 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably Convergent Policy Gradient Methods for Model-Agnostic Meta-Reinforcement Learning
Paper and Code
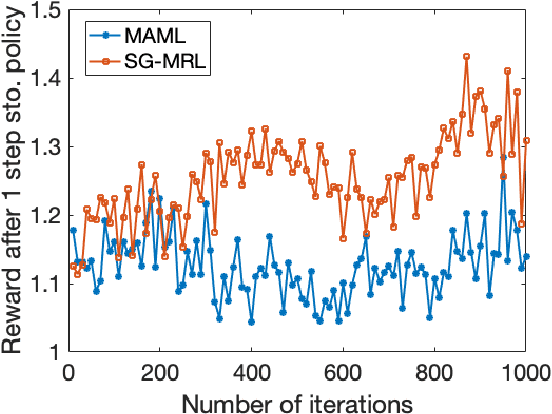
We consider Model-Agnostic Meta-Learning (MAML) methods for Reinforcement Learning (RL) problems where the goal is to find a policy (using data from several tasks represented by Markov Decision Processes (MDPs)) that can be updated by one step of stochastic policy gradient for the realized MDP. In particular, using stochastic gradients in MAML update step is crucial for RL problems since computation of exact gradients requires access to a large number of possible trajectories. For this formulation, we propose a variant of the MAML method, named Stochastic Gradient Meta-Reinforcement Learning (SG-MRL), and study its convergence properties. We derive the iteration and sample complexity of SG-MRL to find an $\epsilon$-first-order stationary point, which, to the best of our knowledge, provides the first convergence guarantee for model-agnostic meta-reinforcement learning algorithms. We further show how our results extend to the case where more than one step of stochastic policy gradient method is used in the update during the test time.