 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruning Convolutional Neural Networks with Self-Supervision
Jan 10, 2020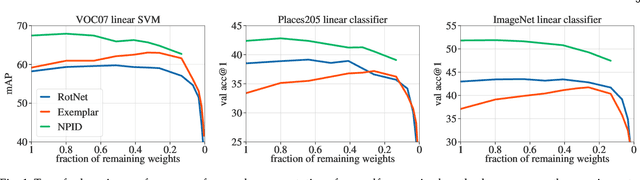
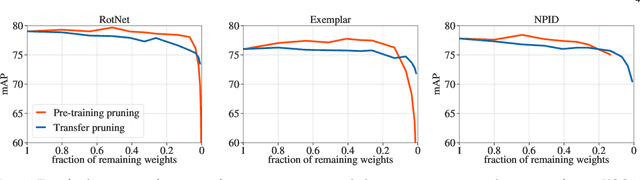
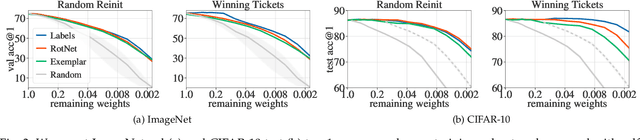
Convolutional neural networks trained without supervision come close to matching performance with supervised pre-training, but sometimes at the cost of an even higher number of parameters. Extracting subnetworks from these large unsupervised convnets with preserved performance is of particular interest to make them less computationally intensive. Typical pruning methods operate during training on a task while trying to maintain the performance of the pruned network on the same task. However, in self-supervised feature learning, the training objective is agnostic on the representation transferability to downstream tasks. Thus, preserving performance for this objective does not ensure that the pruned subnetwork remains effective for solving downstream tasks. In this work, we investigate the use of standard pruning methods, developed primarily for supervised learning, for networks trained without labels (i.e. on self-supervised tasks). We show that pruned masks obtained with or without labels reach comparable performance when re-trained on labels, suggesting that pruning operates similarly for self-supervised and supervised learning. Interestingly, we also find that pruning preserves the transfer performance of self-supervised subnetwork representations.
Libri-Light: A Benchmark for ASR with Limited or No Supervision
Dec 17, 2019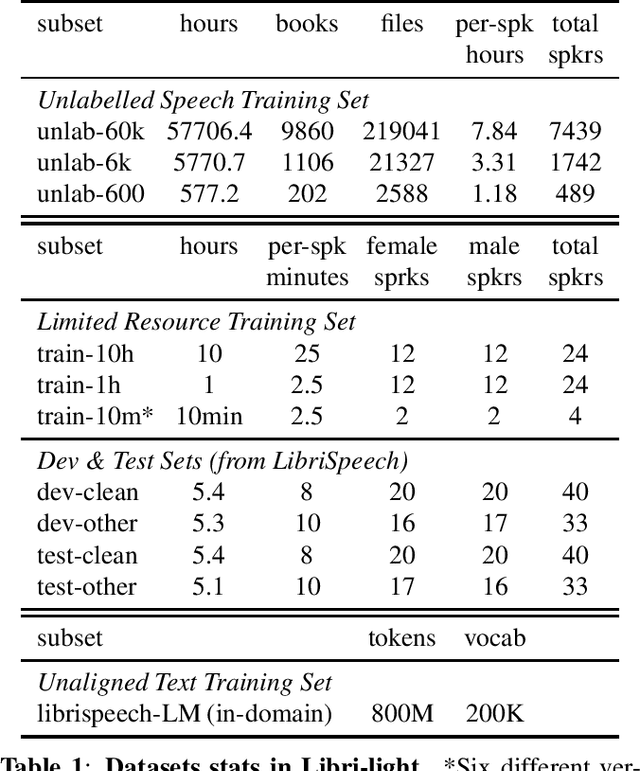
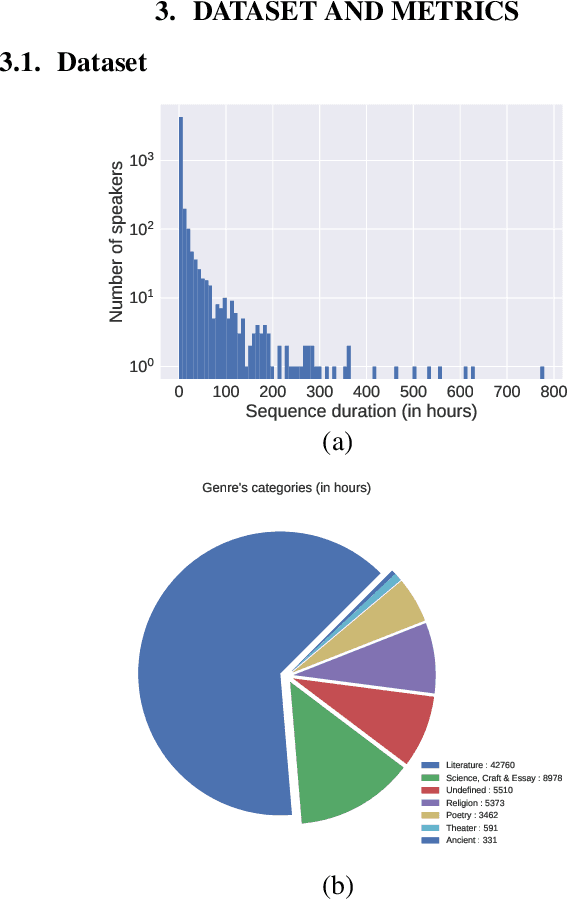
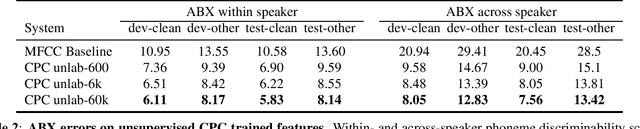
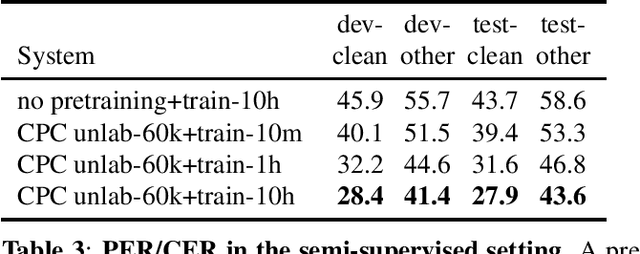
We introduce a new collection of spoken English audio suitable for training speech recognition systems under limited or no supervision. It is derived from open-source audio books from the LibriVox project. It contains over 60K hours of audio, which is, to our knowledge, the largest freely-available corpus of speech. The audio has been segmented using voice activity detection and is tagged with SNR, speaker ID and genre descriptions. Additionally, we provide baseline systems and evaluation metrics working under three settings: (1) the zero resource/unsupervised setting (ABX), (2) the semi-supervised setting (PER, CER) and (3) the distant supervision setting (WER). Settings (2) and (3) use limited textual resources (10 minutes to 10 hours) aligned with the speech. Setting (3) uses large amounts of unaligned text. They are evaluated on the standard LibriSpeech dev and test sets for comparison with the supervised state-of-the-art.
CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data
Nov 15, 2019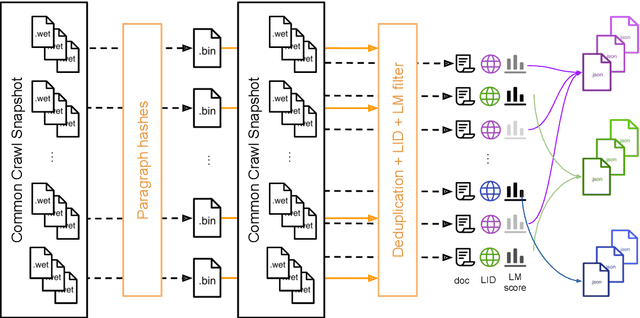
Pre-training text representations have led to significant improvements in many areas of natural language processing. The quality of these models benefits greatly from the size of the pretraining corpora as long as its quality is preserved. In this paper, we describe an automatic pipeline to extract massive high-quality monolingual datasets from Common Crawl for a variety of languages. Our pipeline follows the data processing introduced in fastText (Mikolov et al., 2017; Grave et al., 2018), that deduplicates documents and identifies their language. We augment this pipeline with a filtering step to select documents that are close to high quality corpora like Wikipedia.
CCMatrix: Mining Billions of High-Quality Parallel Sentences on the WEB
Nov 10, 2019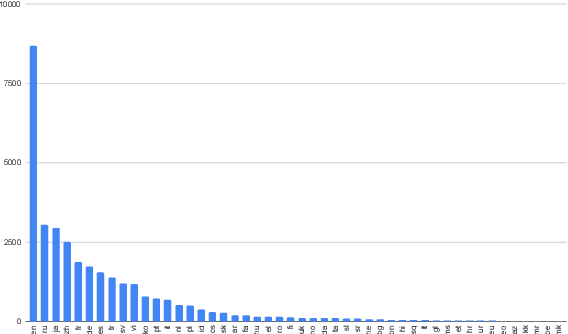
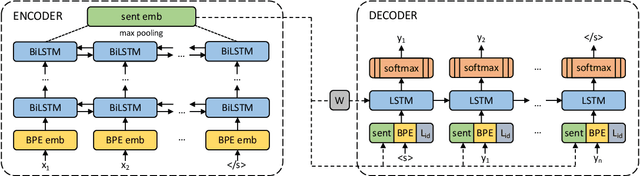
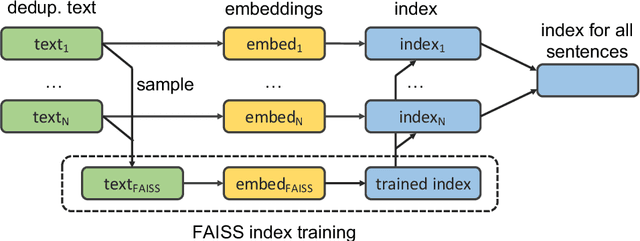
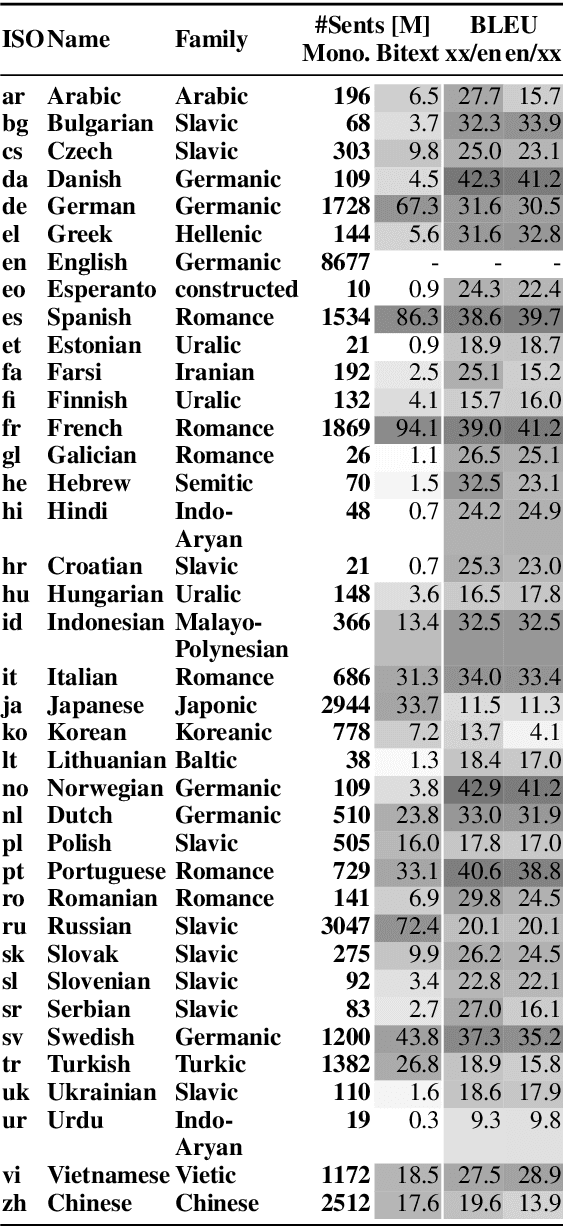
We show that margin-based bitext mining in a multilingual sentence space can be applied to monolingual corpora of billions of sentences. We are using ten snapshots of a curated common crawl corpus (Wenzek et al., 2019) totaling 32.7 billion unique sentences. Using one unified approach for 38 languages, we were able to mine 3.5 billions parallel sentences, out of which 661 million are aligned with English. 17 language pairs have more then 30 million parallel sentences, 82 more then 10 million, and most more than one million, including direct alignments between many European or Asian languages. To evaluate the quality of the mined bitexts, we train NMT systems for most of the language pairs and evaluate them on TED, WMT and WAT test sets. Using our mined bitexts only and no human translated parallel data, we achieve a new state-of-the-art for a single system on the WMT'19 test set for translation between English and German, Russian and Chinese, as well as German/French. In particular, our English/German system outperforms the best single one by close to 4 BLEU points and is almost on pair with best WMT'19 evaluation system which uses system combination and back-translation. We also achieve excellent results for distant languages pairs like Russian/Japanese, outperforming the best submission at the 2019 workshop on Asian Translation (WAT).
Updating Pre-trained Word Vectors and Text Classifiers using Monolingual Alignment
Oct 15, 2019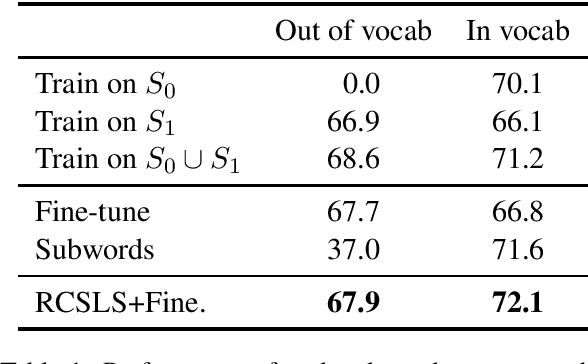
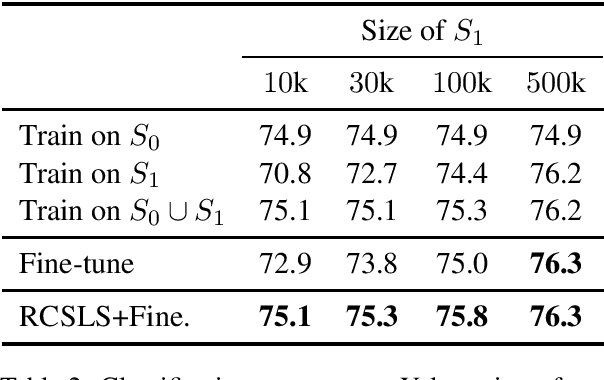
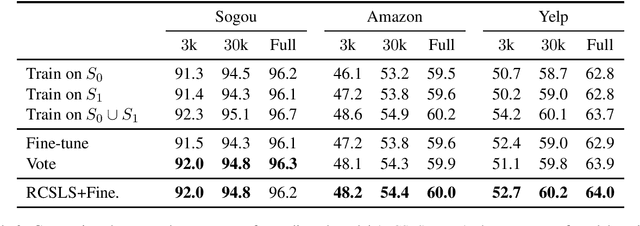
In this paper, we focus on the problem of adapting word vector-based models to new textual data. Given a model pre-trained on large reference data, how can we adapt it to a smaller piece of data with a slightly different language distribution? We frame the adaptation problem as a monolingual word vector alignment problem, and simply average models after alignment. We align vectors using the RCSLS criterion. Our formulation results in a simple and efficient algorithm that allows adapting general-purpose models to changing word distributions. In our evaluation, we consider applications to word embedding and text classification models. We show that the proposed approach yields good performance in all setups and outperforms a baseline consisting in fine-tuning the model on new data.
Reducing Transformer Depth on Demand with Structured Dropout
Sep 25, 2019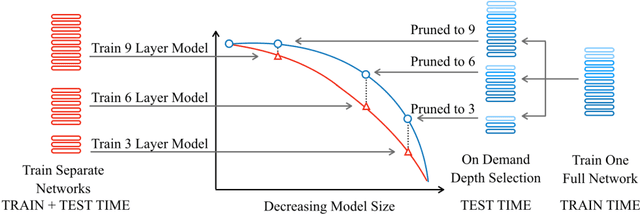
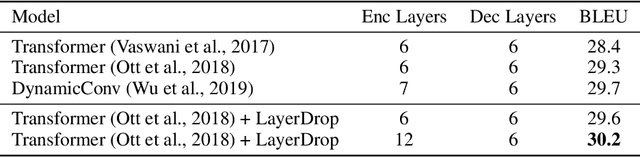

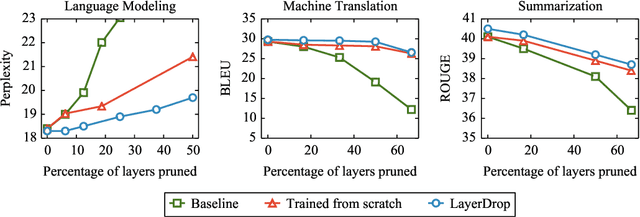
Overparameterized transformer networks have obtained state of the art results in various natural language processing tasks, such as machine translation, language modeling, and question answering. These models contain hundreds of millions of parameters, necessitating a large amount of computation and making them prone to overfitting. In this work, we explore LayerDrop, a form of structured dropout, which has a regularization effect during training and allows for efficient pruning at inference time. In particular, we show that it is possible to select sub-networks of any depth from one large network without having to finetune them and with limited impact on performance. We demonstrate the effectiveness of our approach by improving the state of the art on machine translation, language modeling, summarization, question answering, and language understanding benchmarks. Moreover, we show that our approach leads to small BERT-like models of higher quality compared to training from scratch or using distillation.
And the Bit Goes Down: Revisiting the Quantization of Neural Networks
Jul 29, 2019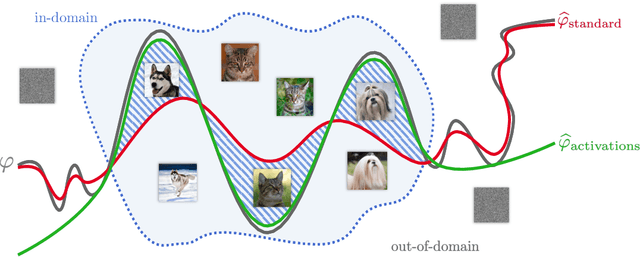
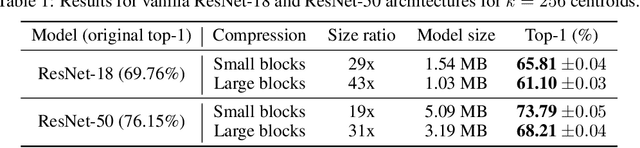
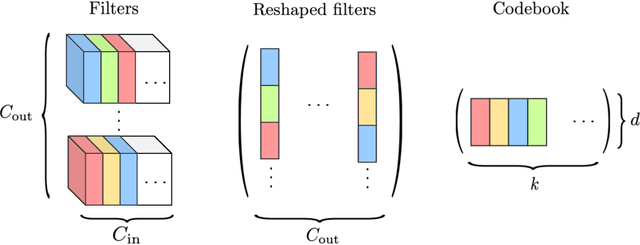

In this paper, we address the problem of reducing the memory footprint of ResNet-like convolutional network architectures. We introduce a vector quantization method that aims at preserving the quality of the reconstruction of the network outputs and not its weights. The advantage of our approach is that it minimizes the loss reconstruction error for in-domain inputs and does not require any labelled data. We also use byte-aligned codebooks to produce compressed networks with efficient inference on CPU. We validate our approach by quantizing a high performing ResNet-50 model to a memory size of 5 MB (20x compression factor) while preserving a top-1 accuracy of 76.1% on ImageNet object classification and by compressing a Mask R-CNN with a size budget around 6 MB.
Why Build an Assistant in Minecraft?
Jul 25, 2019In this document we describe a rationale for a research program aimed at building an open "assistant" in the game Minecraft, in order to make progress on the problems of natural language understanding and learning from dialogue.
Augmenting Self-attention with Persistent Memory
Jul 02, 2019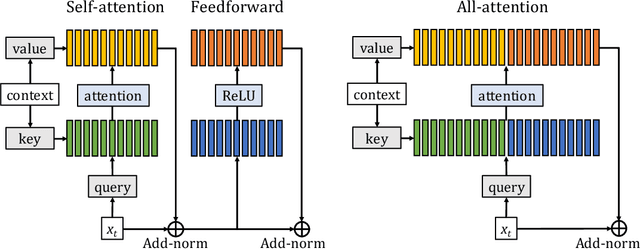
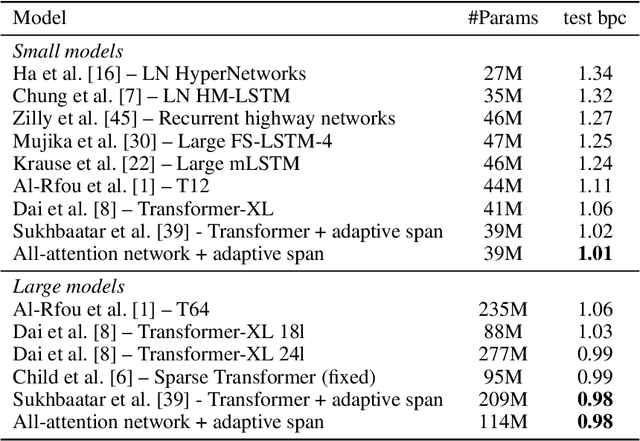

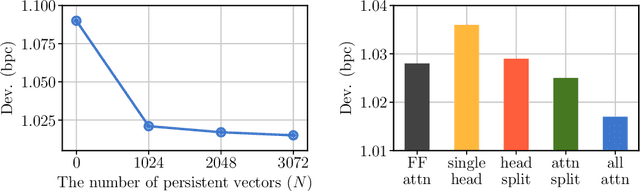
Transformer networks have lead to important progress in language modeling and machine translation. These models include two consecutive modules, a feed-forward layer and a self-attention layer. The latter allows the network to capture long term dependencies and are often regarded as the key ingredient in the success of Transformers. Building upon this intuition, we propose a new model that solely consists of attention layers. More precisely, we augment the self-attention layers with persistent memory vectors that play a similar role as the feed-forward layer. Thanks to these vectors, we can remove the feed-forward layer without degrading the performance of a transformer. Our evaluation shows the benefits brought by our model on standard character and word level language modeling benchmarks.
Adaptive Attention Span in Transformers
May 19, 2019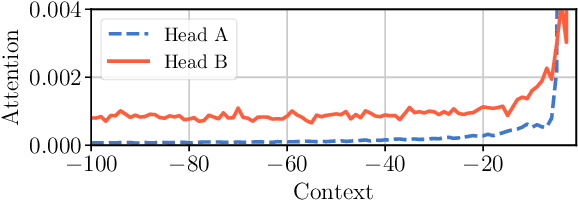
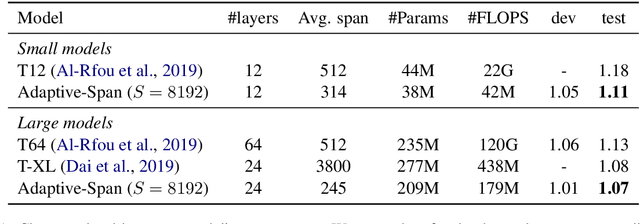
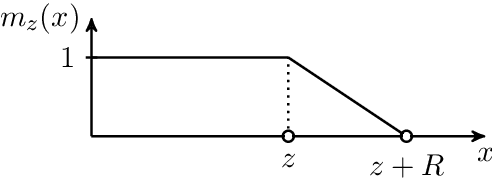
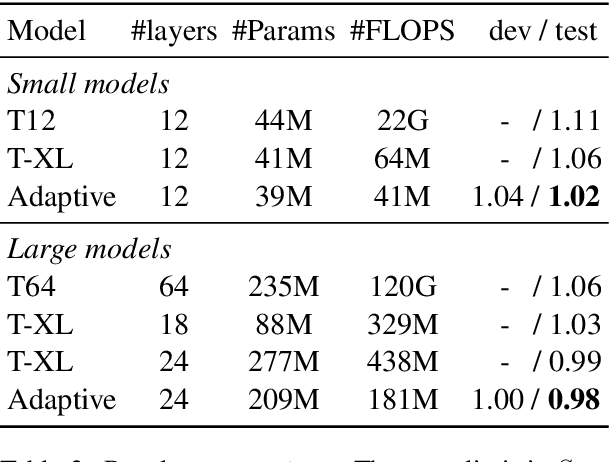
We propose a novel self-attention mechanism that can learn its optimal attention span. This allows us to extend significantly the maximum context size used in Transformer, while maintaining control over their memory footprint and computational time. We show the effectiveness of our approach on the task of character level language modeling, where we achieve state-of-the-art performances on text8 and enwiki8 by using a maximum context of 8k characters.