 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large Dataset for Improving Patch Matching
Apr 17, 2018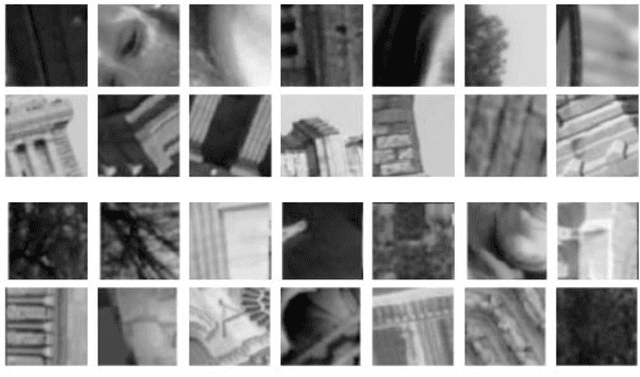
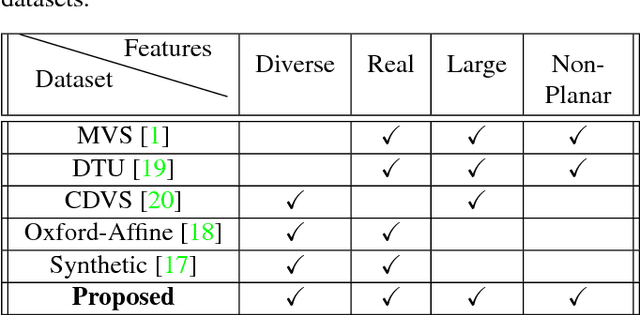

We propose a new dataset for learning local image descriptors which can be used for significantly improved patch matching. Our proposed dataset consists of an order of magnitude more number of scenes, images, and positive and negative correspondences compared to the currently available Multi-View Stereo (MVS) dataset from Brown et al. The new dataset also has better coverage of the overall viewpoint, scale, and lighting changes in comparison to the MVS dataset. Our dataset also provides supplementary information like RGB patches with scale and rotations values, and intrinsic and extrinsic camera parameters which as shown later can be used to customize training data as per application. We train an existing state-of-the-art model on our dataset and evaluate on publicly available benchmarks such as HPatches dataset and Strecha et al.\cite{strecha} to quantify the image descriptor performance. Experimental evaluations show that the descriptors trained using our proposed dataset outperform the current state-of-the-art descriptors trained on MVS by 8%, 4% and 10% on matching, verification and retrieval tasks respectively on the HPatches dataset. Similarly on the Strecha dataset, we see an improvement of 3-5% for the matching task in non-planar scenes.
Improved Descriptors for Patch Matching and Reconstruction
Aug 27, 2017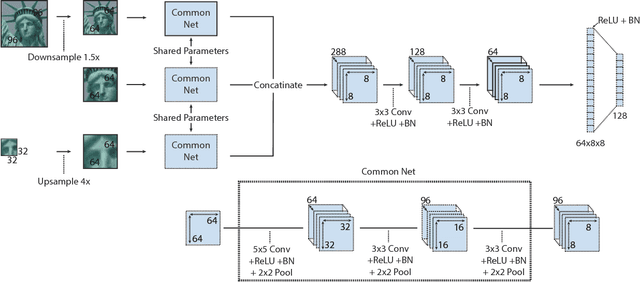
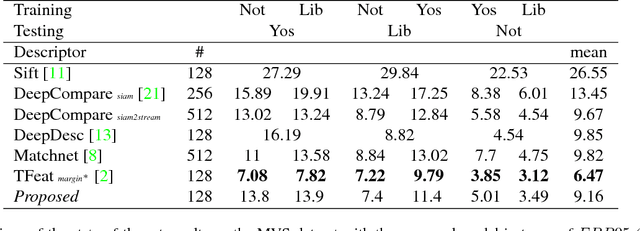
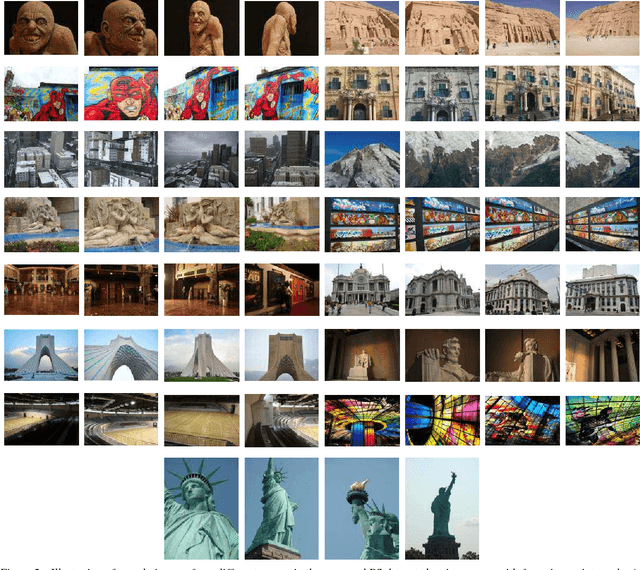
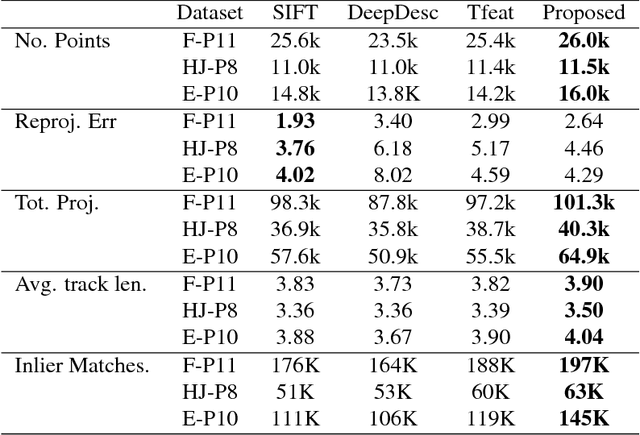
We propose a convolutional neural network (ConvNet) based approach for learning local image descriptors which can be used for significantly improved patch matching and 3D reconstructions. A multi-resolution ConvNet is used for learning keypoint descriptors. We also propose a new dataset consisting of an order of magnitude more number of scenes, images, and positive and negative correspondences compared to the currently available Multi-View Stereo (MVS) [18] dataset. The new dataset also has better coverage of the overall viewpoint, scale, and lighting changes in comparison to the MVS dataset. We evaluate our approach on publicly available datasets, such as Oxford Affine Covariant Regions Dataset (ACRD) [12], MVS [18], Synthetic [6] and Strecha [15] datasets to quantify the image descriptor performance. Scenes from the Oxford ACRD, MVS and Synthetic datasets are used for evaluating the patch matching performance of the learnt descriptors while the Strecha dataset is used to evaluate the 3D reconstruction task. Experiments show that the proposed descriptor outperforms the current state-of-the-art descriptors in both the evaluation tasks.
Theano: A Python framework for fast computation of mathematical expressions
May 09, 2016



Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.
Efficient Object Localization Using Convolutional Networks
Jun 09, 2015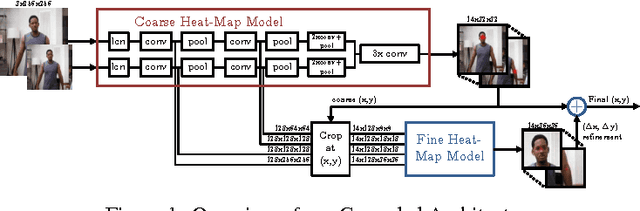
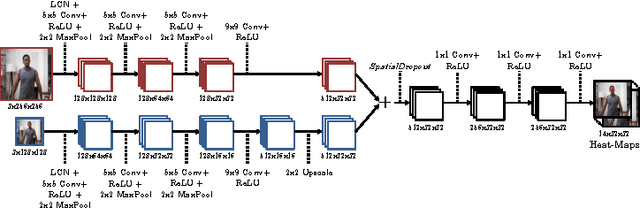
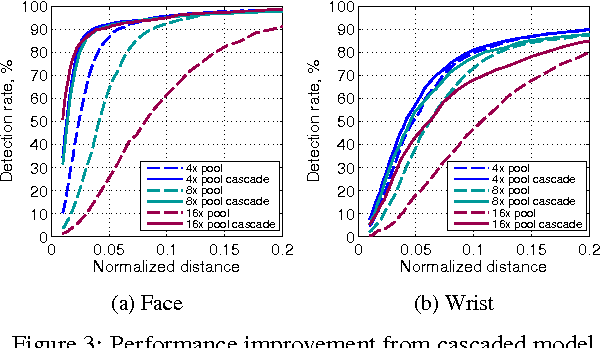
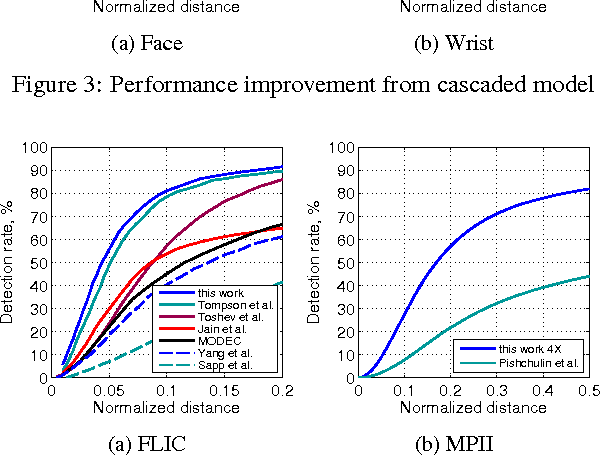
Recent state-of-the-art performance on human-body pose estimation has been achieved with Deep Convolutional Networks (ConvNets). Traditional ConvNet architectures include pooling and sub-sampling layers which reduce computational requirements, introduce invariance and prevent over-training. These benefits of pooling come at the cost of reduced localization accuracy. We introduce a novel architecture which includes an efficient `position refinement' model that is trained to estimate the joint offset location within a small region of the image. This refinement model is jointly trained in cascade with a state-of-the-art ConvNet model to achieve improved accuracy in human joint location estimation. We show that the variance of our detector approaches the variance of human annotations on the FLIC dataset and outperforms all existing approaches on the MPII-human-pose dataset.
MoDeep: A Deep Learning Framework Using Motion Features for Human Pose Estimation
Sep 28, 2014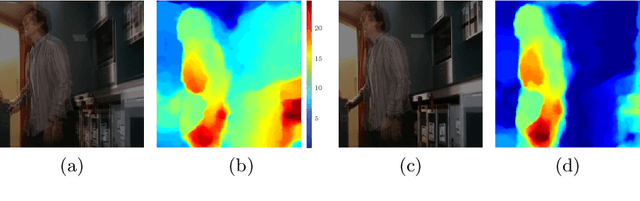
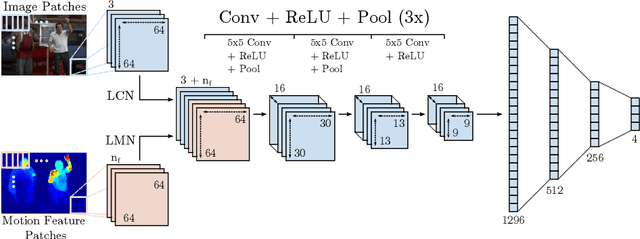
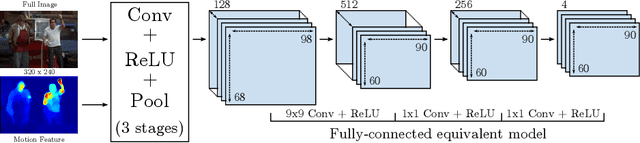
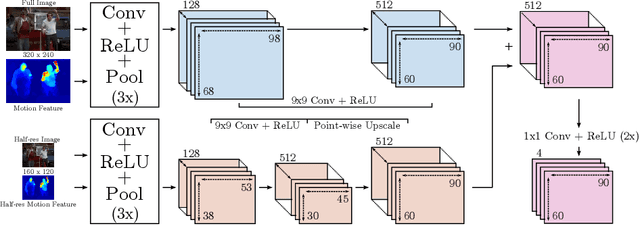
In this work, we propose a novel and efficient method for articulated human pose estimation in videos using a convolutional network architecture, which incorporates both color and motion features. We propose a new human body pose dataset, FLIC-motion, that extends the FLIC dataset with additional motion features. We apply our architecture to this dataset and report significantly better performance than current state-of-the-art pose detection systems.
Joint Training of a Convolutional Network and a Graphical Model for Human Pose Estimation
Sep 17, 2014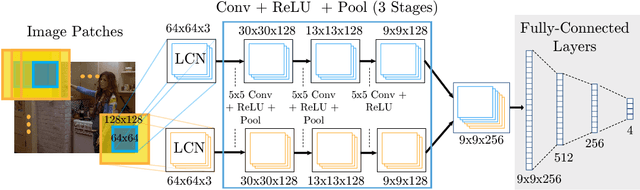
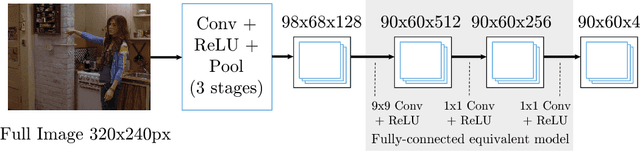
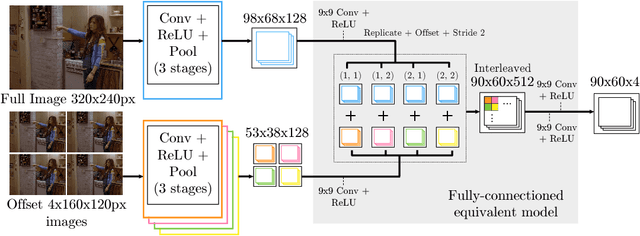
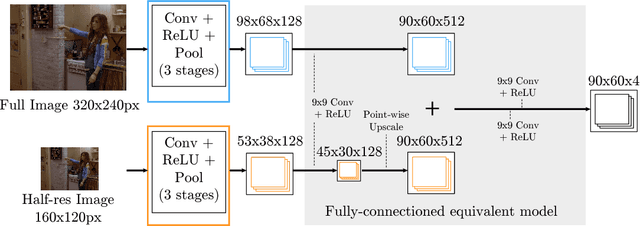
This paper proposes a new hybrid architecture that consists of a deep Convolutional Network and a Markov Random Field. We show how this architecture is successfully applied to the challenging problem of articulated human pose estimation in monocular images. The architecture can exploit structural domain constraints such as geometric relationships between body joint locations. We show that joint training of these two model paradigms improves performance and allows us to significantly outperform existing state-of-the-art techniques.
Learning Human Pose Estimation Features with Convolutional Networks
Apr 23, 2014
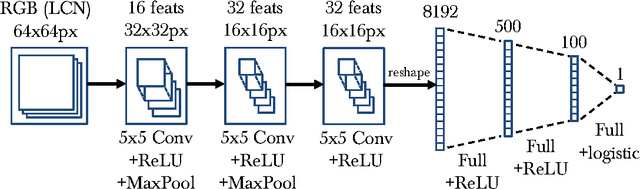
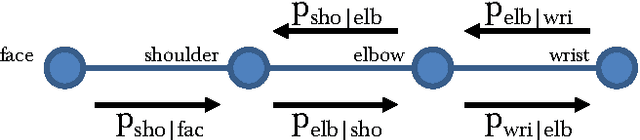
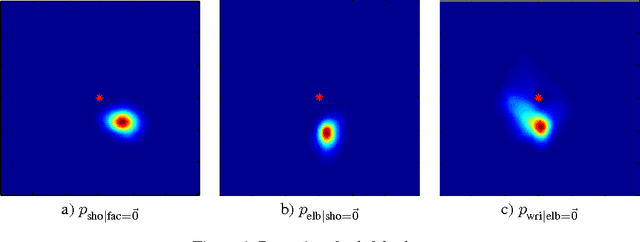
This paper introduces a new architecture for human pose estimation using a multi- layer convolutional network architecture and a modified learning technique that learns low-level features and higher-level weak spatial models. Unconstrained human pose estimation is one of the hardest problems in computer vision, and our new architecture and learning schema shows significant improvement over the current state-of-the-art results. The main contribution of this paper is showing, for the first time, that a specific variation of deep learning is able to outperform all existing traditional architectures on this task. The paper also discusses several lessons learned while researching alternatives, most notably, that it is possible to learn strong low-level feature detectors on features that might even just cover a few pixels in the image. Higher-level spatial models improve somewhat the overall result, but to a much lesser extent then expected. Many researchers previously argued that the kinematic structure and top-down information is crucial for this domain, but with our purely bottom up, and weak spatial model, we could improve other more complicated architectures that currently produce the best results. This mirrors what many other researchers, like those in the speech recognition, object recognition, and other domains have experienced.