 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoftDICE for Imitation Learning: Rethinking Off-policy Distribution Matching
Jun 06, 2021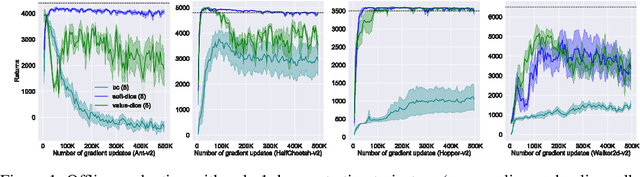
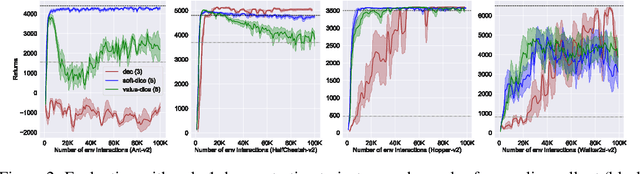
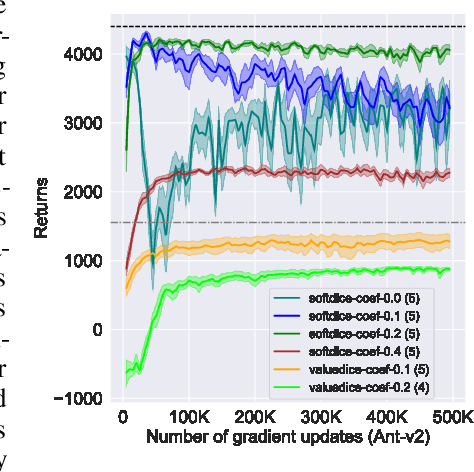
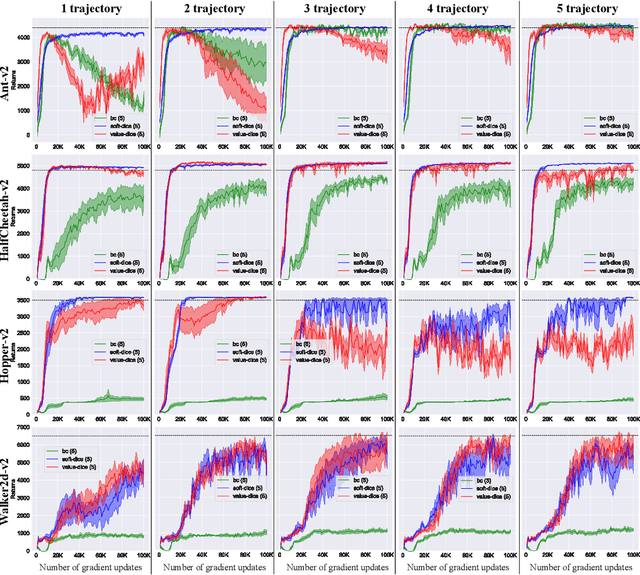
We present SoftDICE, which achieves state-of-the-art performance for imitation learning. SoftDICE fixes several key problems in ValueDICE, an off-policy distribution matching approach for sample-efficient imitation learning. Specifically, the objective of ValueDICE contains logarithms and exponentials of expectations, for which the mini-batch gradient estimate is always biased. Second, ValueDICE regularizes the objective with replay buffer samples when expert demonstrations are limited in number, which however changes the original distribution matching problem. Third, the re-parametrization trick used to derive the off-policy objective relies on an implicit assumption that rarely holds in training. We leverage a novel formulation of distribution matching and consider an entropy-regularized off-policy objective, which yields a completely offline algorithm called SoftDICE. Our empirical results show that SoftDICE recovers the expert policy with only one demonstration trajectory and no further on-policy/off-policy samples. SoftDICE also stably outperforms ValueDICE and other baselines in terms of sample efficiency on Mujoco benchmark tasks.
Tesseract: Tensorised Actors for Multi-Agent Reinforcement Learning
May 31, 2021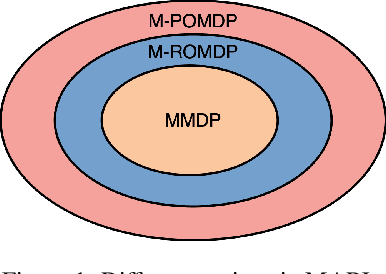
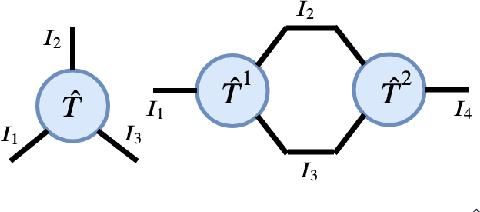
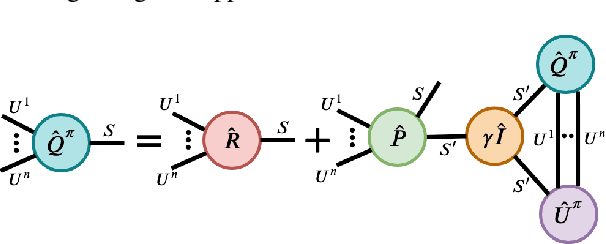
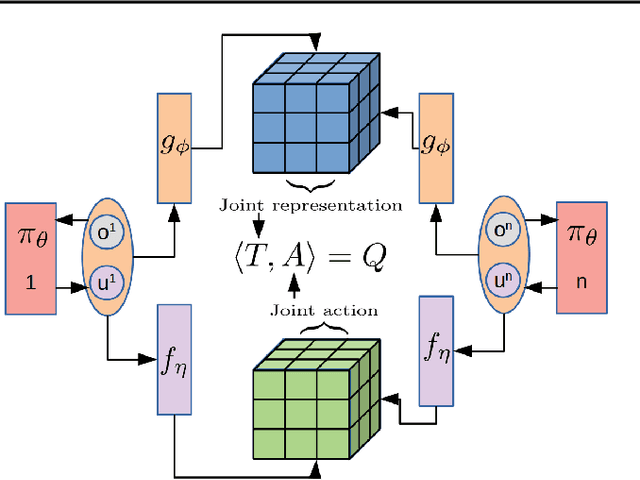
Reinforcement Learning in large action spaces is a challenging problem. Cooperative multi-agent reinforcement learning (MARL) exacerbates matters by imposing various constraints on communication and observability. In this work, we consider the fundamental hurdle affecting both value-based and policy-gradient approaches: an exponential blowup of the action space with the number of agents. For value-based methods, it poses challenges in accurately representing the optimal value function. For policy gradient methods, it makes training the critic difficult and exacerbates the problem of the lagging critic. We show that from a learning theory perspective, both problems can be addressed by accurately representing the associated action-value function with a low-complexity hypothesis class. This requires accurately modelling the agent interactions in a sample efficient way. To this end, we propose a novel tensorised formulation of the Bellman equation. This gives rise to our method Tesseract, which views the Q-function as a tensor whose modes correspond to the action spaces of different agents. Algorithms derived from Tesseract decompose the Q-tensor across agents and utilise low-rank tensor approximations to model agent interactions relevant to the task. We provide PAC analysis for Tesseract-based algorithms and highlight their relevance to the class of rich observation MDPs. Empirical results in different domains confirm Tesseract's gains in sample efficiency predicted by the theory.
UneVEn: Universal Value Exploration for Multi-Agent Reinforcement Learning
Oct 06, 2020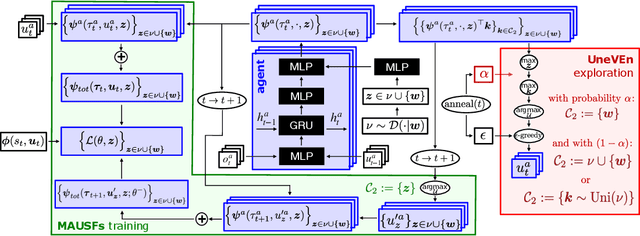
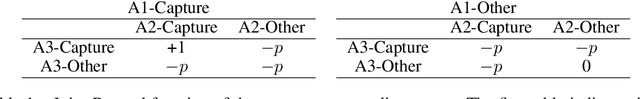
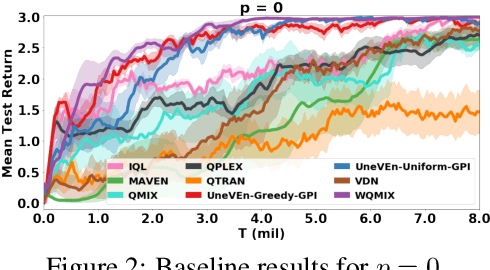
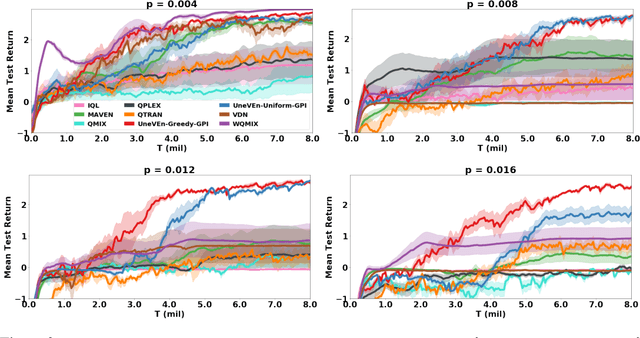
This paper focuses on cooperative value-based multi-agent reinforcement learning (MARL) in the paradigm of centralized training with decentralized execution (CTDE). Current state-of-the-art value-based MARL methods leverage CTDE to learn a centralized joint-action value function as a monotonic mixing of each agent's utility function, which enables easy decentralization. However, this monotonic restriction leads to inefficient exploration in tasks with nonmonotonic returns due to suboptimal approximations of the values of joint actions. To address this, we present a novel MARL approach called Universal Value Exploration (UneVEn), which uses universal successor features (USFs) to learn policies of tasks related to the target task, but with simpler reward functions in a sample efficient manner. UneVEn uses novel action-selection schemes between randomly sampled related tasks during exploration, which enables the monotonic joint-action value function of the target task to place more importance on useful joint actions. Empirical results on a challenging cooperative predator-prey task requiring significant coordination amongst agents show that UneVEn significantly outperforms state-of-the-art baselines.
RODE: Learning Roles to Decompose Multi-Agent Tasks
Oct 04, 2020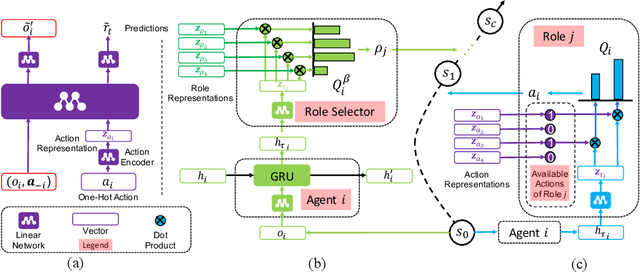

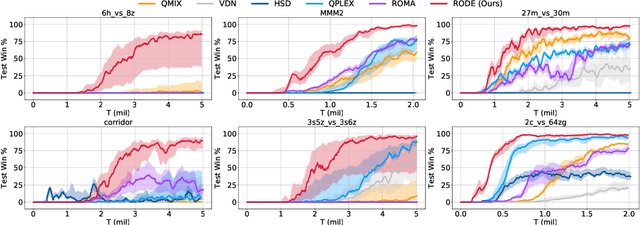
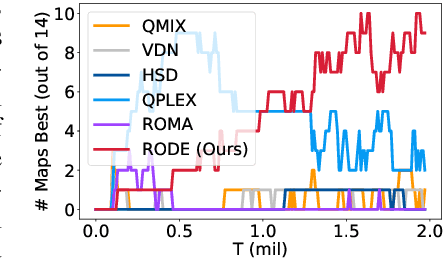
Role-based learning holds the promise of achieving scalable multi-agent learning by decomposing complex tasks using roles. However, it is largely unclear how to efficiently discover such a set of roles. To solve this problem, we propose to first decompose joint action spaces into restricted role action spaces by clustering actions according to their effects on the environment and other agents. Learning a role selector based on action effects makes role discovery much easier because it forms a bi-level learning hierarchy -- the role selector searches in a smaller role space and at a lower temporal resolution, while role policies learn in significantly reduced primitive action-observation spaces. We further integrate information about action effects into the role policies to boost learning efficiency and policy generalization. By virtue of these advances, our method (1) outperforms the current state-of-the-art MARL algorithms on 10 of the 14 scenarios that comprise the challenging StarCraft II micromanagement benchmark and (2) achieves rapid transfer to new environments with three times the number of agents. Demonstrative videos are available at https://sites.google.com/view/rode-marl .
MAVEN: Multi-Agent Variational Exploration
Oct 16, 2019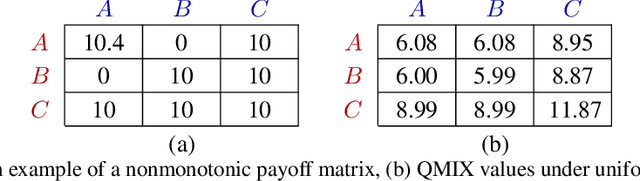
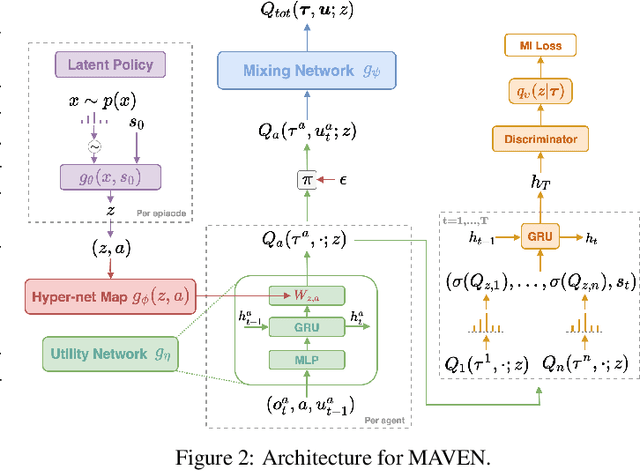
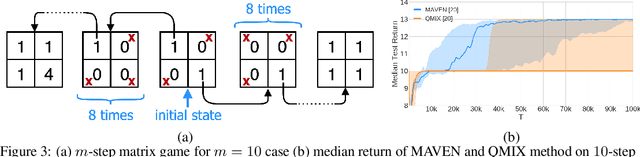

Centralised training with decentralised execution is an important setting for cooperative deep multi-agent reinforcement learning due to communication constraints during execution and computational tractability in training. In this paper, we analyse value-based methods that are known to have superior performance in complex environments [43]. We specifically focus on QMIX [40], the current state-of-the-art in this domain. We show that the representational constraints on the joint action-values introduced by QMIX and similar methods lead to provably poor exploration and suboptimality. Furthermore, we propose a novel approach called MAVEN that hybridises value and policy-based methods by introducing a latent space for hierarchical control. The value-based agents condition their behaviour on the shared latent variable controlled by a hierarchical policy. This allows MAVEN to achieve committed, temporally extended exploration, which is key to solving complex multi-agent tasks. Our experimental results show that MAVEN achieves significant performance improvements on the challenging SMAC domain [43].
VIREL: A Variational Inference Framework for Reinforcement Learning
Nov 03, 2018
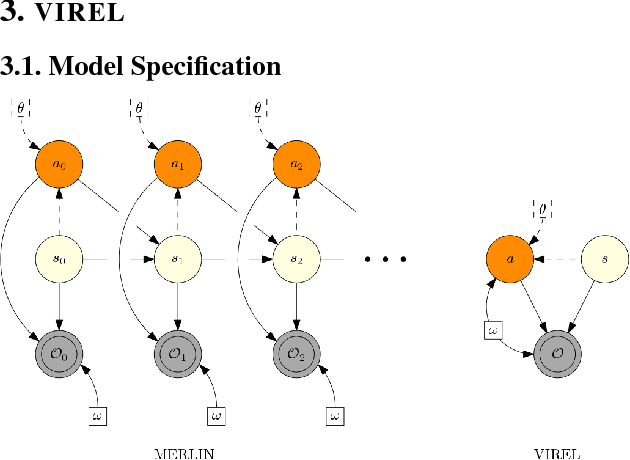

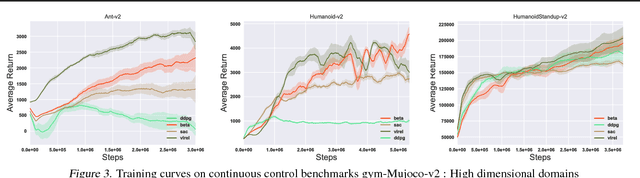
Applying probabilistic models to reinforcement learning (RL) has become an exciting direction of research owing to powerful optimisation tools such as variational inference becoming applicable to RL. However, due to their formulation, existing inference frameworks and their algorithms pose significant challenges for learning optimal policies, for example, the absence of mode capturing behaviour in pseudo-likelihood methods and difficulties in optimisation of learning objective in maximum entropy RL based approaches. We propose VIREL, a novel, theoretically grounded probabilistic inference framework for RL that utilises the action-value function in a parametrised form to capture future dynamics of the underlying Markov decision process. Owing to it's generality, our framework lends itself to current advances in variational inference. Applying the variational expectation-maximisation algorithm to our framework, we show that actor-critic algorithm can be reduced to expectation-maximization. We derive a family of methods from our framework, including state-of-the-art methods based on soft value functions. We evaluate two actor-critic algorithms derived from this family, which perform on par with soft actor critic, demonstrating that our framework offers a promising perspective on RL as inference.
Symmetry Learning for Function Approximation in Reinforcement Learning
Jun 09, 2017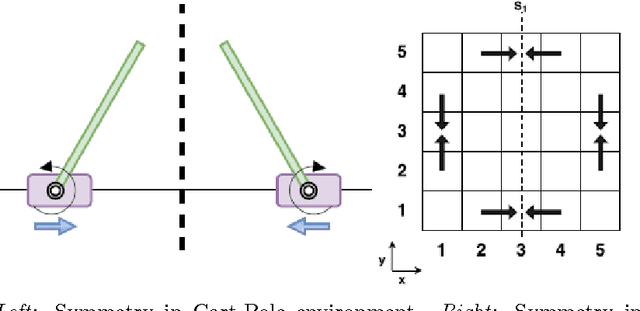
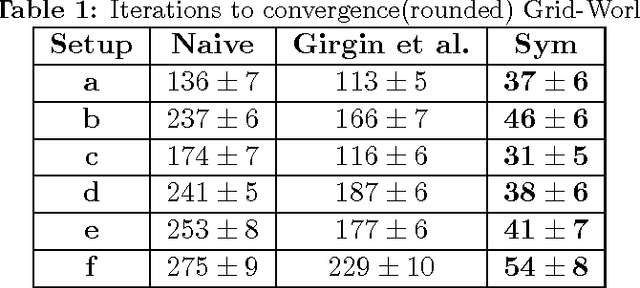
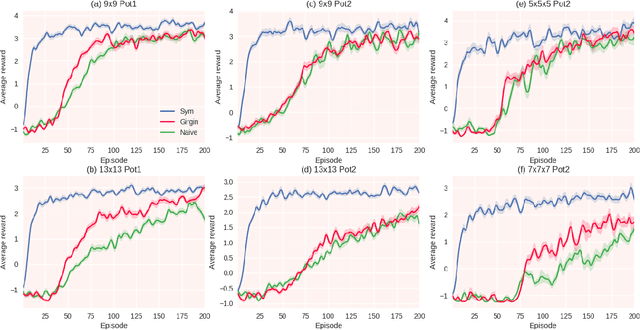
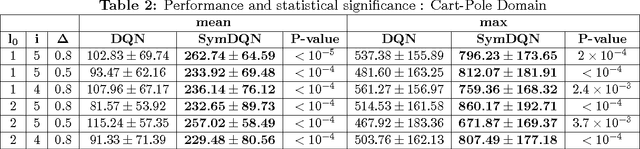
In this paper we explore methods to exploit symmetries for ensuring sample efficiency in reinforcement learning (RL), this problem deserves ever increasing attention with the recent advances in the use of deep networks for complex RL tasks which require large amount of training data. We introduce a novel method to detect symmetries using reward trails observed during episodic experience and prove its completeness. We also provide a framework to incorporate the discovered symmetries for functional approximation. Finally we show that the use of potential based reward shaping is especially effective for our symmetry exploitation mechanism. Experiments on various classical problems show that our method improves the learning performance significantly by utilizing symmetry information.