 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias Mitigated Learning from Differentially Private Synthetic Data: A Cautionary Tale
Aug 24, 2021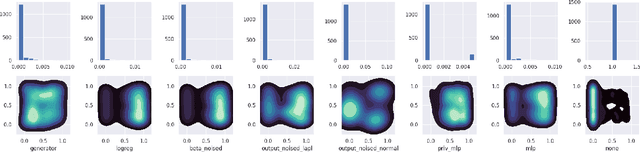
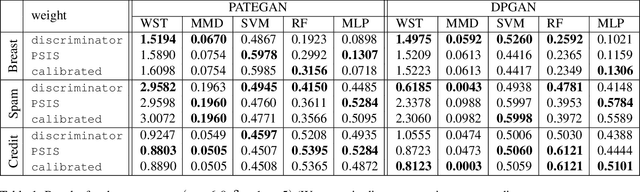
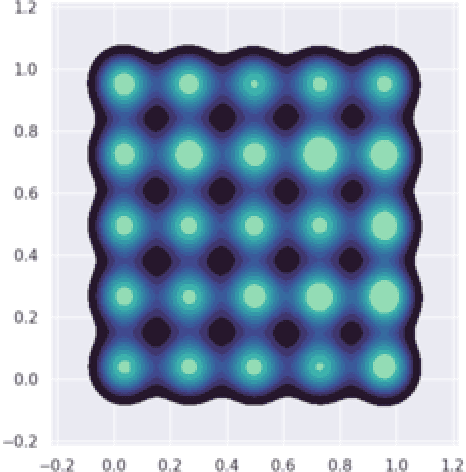
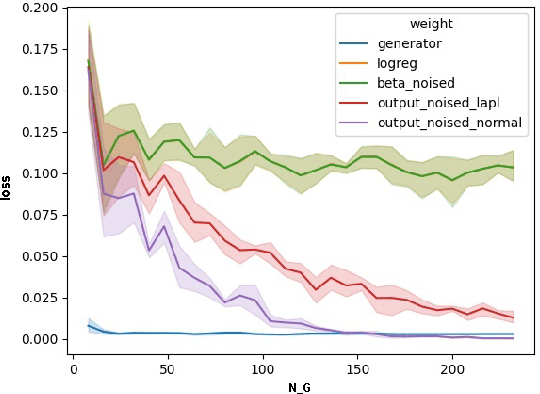
Increasing interest in privacy-preserving machine learning has led to new models for synthetic private data generation from undisclosed real data. However, mechanisms of privacy preservation introduce artifacts in the resulting synthetic data that have a significant impact on downstream tasks such as learning predictive models or inference. In particular, bias can affect all analyses as the synthetic data distribution is an inconsistent estimate of the real-data distribution. We propose several bias mitigation strategies using privatized likelihood ratios that have general applicability to differentially private synthetic data generative models. Through large-scale empirical evaluation, we show that bias mitigation provides simple and effective privacy-compliant augmentation for general applications of synthetic data. However, the work highlights that even after bias correction significant challenges remain on the usefulness of synthetic private data generators for tasks such as prediction and inference.
Quantitative Uniform Stability of the Iterative Proportional Fitting Procedure
Aug 18, 2021We establish the uniform in time stability, w.r.t. the marginals, of the Iterative Proportional Fitting Procedure, also known as Sinkhorn algorithm, used to solve entropy-regularised Optimal Transport problems. Our result is quantitative and stated in terms of the 1-Wasserstein metric. As a corollary we establish a quantitative stability result for Schr\"odinger bridges.
Monte Carlo Variational Auto-Encoders
Jun 30, 2021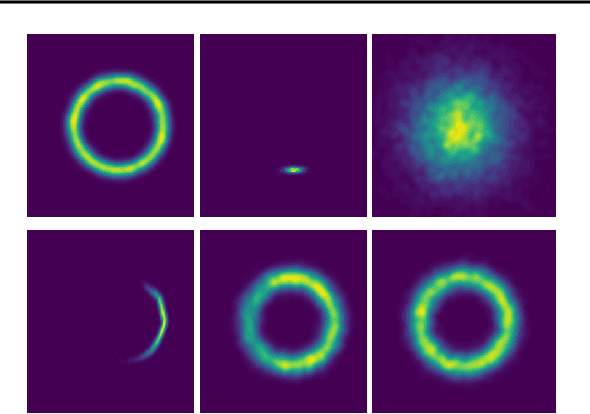
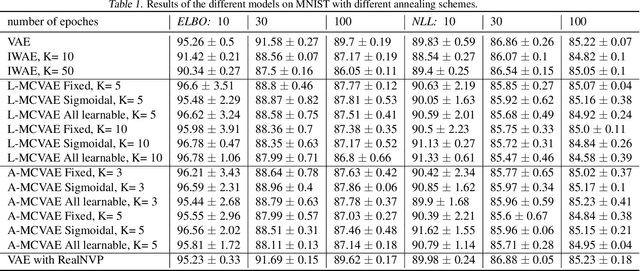
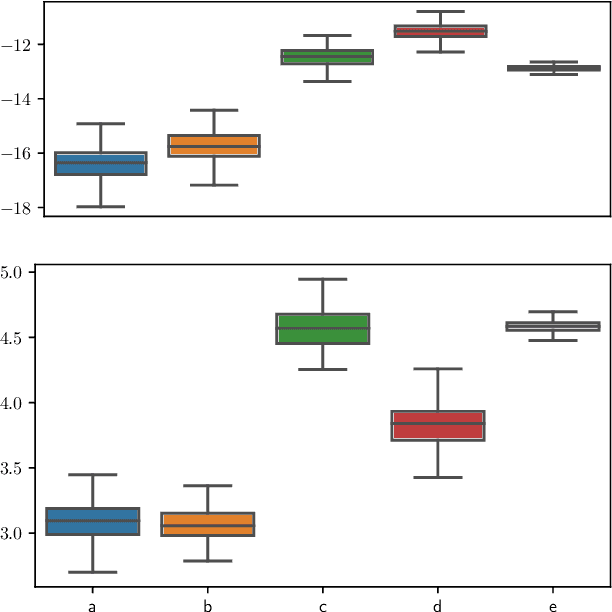
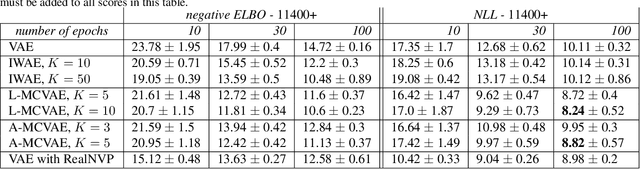
Variational auto-encoders (VAE) are popular deep latent variable models which are trained by maximizing an Evidence Lower Bound (ELBO). To obtain tighter ELBO and hence better variational approximations, it has been proposed to use importance sampling to get a lower variance estimate of the evidence. However, importance sampling is known to perform poorly in high dimensions. While it has been suggested many times in the literature to use more sophisticated algorithms such as Annealed Importance Sampling (AIS) and its Sequential Importance Sampling (SIS) extensions, the potential benefits brought by these advanced techniques have never been realized for VAE: the AIS estimate cannot be easily differentiated, while SIS requires the specification of carefully chosen backward Markov kernels. In this paper, we address both issues and demonstrate the performance of the resulting Monte Carlo VAEs on a variety of applications.
Wide stochastic networks: Gaussian limit and PAC-Bayesian training
Jun 17, 2021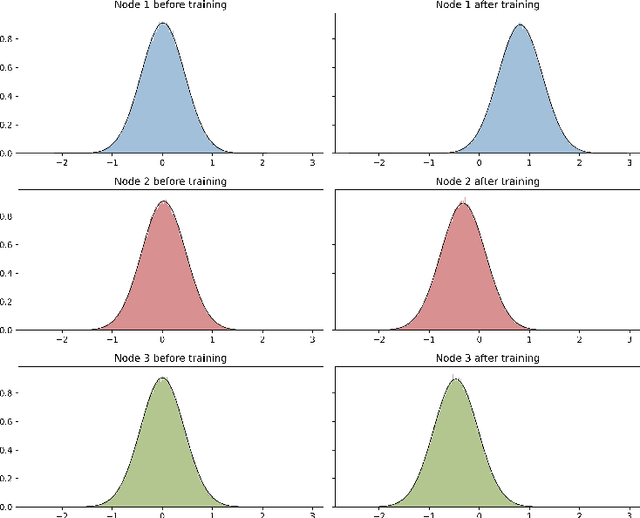
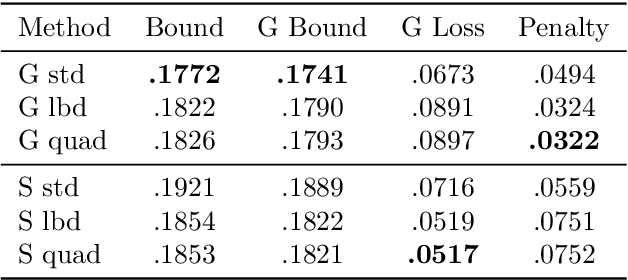
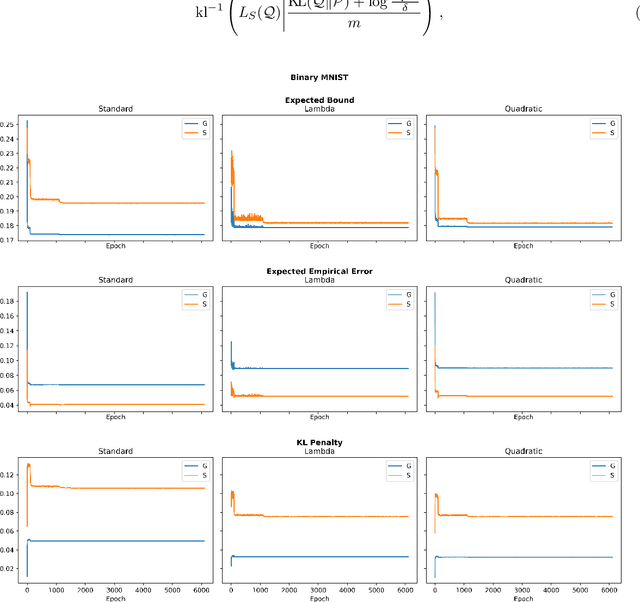
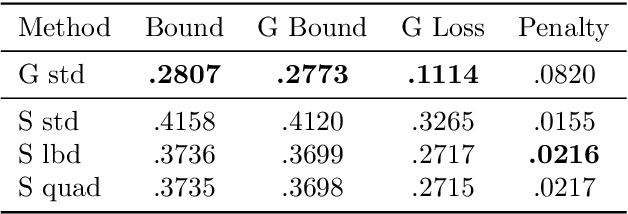
The limit of infinite width allows for substantial simplifications in the analytical study of overparameterized neural networks. With a suitable random initialization, an extremely large network is well approximated by a Gaussian process, both before and during training. In the present work, we establish a similar result for a simple stochastic architecture whose parameters are random variables. The explicit evaluation of the output distribution allows for a PAC-Bayesian training procedure that directly optimizes the generalization bound. For a large but finite-width network, we show empirically on MNIST that this training approach can outperform standard PAC-Bayesian methods.
Diffusion Schrödinger Bridge with Applications to Score-Based Generative Modeling
Jun 16, 2021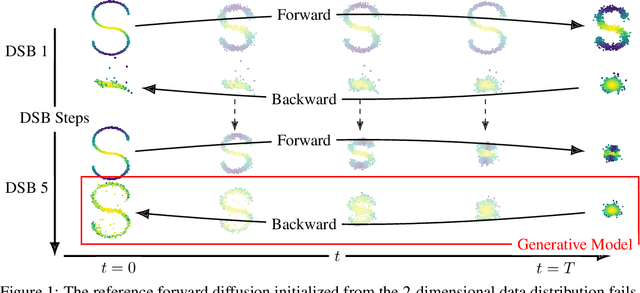
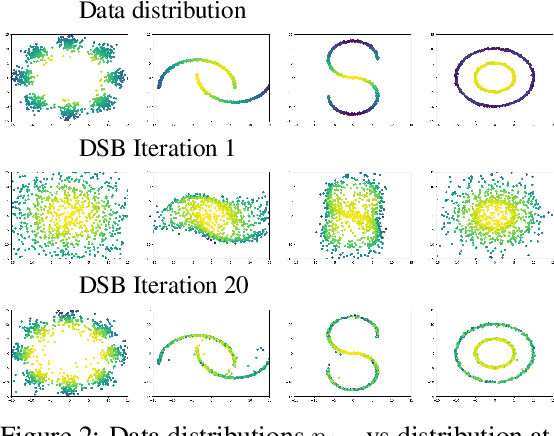
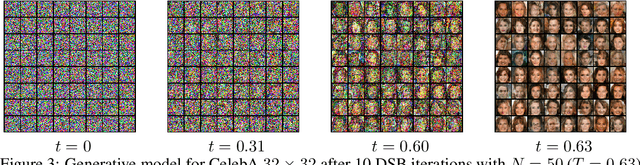
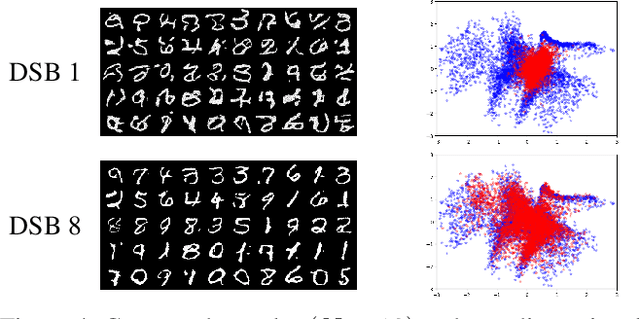
Progressively applying Gaussian noise transforms complex data distributions to approximately Gaussian. Reversing this dynamic defines a generative model. When the forward noising process is given by a Stochastic Differential Equation (SDE), Song et al. (2021) demonstrate how the time inhomogeneous drift of the associated reverse-time SDE may be estimated using score-matching. A limitation of this approach is that the forward-time SDE must be run for a sufficiently long time for the final distribution to be approximately Gaussian. In contrast, solving the Schr\"odinger Bridge problem (SB), i.e. an entropy-regularized optimal transport problem on path spaces, yields diffusions which generate samples from the data distribution in finite time. We present Diffusion SB (DSB), an original approximation of the Iterative Proportional Fitting (IPF) procedure to solve the SB problem, and provide theoretical analysis along with generative modeling experiments. The first DSB iteration recovers the methodology proposed by Song et al. (2021), with the flexibility of using shorter time intervals, as subsequent DSB iterations reduce the discrepancy between the final-time marginal of the forward (resp. backward) SDE with respect to the prior (resp. data) distribution. Beyond generative modeling, DSB offers a widely applicable computational optimal transport tool as the continuous state-space analogue of the popular Sinkhorn algorithm (Cuturi, 2013).
On Instrumental Variable Regression for Deep Offline Policy Evaluation
May 21, 2021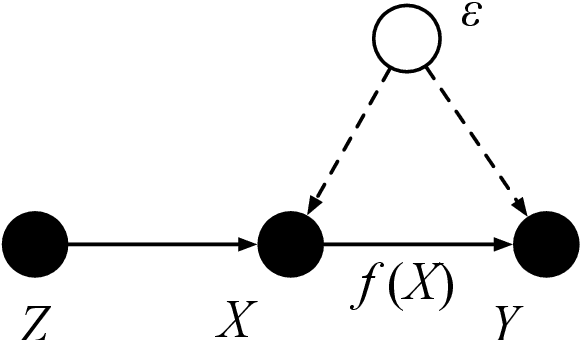
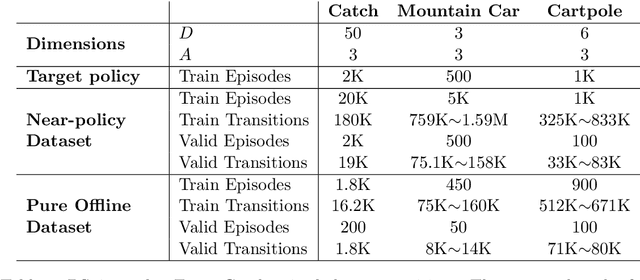
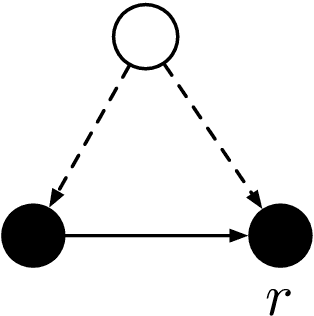
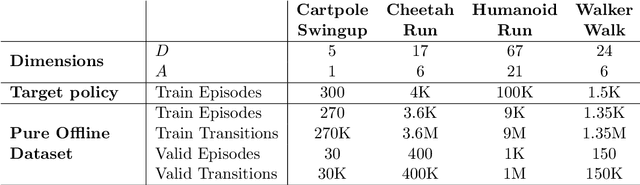
We show that the popular reinforcement learning (RL) strategy of estimating the state-action value (Q-function) by minimizing the mean squared Bellman error leads to a regression problem with confounding, the inputs and output noise being correlated. Hence, direct minimization of the Bellman error can result in significantly biased Q-function estimates. We explain why fixing the target Q-network in Deep Q-Networks and Fitted Q Evaluation provides a way of overcoming this confounding, thus shedding new light on this popular but not well understood trick in the deep RL literature. An alternative approach to address confounding is to leverage techniques developed in the causality literature, notably instrumental variables (IV). We bring together here the literature on IV and RL by investigating whether IV approaches can lead to improved Q-function estimates. This paper analyzes and compares a wide range of recent IV methods in the context of offline policy evaluation (OPE), where the goal is to estimate the value of a policy using logged data only. By applying different IV techniques to OPE, we are not only able to recover previously proposed OPE methods such as model-based techniques but also to obtain competitive new techniques. We find empirically that state-of-the-art OPE methods are closely matched in performance by some IV methods such as AGMM, which were not developed for OPE. We open-source all our code and datasets at https://github.com/liyuan9988/IVOPEwithACME.
Invertible Flow Non Equilibrium sampling
Mar 17, 2021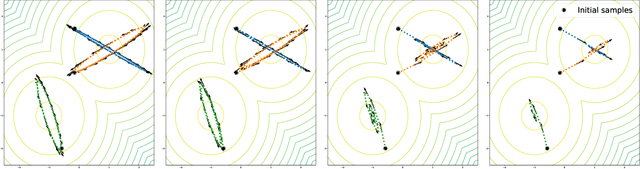
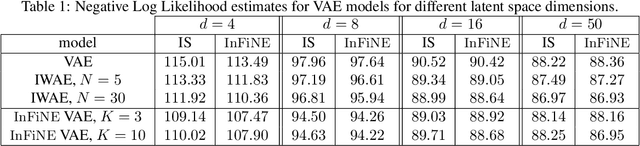
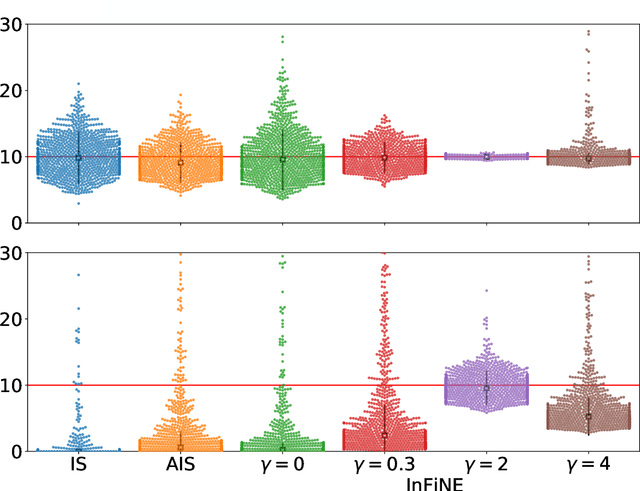
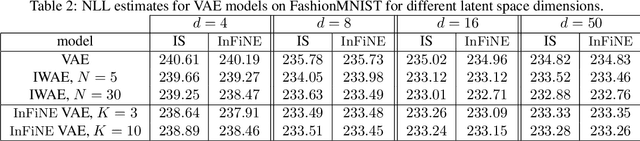
Simultaneously sampling from a complex distribution with intractable normalizing constant and approximating expectations under this distribution is a notoriously challenging problem. We introduce a novel scheme, Invertible Flow Non Equilibrium Sampling (InFine), which departs from classical Sequential Monte Carlo (SMC) and Markov chain Monte Carlo (MCMC) approaches. InFine constructs unbiased estimators of expectations and in particular of normalizing constants by combining the orbits of a deterministic transform started from random initializations.When this transform is chosen as an appropriate integrator of a conformal Hamiltonian system, these orbits are optimization paths. InFine is also naturally suited to design new MCMC sampling schemes by selecting samples on the optimization paths.Additionally, InFine can be used to construct an Evidence Lower Bound (ELBO) leading to a new class of Variational AutoEncoders (VAE).
COIN: COmpression with Implicit Neural representations
Mar 03, 2021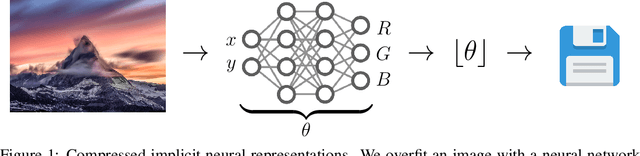
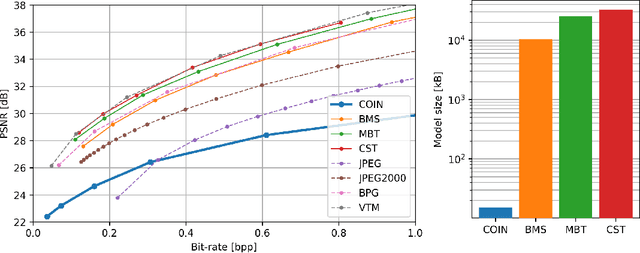
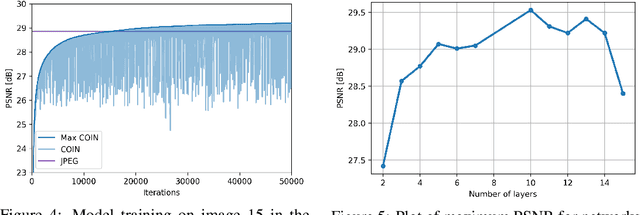
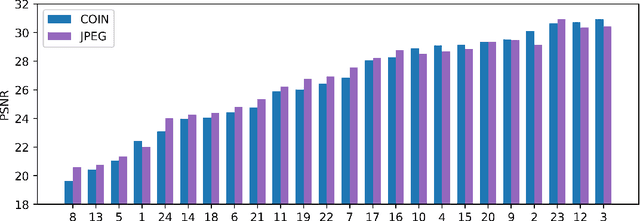
We propose a new simple approach for image compression: instead of storing the RGB values for each pixel of an image, we store the weights of a neural network overfitted to the image. Specifically, to encode an image, we fit it with an MLP which maps pixel locations to RGB values. We then quantize and store the weights of this MLP as a code for the image. To decode the image, we simply evaluate the MLP at every pixel location. We found that this simple approach outperforms JPEG at low bit-rates, even without entropy coding or learning a distribution over weights. While our framework is not yet competitive with state of the art compression methods, we show that it has various attractive properties which could make it a viable alternative to other neural data compression approaches.
Improving Lossless Compression Rates via Monte Carlo Bits-Back Coding
Feb 22, 2021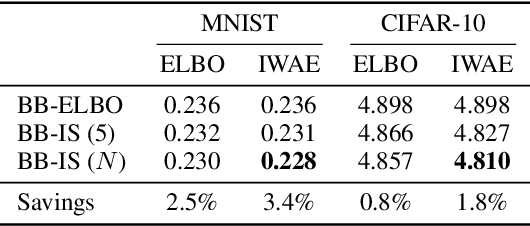
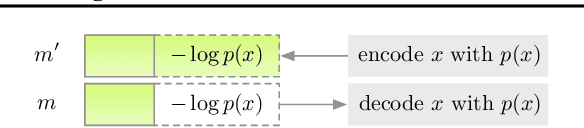
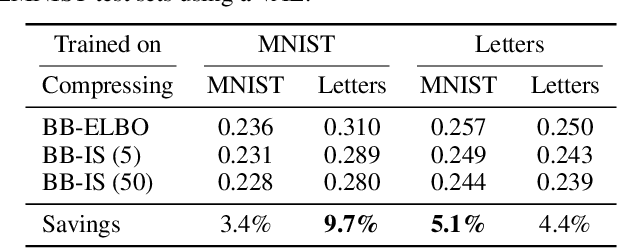
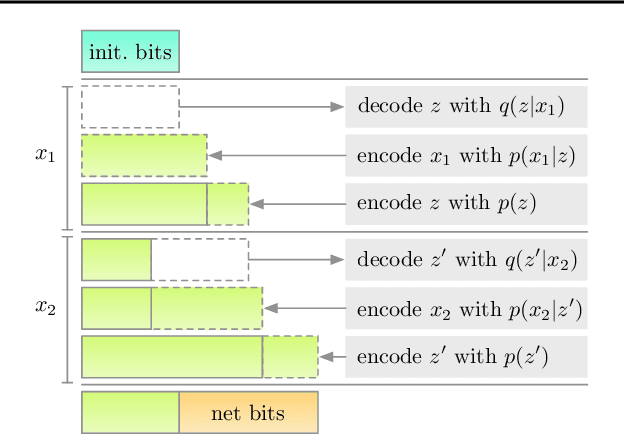
Latent variable models have been successfully applied in lossless compression with the bits-back coding algorithm. However, bits-back suffers from an increase in the bitrate equal to the KL divergence between the approximate posterior and the true posterior. In this paper, we show how to remove this gap asymptotically by deriving bits-back coding algorithms from tighter variational bounds. The key idea is to exploit extended space representations of Monte Carlo estimators of the marginal likelihood. Naively applied, our schemes would require more initial bits than the standard bits-back coder, but we show how to drastically reduce this additional cost with couplings in the latent space. When parallel architectures can be exploited, our coders can achieve better rates than bits-back with little additional cost. We demonstrate improved lossless compression rates in a variety of settings, including entropy coding for lossy compression.
Differentiable Particle Filtering via Entropy-Regularized Optimal Transport
Feb 15, 2021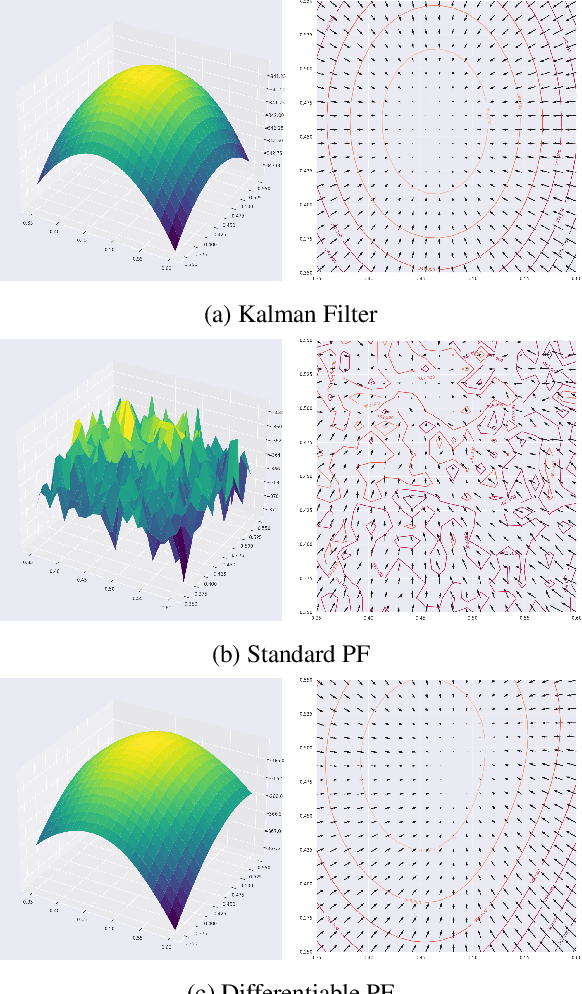
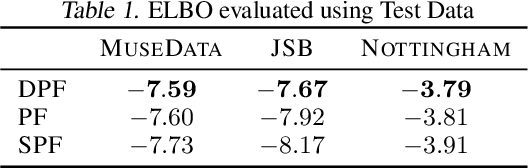
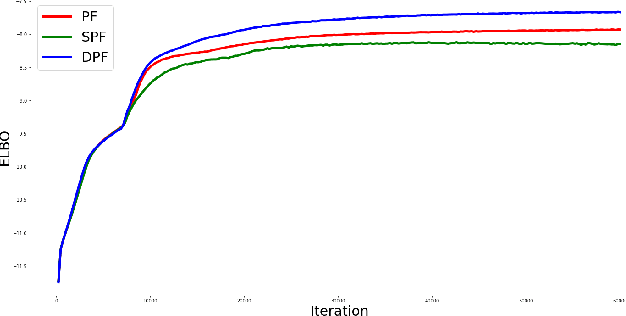
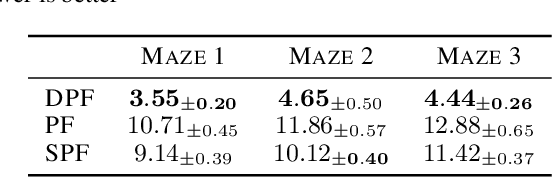
Particle Filtering (PF) methods are an established class of procedures for performing inference in non-linear state-space models. Resampling is a key ingredient of PF, necessary to obtain low variance likelihood and states estimates. However, traditional resampling methods result in PF-based loss functions being non-differentiable with respect to model and PF parameters. In a variational inference context, resampling also yields high variance gradient estimates of the PF-based evidence lower bound. By leveraging optimal transport ideas, we introduce a principled differentiable particle filter and provide convergence results. We demonstrate this novel method on a variety of applications.