 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding the Enigma: Benchmarking Humans and AIs on the Many Facets of Working Memory
Jul 20, 2023



Working memory (WM), a fundamental cognitive process facilitating the temporary storage, integration, manipulation, and retrieval of information, plays a vital role in reasoning and decision-making tasks. Robust benchmark datasets that capture the multifaceted nature of WM are crucial for the effective development and evaluation of AI WM models. Here, we introduce a comprehensive Working Memory (WorM) benchmark dataset for this purpose. WorM comprises 10 tasks and a total of 1 million trials, assessing 4 functionalities, 3 domains, and 11 behavioral and neural characteristics of WM. We jointly trained and tested state-of-the-art recurrent neural networks and transformers on all these tasks. We also include human behavioral benchmarks as an upper bound for comparison. Our results suggest that AI models replicate some characteristics of WM in the brain, most notably primacy and recency effects, and neural clusters and correlates specialized for different domains and functionalities of WM. In the experiments, we also reveal some limitations in existing models to approximate human behavior. This dataset serves as a valuable resource for communities in cognitive psychology, neuroscience, and AI, offering a standardized framework to compare and enhance WM models, investigate WM's neural underpinnings, and develop WM models with human-like capabilities. Our source code and data are available at https://github.com/ZhangLab-DeepNeuroCogLab/WorM.
Learning to Learn: How to Continuously Teach Humans and Machines
Nov 28, 2022



Our education system comprises a series of curricula. For example, when we learn mathematics at school, we learn in order from addition, to multiplication, and later to integration. Delineating a curriculum for teaching either a human or a machine shares the underlying goal of maximizing the positive knowledge transfer from early to later tasks and minimizing forgetting of the early tasks. Here, we exhaustively surveyed the effect of curricula on existing continual learning algorithms in the class-incremental setting, where algorithms must learn classes one at a time from a continuous stream of data. We observed that across a breadth of possible class orders (curricula), curricula influence the retention of information and that this effect is not just a product of stochasticity. Further, as a primary effort toward automated curriculum design, we proposed a method capable of designing and ranking effective curricula based on inter-class feature similarities. We compared the predicted curricula against empirically determined effectual curricula and observed significant overlaps between the two. To support the study of a curriculum designer, we conducted a series of human psychophysics experiments and contributed a new Continual Learning benchmark in object recognition. We assessed the degree of agreement in effective curricula between humans and machines. Surprisingly, our curriculum designer successfully predicts an optimal set of curricula that is effective for human learning. There are many considerations in curriculum design, such as timely student feedback and learning with multiple modalities. Our study is the first attempt to set a standard framework for the community to tackle the problem of teaching humans and machines to learn to learn continuously.
Reason from Context with Self-supervised Learning
Nov 23, 2022



A tiny object in the sky cannot be an elephant. Context reasoning is critical in visual recognition, where current inputs need to be interpreted in the light of previous experience and knowledge. To date, research into contextual reasoning in visual recognition has largely proceeded with supervised learning methods. The question of whether contextual knowledge can be captured with self-supervised learning regimes remains under-explored. Here, we established a methodology for context-aware self-supervised learning. We proposed a novel Self-supervised Learning Method for Context Reasoning (SeCo), where the only inputs to SeCo are unlabeled images with multiple objects present in natural scenes. Similar to the distinction between fovea and periphery in human vision, SeCo processes self-proposed target object regions and their contexts separately, and then employs a learnable external memory for retrieving and updating context-relevant target information. To evaluate the contextual associations learned by the computational models, we introduced two evaluation protocols, lift-the-flap and object priming, addressing the problems of "what" and "where" in context reasoning. In both tasks, SeCo outperformed all state-of-the-art (SOTA) self-supervised learning methods by a significant margin. Our network analysis revealed that the external memory in SeCo learns to store prior contextual knowledge, facilitating target identity inference in lift-the-flap task. Moreover, we conducted psychophysics experiments and introduced a Human benchmark in Object Priming dataset (HOP). Our quantitative and qualitative results demonstrate that SeCo approximates human-level performance and exhibits human-like behavior. All our source code and data are publicly available here.
Human or Machine? Turing Tests for Vision and Language
Nov 23, 2022As AI algorithms increasingly participate in daily activities that used to be the sole province of humans, we are inevitably called upon to consider how much machines are really like us. To address this question, we turn to the Turing test and systematically benchmark current AIs in their abilities to imitate humans. We establish a methodology to evaluate humans versus machines in Turing-like tests and systematically evaluate a representative set of selected domains, parameters, and variables. The experiments involved testing 769 human agents, 24 state-of-the-art AI agents, 896 human judges, and 8 AI judges, in 21,570 Turing tests across 6 tasks encompassing vision and language modalities. Surprisingly, the results reveal that current AIs are not far from being able to impersonate human judges across different ages, genders, and educational levels in complex visual and language challenges. In contrast, simple AI judges outperform human judges in distinguishing human answers versus machine answers. The curated large-scale Turing test datasets introduced here and their evaluation metrics provide valuable insights to assess whether an agent is human or not. The proposed formulation to benchmark human imitation ability in current AIs paves a way for the research community to expand Turing tests to other research areas and conditions. All of source code and data are publicly available at https://tinyurl.com/8x8nha7p
When Can Transformers Ground and Compose: Insights from Compositional Generalization Benchmarks
Oct 31, 2022Humans can reason compositionally whilst grounding language utterances to the real world. Recent benchmarks like ReaSCAN use navigation tasks grounded in a grid world to assess whether neural models exhibit similar capabilities. In this work, we present a simple transformer-based model that outperforms specialized architectures on ReaSCAN and a modified version of gSCAN. On analyzing the task, we find that identifying the target location in the grid world is the main challenge for the models. Furthermore, we show that a particular split in ReaSCAN, which tests depth generalization, is unfair. On an amended version of this split, we show that transformers can generalize to deeper input structures. Finally, we design a simpler grounded compositional generalization task, RefEx, to investigate how transformers reason compositionally. We show that a single self-attention layer with a single head generalizes to novel combinations of object attributes. Moreover, we derive a precise mathematical construction of the transformer's computations from the learned network. Overall, we provide valuable insights about the grounded compositional generalization task and the behaviour of transformers on it, which would be useful for researchers working in this area.
On the Efficacy of Co-Attention Transformer Layers in Visual Question Answering
Jan 11, 2022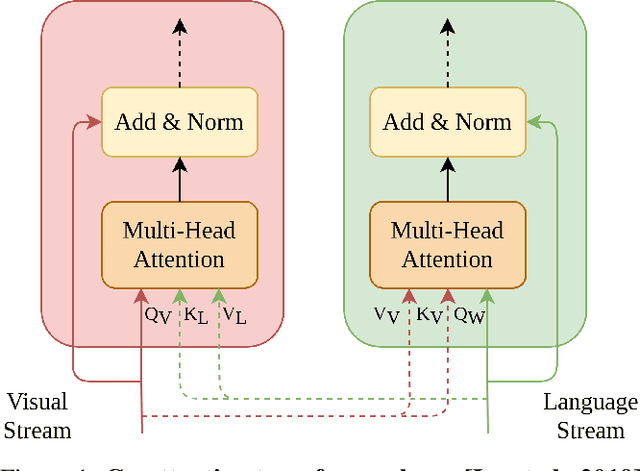

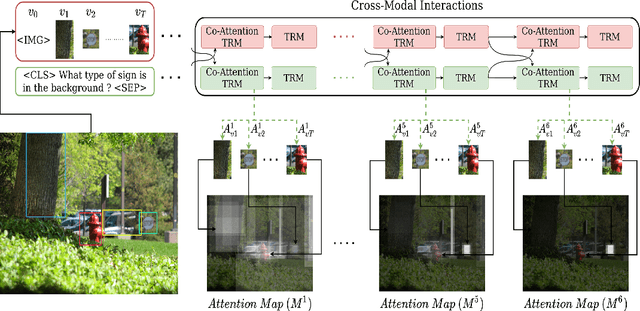

In recent years, multi-modal transformers have shown significant progress in Vision-Language tasks, such as Visual Question Answering (VQA), outperforming previous architectures by a considerable margin. This improvement in VQA is often attributed to the rich interactions between vision and language streams. In this work, we investigate the efficacy of co-attention transformer layers in helping the network focus on relevant regions while answering the question. We generate visual attention maps using the question-conditioned image attention scores in these co-attention layers. We evaluate the effect of the following critical components on visual attention of a state-of-the-art VQA model: (i) number of object region proposals, (ii) question part of speech (POS) tags, (iii) question semantics, (iv) number of co-attention layers, and (v) answer accuracy. We compare the neural network attention maps against human attention maps both qualitatively and quantitatively. Our findings indicate that co-attention transformer modules are crucial in attending to relevant regions of the image given a question. Importantly, we observe that the semantic meaning of the question is not what drives visual attention, but specific keywords in the question do. Our work sheds light on the function and interpretation of co-attention transformer layers, highlights gaps in current networks, and can guide the development of future VQA models and networks that simultaneously process visual and language streams.