 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWidth Transfer: On the variance of Width Optimization
Apr 24, 2021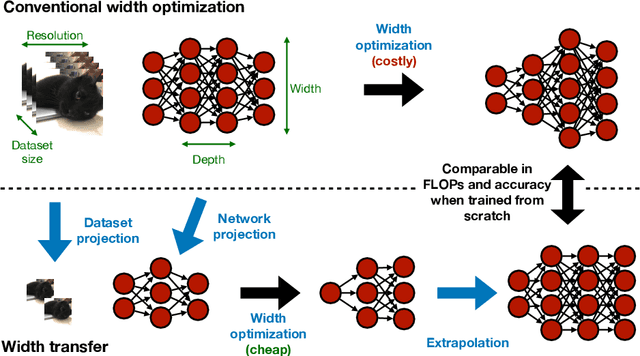

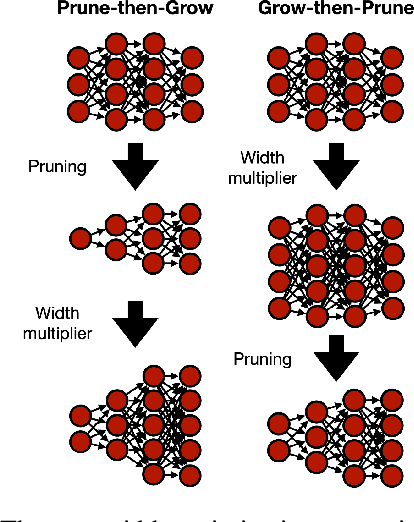
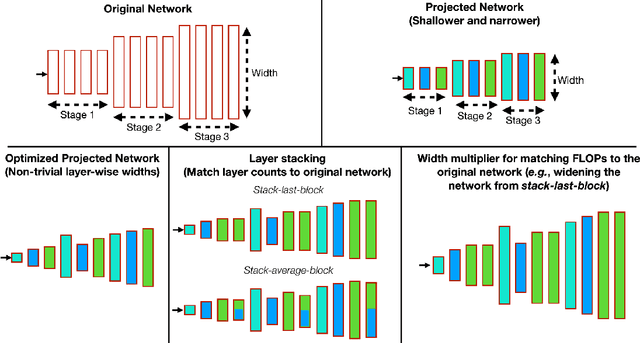
Optimizing the channel counts for different layers of a CNN has shown great promise in improving the efficiency of CNNs at test-time. However, these methods often introduce large computational overhead (e.g., an additional 2x FLOPs of standard training). Minimizing this overhead could therefore significantly speed up training. In this work, we propose width transfer, a technique that harnesses the assumptions that the optimized widths (or channel counts) are regular across sizes and depths. We show that width transfer works well across various width optimization algorithms and networks. Specifically, we can achieve up to 320x reduction in width optimization overhead without compromising the top-1 accuracy on ImageNet, making the additional cost of width optimization negligible relative to initial training. Our findings not only suggest an efficient way to conduct width optimization but also highlight that the widths that lead to better accuracy are invariant to various aspects of network architectures and training data.
Leveraging background augmentations to encourage semantic focus in self-supervised contrastive learning
Mar 23, 2021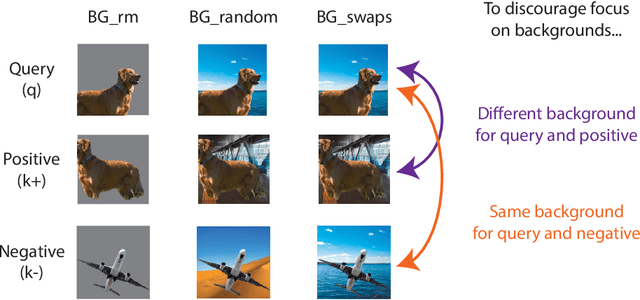
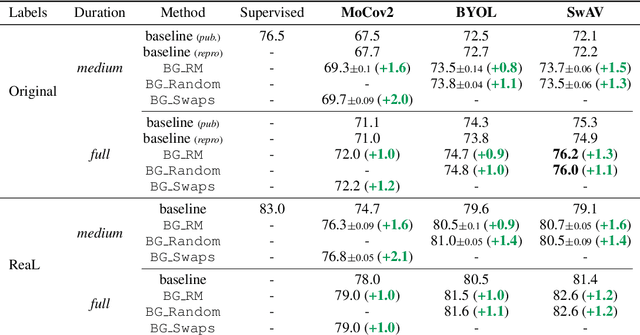
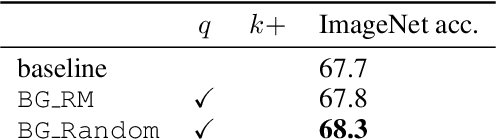
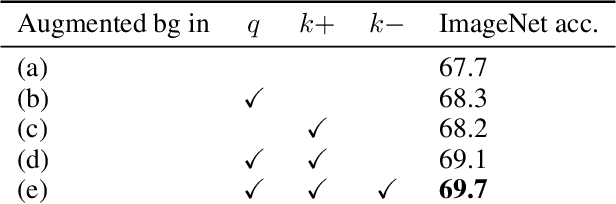
Unsupervised representation learning is an important challenge in computer vision, with self-supervised learning methods recently closing the gap to supervised representation learning. An important ingredient in high-performing self-supervised methods is the use of data augmentation by training models to place different augmented views of the same image nearby in embedding space. However, commonly used augmentation pipelines treat images holistically, disregarding the semantic relevance of parts of an image-e.g. a subject vs. a background-which can lead to the learning of spurious correlations. Our work addresses this problem by investigating a class of simple, yet highly effective "background augmentations", which encourage models to focus on semantically-relevant content by discouraging them from focusing on image backgrounds. Background augmentations lead to substantial improvements (+1-2% on ImageNet-1k) in performance across a spectrum of state-of-the art self-supervised methods (MoCov2, BYOL, SwAV) on a variety of tasks, allowing us to reach within 0.3% of supervised performance. We also demonstrate that background augmentations improve robustness to a number of out of distribution settings, including natural adversarial examples, the backgrounds challenge, adversarial attacks, and ReaL ImageNet.
Reservoir Transformer
Dec 30, 2020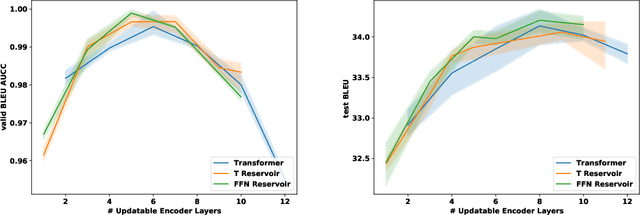
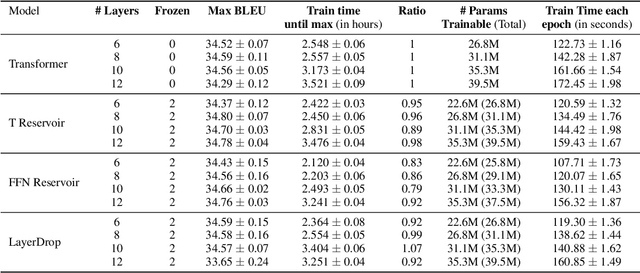
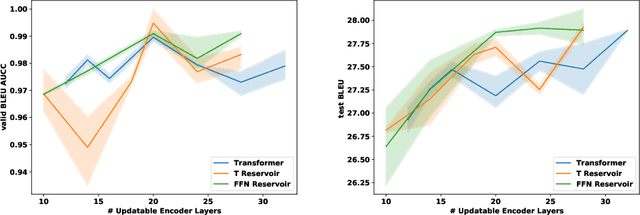
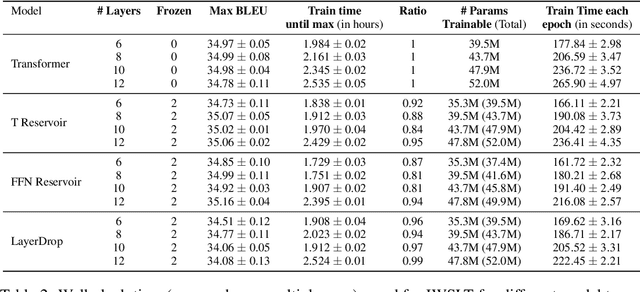
We demonstrate that transformers obtain impressive performance even when some of the layers are randomly initialized and never updated. Inspired by old and well-established ideas in machine learning, we explore a variety of non-linear "reservoir" layers interspersed with regular transformer layers, and show improvements in wall-clock compute time until convergence, as well as overall performance, on various machine translation and (masked) language modelling tasks.
Are all negatives created equal in contrastive instance discrimination?
Oct 25, 2020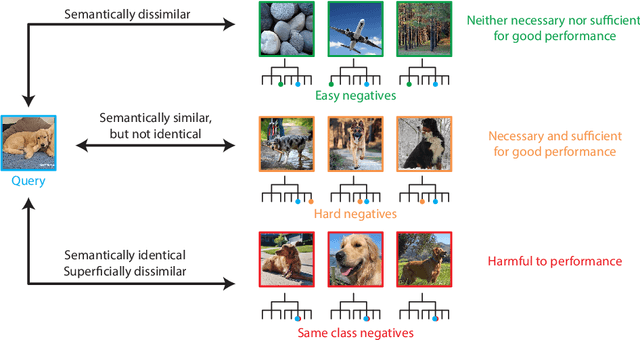
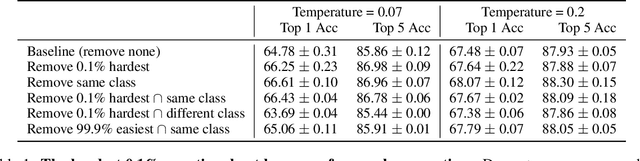
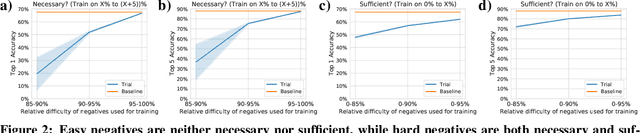
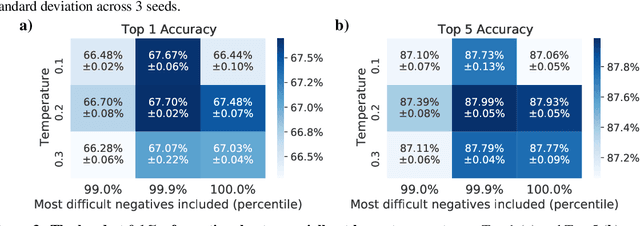
Self-supervised learning has recently begun to rival supervised learning on computer vision tasks. Many of the recent approaches have been based on contrastive instance discrimination (CID), in which the network is trained to recognize two augmented versions of the same instance (a query and positive) while discriminating against a pool of other instances (negatives). The learned representation is then used on downstream tasks such as image classification. Using methodology from MoCo v2 (Chen et al., 2020), we divided negatives by their difficulty for a given query and studied which difficulty ranges were most important for learning useful representations. We found a minority of negatives -- the hardest 5% -- were both necessary and sufficient for the downstream task to reach nearly full accuracy. Conversely, the easiest 95% of negatives were unnecessary and insufficient. Moreover, the very hardest 0.1% of negatives were unnecessary and sometimes detrimental. Finally, we studied the properties of negatives that affect their hardness, and found that hard negatives were more semantically similar to the query, and that some negatives were more consistently easy or hard than we would expect by chance. Together, our results indicate that negatives vary in importance and that CID may benefit from more intelligent negative treatment.
PareCO: Pareto-aware Channel Optimization for Slimmable Neural Networks
Jul 23, 2020
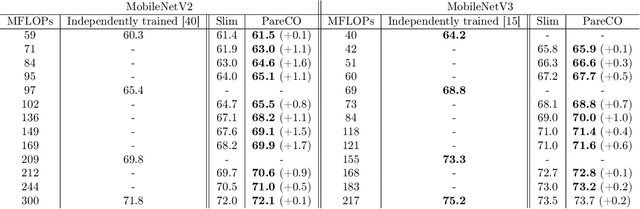

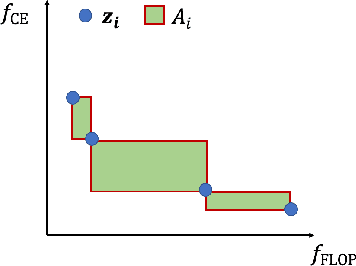
Slimmable neural networks provide a flexible trade-off front between prediction error and computational cost (such as the number of floating-point operations or FLOPs) with the same storage cost as a single model, have been proposed recently for resource-constrained settings such as mobile devices. However, current slimmable neural networks use a single width-multiplier for all the layers to arrive at sub-networks with different performance profiles, which neglects that different layers affect the network's prediction accuracy differently and have different FLOP requirements. Hence, developing a principled approach for deciding width-multipliers across different layers could potentially improve the performance of slimmable networks. To allow for heterogeneous width-multipliers across different layers, we formulate the problem of optimizing slimmable networks from a multi-objective optimization lens, which leads to a novel algorithm for optimizing both the shared weights and the width-multipliers for the sub-networks. We perform extensive empirical analysis with 14 network and dataset combinations and find that less over-parameterized networks benefit more from a joint channel and weight optimization than extremely over-parameterized networks. Quantitatively, improvements up to 1.7\% and 1\% in top-1 accuracy on the ImageNet dataset can be attained for MobileNetV2 and MobileNetV3, respectively. Our results highlight the potential of optimizing the channel counts for different layers jointly with the weights and demonstrate the power of such techniques for slimmable networks.
On the relationship between class selectivity, dimensionality, and robustness
Jul 08, 2020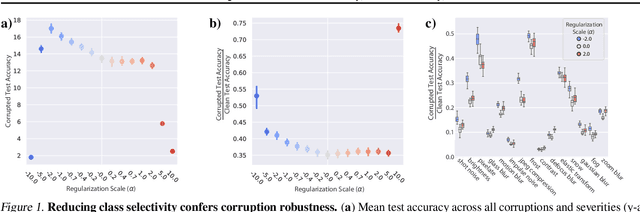
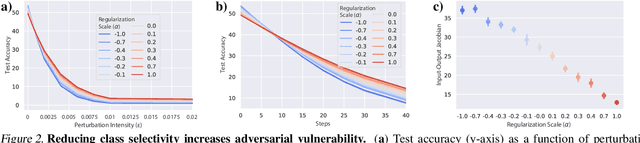
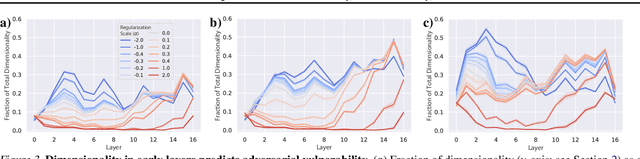
While the relative trade-offs between sparse and distributed representations in deep neural networks (DNNs) are well-studied, less is known about how these trade-offs apply to representations of semantically-meaningful information. Class selectivity, the variability of a unit's responses across data classes or dimensions, is one way of quantifying the sparsity of semantic representations. Given recent evidence showing that class selectivity can impair generalization, we sought to investigate whether it also confers robustness (or vulnerability) to perturbations of input data. We found that mean class selectivity predicts vulnerability to naturalistic corruptions; networks regularized to have lower levels of class selectivity are more robust to corruption, while networks with higher class selectivity are more vulnerable to corruption, as measured using Tiny ImageNetC and CIFAR10C. In contrast, we found that class selectivity increases robustness to multiple types of gradient-based adversarial attacks. To examine this difference, we studied the dimensionality of the change in the representation due to perturbation, finding that decreasing class selectivity increases the dimensionality of this change for both corruption types, but with a notably larger increase for adversarial attacks. These results demonstrate the causal relationship between selectivity and robustness and provide new insights into the mechanisms of this relationship.
Plan2Vec: Unsupervised Representation Learning by Latent Plans
May 07, 2020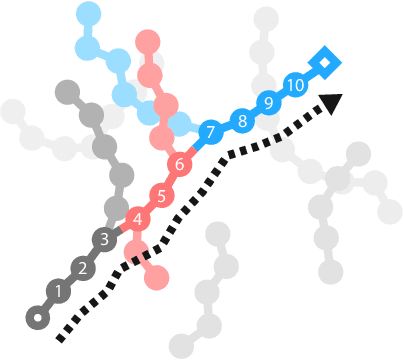
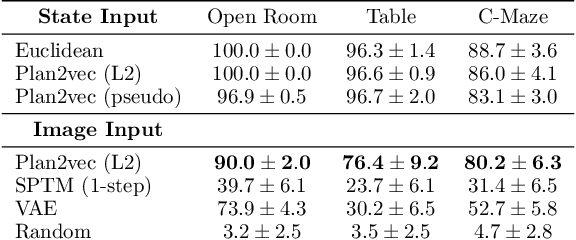
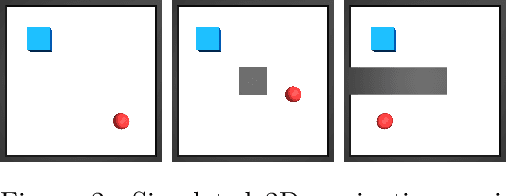

In this paper we introduce plan2vec, an unsupervised representation learning approach that is inspired by reinforcement learning. Plan2vec constructs a weighted graph on an image dataset using near-neighbor distances, and then extrapolates this local metric to a global embedding by distilling path-integral over planned path. When applied to control, plan2vec offers a way to learn goal-conditioned value estimates that are accurate over long horizons that is both compute and sample efficient. We demonstrate the effectiveness of plan2vec on one simulated and two challenging real-world image datasets. Experimental results show that plan2vec successfully amortizes the planning cost, enabling reactive planning that is linear in memory and computation complexity rather than exhaustive over the entire state space.
* code available at https://geyang.github.io/plan2vec
Training BatchNorm and Only BatchNorm: On the Expressive Power of Random Features in CNNs
Feb 29, 2020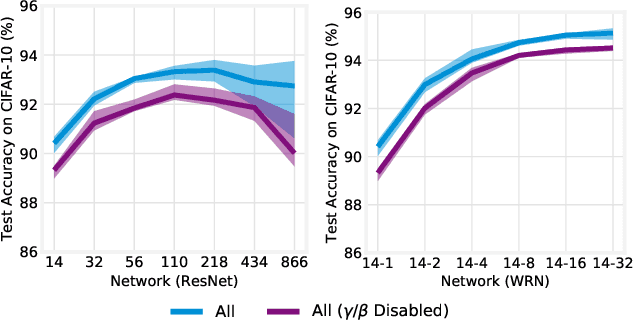
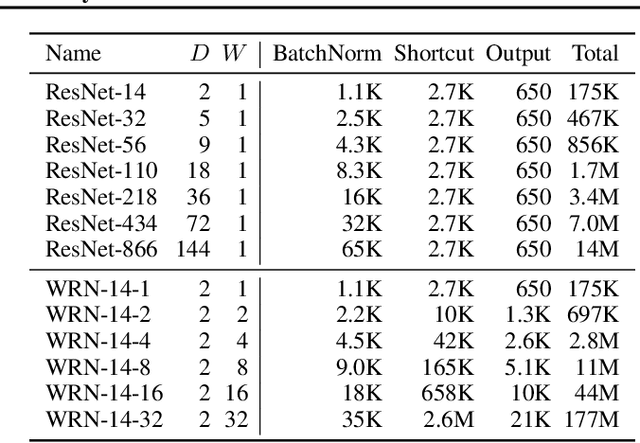
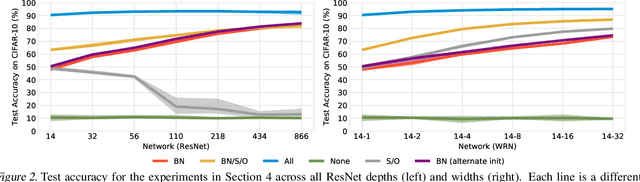
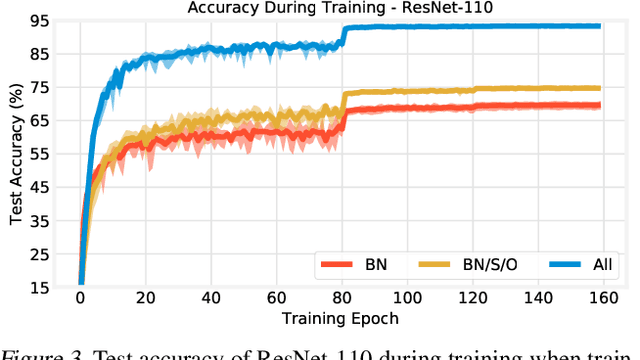
Batch normalization (BatchNorm) has become an indispensable tool for training deep neural networks, yet it is still poorly understood. Although previous work has typically focused on its normalization component, BatchNorm also adds two per-feature trainable parameters: a coefficient and a bias. However, the role and expressive power of these parameters remains unclear. To study this question, we investigate the performance achieved when training only these parameters and freezing all others at their random initializations. We find that doing so leads to surprisingly high performance. For example, a sufficiently deep ResNet reaches 83% accuracy on CIFAR-10 in this configuration. Interestingly, BatchNorm achieves this performance in part by naturally learning to disable around a third of the random features without any changes to the training objective. Not only do these results highlight the under-appreciated role of the affine parameters in BatchNorm, but - in a broader sense - they characterize the expressive power of neural networks constructed simply by shifting and rescaling random features.
The Early Phase of Neural Network Training
Feb 24, 2020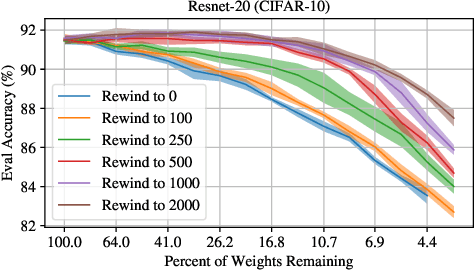
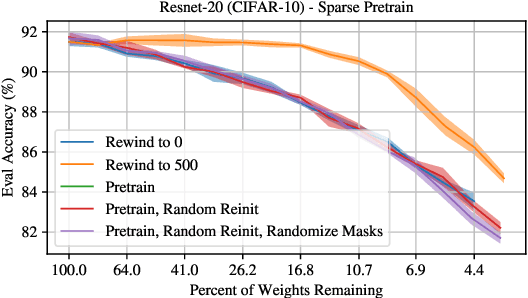

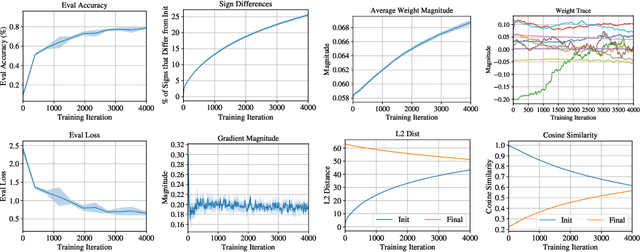
Recent studies have shown that many important aspects of neural network learning take place within the very earliest iterations or epochs of training. For example, sparse, trainable sub-networks emerge (Frankle et al., 2019), gradient descent moves into a small subspace (Gur-Ari et al., 2018), and the network undergoes a critical period (Achille et al., 2019). Here, we examine the changes that deep neural networks undergo during this early phase of training. We perform extensive measurements of the network state during these early iterations of training and leverage the framework of Frankle et al. (2019) to quantitatively probe the weight distribution and its reliance on various aspects of the dataset. We find that, within this framework, deep networks are not robust to reinitializing with random weights while maintaining signs, and that weight distributions are highly non-independent even after only a few hundred iterations. Despite this behavior, pre-training with blurred inputs or an auxiliary self-supervised task can approximate the changes in supervised networks, suggesting that these changes are not inherently label-dependent, though labels significantly accelerate this process. Together, these results help to elucidate the network changes occurring during this pivotal initial period of learning.
The Generalization-Stability Tradeoff in Neural Network Pruning
Jun 09, 2019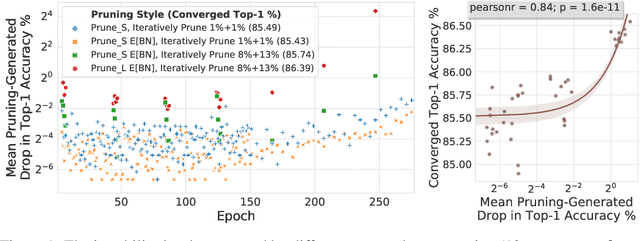
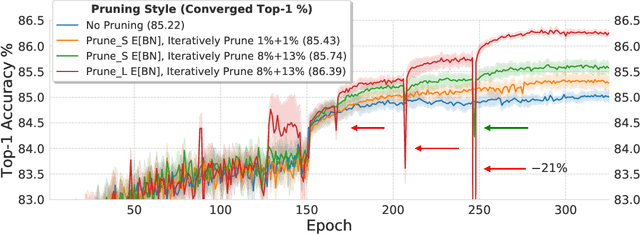
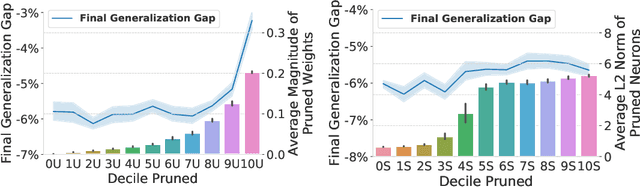
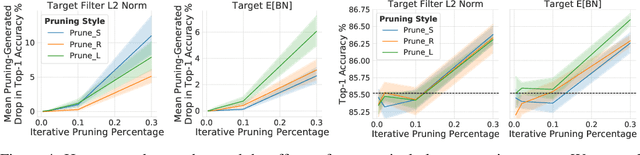
Pruning neural network parameters to reduce model size is an area of much interest, but the original motivation for pruning was the prevention of overfitting rather than the improvement of computational efficiency. This motivation is particularly relevant given the perhaps surprising observation that a wide variety of pruning approaches confer increases in test accuracy, even when parameter counts are drastically reduced. To better understand this phenomenon, we analyze the behavior of pruning over the course of training, finding that pruning's effect on generalization relies more on the instability generated by pruning than the final size of the pruned model. We demonstrate that even pruning of seemingly unimportant parameters can lead to such instability, allowing our finding to account for the generalization benefits of modern pruning techniques. Our results ultimately suggest that, counter-intuitively, pruning regularizes through instability and mechanisms unrelated to parameter counts.