 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHR-Agent: A Task-Oriented Dialogue (TOD) LLM Agent Tailored for HR Applications
Oct 15, 2024Recent LLM (Large Language Models) advancements benefit many fields such as education and finance, but HR has hundreds of repetitive processes, such as access requests, medical claim filing and time-off submissions, which are unaddressed. We relate these tasks to the LLM agent, which has addressed tasks such as writing assisting and customer support. We present HR-Agent, an efficient, confidential, and HR-specific LLM-based task-oriented dialogue system tailored for automating repetitive HR processes such as medical claims and access requests. Since conversation data is not sent to an LLM during inference, it preserves confidentiality required in HR-related tasks.
LOLAMEME: Logic, Language, Memory, Mechanistic Framework
May 31, 2024



The performance of Large Language Models has achieved superhuman breadth with unprecedented depth. At the same time, the language models are mostly black box models and the underlying mechanisms for performance have been evaluated using synthetic or mechanistic schemes. We extend current mechanistic schemes to incorporate Logic, memory, and nuances of Language such as latent structure. The proposed framework is called LOLAMEME and we provide two instantiations of LOLAMEME: LoLa and MeMe languages. We then consider two generative language model architectures: transformer-based GPT-2 and convolution-based Hyena. We propose the hybrid architecture T HEX and use LOLAMEME framework is used to compare three architectures. T HEX outperforms GPT-2 and Hyena on select tasks.
JADS: A Framework for Self-supervised Joint Aspect Discovery and Summarization
May 28, 2024



To generate summaries that include multiple aspects or topics for text documents, most approaches use clustering or topic modeling to group relevant sentences and then generate a summary for each group. These approaches struggle to optimize the summarization and clustering algorithms jointly. On the other hand, aspect-based summarization requires known aspects. Our solution integrates topic discovery and summarization into a single step. Given text data, our Joint Aspect Discovery and Summarization algorithm (JADS) discovers aspects from the input and generates a summary of the topics, in one step. We propose a self-supervised framework that creates a labeled dataset by first mixing sentences from multiple documents (e.g., CNN/DailyMail articles) as the input and then uses the article summaries from the mixture as the labels. The JADS model outperforms the two-step baselines. With pretraining, the model achieves better performance and stability. Furthermore, embeddings derived from JADS exhibit superior clustering capabilities. Our proposed method achieves higher semantic alignment with ground truth and is factual.
Two-Stage Violence Detection Using ViTPose and Classification Models at Smart Airports
Aug 30, 2023



This study introduces an innovative violence detection framework tailored to the unique requirements of smart airports, where prompt responses to violent situations are crucial. The proposed framework harnesses the power of ViTPose for human pose estimation. It employs a CNN - BiLSTM network to analyse spatial and temporal information within keypoints sequences, enabling the accurate classification of violent behaviour in real time. Seamlessly integrated within the SAFE (Situational Awareness for Enhanced Security framework of SAAB, the solution underwent integrated testing to ensure robust performance in real world scenarios. The AIRTLab dataset, characterized by its high video quality and relevance to surveillance scenarios, is utilized in this study to enhance the model's accuracy and mitigate false positives. As airports face increased foot traffic in the post pandemic era, implementing AI driven violence detection systems, such as the one proposed, is paramount for improving security, expediting response times, and promoting data informed decision making. The implementation of this framework not only diminishes the probability of violent events but also assists surveillance teams in effectively addressing potential threats, ultimately fostering a more secure and protected aviation sector. Codes are available at: https://github.com/Asami-1/GDP.
S2vNTM: Semi-supervised vMF Neural Topic Modeling
Jul 06, 2023Language model based methods are powerful techniques for text classification. However, the models have several shortcomings. (1) It is difficult to integrate human knowledge such as keywords. (2) It needs a lot of resources to train the models. (3) It relied on large text data to pretrain. In this paper, we propose Semi-Supervised vMF Neural Topic Modeling (S2vNTM) to overcome these difficulties. S2vNTM takes a few seed keywords as input for topics. S2vNTM leverages the pattern of keywords to identify potential topics, as well as optimize the quality of topics' keywords sets. Across a variety of datasets, S2vNTM outperforms existing semi-supervised topic modeling methods in classification accuracy with limited keywords provided. S2vNTM is at least twice as fast as baselines.
* 17 pages, 9 figures, ICLR Workshop 2023. arXiv admin note: text overlap with arXiv:2307.01226
KDSTM: Neural Semi-supervised Topic Modeling with Knowledge Distillation
Jul 04, 2023



In text classification tasks, fine tuning pretrained language models like BERT and GPT-3 yields competitive accuracy; however, both methods require pretraining on large text datasets. In contrast, general topic modeling methods possess the advantage of analyzing documents to extract meaningful patterns of words without the need of pretraining. To leverage topic modeling's unsupervised insights extraction on text classification tasks, we develop the Knowledge Distillation Semi-supervised Topic Modeling (KDSTM). KDSTM requires no pretrained embeddings, few labeled documents and is efficient to train, making it ideal under resource constrained settings. Across a variety of datasets, our method outperforms existing supervised topic modeling methods in classification accuracy, robustness and efficiency and achieves similar performance compare to state of the art weakly supervised text classification methods.
* 12 pages, 4 figures, ICLR 2022 Workshop
Attention-based Region of Interest (ROI) Detection for Speech Emotion Recognition
Mar 03, 2022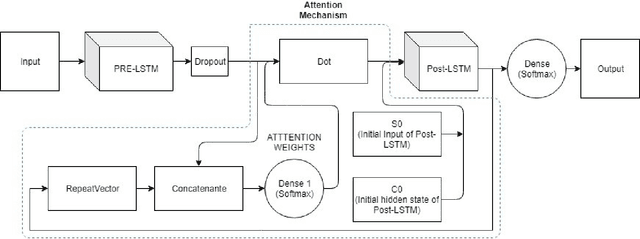
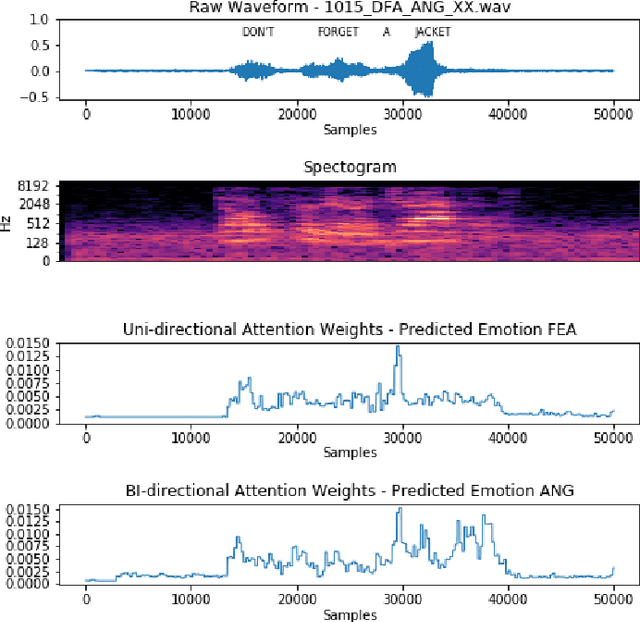

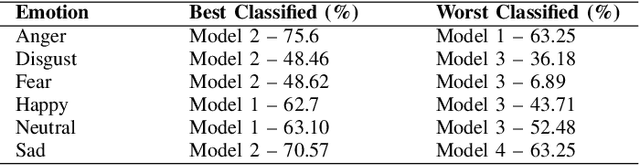
Automatic emotion recognition for real-life appli-cations is a challenging task. Human emotion expressions aresubtle, and can be conveyed by a combination of several emo-tions. In most existing emotion recognition studies, each audioutterance/video clip is labelled/classified in its entirety. However,utterance/clip-level labelling and classification can be too coarseto capture the subtle intra-utterance/clip temporal dynamics. Forexample, an utterance/video clip usually contains only a fewemotion-salient regions and many emotionless regions. In thisstudy, we propose to use attention mechanism in deep recurrentneural networks to detection the Regions-of-Interest (ROI) thatare more emotionally salient in human emotional speech/video,and further estimate the temporal emotion dynamics by aggre-gating those emotionally salient regions-of-interest. We comparethe ROI from audio and video and analyse them. We comparethe performance of the proposed attention networks with thestate-of-the-art LSTM models on multi-class classification task ofrecognizing six basic human emotions, and the proposed attentionmodels exhibit significantly better performance. Furthermore, theattention weight distribution can be used to interpret how anutterance can be expressed as a mixture of possible emotions.