 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUNRISE: A Simple Unified Framework for Ensemble Learning in Deep Reinforcement Learning
Jul 09, 2020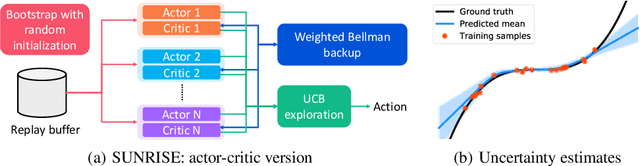
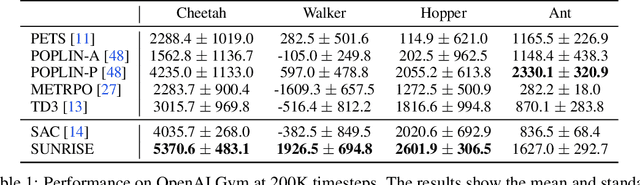
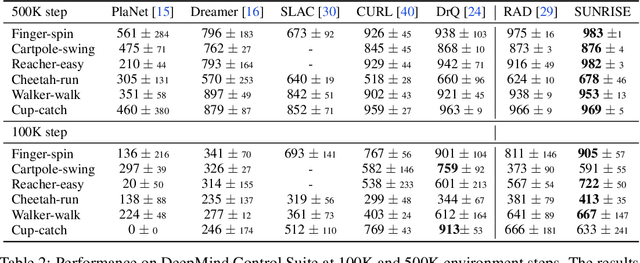
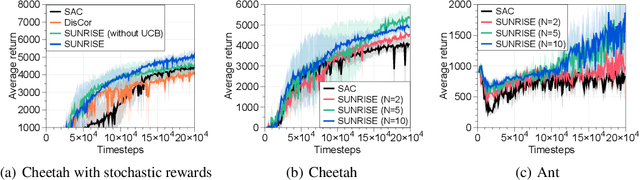
Model-free deep reinforcement learning (RL) has been successful in a range of challenging domains. However, there are some remaining issues, such as stabilizing the optimization of nonlinear function approximators, preventing error propagation due to the Bellman backup in Q-learning, and efficient exploration. To mitigate these issues, we present SUNRISE, a simple unified ensemble method, which is compatible with various off-policy RL algorithms. SUNRISE integrates three key ingredients: (a) bootstrap with random initialization which improves the stability of the learning process by training a diverse ensemble of agents, (b) weighted Bellman backups, which prevent error propagation in Q-learning by reweighing sample transitions based on uncertainty estimates from the ensembles, and (c) an inference method that selects actions using highest upper-confidence bounds for efficient exploration. Our experiments show that SUNRISE significantly improves the performance of existing off-policy RL algorithms, such as Soft Actor-Critic and Rainbow DQN, for both continuous and discrete control tasks on both low-dimensional and high-dimensional environments. Our training code is available at https://github.com/pokaxpoka/sunrise.
Reinforcement Learning with Augmented Data
May 11, 2020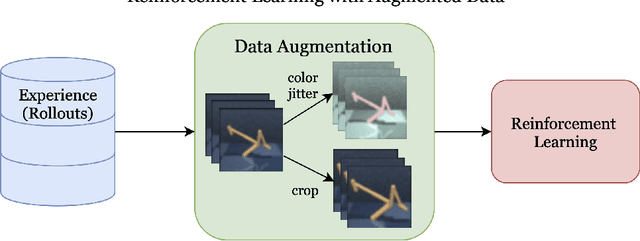
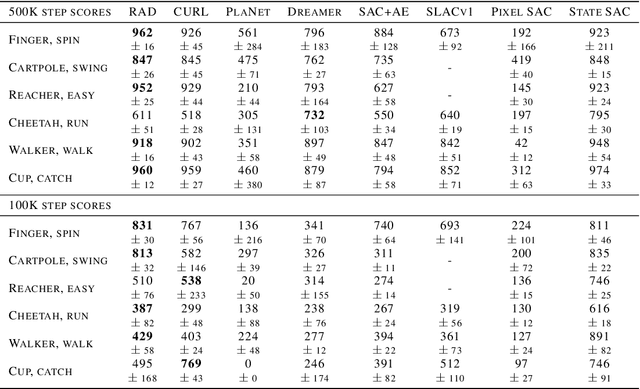

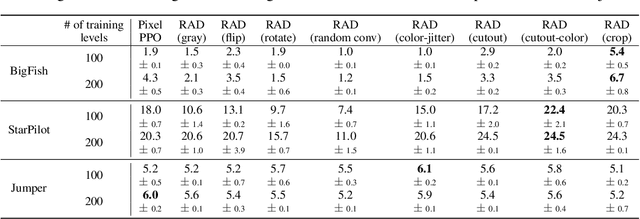
Learning from visual observations is a fundamental yet challenging problem in reinforcement learning (RL). Although algorithmic advancements combined with convolutional neural networks have proved to be a recipe for success, current methods are still lacking on two fronts: (a) sample efficiency of learning and (b) generalization to new environments. To this end, we present RAD: Reinforcement Learning with Augmented Data, a simple plug-and-play module that can enhance any RL algorithm. We show that data augmentations such as random crop, color jitter, patch cutout, and random convolutions can enable simple RL algorithms to match and even outperform complex state-of-the-art methods across common benchmarks in terms of data-efficiency, generalization, and wall-clock speed. We find that data diversity alone can make agents focus on meaningful information from high-dimensional observations without any changes to the reinforcement learning method. On the DeepMind Control Suite, we show that RAD is state-of-the-art in terms of data-efficiency and performance across 15 environments. We further demonstrate that RAD can significantly improve the test-time generalization on several OpenAI ProcGen benchmarks. Finally, our customized data augmentation modules enable faster wall-clock speed compared to competing RL techniques. Our RAD module and training code are available at https://www.github.com/MishaLaskin/rad.
CURL: Contrastive Unsupervised Representations for Reinforcement Learning
Apr 28, 2020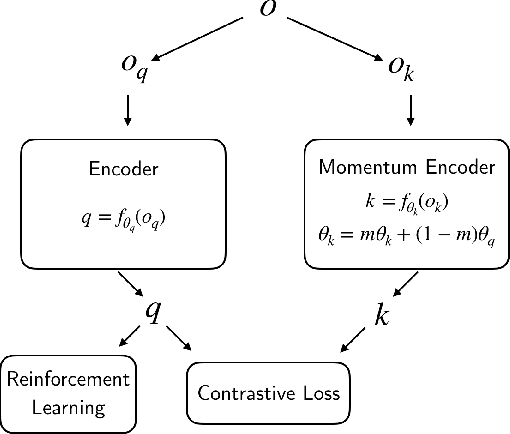
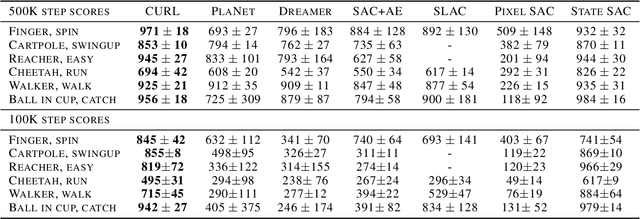
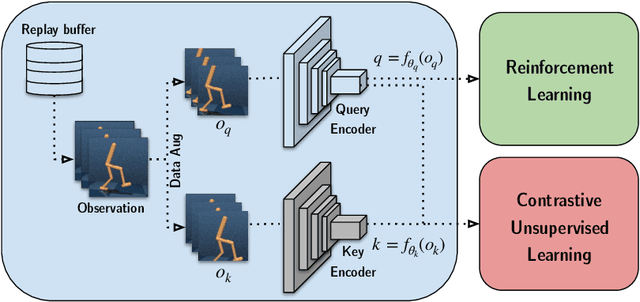
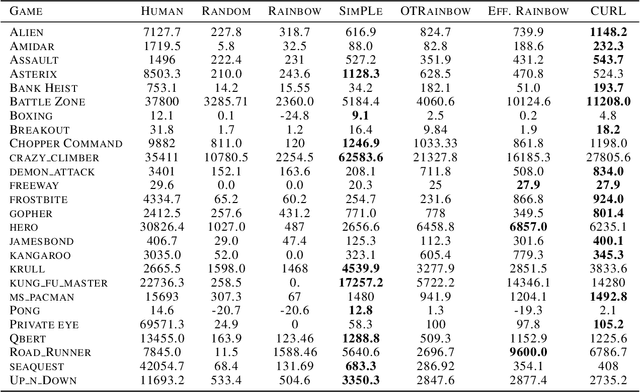
We present CURL: Contrastive Unsupervised Representations for Reinforcement Learning. CURL extracts high-level features from raw pixels using contrastive learning and performs off-policy control on top of the extracted features. CURL outperforms prior pixel-based methods, both model-based and model-free, on complex tasks in the DeepMind Control Suite and Atari Games showing 1.9x and 1.6x performance gains at the 100K environment and interaction steps benchmarks respectively. On the DeepMind Control Suite, CURL is the first image-based algorithm to nearly match the sample-efficiency and performance of methods that use state-based features.
Flow++: Improving Flow-Based Generative Models with Variational Dequantization and Architecture Design
Feb 01, 2019



Flow-based generative models are powerful exact likelihood models with efficient sampling and inference. Despite their computational efficiency, flow-based models generally have much worse density modeling performance compared to state-of-the-art autoregressive models. In this paper, we investigate and improve upon three limiting design choices employed by flow-based models in prior work: the use of uniform noise for dequantization, the use of inexpressive affine flows, and the use of purely convolutional conditioning networks in coupling layers. Based on our findings, we propose Flow++, a new flow-based model that is now the state-of-the-art non-autoregressive model for unconditional density estimation on standard image benchmarks. Our work has begun to close the significant performance gap that has so far existed between autoregressive models and flow-based models. Our implementation is available at https://github.com/aravind0706/flowpp.
Universal Planning Networks
Apr 04, 2018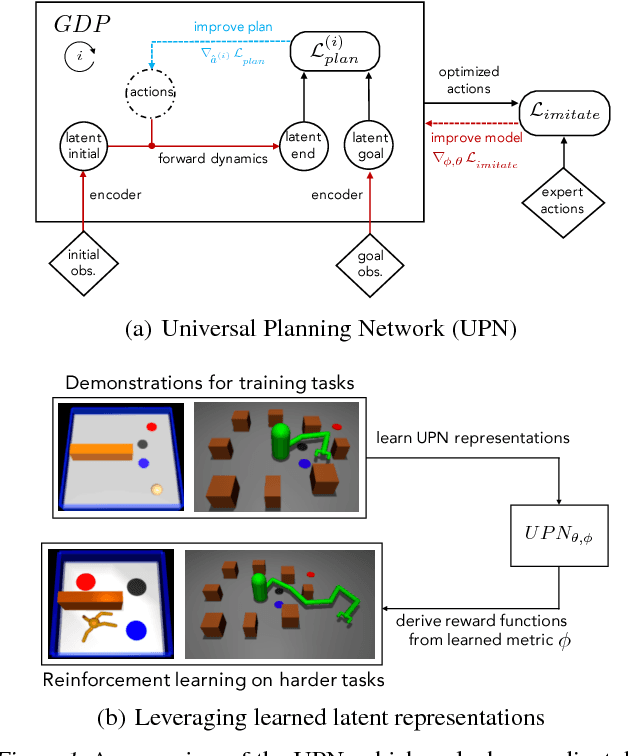
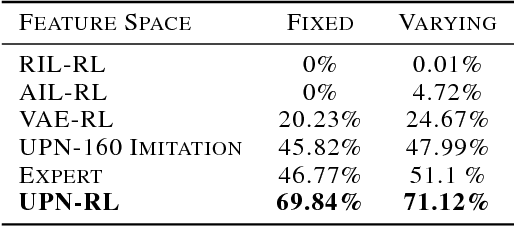
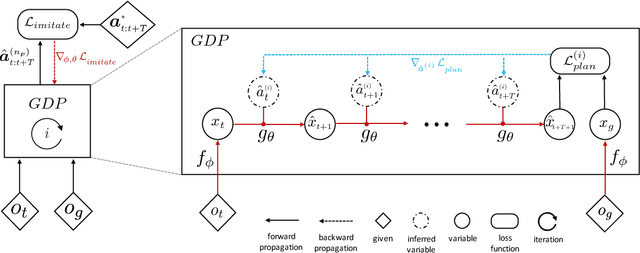
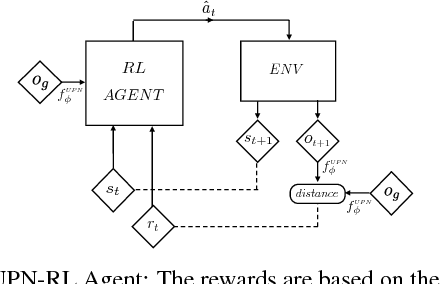
A key challenge in complex visuomotor control is learning abstract representations that are effective for specifying goals, planning, and generalization. To this end, we introduce universal planning networks (UPN). UPNs embed differentiable planning within a goal-directed policy. This planning computation unrolls a forward model in a latent space and infers an optimal action plan through gradient descent trajectory optimization. The plan-by-gradient-descent process and its underlying representations are learned end-to-end to directly optimize a supervised imitation learning objective. We find that the representations learned are not only effective for goal-directed visual imitation via gradient-based trajectory optimization, but can also provide a metric for specifying goals using images. The learned representations can be leveraged to specify distance-based rewards to reach new target states for model-free reinforcement learning, resulting in substantially more effective learning when solving new tasks described via image-based goals. We were able to achieve successful transfer of visuomotor planning strategies across robots with significantly different morphologies and actuation capabilities.