 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWM-DAgger: Enabling Efficient Data Aggregation for Imitation Learning with World Models
Apr 13, 2026Imitation learning is a powerful paradigm for training robotic policies, yet its performance is limited by compounding errors: minor policy inaccuracies could drive robots into unseen out-of-distribution (OOD) states in the training set, where the policy could generate even bigger errors, leading to eventual failures. While the Data Aggregation (DAgger) framework tries to address this issue, its reliance on continuous human involvement severely limits scalability. In this paper, we propose WM-DAgger, an efficient data aggregation framework that leverages World Models to synthesize OOD recovery data without requiring human involvement. Specifically, we focus on manipulation tasks with an eye-in-hand robotic arm and only few-shot demonstrations. To avoid synthesizing misleading data and overcome the hallucination issues inherent to World Models, our framework introduces two key mechanisms: (1) a Corrective Action Synthesis Module that generates task-oriented recovery actions to prevent misleading supervision, and (2) a Consistency-Guided Filtering Module that discards physically implausible trajectories by anchoring terminal synthesized frames to corresponding real frames in expert demonstrations. We extensively validate WM-DAgger on multiple real-world robotic tasks. Results that our method significantly improves success rates, achieving a 93.3\% success rate in soft bag pushing with only five demonstrations. The source code is publicly available at https://github.com/czs12354-xxdbd/WM-Dagger.
FedSC: Provable Federated Self-supervised Learning with Spectral Contrastive Objective over Non-i.i.d. Data
May 07, 2024Recent efforts have been made to integrate self-supervised learning (SSL) with the framework of federated learning (FL). One unique challenge of federated self-supervised learning (FedSSL) is that the global objective of FedSSL usually does not equal the weighted sum of local SSL objectives. Consequently, conventional approaches, such as federated averaging (FedAvg), fail to precisely minimize the FedSSL global objective, often resulting in suboptimal performance, especially when data is non-i.i.d.. To fill this gap, we propose a provable FedSSL algorithm, named FedSC, based on the spectral contrastive objective. In FedSC, clients share correlation matrices of data representations in addition to model weights periodically, which enables inter-client contrast of data samples in addition to intra-client contrast and contraction, resulting in improved quality of data representations. Differential privacy (DP) protection is deployed to control the additional privacy leakage on local datasets when correlation matrices are shared. We also provide theoretical analysis on the convergence and extra privacy leakage. The experimental results validate the effectiveness of our proposed algorithm.
Inference with Hybrid Bio-hardware Neural Networks
May 28, 2019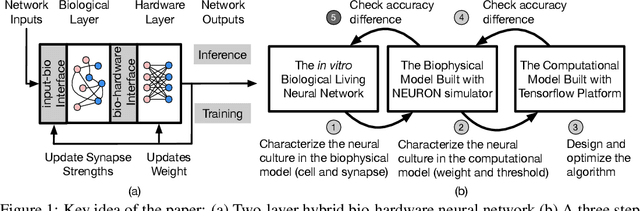
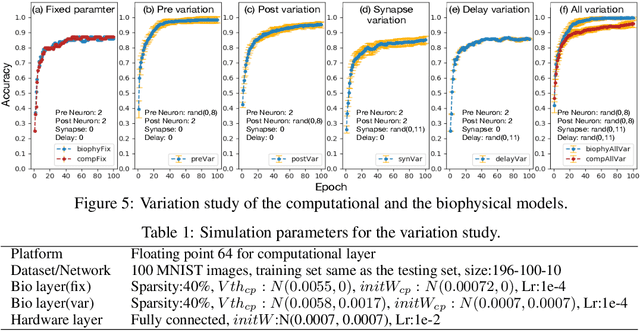

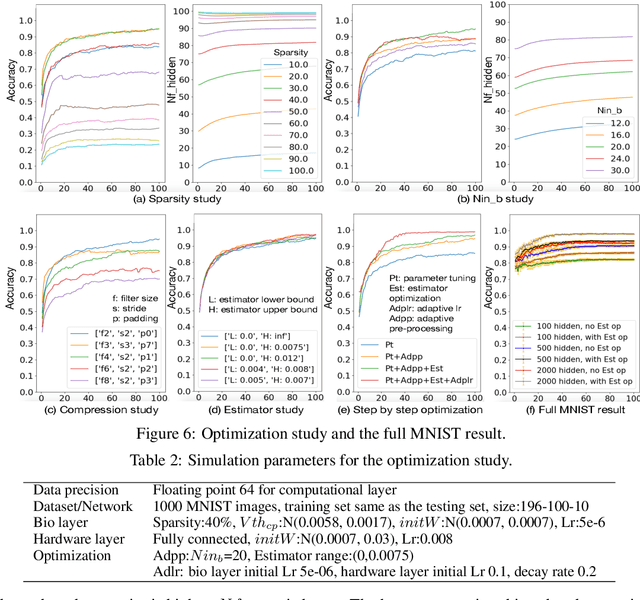
To understand the learning process in brains, biologically plausible algorithms have been explored by modeling the detailed neuron properties and dynamics. On the other hand, simplified multi-layer models of neural networks have shown great success on computational tasks such as image classification and speech recognition. However, the computational models that can achieve good accuracy for these learning applications are very different from the bio-plausible models. This paper studies whether a bio-plausible model of a in vitro living neural network can be used to perform machine learning tasks and achieve good inference accuracy. A novel two-layer bio-hardware hybrid neural network is proposed. The biological layer faithfully models variations of synapses, neurons, and network sparsity in in vitro living neural networks. The hardware layer is a computational fully-connected layer that tunes parameters to optimize for accuracy. Several techniques are proposed to improve the inference accuracy of the proposed hybrid neural network. For instance, an adaptive pre-processing technique helps the proposed neural network to achieve good learning accuracy for different living neural network sparsity. The proposed hybrid neural network with realistic neuron parameters and variations achieves a 98.3% testing accuracy for the handwritten digit recognition task on the full MNIST dataset.