 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Step-KTO: Optimizing Mathematical Reasoning through Stepwise Binary Feedback
Jan 18, 2025Large language models (LLMs) have recently demonstrated remarkable success in mathematical reasoning. Despite progress in methods like chain-of-thought prompting and self-consistency sampling, these advances often focus on final correctness without ensuring that the underlying reasoning process is coherent and reliable. This paper introduces Step-KTO, a training framework that combines process-level and outcome-level binary feedback to guide LLMs toward more trustworthy reasoning trajectories. By providing binary evaluations for both the intermediate reasoning steps and the final answer, Step-KTO encourages the model to adhere to logical progressions rather than relying on superficial shortcuts. Our experiments on challenging mathematical benchmarks show that Step-KTO significantly improves both final answer accuracy and the quality of intermediate reasoning steps. For example, on the MATH-500 dataset, Step-KTO achieves a notable improvement in Pass@1 accuracy over strong baselines. These results highlight the promise of integrating stepwise process feedback into LLM training, paving the way toward more interpretable and dependable reasoning capabilities.
Robustness against Adversarial Attacks in Neural Networks using Incremental Dissipativity
Nov 25, 2021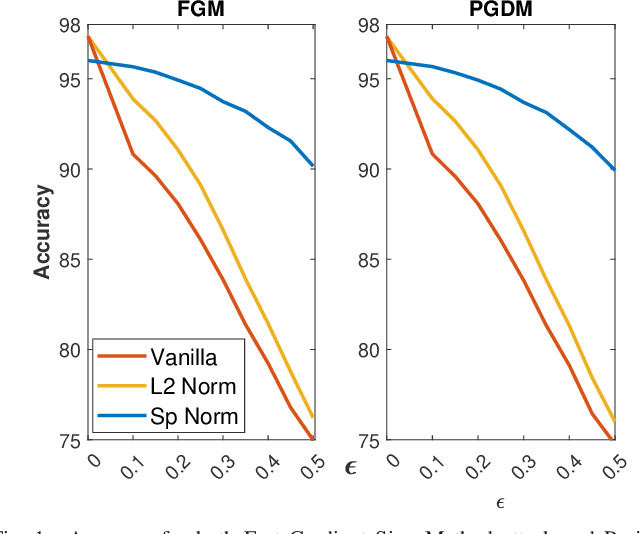
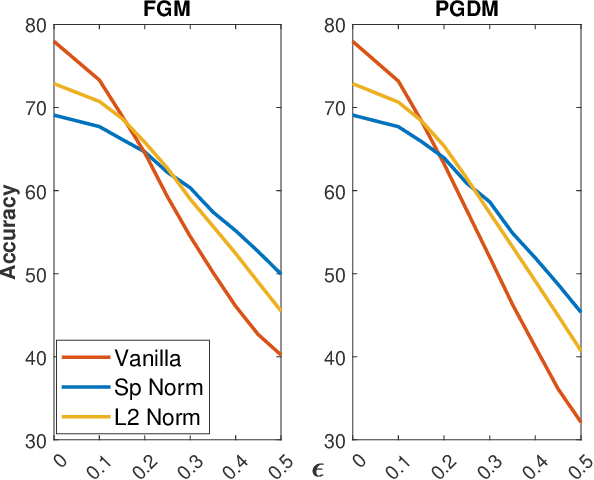
Adversarial examples can easily degrade the classification performance in neural networks. Empirical methods for promoting robustness to such examples have been proposed, but often lack both analytical insights and formal guarantees. Recently, some robustness certificates have appeared in the literature based on system theoretic notions. This work proposes an incremental dissipativity-based robustness certificate for neural networks in the form of a linear matrix inequality for each layer. We also propose an equivalent spectral norm bound for this certificate which is scalable to neural networks with multiple layers. We demonstrate the improved performance against adversarial attacks on a feed-forward neural network trained on MNIST and an Alexnet trained using CIFAR-10.
Amazon SageMaker Model Parallelism: A General and Flexible Framework for Large Model Training
Nov 10, 2021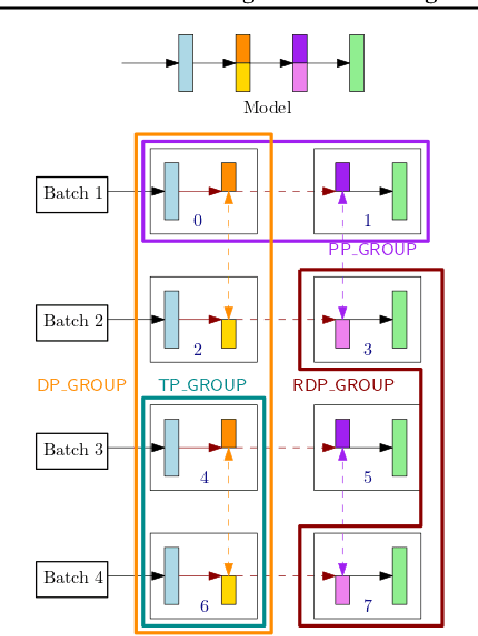
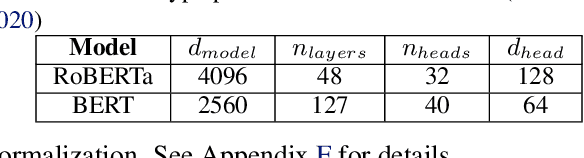
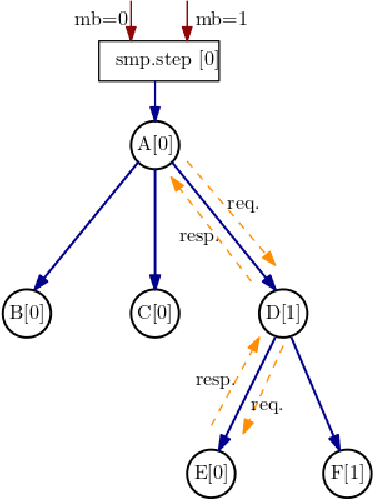

With deep learning models rapidly growing in size, systems-level solutions for large-model training are required. We present Amazon SageMaker model parallelism, a software library that integrates with PyTorch, and enables easy training of large models using model parallelism and other memory-saving features. In contrast to existing solutions, the implementation of the SageMaker library is much more generic and flexible, in that it can automatically partition and run pipeline parallelism over arbitrary model architectures with minimal code change, and also offers a general and extensible framework for tensor parallelism, which supports a wider range of use cases, and is modular enough to be easily applied to new training scripts. The library also preserves the native PyTorch user experience to a much larger degree, supporting module re-use and dynamic graphs, while giving the user full control over the details of the training step. We evaluate performance over GPT-3, RoBERTa, BERT, and neural collaborative filtering, and demonstrate competitive performance over existing solutions.
An Adversarial Approach for Explaining the Predictions of Deep Neural Networks
Jun 22, 2020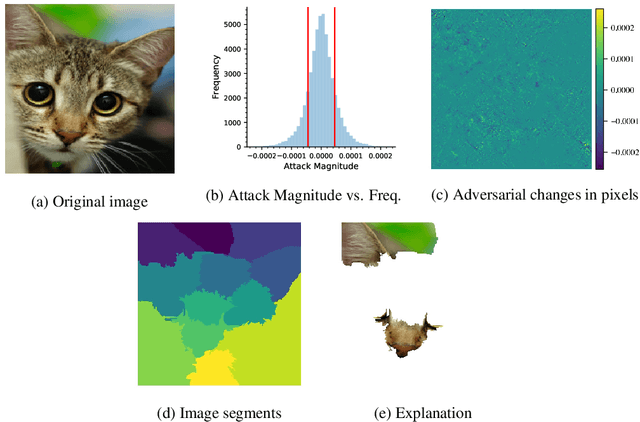
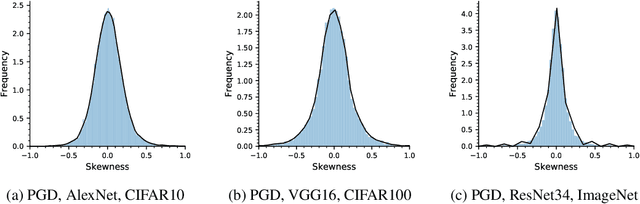
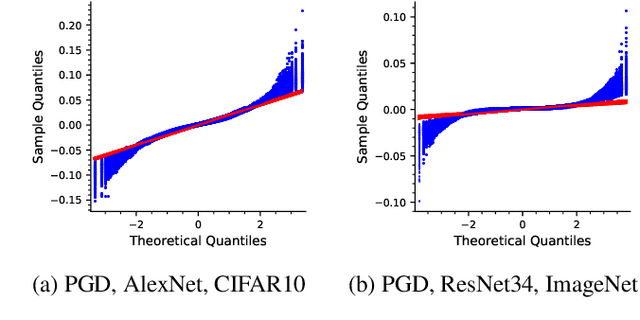
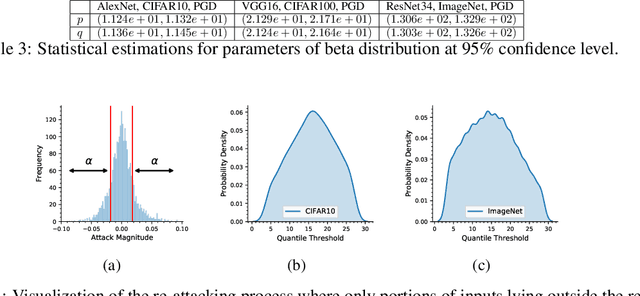
Machine learning models have been successfully applied to a wide range of applications including computer vision, natural language processing, and speech recognition. A successful implementation of these models however, usually relies on deep neural networks (DNNs) which are treated as opaque black-box systems due to their incomprehensible complexity and intricate internal mechanism. In this work, we present a novel algorithm for explaining the predictions of a DNN using adversarial machine learning. Our approach identifies the relative importance of input features in relation to the predictions based on the behavior of an adversarial attack on the DNN. Our algorithm has the advantage of being fast, consistent, and easy to implement and interpret. We present our detailed analysis that demonstrates how the behavior of an adversarial attack, given a DNN and a task, stays consistent for any input test data point proving the generality of our approach. Our analysis enables us to produce consistent and efficient explanations. We illustrate the effectiveness of our approach by conducting experiments using a variety of DNNs, tasks, and datasets. Finally, we compare our work with other well-known techniques in the current literature.
Robust Design of Deep Neural Networks against Adversarial Attacks based on Lyapunov Theory
Nov 12, 2019
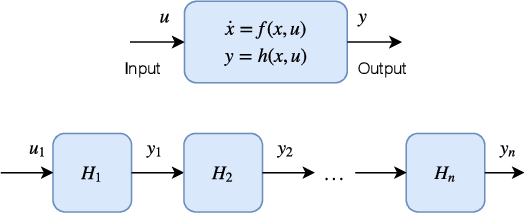
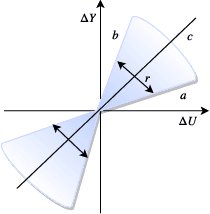
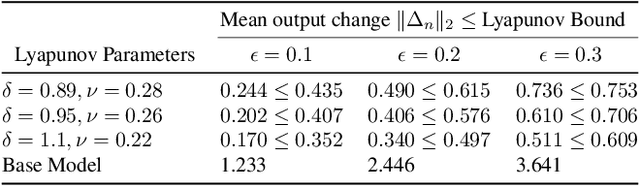
Deep neural networks (DNNs) are vulnerable to subtle adversarial perturbations applied to the input. These adversarial perturbations, though imperceptible, can easily mislead the DNN. In this work, we take a control theoretic approach to the problem of robustness in DNNs. We treat each individual layer of the DNN as a nonlinear dynamical system and use Lyapunov theory to prove stability and robustness locally. We then proceed to prove stability and robustness globally for the entire DNN. We develop empirically tight bounds on the response of the output layer, or any hidden layer, to adversarial perturbations added to the input, or the input of hidden layers. Recent works have proposed spectral norm regularization as a solution for improving robustness against l2 adversarial attacks. Our results give new insights into how spectral norm regularization can mitigate the adversarial effects. Finally, we evaluate the power of our approach on a variety of data sets and network architectures and against some of the well-known adversarial attacks.
Connecting Lyapunov Control Theory to Adversarial Attacks
Jul 17, 2019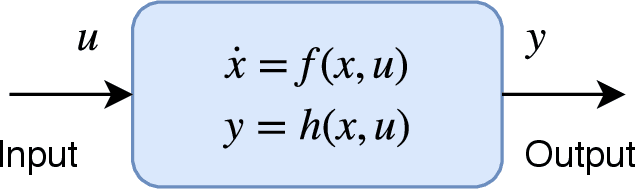
Significant work is being done to develop the math and tools necessary to build provable defenses, or at least bounds, against adversarial attacks of neural networks. In this work, we argue that tools from control theory could be leveraged to aid in defending against such attacks. We do this by example, building a provable defense against a weaker adversary. This is done so we can focus on the mechanisms of control theory, and illuminate its intrinsic value.
Network-based protein structural classification
Apr 12, 2018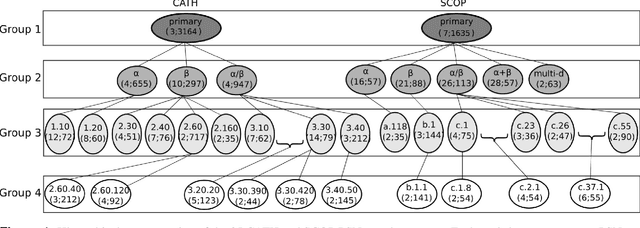
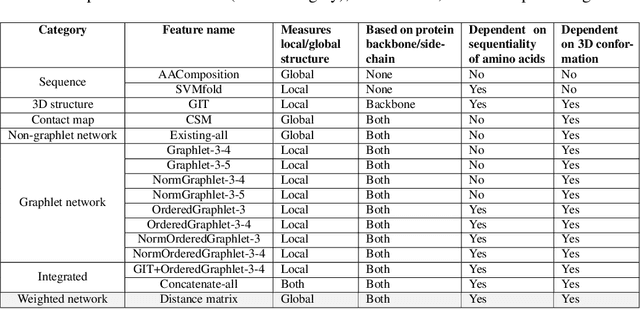
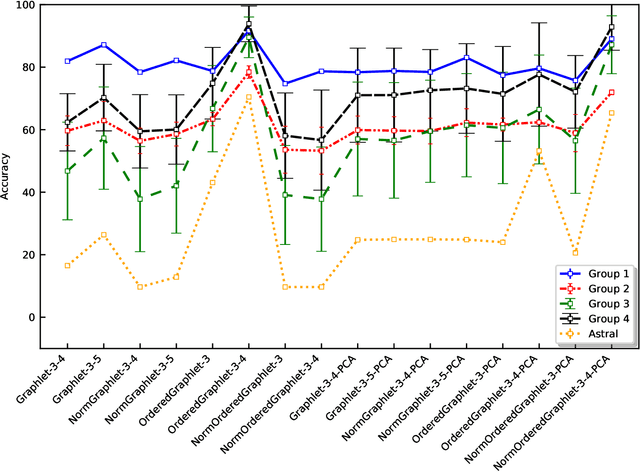
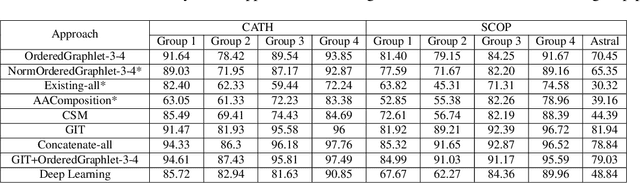
Experimental determination of protein function is resource-consuming. As an alternative, computational prediction of protein function has received attention. In this context, protein structural classification (PSC) can help, by allowing for determining structural classes of currently unclassified proteins based on their features, and then relying on the fact that proteins with similar structures have similar functions. Existing PSC approaches rely on sequence-based or direct ("raw") 3-dimensional (3D) structure-based protein features. Instead, we first model 3D structures as protein structure networks (PSNs). Then, we use ("processed") network-based features for PSC. We are the first ones to do so. We propose the use of graphlets, state-of-the-art features in many domains of network science, in the task of PSC. Moreover, because graphlets can deal only with unweighted PSNs, and because accounting for edge weights when constructing PSNs could improve PSC accuracy, we also propose a deep learning framework that automatically learns network features from the weighted PSNs. When evaluated on a large set of 9,509 CATH and 11,451 SCOP protein domains, our proposed approaches are superior to existing PSC approaches in terms of both accuracy and running time.
Resilient Learning-Based Control for Synchronization of Passive Multi-Agent Systems under Attack
Sep 28, 2017
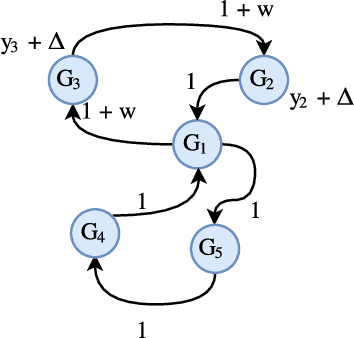
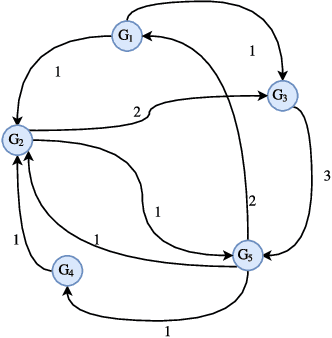
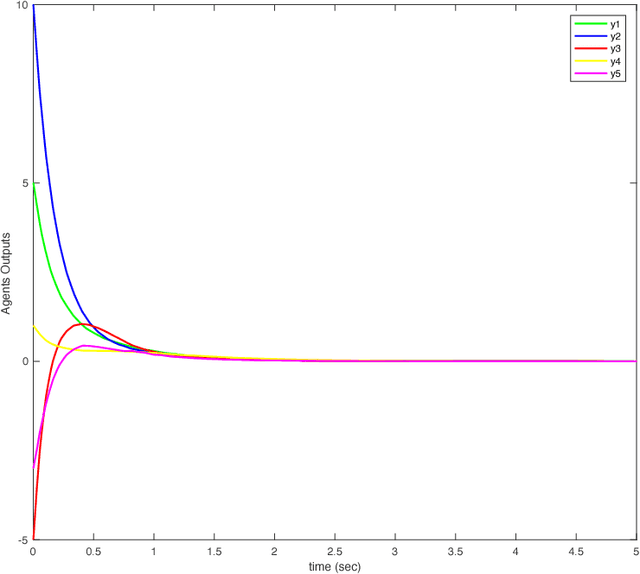
In this paper, we show synchronization for a group of output passive agents that communicate with each other according to an underlying communication graph to achieve a common goal. We propose a distributed event-triggered control framework that will guarantee synchronization and considerably decrease the required communication load on the band-limited network. We define a general Byzantine attack on the event-triggered multi-agent network system and characterize its negative effects on synchronization. The Byzantine agents are capable of intelligently falsifying their data and manipulating the underlying communication graph by altering their respective control feedback weights. We introduce a decentralized detection framework and analyze its steady-state and transient performances. We propose a way of identifying individual Byzantine neighbors and a learning-based method of estimating the attack parameters. Lastly, we propose learning-based control approaches to mitigate the negative effects of the adversarial attack.
Encoding Multi-Resolution Brain Networks Using Unsupervised Deep Learning
Aug 13, 2017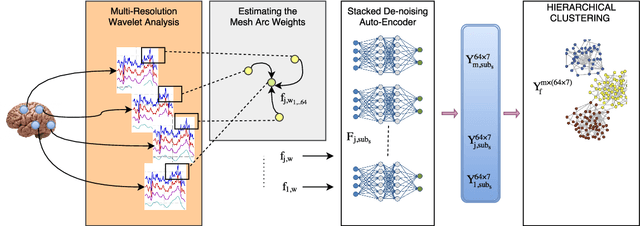
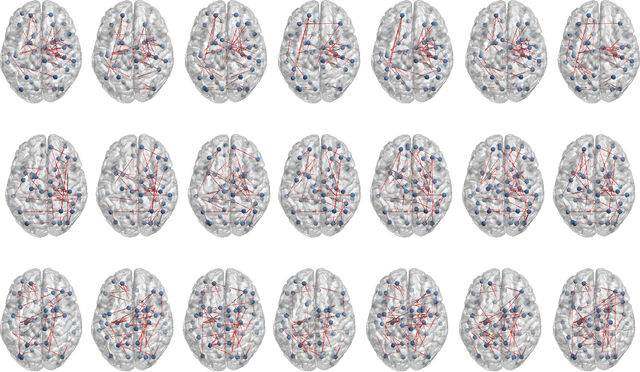


The main goal of this study is to extract a set of brain networks in multiple time-resolutions to analyze the connectivity patterns among the anatomic regions for a given cognitive task. We suggest a deep architecture which learns the natural groupings of the connectivity patterns of human brain in multiple time-resolutions. The suggested architecture is tested on task data set of Human Connectome Project (HCP) where we extract multi-resolution networks, each of which corresponds to a cognitive task. At the first level of this architecture, we decompose the fMRI signal into multiple sub-bands using wavelet decompositions. At the second level, for each sub-band, we estimate a brain network extracted from short time windows of the fMRI signal. At the third level, we feed the adjacency matrices of each mesh network at each time-resolution into an unsupervised deep learning algorithm, namely, a Stacked De- noising Auto-Encoder (SDAE). The outputs of the SDAE provide a compact connectivity representation for each time window at each sub-band of the fMRI signal. We concatenate the learned representations of all sub-bands at each window and cluster them by a hierarchical algorithm to find the natural groupings among the windows. We observe that each cluster represents a cognitive task with a performance of 93% Rand Index and 71% Adjusted Rand Index. We visualize the mean values and the precisions of the networks at each component of the cluster mixture. The mean brain networks at cluster centers show the variations among cognitive tasks and the precision of each cluster shows the within cluster variability of networks, across the subjects.