 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Synthetic Oracle Datasets to Analyze Noise Impact: A Study on Building Function Classification Using Tweets
Mar 28, 2025


Tweets provides valuable semantic context for earth observation tasks and serves as a complementary modality to remote sensing imagery. In building function classification (BFC), tweets are often collected using geographic heuristics and labeled via external databases, an inherently weakly supervised process that introduces both label noise and sentence level feature noise (e.g., irrelevant or uninformative tweets). While label noise has been widely studied, the impact of sentence level feature noise remains underexplored, largely due to the lack of clean benchmark datasets for controlled analysis. In this work, we propose a method for generating a synthetic oracle dataset using LLM, designed to contain only tweets that are both correctly labeled and semantically relevant to their associated buildings. This oracle dataset enables systematic investigation of noise impacts that are otherwise difficult to isolate in real-world data. To assess its utility, we compare model performance using Naive Bayes and mBERT classifiers under three configurations: real vs. synthetic training data, and cross-domain generalization. Results show that noise in real tweets significantly degrades the contextual learning capacity of mBERT, reducing its performance to that of a simple keyword-based model. In contrast, the clean synthetic dataset allows mBERT to learn effectively, outperforming Naive Bayes Bayes by a large margin. These findings highlight that addressing feature noise is more critical than model complexity in this task. Our synthetic dataset offers a novel experimental environment for future noise injection studies and is publicly available on GitHub.
Musical ethnocentrism in Large Language Models
Jan 23, 2025Large Language Models (LLMs) reflect the biases in their training data and, by extension, those of the people who created this training data. Detecting, analyzing, and mitigating such biases is becoming a focus of research. One type of bias that has been understudied so far are geocultural biases. Those can be caused by an imbalance in the representation of different geographic regions and cultures in the training data, but also by value judgments contained therein. In this paper, we make a first step towards analyzing musical biases in LLMs, particularly ChatGPT and Mixtral. We conduct two experiments. In the first, we prompt LLMs to provide lists of the "Top 100" musical contributors of various categories and analyze their countries of origin. In the second experiment, we ask the LLMs to numerically rate various aspects of the musical cultures of different countries. Our results indicate a strong preference of the LLMs for Western music cultures in both experiments.
Harmonic Reasoning in Large Language Models
Sep 09, 2024Large Language Models (LLMs) are becoming very popular and are used for many different purposes, including creative tasks in the arts. However, these models sometimes have trouble with specific reasoning tasks, especially those that involve logical thinking and counting. This paper looks at how well LLMs understand and reason when dealing with musical tasks like figuring out notes from intervals and identifying chords and scales. We tested GPT-3.5 and GPT-4o to see how they handle these tasks. Our results show that while LLMs do well with note intervals, they struggle with more complicated tasks like recognizing chords and scales. This points out clear limits in current LLM abilities and shows where we need to make them better, which could help improve how they think and work in both artistic and other complex areas. We also provide an automatically generated benchmark data set for the described tasks.
Joint sentiment analysis of lyrics and audio in music
May 03, 2024



Sentiment or mood can express themselves on various levels in music. In automatic analysis, the actual audio data is usually analyzed, but the lyrics can also play a crucial role in the perception of moods. We first evaluate various models for sentiment analysis based on lyrics and audio separately. The corresponding approaches already show satisfactory results, but they also exhibit weaknesses, the causes of which we examine in more detail. Furthermore, different approaches to combining the audio and lyrics results are proposed and evaluated. Considering both modalities generally leads to improved performance. We investigate misclassifications and (also intentional) contradictions between audio and lyrics sentiment more closely, and identify possible causes. Finally, we address fundamental problems in this research area, such as high subjectivity, lack of data, and inconsistency in emotion taxonomies.
Towards detecting unanticipated bias in Large Language Models
Apr 03, 2024Over the last year, Large Language Models (LLMs) like ChatGPT have become widely available and have exhibited fairness issues similar to those in previous machine learning systems. Current research is primarily focused on analyzing and quantifying these biases in training data and their impact on the decisions of these models, alongside developing mitigation strategies. This research largely targets well-known biases related to gender, race, ethnicity, and language. However, it is clear that LLMs are also affected by other, less obvious implicit biases. The complex and often opaque nature of these models makes detecting such biases challenging, yet this is crucial due to their potential negative impact in various applications. In this paper, we explore new avenues for detecting these unanticipated biases in LLMs, focusing specifically on Uncertainty Quantification and Explainable AI methods. These approaches aim to assess the certainty of model decisions and to make the internal decision-making processes of LLMs more transparent, thereby identifying and understanding biases that are not immediately apparent. Through this research, we aim to contribute to the development of fairer and more transparent AI systems.
More than words: Advancements and challenges in speech recognition for singing
Mar 14, 2024This paper addresses the challenges and advancements in speech recognition for singing, a domain distinctly different from standard speech recognition. Singing encompasses unique challenges, including extensive pitch variations, diverse vocal styles, and background music interference. We explore key areas such as phoneme recognition, language identification in songs, keyword spotting, and full lyrics transcription. I will describe some of my own experiences when performing research on these tasks just as they were starting to gain traction, but will also show how recent developments in deep learning and large-scale datasets have propelled progress in this field. My goal is to illuminate the complexities of applying speech recognition to singing, evaluate current capabilities, and outline future research directions.
Towards Large-scale Building Attribute Mapping using Crowdsourced Images: Scene Text Recognition on Flickr and Problems to be Solved
Sep 14, 2023



Crowdsourced platforms provide huge amounts of street-view images that contain valuable building information. This work addresses the challenges in applying Scene Text Recognition (STR) in crowdsourced street-view images for building attribute mapping. We use Flickr images, particularly examining texts on building facades. A Berlin Flickr dataset is created, and pre-trained STR models are used for text detection and recognition. Manual checking on a subset of STR-recognized images demonstrates high accuracy. We examined the correlation between STR results and building functions, and analysed instances where texts were recognized on residential buildings but not on commercial ones. Further investigation revealed significant challenges associated with this task, including small text regions in street-view images, the absence of ground truth labels, and mismatches in buildings in Flickr images and building footprints in OpenStreetMap (OSM). To develop city-wide mapping beyond urban hotspot locations, we suggest differentiating the scenarios where STR proves effective while developing appropriate algorithms or bringing in additional data for handling other cases. Furthermore, interdisciplinary collaboration should be undertaken to understand the motivation behind building photography and labeling. The STR-on-Flickr results are publicly available at https://github.com/ya0-sun/STR-Berlin.
Geo-Information Harvesting from Social Media Data
Nov 01, 2022As unconventional sources of geo-information, massive imagery and text messages from open platforms and social media form a temporally quasi-seamless, spatially multi-perspective stream, but with unknown and diverse quality. Due to its complementarity to remote sensing data, geo-information from these sources offers promising perspectives, but harvesting is not trivial due to its data characteristics. In this article, we address key aspects in the field, including data availability, analysis-ready data preparation and data management, geo-information extraction from social media text messages and images, and the fusion of social media and remote sensing data. We then showcase some exemplary geographic applications. In addition, we present the first extensive discussion of ethical considerations of social media data in the context of geo-information harvesting and geographic applications. With this effort, we wish to stimulate curiosity and lay the groundwork for researchers who intend to explore social media data for geo-applications. We encourage the community to join forces by sharing their code and data.
A Survey of Uncertainty in Deep Neural Networks
Jul 07, 2021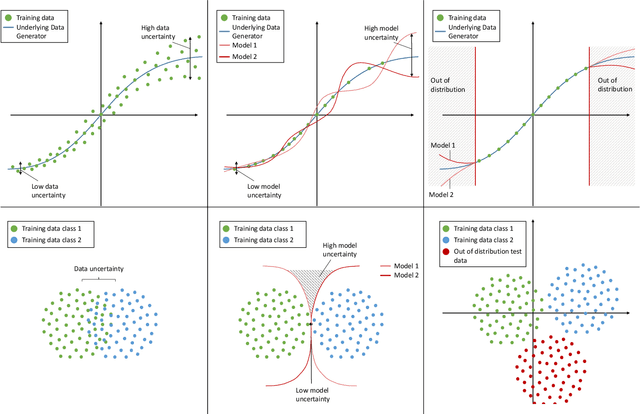
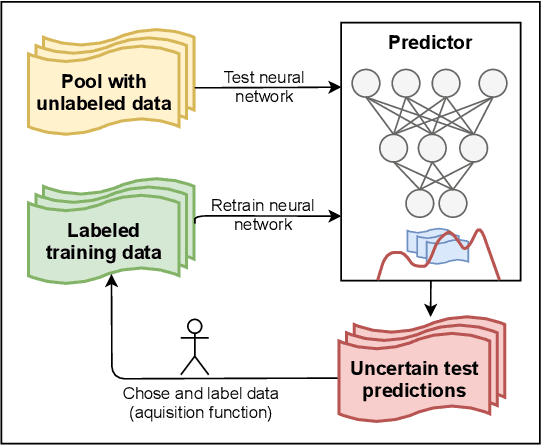
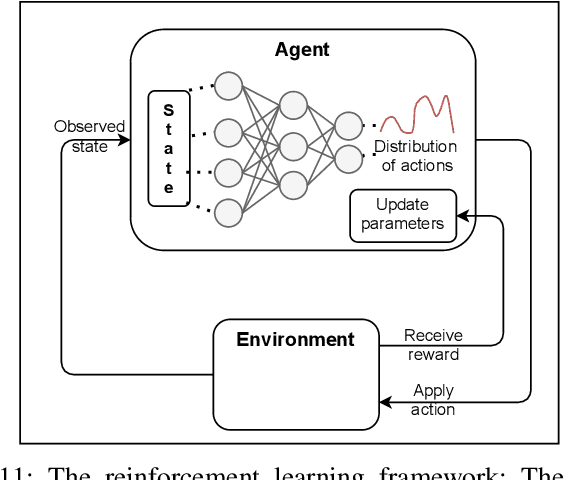
Due to their increasing spread, confidence in neural network predictions became more and more important. However, basic neural networks do not deliver certainty estimates or suffer from over or under confidence. Many researchers have been working on understanding and quantifying uncertainty in a neural network's prediction. As a result, different types and sources of uncertainty have been identified and a variety of approaches to measure and quantify uncertainty in neural networks have been proposed. This work gives a comprehensive overview of uncertainty estimation in neural networks, reviews recent advances in the field, highlights current challenges, and identifies potential research opportunities. It is intended to give anyone interested in uncertainty estimation in neural networks a broad overview and introduction, without presupposing prior knowledge in this field. A comprehensive introduction to the most crucial sources of uncertainty is given and their separation into reducible model uncertainty and not reducible data uncertainty is presented. The modeling of these uncertainties based on deterministic neural networks, Bayesian neural networks, ensemble of neural networks, and test-time data augmentation approaches is introduced and different branches of these fields as well as the latest developments are discussed. For a practical application, we discuss different measures of uncertainty, approaches for the calibration of neural networks and give an overview of existing baselines and implementations. Different examples from the wide spectrum of challenges in different fields give an idea of the needs and challenges regarding uncertainties in practical applications. Additionally, the practical limitations of current methods for mission- and safety-critical real world applications are discussed and an outlook on the next steps towards a broader usage of such methods is given.
Out-of-distribution detection in satellite image classification
Apr 09, 2021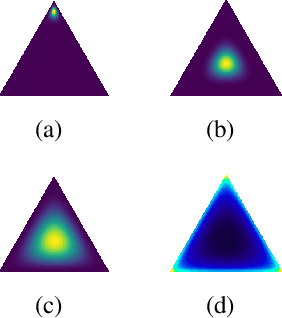
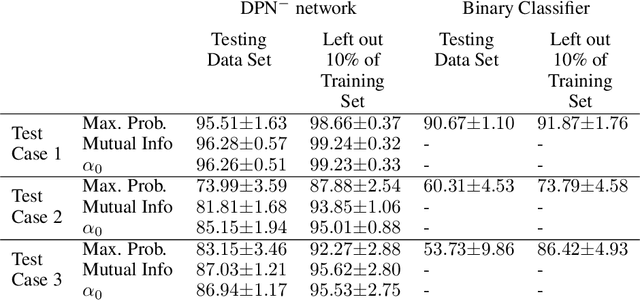
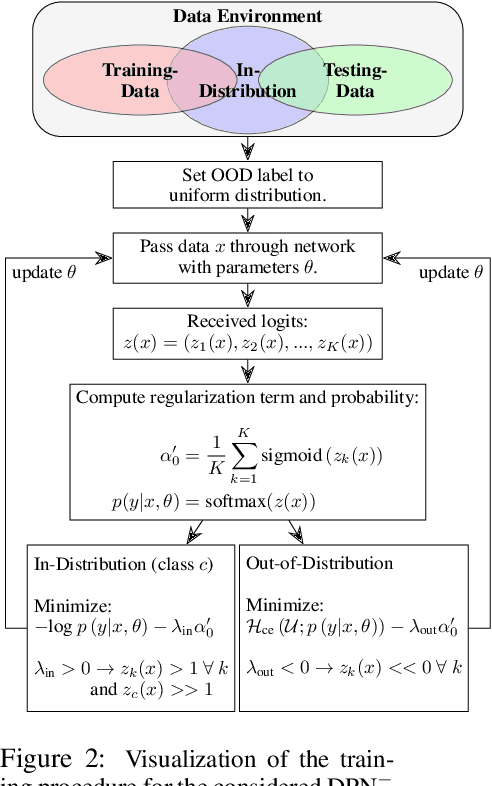

In satellite image analysis, distributional mismatch between the training and test data may arise due to several reasons, including unseen classes in the test data and differences in the geographic area. Deep learning based models may behave in unexpected manner when subjected to test data that has such distributional shifts from the training data, also called out-of-distribution (OOD) examples. Predictive uncertainly analysis is an emerging research topic which has not been explored much in context of satellite image analysis. Towards this, we adopt a Dirichlet Prior Network based model to quantify distributional uncertainty of deep learning models for remote sensing. The approach seeks to maximize the representation gap between the in-domain and OOD examples for a better identification of unknown examples at test time. Experimental results on three exemplary test scenarios show the efficacy of the model in satellite image analysis.