 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoice Morphing: Two Identities in One Voice
Sep 05, 2023



In a biometric system, each biometric sample or template is typically associated with a single identity. However, recent research has demonstrated the possibility of generating "morph" biometric samples that can successfully match more than a single identity. Morph attacks are now recognized as a potential security threat to biometric systems. However, most morph attacks have been studied on biometric modalities operating in the image domain, such as face, fingerprint, and iris. In this preliminary work, we introduce Voice Identity Morphing (VIM) - a voice-based morph attack that can synthesize speech samples that impersonate the voice characteristics of a pair of individuals. Our experiments evaluate the vulnerabilities of two popular speaker recognition systems, ECAPA-TDNN and x-vector, to VIM, with a success rate (MMPMR) of over 80% at a false match rate of 1% on the Librispeech dataset.
On the Biometric Capacity of Generative Face Models
Aug 03, 2023



There has been tremendous progress in generating realistic faces with high fidelity over the past few years. Despite this progress, a crucial question remains unanswered: "Given a generative face model, how many unique identities can it generate?" In other words, what is the biometric capacity of the generative face model? A scientific basis for answering this question will benefit evaluating and comparing different generative face models and establish an upper bound on their scalability. This paper proposes a statistical approach to estimate the biometric capacity of generated face images in a hyperspherical feature space. We employ our approach on multiple generative models, including unconditional generators like StyleGAN, Latent Diffusion Model, and "Generated Photos," as well as DCFace, a class-conditional generator. We also estimate capacity w.r.t. demographic attributes such as gender and age. Our capacity estimates indicate that (a) under ArcFace representation at a false acceptance rate (FAR) of 0.1%, StyleGAN3 and DCFace have a capacity upper bound of $1.43\times10^6$ and $1.190\times10^4$, respectively; (b) the capacity reduces drastically as we lower the desired FAR with an estimate of $1.796\times10^4$ and $562$ at FAR of 1% and 10%, respectively, for StyleGAN3; (c) there is no discernible disparity in the capacity w.r.t gender; and (d) for some generative models, there is an appreciable disparity in the capacity w.r.t age. Code is available at https://github.com/human-analysis/capacity-generative-face-models.
Synthesizing Forestry Images Conditioned on Plant Phenotype Using a Generative Adversarial Network
Jul 07, 2023Plant phenology and phenotype prediction using remote sensing data is increasingly gaining the attention of the plant science community to improve agricultural productivity. In this work, we generate synthetic forestry images that satisfy certain phenotypic attributes, viz. canopy greenness. The greenness index of plants describes a particular vegetation type in a mixed forest. Our objective is to develop a Generative Adversarial Network (GAN) to synthesize forestry images conditioned on this continuous attribute, i.e., greenness of vegetation, over a specific region of interest. The training data is based on the automated digital camera imagery provided by the National Ecological Observatory Network (NEON) and processed by the PhenoCam Network. The synthetic images generated by our method are also used to predict another phenotypic attribute, viz., redness of plants. The Structural SIMilarity (SSIM) index is utilized to assess the quality of the synthetic images. The greenness and redness indices of the generated synthetic images are compared against that of the original images using Root Mean Squared Error (RMSE) in order to evaluate their accuracy and integrity. Moreover, the generalizability and scalability of our proposed GAN model is determined by effectively transforming it to generate synthetic images for other forest sites and vegetation types.
FarSight: A Physics-Driven Whole-Body Biometric System at Large Distance and Altitude
Jun 29, 2023



Whole-body biometric recognition is an important area of research due to its vast applications in law enforcement, border security, and surveillance. This paper presents the end-to-end design, development and evaluation of FarSight, an innovative software system designed for whole-body (fusion of face, gait and body shape) biometric recognition. FarSight accepts videos from elevated platforms and drones as input and outputs a candidate list of identities from a gallery. The system is designed to address several challenges, including (i) low-quality imagery, (ii) large yaw and pitch angles, (iii) robust feature extraction to accommodate large intra-person variabilities and large inter-person similarities, and (iv) the large domain gap between training and test sets. FarSight combines the physics of imaging and deep learning models to enhance image restoration and biometric feature encoding. We test FarSight's effectiveness using the newly acquired IARPA Biometric Recognition and Identification at Altitude and Range (BRIAR) dataset. Notably, FarSight demonstrated a substantial performance increase on the BRIAR dataset, with gains of +11.82% Rank-20 identification and +11.3% TAR@1% FAR.
iWarpGAN: Disentangling Identity and Style to Generate Synthetic Iris Images
May 21, 2023Generative Adversarial Networks (GANs) have shown success in approximating complex distributions for synthetic image generation and for editing specific portions of an input image, particularly in faces. However, current GAN-based methods for generating biometric images, such as iris, have limitations in controlling the identity of the generated images, i.e., the synthetically generated images often closely resemble images in the training dataset. Further, the generated images often lack diversity in terms of the number of unique identities represented in them. To overcome these issues, we propose iWarpGAN that disentangles identity and style in the context of the iris modality by using two transformation pathways: Identity Transformation Pathway to generate unique identities from the training set, and Style Transformation Pathway to extract the style code from a reference image and output an iris image using this style. By concatenating the transformed identity code and reference style code, iWarpGAN generates iris images with both inter and intra-class variations. The efficacy of the proposed method in generating Iris DeepFakes is evaluated both qualitatively and quantitatively using ISO/IEC 29794-6 Standard Quality Metrics and the VeriEye iris matcher. Finally, the utility of the synthetically generated images is demonstrated by improving the performance of multiple deep learning based iris matchers that augment synthetic data with real data during the training process.
Vocal Style Factorization for Effective Speaker Recognition in Affective Scenarios
May 13, 2023The accuracy of automated speaker recognition is negatively impacted by change in emotions in a person's speech. In this paper, we hypothesize that speaker identity is composed of various vocal style factors that may be learned from unlabeled data and re-combined using a neural network architecture to generate holistic speaker identity representations for affective scenarios. In this regard we propose the E-Vector architecture, composed of a 1-D CNN for learning speaker identity features and a vocal style factorization technique for determining vocal styles. Experiments conducted on the MSP-Podcast dataset demonstrate that the proposed architecture improves state-of-the-art speaker recognition accuracy in the affective domain over baseline ECAPA-TDNN speaker recognition models. For instance, the true match rate at a false match rate of 1% improves from 27.6% to 46.2%.
Periocular Biometrics: A Modality for Unconstrained Scenarios
Dec 28, 2022Periocular refers to the region of the face that surrounds the eye socket. This is a feature-rich area that can be used by itself to determine the identity of an individual. It is especially useful when the iris or the face cannot be reliably acquired. This can be the case of unconstrained or uncooperative scenarios, where the face may appear partially occluded, or the subject-to-camera distance may be high. However, it has received revived attention during the pandemic due to masked faces, leaving the ocular region as the only visible facial area, even in controlled scenarios. This paper discusses the state-of-the-art of periocular biometrics, giving an overall framework of its most significant research aspects.
Is Style All You Need? Dependencies Between Emotion and GST-based Speaker Recognition
Nov 15, 2022In this work, we study the hypothesis that speaker identity embeddings extracted from speech samples may be used for detection and classification of emotion. In particular, we show that emotions can be effectively identified by learning speaker identities by use of a 1-D Triplet Convolutional Neural Network (CNN) & Global Style Token (GST) scheme (e.g., DeepTalk Network) and reusing the trained speaker recognition model weights to generate features in the emotion classification domain. The automatic speaker recognition (ASR) network is trained with VoxCeleb1, VoxCeleb2, and Librispeech datasets with a triplet training loss function using speaker identity labels. Using an Support Vector Machine (SVM) classifier, we map speaker identity embeddings into discrete emotion categories from the CREMA-D, IEMOCAP, and MSP-Podcast datasets. On the task of speech emotion detection, we obtain 80.8% ACC with acted emotion samples from CREMA-D, 81.2% ACC with semi-natural emotion samples in IEMOCAP, and 66.9% ACC with natural emotion samples in MSP-Podcast. We also propose a novel two-stage hierarchical classifier (HC) approach which demonstrates +2% ACC improvement on CREMA-D emotion samples. Through this work, we seek to convey the importance of holistically modeling intra-user variation within audio samples
Can GAN-induced Attribute Manipulations Impact Face Recognition?
Sep 07, 2022
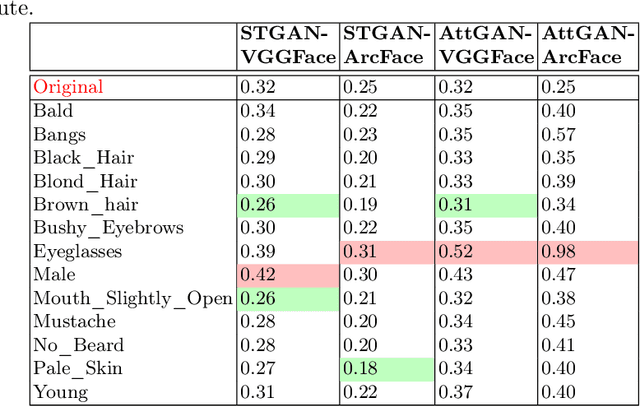
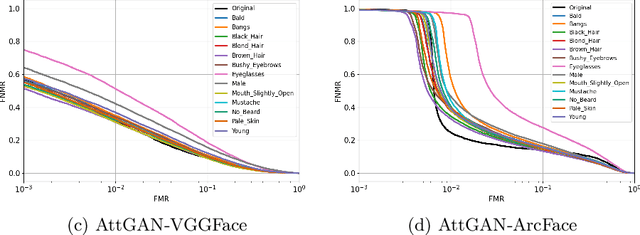
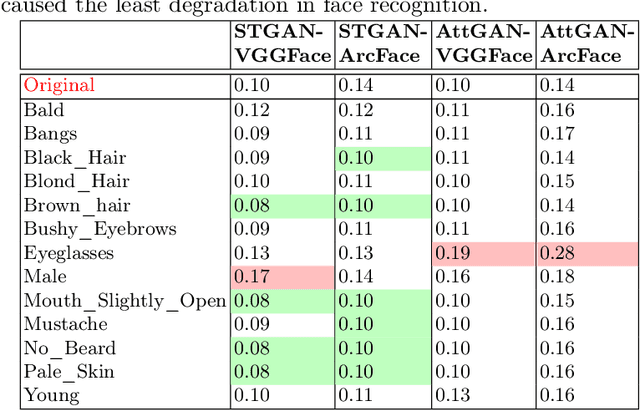
Impact due to demographic factors such as age, sex, race, etc., has been studied extensively in automated face recognition systems. However, the impact of \textit{digitally modified} demographic and facial attributes on face recognition is relatively under-explored. In this work, we study the effect of attribute manipulations induced via generative adversarial networks (GANs) on face recognition performance. We conduct experiments on the CelebA dataset by intentionally modifying thirteen attributes using AttGAN and STGAN and evaluating their impact on two deep learning-based face verification methods, ArcFace and VGGFace. Our findings indicate that some attribute manipulations involving eyeglasses and digital alteration of sex cues can significantly impair face recognition by up to 73% and need further analysis.
Facial De-morphing: Extracting Component Faces from a Single Morph
Sep 07, 2022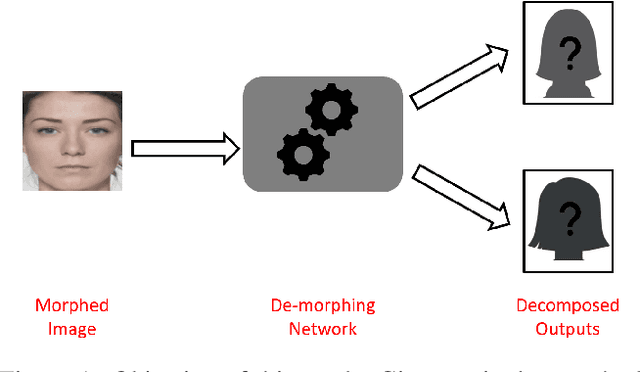
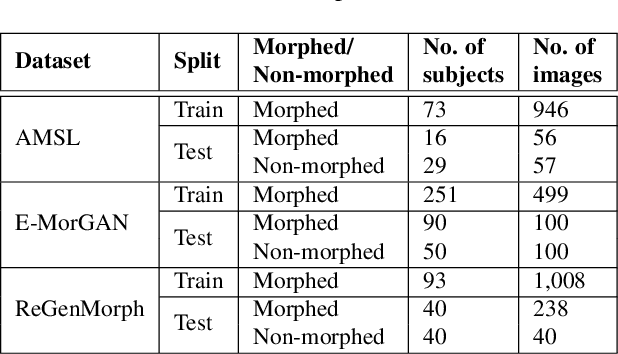
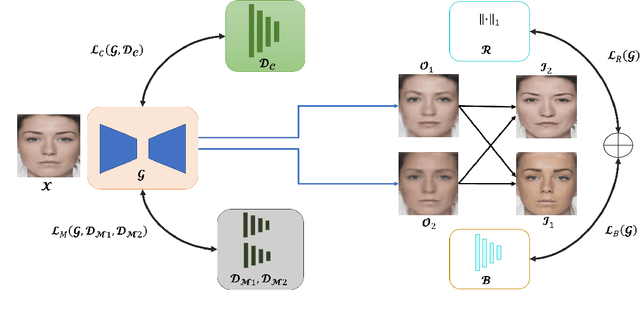
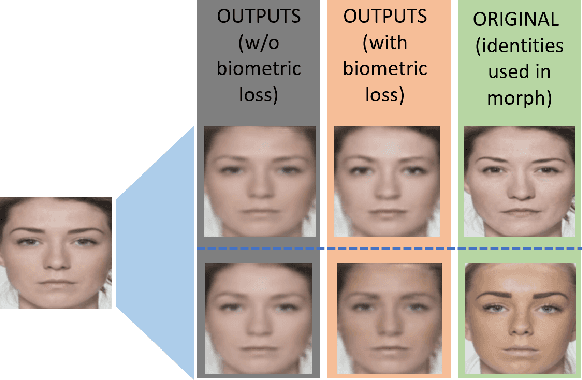
A face morph is created by strategically combining two or more face images corresponding to multiple identities. The intention is for the morphed image to match with multiple identities. Current morph attack detection strategies can detect morphs but cannot recover the images or identities used in creating them. The task of deducing the individual face images from a morphed face image is known as \textit{de-morphing}. Existing work in de-morphing assume the availability of a reference image pertaining to one identity in order to recover the image of the accomplice - i.e., the other identity. In this work, we propose a novel de-morphing method that can recover images of both identities simultaneously from a single morphed face image without needing a reference image or prior information about the morphing process. We propose a generative adversarial network that achieves single image-based de-morphing with a surprisingly high degree of visual realism and biometric similarity with the original face images. We demonstrate the performance of our method on landmark-based morphs and generative model-based morphs with promising results.