
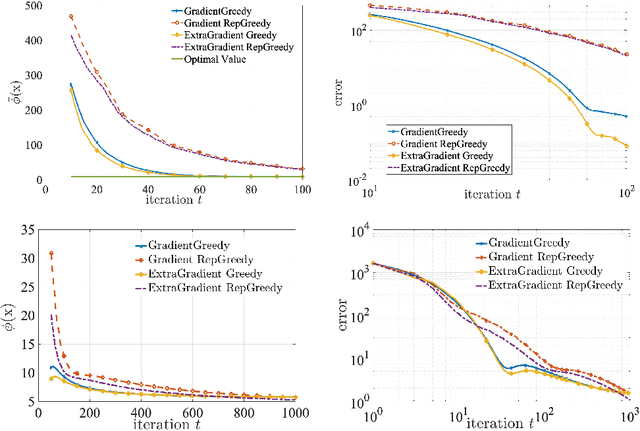
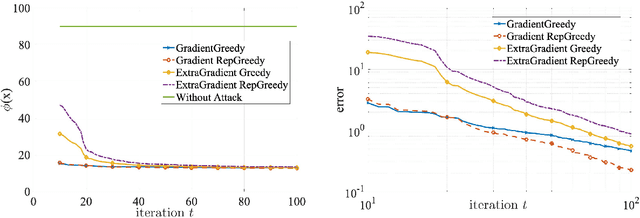
Minimax optimization has been central in addressing various applications in machine learning, game theory, and control theory. Prior literature has thus far mainly focused on studying such problems in the continuous domain, e.g., convex-concave minimax optimization is now understood to a significant extent. Nevertheless, minimax problems extend far beyond the continuous domain to mixed continuous-discrete domains or even fully discrete domains. In this paper, we study mixed continuous-discrete minimax problems where the minimization is over a continuous variable belonging to Euclidean space and the maximization is over subsets of a given ground set. We introduce the class of convex-submodular minimax problems, where the objective is convex with respect to the continuous variable and submodular with respect to the discrete variable. Even though such problems appear frequently in machine learning applications, little is known about how to address them from algorithmic and theoretical perspectives. For such problems, we first show that obtaining saddle points are hard up to any approximation, and thus introduce new notions of (near-) optimality. We then provide several algorithmic procedures for solving convex and monotone-submodular minimax problems and characterize their convergence rates, computational complexity, and quality of the final solution according to our notions of optimally. Our proposed algorithms are iterative and combine tools from both discrete and continuous optimization. Finally, we provide numerical experiments to showcase the effectiveness of our purposed methods.
Exploiting Local Convergence of Quasi-Newton Methods Globally: Adaptive Sample Size Approach
Jun 10, 2021
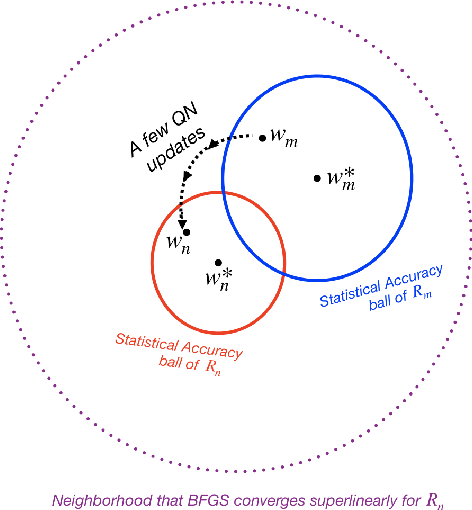
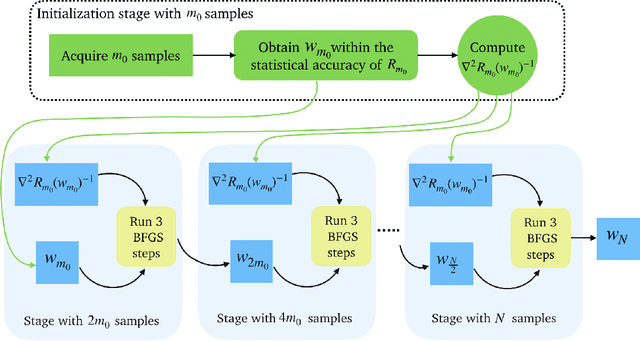
In this paper, we study the application of quasi-Newton methods for solving empirical risk minimization (ERM) problems defined over a large dataset. Traditional deterministic and stochastic quasi-Newton methods can be executed to solve such problems; however, it is known that their global convergence rate may not be better than first-order methods, and their local superlinear convergence only appears towards the end of the learning process. In this paper, we use an adaptive sample size scheme that exploits the superlinear convergence of quasi-Newton methods globally and throughout the entire learning process. The main idea of the proposed adaptive sample size algorithms is to start with a small subset of data points and solve their corresponding ERM problem within its statistical accuracy, and then enlarge the sample size geometrically and use the optimal solution of the problem corresponding to the smaller set as an initial point for solving the subsequent ERM problem with more samples. We show that if the initial sample size is sufficiently large and we use quasi-Newton methods to solve each subproblem, the subproblems can be solved superlinearly fast (after at most three iterations), as we guarantee that the iterates always stay within a neighborhood that quasi-Newton methods converge superlinearly. Numerical experiments on various datasets confirm our theoretical results and demonstrate the computational advantages of our method.
Exploiting Shared Representations for Personalized Federated Learning
Feb 14, 2021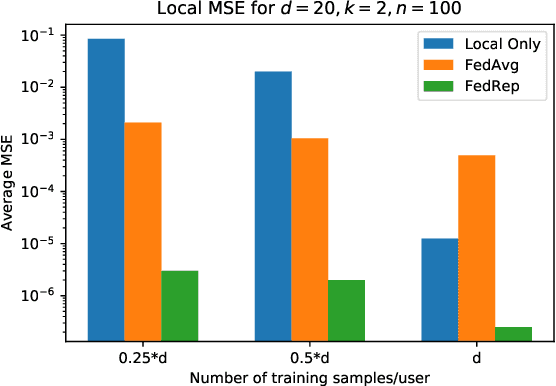
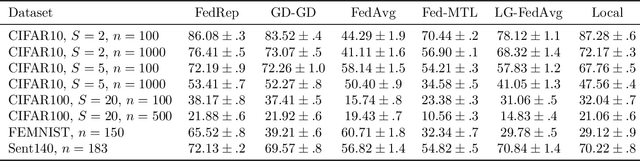
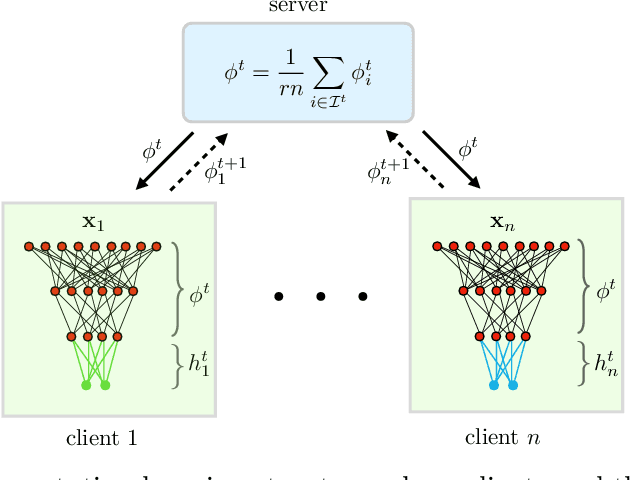
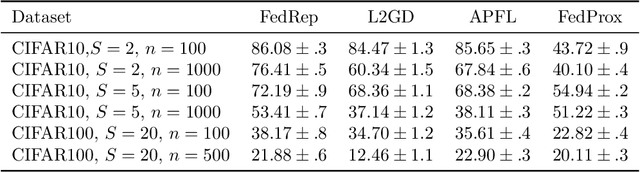
Deep neural networks have shown the ability to extract universal feature representations from data such as images and text that have been useful for a variety of learning tasks. However, the fruits of representation learning have yet to be fully-realized in federated settings. Although data in federated settings is often non-i.i.d. across clients, the success of centralized deep learning suggests that data often shares a global feature representation, while the statistical heterogeneity across clients or tasks is concentrated in the labels. Based on this intuition, we propose a novel federated learning framework and algorithm for learning a shared data representation across clients and unique local heads for each client. Our algorithm harnesses the distributed computational power across clients to perform many local-updates with respect to the low-dimensional local parameters for every update of the representation. We prove that this method obtains linear convergence to the ground-truth representation with near-optimal sample complexity in a linear setting, demonstrating that it can efficiently reduce the problem dimension for each client. Further, we provide extensive experimental results demonstrating the improvement of our method over alternative personalized federated learning approaches in heterogeneous settings.
Generalization of Model-Agnostic Meta-Learning Algorithms: Recurring and Unseen Tasks
Feb 07, 2021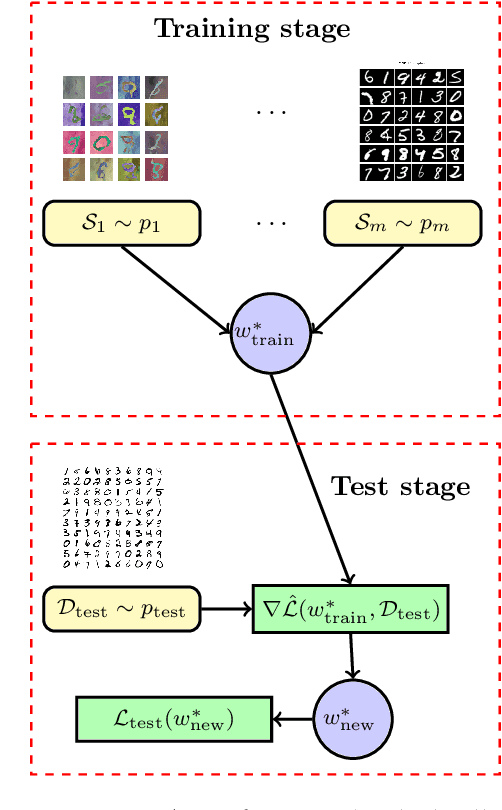
In this paper, we study the generalization properties of Model-Agnostic Meta-Learning (MAML) algorithms for supervised learning problems. We focus on the setting in which we train the MAML model over $m$ tasks, each with $n$ data points, and characterize its generalization error from two points of view: First, we assume the new task at test time is one of the training tasks, and we show that, for strongly convex objective functions, the expected excess population loss is bounded by $\mathcal{O}(1/mn)$. Second, we consider the MAML algorithm's generalization to an unseen task and show that the resulting generalization error depends on the total variation distance between the underlying distributions of the new task and the tasks observed during the training process. Our proof techniques rely on the connections between algorithmic stability and generalization bounds of algorithms. In particular, we propose a new definition of stability for meta-learning algorithms, which allows us to capture the role of both the number of tasks $m$ and number of samples per task $n$ on the generalization error of MAML.
Straggler-Resilient Federated Learning: Leveraging the Interplay Between Statistical Accuracy and System Heterogeneity
Dec 28, 2020

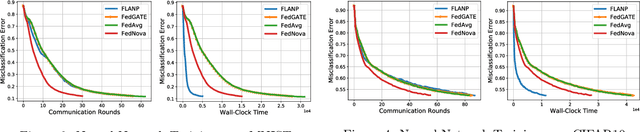
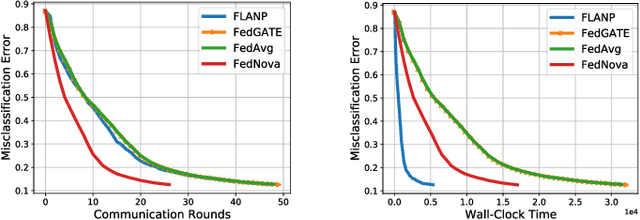
Federated Learning is a novel paradigm that involves learning from data samples distributed across a large network of clients while the data remains local. It is, however, known that federated learning is prone to multiple system challenges including system heterogeneity where clients have different computation and communication capabilities. Such heterogeneity in clients' computation speeds has a negative effect on the scalability of federated learning algorithms and causes significant slow-down in their runtime due to the existence of stragglers. In this paper, we propose a novel straggler-resilient federated learning method that incorporates statistical characteristics of the clients' data to adaptively select the clients in order to speed up the learning procedure. The key idea of our algorithm is to start the training procedure with faster nodes and gradually involve the slower nodes in the model training once the statistical accuracy of the data corresponding to the current participating nodes is reached. The proposed approach reduces the overall runtime required to achieve the statistical accuracy of data of all nodes, as the solution for each stage is close to the solution of the subsequent stage with more samples and can be used as a warm-start. Our theoretical results characterize the speedup gain in comparison to standard federated benchmarks for strongly convex objectives, and our numerical experiments also demonstrate significant speedups in wall-clock time of our straggler-resilient method compared to federated learning benchmarks.
Why Does MAML Outperform ERM? An Optimization Perspective
Oct 27, 2020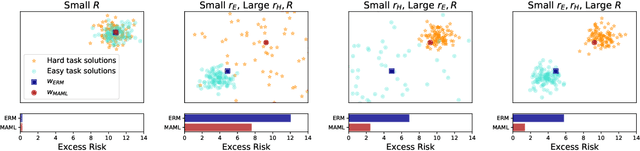
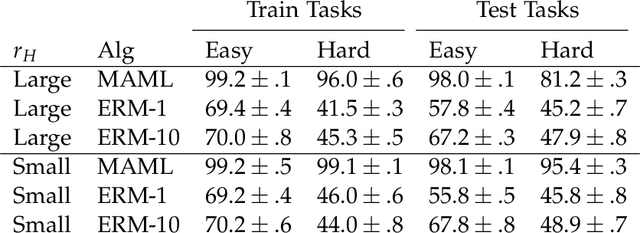
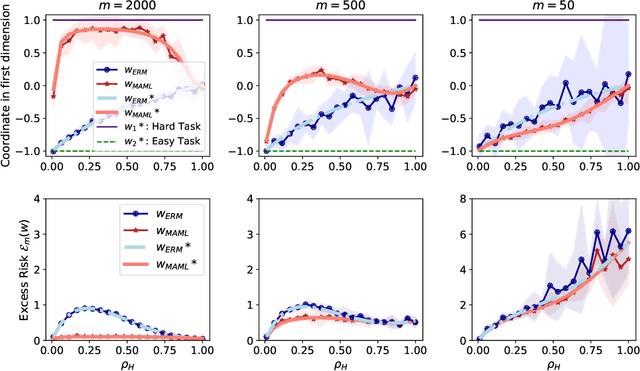
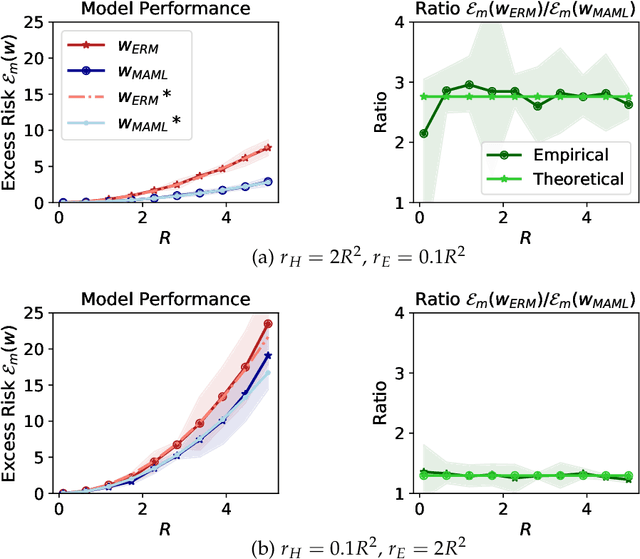
Model-Agnostic Meta-Learning (MAML) has demonstrated widespread success in training models that can quickly adapt to new tasks via one or few stochastic gradient descent steps. However, the MAML objective is significantly more difficult to optimize compared to standard Empirical Risk Minimization (ERM), and little is understood about how much MAML improves over ERM in terms of the fast adaptability of their solutions in various scenarios. We analytically address this issue in a linear regression setting consisting of a mixture of easy and hard tasks, where hardness is determined by the number of gradient steps required to solve the task. Specifically, we prove that for $\Omega(d_{\text{eff}})$ labelled test samples (for gradient-based fine-tuning) where $d_{\text{eff}}$ is the effective dimension of the problem, in order for MAML to achieve substantial gain over ERM, the optimal solutions of the hard tasks must be closely packed together with the center far from the center of the easy task optimal solutions. We show that these insights also apply in a low-dimensional feature space when both MAML and ERM learn a representation of the tasks, which reduces the effective problem dimension. Further, our few-shot image classification experiments suggest that our results generalize beyond linear regression.
Submodular Meta-Learning
Jul 11, 2020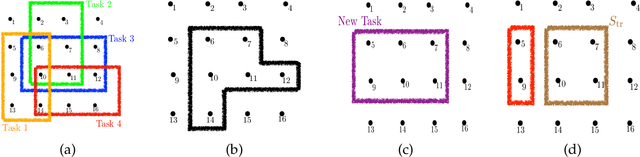
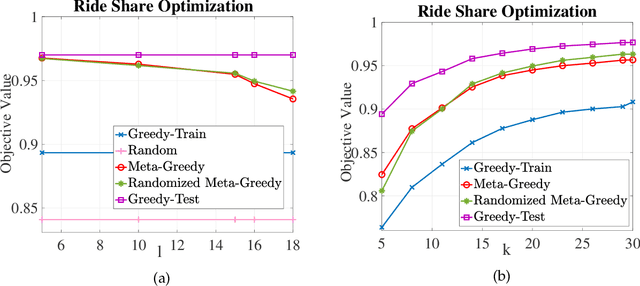
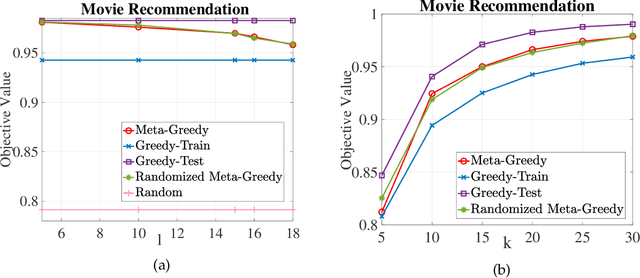
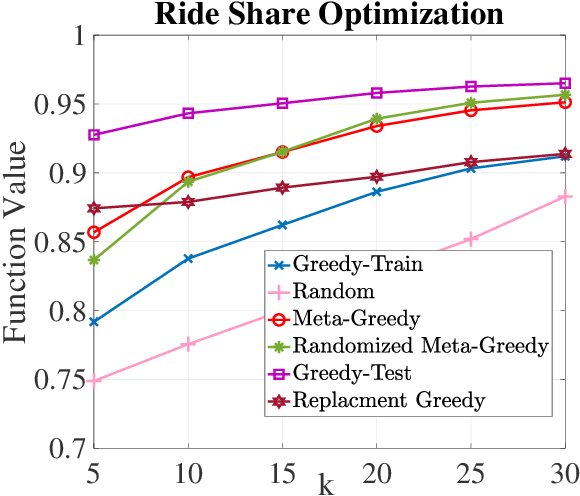
In this paper, we introduce a discrete variant of the meta-learning framework. Meta-learning aims at exploiting prior experience and data to improve performance on future tasks. By now, there exist numerous formulations for meta-learning in the continuous domain. Notably, the Model-Agnostic Meta-Learning (MAML) formulation views each task as a continuous optimization problem and based on prior data learns a suitable initialization that can be adapted to new, unseen tasks after a few simple gradient updates. Motivated by this terminology, we propose a novel meta-learning framework in the discrete domain where each task is equivalent to maximizing a set function under a cardinality constraint. Our approach aims at using prior data, i.e., previously visited tasks, to train a proper initial solution set that can be quickly adapted to a new task at a relatively low computational cost. This approach leads to (i) a personalized solution for each individual task, and (ii) significantly reduced computational cost at test time compared to the case where the solution is fully optimized once the new task is revealed. The training procedure is performed by solving a challenging discrete optimization problem for which we present deterministic and randomized algorithms. In the case where the tasks are monotone and submodular, we show strong theoretical guarantees for our proposed methods even though the training objective may not be submodular. We also demonstrate the effectiveness of our framework on two real-world problem instances where we observe that our methods lead to a significant reduction in computational complexity in solving the new tasks while incurring a small performance loss compared to when the tasks are fully optimized.