 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASR-Generated Text for Language Model Pre-training Applied to Speech Tasks
Jul 05, 2022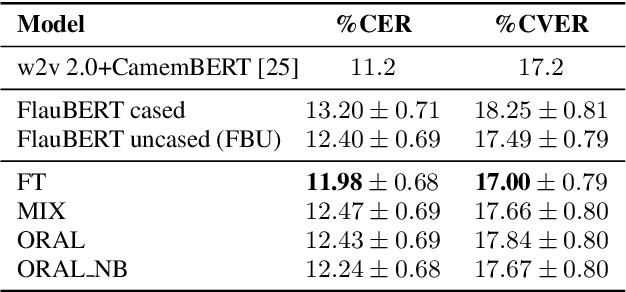
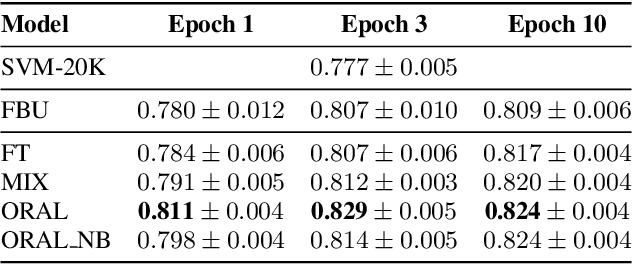
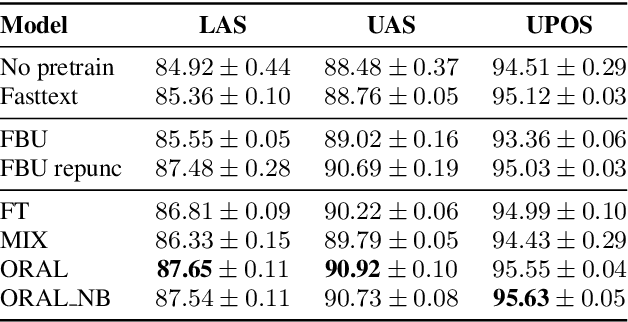
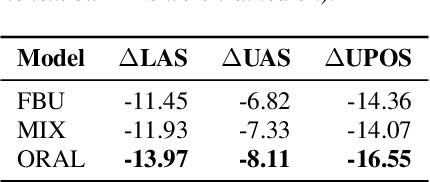
We aim at improving spoken language modeling (LM) using very large amount of automatically transcribed speech. We leverage the INA (French National Audiovisual Institute) collection and obtain 19GB of text after applying ASR on 350,000 hours of diverse TV shows. From this, spoken language models are trained either by fine-tuning an existing LM (FlauBERT) or through training a LM from scratch. New models (FlauBERT-Oral) are shared with the community and evaluated for 3 downstream tasks: spoken language understanding, classification of TV shows and speech syntactic parsing. Results show that FlauBERT-Oral can be beneficial compared to its initial FlauBERT version demonstrating that, despite its inherent noisy nature, ASR-generated text can be used to build spoken language models.
SAMU-XLSR: Semantically-Aligned Multimodal Utterance-level Cross-Lingual Speech Representation
May 17, 2022
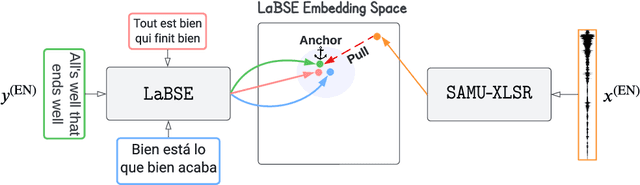
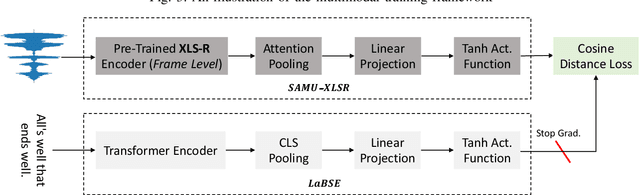
We propose the SAMU-XLSR: Semantically-Aligned Multimodal Utterance-level Cross-Lingual Speech Representation learning framework. Unlike previous works on speech representation learning, which learns multilingual contextual speech embedding at the resolution of an acoustic frame (10-20ms), this work focuses on learning multimodal (speech-text) multilingual speech embedding at the resolution of a sentence (5-10s) such that the embedding vector space is semantically aligned across different languages. We combine state-of-the-art multilingual acoustic frame-level speech representation learning model XLS-R with the Language Agnostic BERT Sentence Embedding (LaBSE) model to create an utterance-level multimodal multilingual speech encoder SAMU-XLSR. Although we train SAMU-XLSR with only multilingual transcribed speech data, cross-lingual speech-text and speech-speech associations emerge in its learned representation space. To substantiate our claims, we use SAMU-XLSR speech encoder in combination with a pre-trained LaBSE text sentence encoder for cross-lingual speech-to-text translation retrieval, and SAMU-XLSR alone for cross-lingual speech-to-speech translation retrieval. We highlight these applications by performing several cross-lingual text and speech translation retrieval tasks across several datasets.
ON-TRAC Consortium Systems for the IWSLT 2022 Dialect and Low-resource Speech Translation Tasks
May 04, 2022

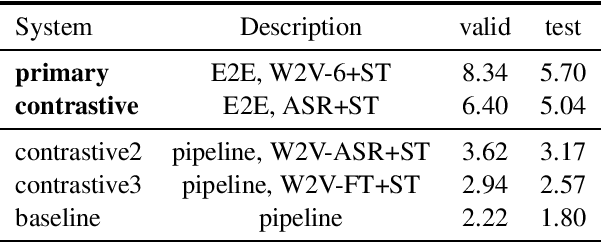

This paper describes the ON-TRAC Consortium translation systems developed for two challenge tracks featured in the Evaluation Campaign of IWSLT 2022: low-resource and dialect speech translation. For the Tunisian Arabic-English dataset (low-resource and dialect tracks), we build an end-to-end model as our joint primary submission, and compare it against cascaded models that leverage a large fine-tuned wav2vec 2.0 model for ASR. Our results show that in our settings pipeline approaches are still very competitive, and that with the use of transfer learning, they can outperform end-to-end models for speech translation (ST). For the Tamasheq-French dataset (low-resource track) our primary submission leverages intermediate representations from a wav2vec 2.0 model trained on 234 hours of Tamasheq audio, while our contrastive model uses a French phonetic transcription of the Tamasheq audio as input in a Conformer speech translation architecture jointly trained on automatic speech recognition, ST and machine translation losses. Our results highlight that self-supervised models trained on smaller sets of target data are more effective to low-resource end-to-end ST fine-tuning, compared to large off-the-shelf models. Results also illustrate that even approximate phonetic transcriptions can improve ST scores.
Magic dust for cross-lingual adaptation of monolingual wav2vec-2.0
Oct 07, 2021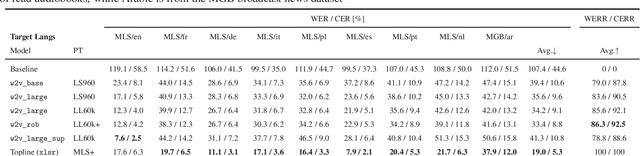
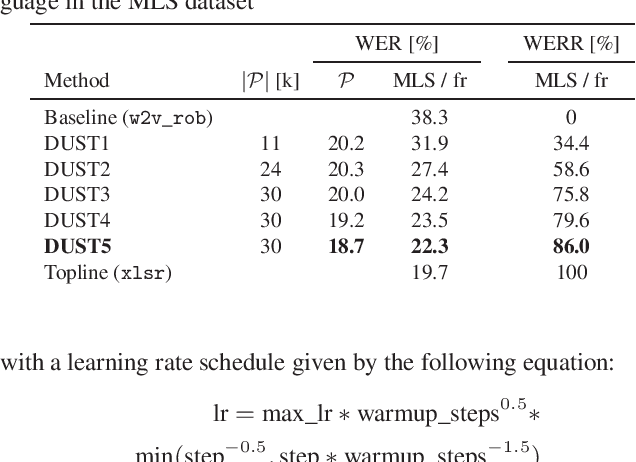
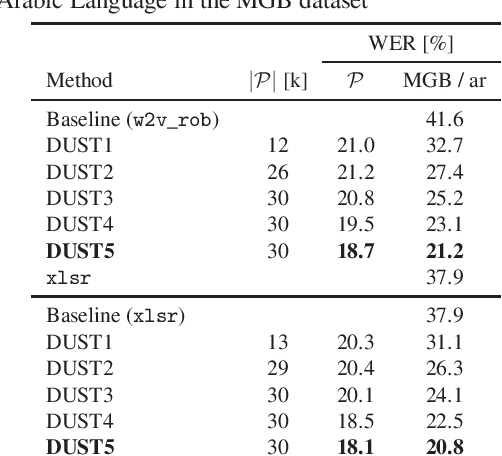
We propose a simple and effective cross-lingual transfer learning method to adapt monolingual wav2vec-2.0 models for Automatic Speech Recognition (ASR) in resource-scarce languages. We show that a monolingual wav2vec-2.0 is a good few-shot ASR learner in several languages. We improve its performance further via several iterations of Dropout Uncertainty-Driven Self-Training (DUST) by using a moderate-sized unlabeled speech dataset in the target language. A key finding of this work is that the adapted monolingual wav2vec-2.0 achieves similar performance as the topline multilingual XLSR model, which is trained on fifty-three languages, on the target language ASR task.
End-to-end speaker segmentation for overlap-aware resegmentation
Apr 08, 2021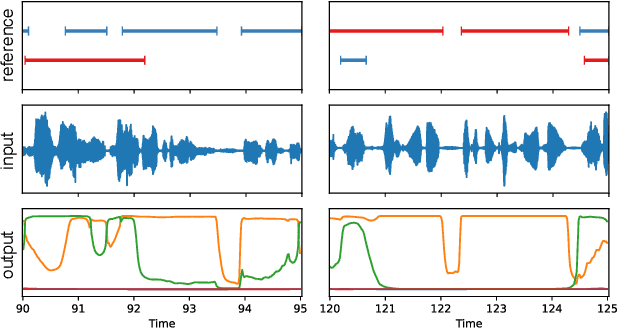
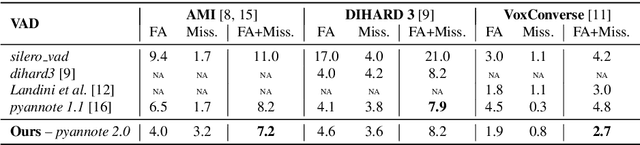
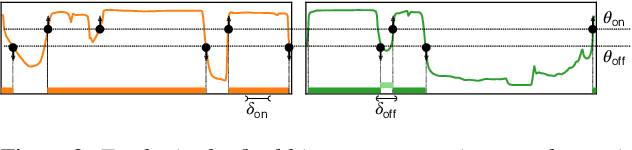

Speaker segmentation consists in partitioning a conversation between one or more speakers into speaker turns. Usually addressed as the late combination of three sub-tasks (voice activity detection, speaker change detection, and overlapped speech detection), we propose to train an end-to-end segmentation model that does it directly. Inspired by the original end-to-end neural speaker diarization approach (EEND), the task is modeled as a multi-label classification problem using permutation-invariant training. The main difference is that our model operates on short audio chunks (5 seconds) but at a much higher temporal resolution (every 16ms). Experiments on multiple speaker diarization datasets conclude that our model can be used with great success on both voice activity detection and overlapped speech detection. Our proposed model can also be used as a post-processing step, to detect and correctly assign overlapped speech regions. Relative diarization error rate improvement over the best considered baseline (VBx) reaches 18% on AMI, 17% on DIHARD 3, and 16% on VoxConverse.
End2End Acoustic to Semantic Transduction
Feb 01, 2021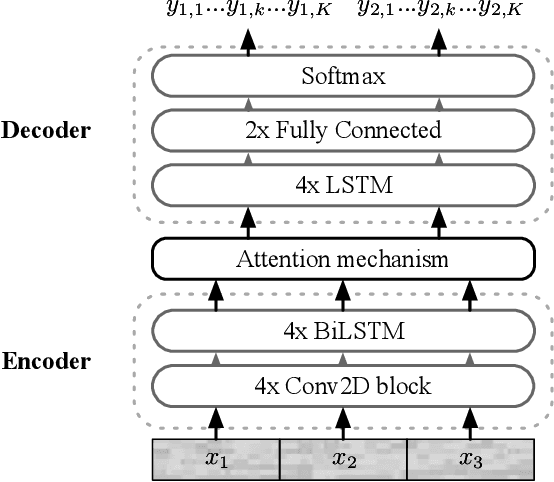

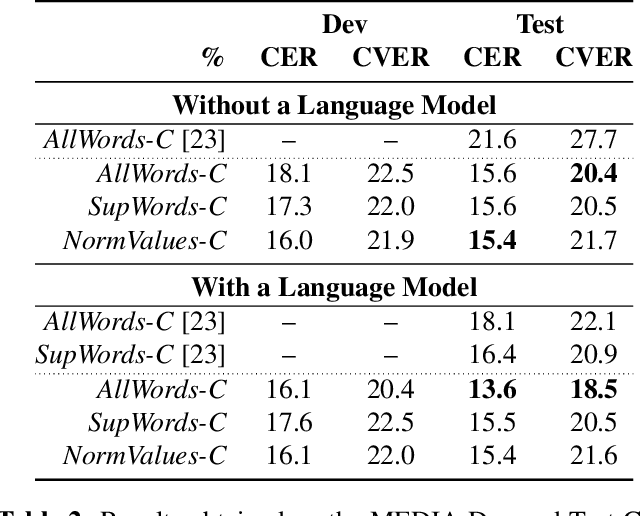
In this paper, we propose a novel end-to-end sequence-to-sequence spoken language understanding model using an attention mechanism. It reliably selects contextual acoustic features in order to hypothesize semantic contents. An initial architecture capable of extracting all pronounced words and concepts from acoustic spans is designed and tested. With a shallow fusion language model, this system reaches a 13.6 concept error rate (CER) and an 18.5 concept value error rate (CVER) on the French MEDIA corpus, achieving an absolute 2.8 points reduction compared to the state-of-the-art. Then, an original model is proposed for hypothesizing concepts and their values. This transduction reaches a 15.4 CER and a 21.6 CVER without any new type of context.
CSTNet: Contrastive Speech Translation Network for Self-Supervised Speech Representation Learning
Jun 04, 2020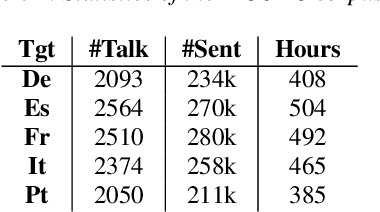
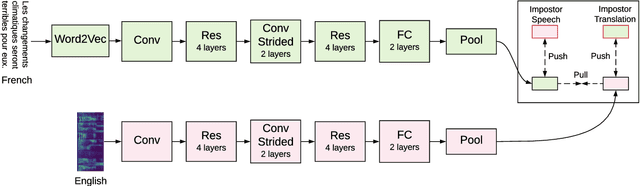
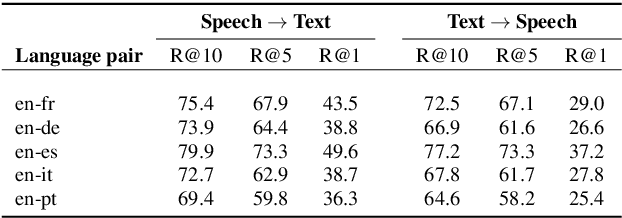
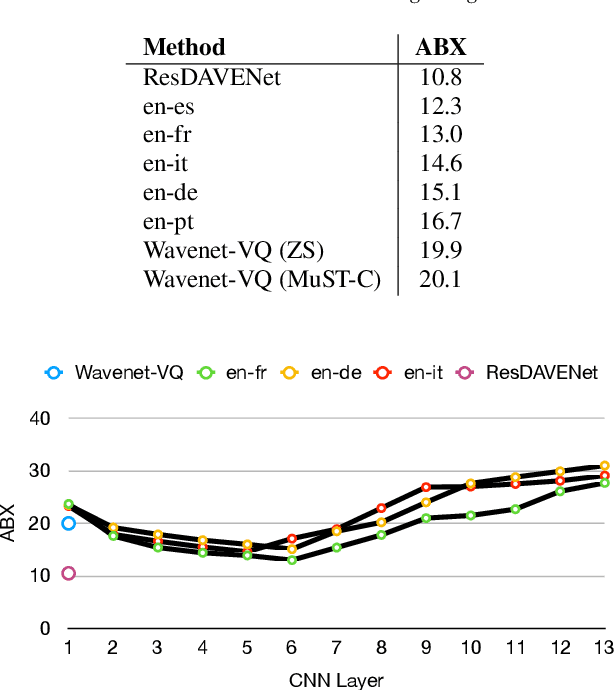
More than half of the 7,000 languages in the world are in imminent danger of going extinct. Traditional methods of documenting language proceed by collecting audio data followed by manual annotation by trained linguists at different levels of granularity. This time consuming and painstaking process could benefit from machine learning. Many endangered languages do not have any orthographic form but usually have speakers that are bi-lingual and trained in a high resource language. It is relatively easy to obtain textual translations corresponding to speech. In this work, we provide a multimodal machine learning framework for speech representation learning by exploiting the correlations between the two modalities namely speech and its corresponding text translation. Here, we construct a convolutional neural network audio encoder capable of extracting linguistic representations from speech. The audio encoder is trained to perform a speech-translation retrieval task in a contrastive learning framework. By evaluating the learned representations on a phone recognition task, we demonstrate that linguistic representations emerge in the audio encoder's internal representations as a by-product of learning to perform the retrieval task.
A Convolutional Deep Markov Model for Unsupervised Speech Representation Learning
Jun 03, 2020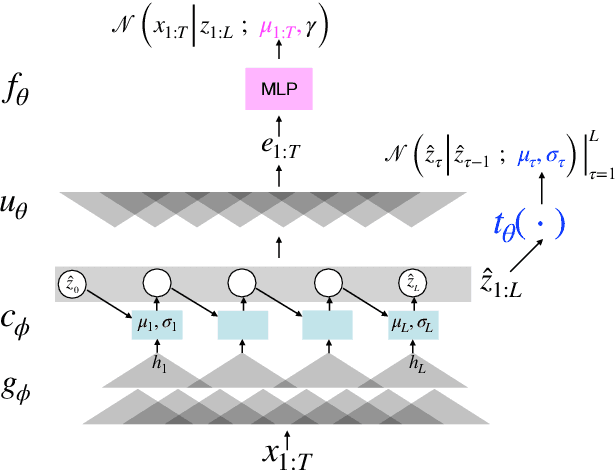
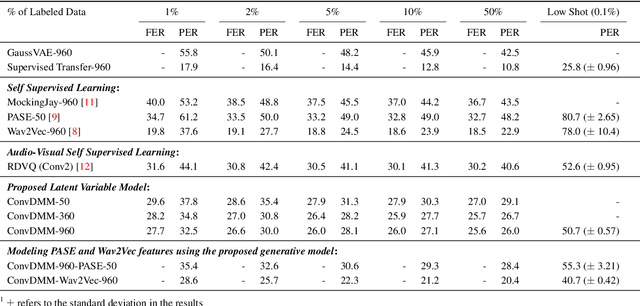
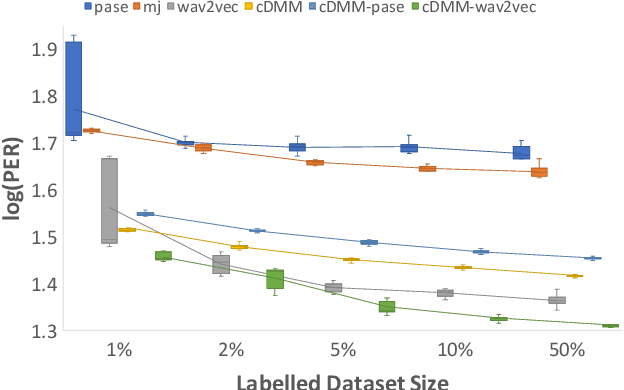
Probabilistic Latent Variable Models (LVMs) provide an alternative to self-supervised learning approaches for linguistic representation learning from speech. LVMs admit an intuitive probabilistic interpretation where the latent structure shapes the information extracted from the signal. Even though LVMs have recently seen a renewed interest due to the introduction of Variational Autoencoders (VAEs), their use for speech representation learning remains largely unexplored. In this work, we propose Convolutional Deep Markov Model (ConvDMM), a Gaussian state-space model with non-linear emission and transition functions modelled by deep neural networks. This unsupervised model is trained using black box variational inference. A deep convolutional neural network is used as an inference network for structured variational approximation. When trained on a large scale speech dataset (LibriSpeech), ConvDMM produces features that significantly outperform multiple self-supervised feature extracting methods on linear phone classification and recognition on the Wall Street Journal dataset. Furthermore, we found that ConvDMM complements self-supervised methods like Wav2Vec and PASE, improving on the results achieved with any of the methods alone. Lastly, we find that ConvDMM features enable learning better phone recognizers than any other features in an extreme low-resource regime with few labeled training examples.
Robust Training of Vector Quantized Bottleneck Models
May 18, 2020
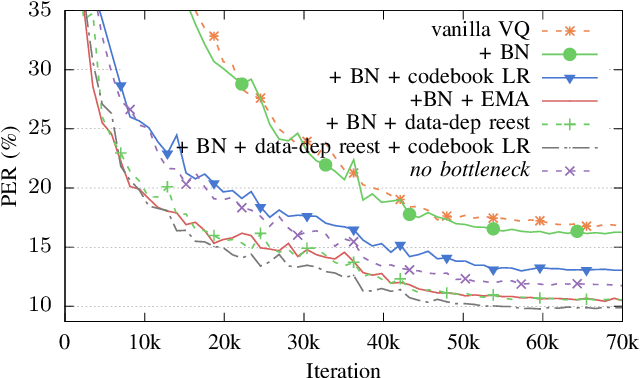
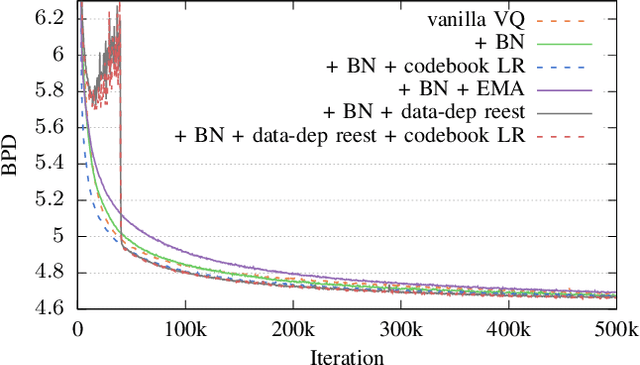

In this paper we demonstrate methods for reliable and efficient training of discrete representation using Vector-Quantized Variational Auto-Encoder models (VQ-VAEs). Discrete latent variable models have been shown to learn nontrivial representations of speech, applicable to unsupervised voice conversion and reaching state-of-the-art performance on unit discovery tasks. For unsupervised representation learning, they became viable alternatives to continuous latent variable models such as the Variational Auto-Encoder (VAE). However, training deep discrete variable models is challenging, due to the inherent non-differentiability of the discretization operation. In this paper we focus on VQ-VAE, a state-of-the-art discrete bottleneck model shown to perform on par with its continuous counterparts. It quantizes encoder outputs with on-line $k$-means clustering. We show that the codebook learning can suffer from poor initialization and non-stationarity of clustered encoder outputs. We demonstrate that these can be successfully overcome by increasing the learning rate for the codebook and periodic date-dependent codeword re-initialization. As a result, we achieve more robust training across different tasks, and significantly increase the usage of latent codewords even for large codebooks. This has practical benefit, for instance, in unsupervised representation learning, where large codebooks may lead to disentanglement of latent representations.
Recent Advances in End-to-End Spoken Language Understanding
Sep 29, 2019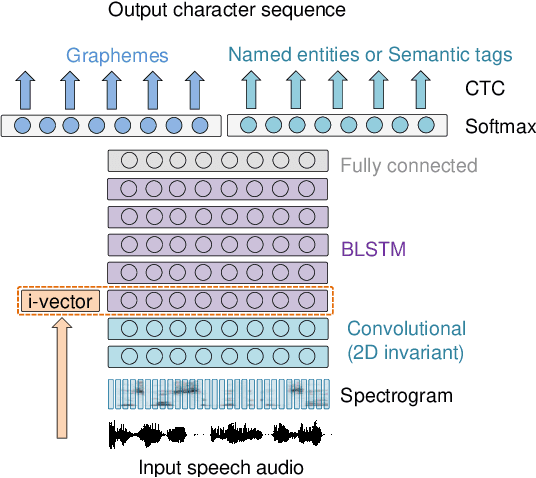
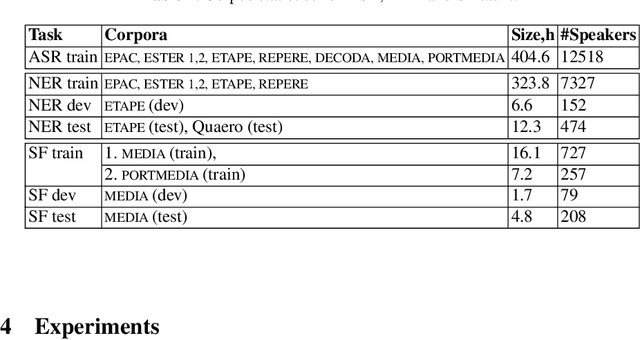
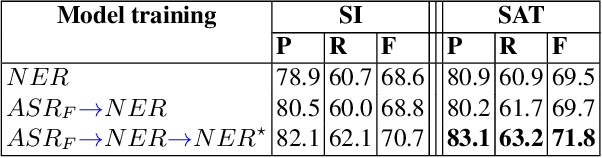
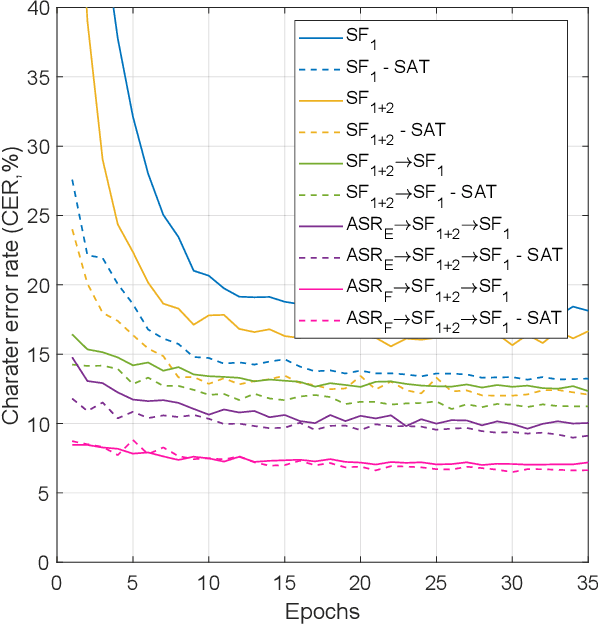
This work investigates spoken language understanding (SLU) systems in the scenario when the semantic information is extracted directly from the speech signal by means of a single end-to-end neural network model. Two SLU tasks are considered: named entity recognition (NER) and semantic slot filling (SF). For these tasks, in order to improve the model performance, we explore various techniques including speaker adaptation, a modification of the connectionist temporal classification (CTC) training criterion, and sequential pretraining.