 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCycleDRUMS: Automatic Drum Arrangement For Bass Lines Using CycleGAN
Apr 09, 2021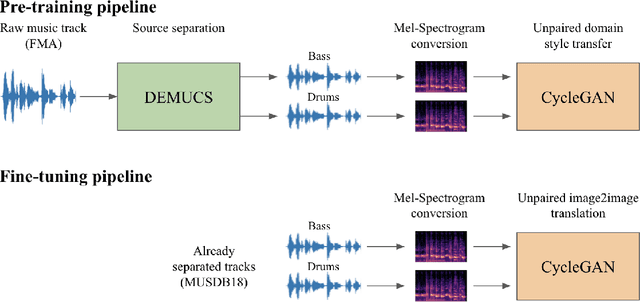
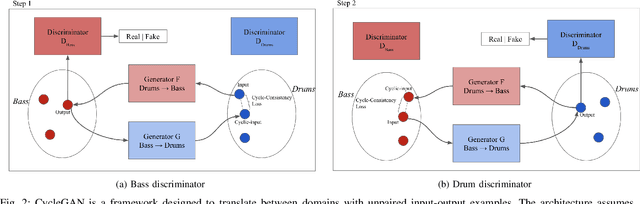
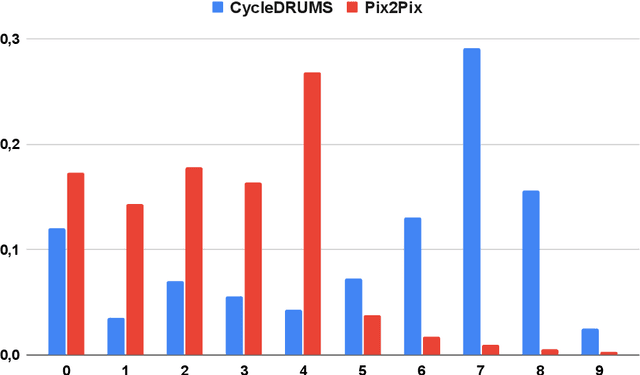
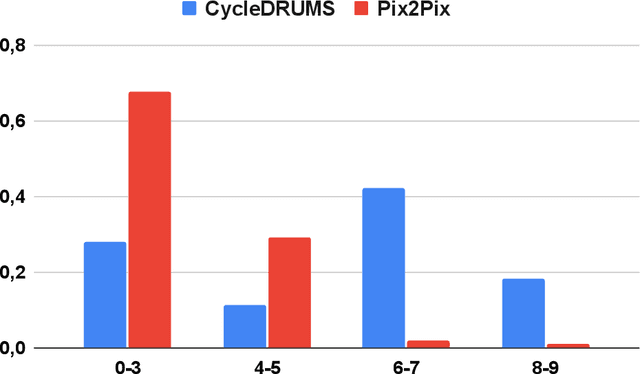
The two main research threads in computer-based music generation are: the construction of autonomous music-making systems, and the design of computer-based environments to assist musicians. In the symbolic domain, the key problem of automatically arranging a piece music was extensively studied, while relatively fewer systems tackled this challenge in the audio domain. In this contribution, we propose CycleDRUMS, a novel method for generating drums given a bass line. After converting the waveform of the bass into a mel-spectrogram, we are able to automatically generate original drums that follow the beat, sound credible and can be directly mixed with the input bass. We formulated this task as an unpaired image-to-image translation problem, and we addressed it with CycleGAN, a well-established unsupervised style transfer framework, originally designed for treating images. The choice to deploy raw audio and mel-spectrograms enabled us to better represent how humans perceive music, and to potentially draw sounds for new arrangements from the vast collection of music recordings accumulated in the last century. In absence of an objective way of evaluating the output of both generative adversarial networks and music generative systems, we further defined a possible metric for the proposed task, partially based on human (and expert) judgement. Finally, as a comparison, we replicated our results with Pix2Pix, a paired image-to-image translation network, and we showed that our approach outperforms it.
Human Evaluation of Spoken vs. Visual Explanations for Open-Domain QA
Dec 30, 2020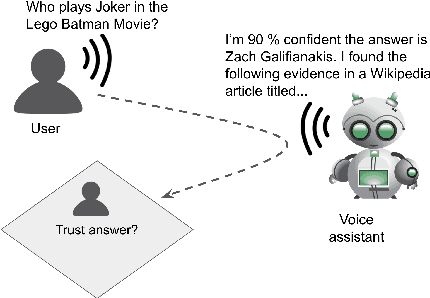
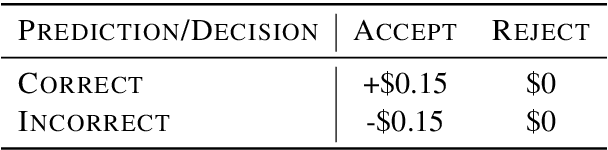


While research on explaining predictions of open-domain QA systems (ODQA) to users is gaining momentum, most works have failed to evaluate the extent to which explanations improve user trust. While few works evaluate explanations using user studies, they employ settings that may deviate from the end-user's usage in-the-wild: ODQA is most ubiquitous in voice-assistants, yet current research only evaluates explanations using a visual display, and may erroneously extrapolate conclusions about the most performant explanations to other modalities. To alleviate these issues, we conduct user studies that measure whether explanations help users correctly decide when to accept or reject an ODQA system's answer. Unlike prior work, we control for explanation modality, e.g., whether they are communicated to users through a spoken or visual interface, and contrast effectiveness across modalities. Our results show that explanations derived from retrieved evidence passages can outperform strong baselines (calibrated confidence) across modalities but the best explanation strategy in fact changes with the modality. We show common failure cases of current explanations, emphasize end-to-end evaluation of explanations, and caution against evaluating them in proxy modalities that are different from deployment.
Facebook AI's WMT20 News Translation Task Submission
Nov 16, 2020

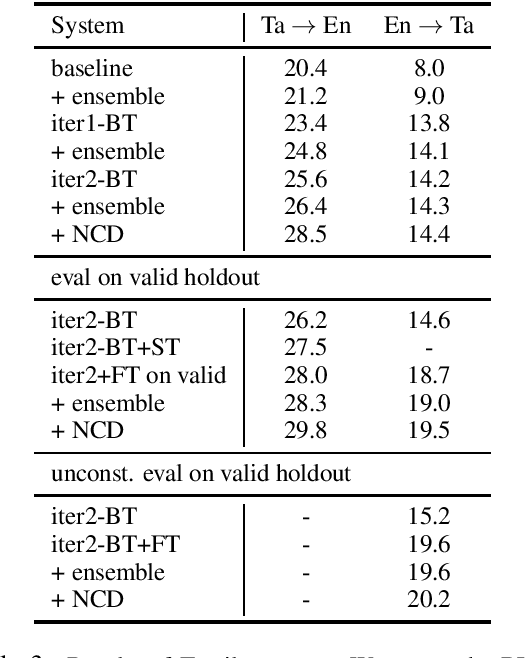
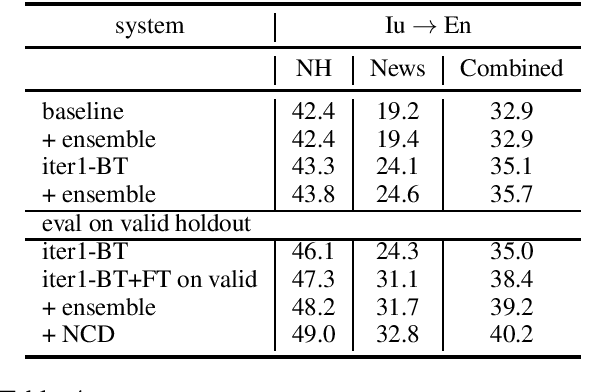
This paper describes Facebook AI's submission to WMT20 shared news translation task. We focus on the low resource setting and participate in two language pairs, Tamil <-> English and Inuktitut <-> English, where there are limited out-of-domain bitext and monolingual data. We approach the low resource problem using two main strategies, leveraging all available data and adapting the system to the target news domain. We explore techniques that leverage bitext and monolingual data from all languages, such as self-supervised model pretraining, multilingual models, data augmentation, and reranking. To better adapt the translation system to the test domain, we explore dataset tagging and fine-tuning on in-domain data. We observe that different techniques provide varied improvements based on the available data of the language pair. Based on the finding, we integrate these techniques into one training pipeline. For En->Ta, we explore an unconstrained setup with additional Tamil bitext and monolingual data and show that further improvement can be obtained. On the test set, our best submitted systems achieve 21.5 and 13.7 BLEU for Ta->En and En->Ta respectively, and 27.9 and 13.0 for Iu->En and En->Iu respectively.
Generating Fact Checking Briefs
Nov 10, 2020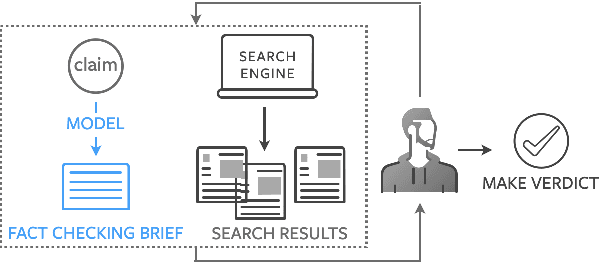
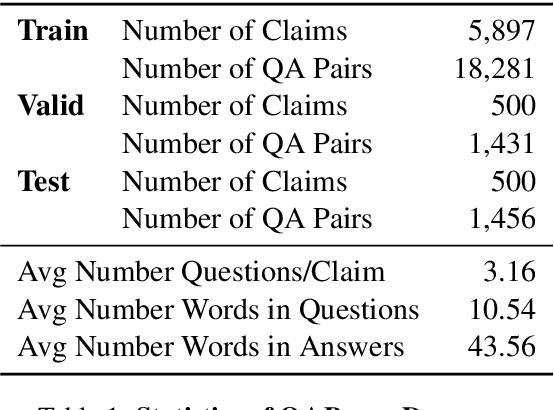

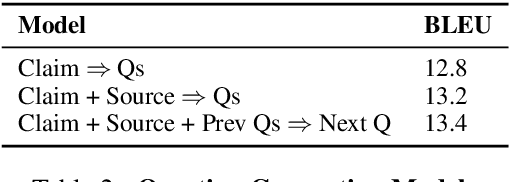
Fact checking at scale is difficult -- while the number of active fact checking websites is growing, it remains too small for the needs of the contemporary media ecosystem. However, despite good intentions, contributions from volunteers are often error-prone, and thus in practice restricted to claim detection. We investigate how to increase the accuracy and efficiency of fact checking by providing information about the claim before performing the check, in the form of natural language briefs. We investigate passage-based briefs, containing a relevant passage from Wikipedia, entity-centric ones consisting of Wikipedia pages of mentioned entities, and Question-Answering Briefs, with questions decomposing the claim, and their answers. To produce QABriefs, we develop QABriefer, a model that generates a set of questions conditioned on the claim, searches the web for evidence, and generates answers. To train its components, we introduce QABriefDataset which we collected via crowdsourcing. We show that fact checking with briefs -- in particular QABriefs -- increases the accuracy of crowdworkers by 10% while slightly decreasing the time taken. For volunteer (unpaid) fact checkers, QABriefs slightly increase accuracy and reduce the time required by around 20%.
Multilingual AMR-to-Text Generation
Nov 10, 2020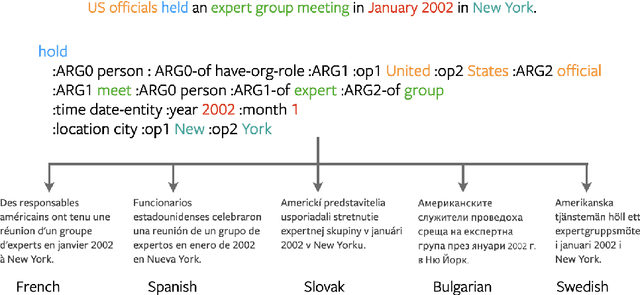
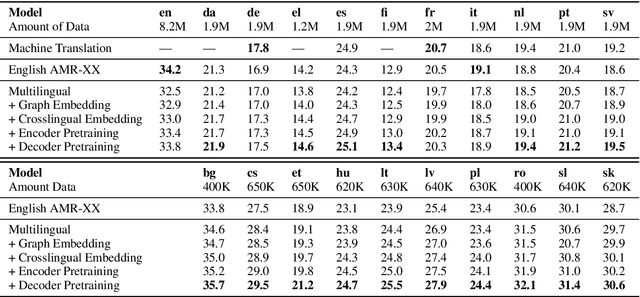
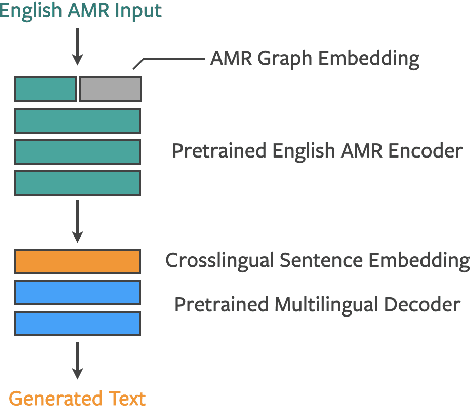
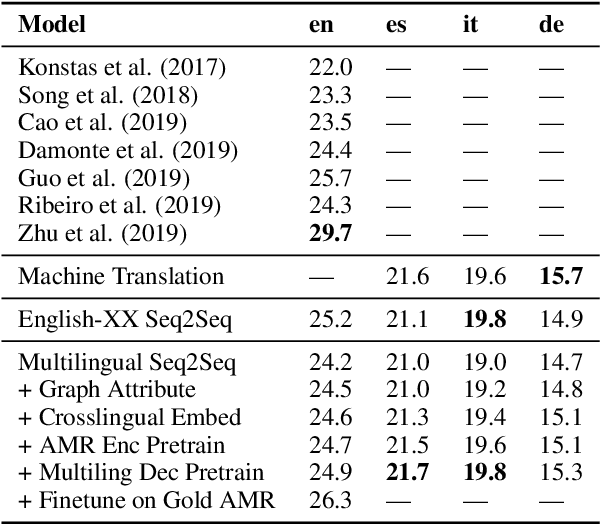
Generating text from structured data is challenging because it requires bridging the gap between (i) structure and natural language (NL) and (ii) semantically underspecified input and fully specified NL output. Multilingual generation brings in an additional challenge: that of generating into languages with varied word order and morphological properties. In this work, we focus on Abstract Meaning Representations (AMRs) as structured input, where previous research has overwhelmingly focused on generating only into English. We leverage advances in cross-lingual embeddings, pretraining, and multilingual models to create multilingual AMR-to-text models that generate in twenty one different languages. For eighteen languages, based on automatic metrics, our multilingual models surpass baselines that generate into a single language. We analyse the ability of our multilingual models to accurately capture morphology and word order using human evaluation, and find that native speakers judge our generations to be fluent.
Beyond English-Centric Multilingual Machine Translation
Oct 21, 2020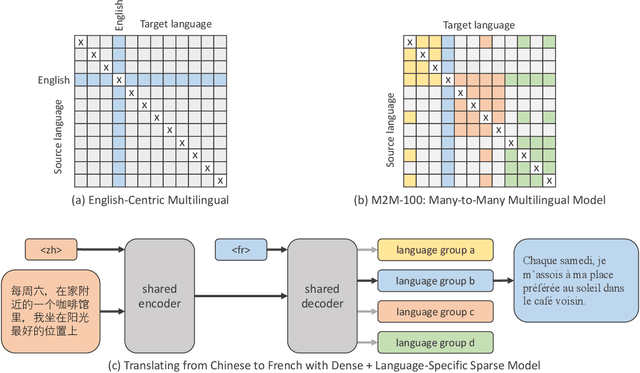
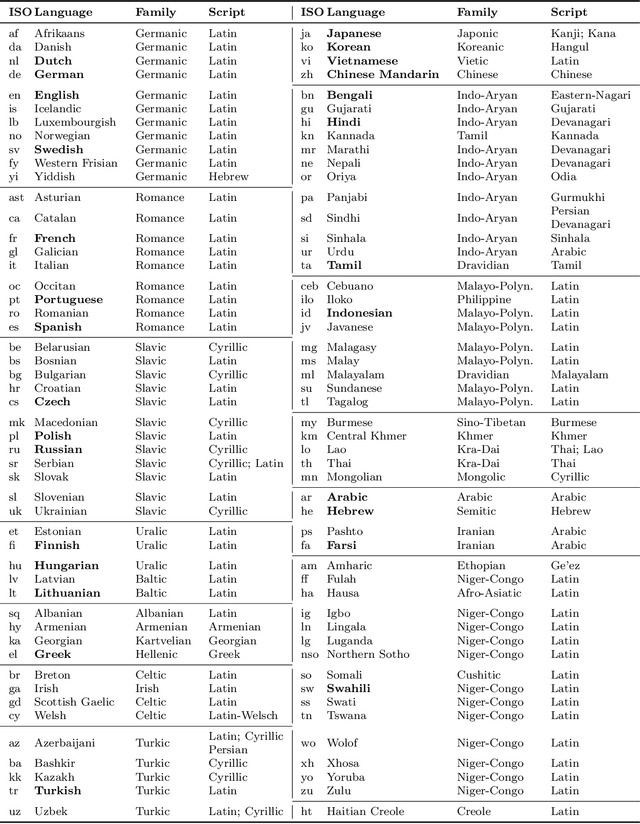
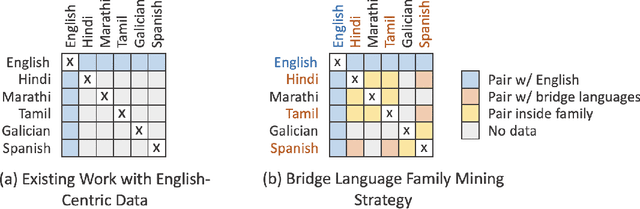

Existing work in translation demonstrated the potential of massively multilingual machine translation by training a single model able to translate between any pair of languages. However, much of this work is English-Centric by training only on data which was translated from or to English. While this is supported by large sources of training data, it does not reflect translation needs worldwide. In this work, we create a true Many-to-Many multilingual translation model that can translate directly between any pair of 100 languages. We build and open source a training dataset that covers thousands of language directions with supervised data, created through large-scale mining. Then, we explore how to effectively increase model capacity through a combination of dense scaling and language-specific sparse parameters to create high quality models. Our focus on non-English-Centric models brings gains of more than 10 BLEU when directly translating between non-English directions while performing competitively to the best single systems of WMT. We open-source our scripts so that others may reproduce the data, evaluation, and final M2M-100 model.
Nearest Neighbor Machine Translation
Oct 01, 2020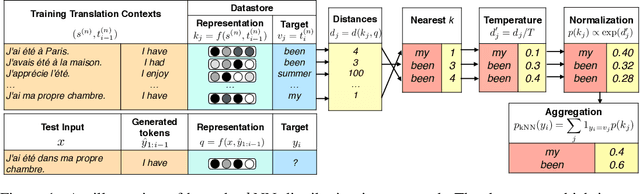
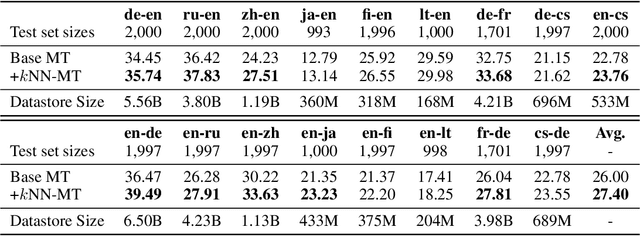
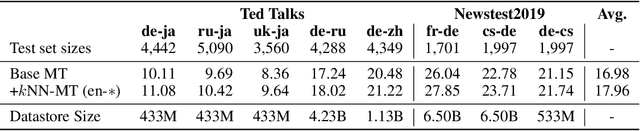
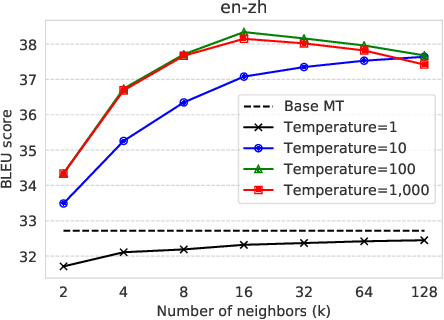
We introduce $k$-nearest-neighbor machine translation ($k$NN-MT), which predicts tokens with a nearest neighbor classifier over a large datastore of cached examples, using representations from a neural translation model for similarity search. This approach requires no additional training and scales to give the decoder direct access to billions of examples at test time, resulting in a highly expressive model that consistently improves performance across many settings. Simply adding nearest neighbor search improves a state-of-the-art German-English translation model by 1.5 BLEU. $k$NN-MT allows a single model to be adapted to diverse domains by using a domain-specific datastore, improving results by an average of 9.2 BLEU over zero-shot transfer, and achieving new state-of-the-art results---without training on these domains. A massively multilingual model can also be specialized for particular language pairs, with improvements of 3 BLEU for translating from English into German and Chinese. Qualitatively, $k$NN-MT is easily interpretable; it combines source and target context to retrieve highly relevant examples.
KILT: a Benchmark for Knowledge Intensive Language Tasks
Sep 04, 2020
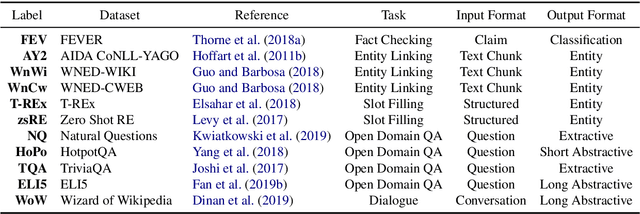
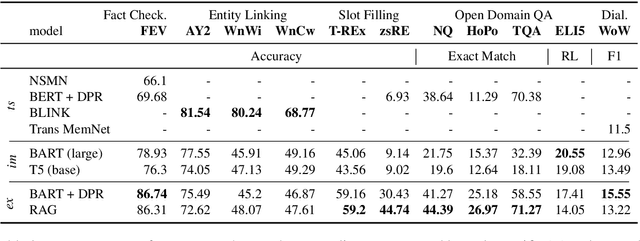
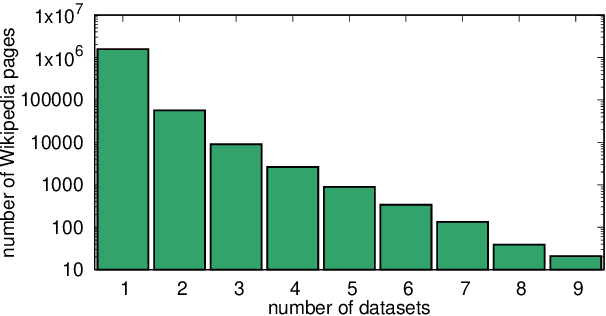
Challenging problems such as open-domain question answering, fact checking, slot filling and entity linking require access to large, external knowledge sources. While some models do well on individual tasks, developing general models is difficult as each task might require computationally expensive indexing of custom knowledge sources, in addition to dedicated infrastructure. To catalyze research on models that condition on specific information in large textual resources, we present a benchmark for knowledge-intensive language tasks (KILT). All tasks in KILT are grounded in the same snapshot of Wikipedia, reducing engineering turnaround through the re-use of components, as well as accelerating research into task-agnostic memory architectures. We test both task-specific and general baselines, evaluating downstream performance in addition to the ability of the models to provide provenance. We find that a shared dense vector index coupled with a seq2seq model is a strong baseline, outperforming more tailor-made approaches for fact checking, open-domain question answering and dialogue, and yielding competitive results on entity linking and slot filling, by generating disambiguated text. KILT data and code are available at https://github.com/facebookresearch/KILT.
Multilingual Translation with Extensible Multilingual Pretraining and Finetuning
Aug 02, 2020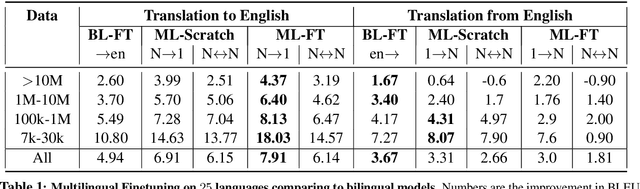
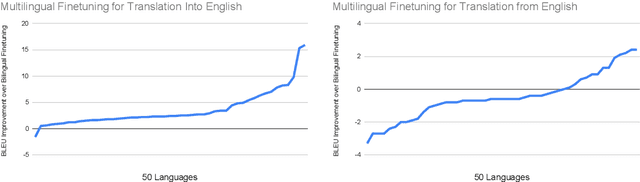
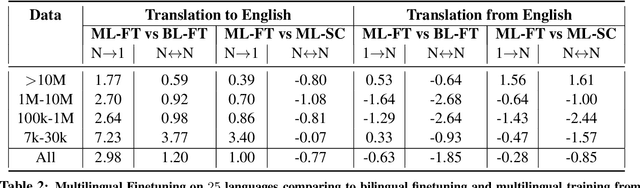
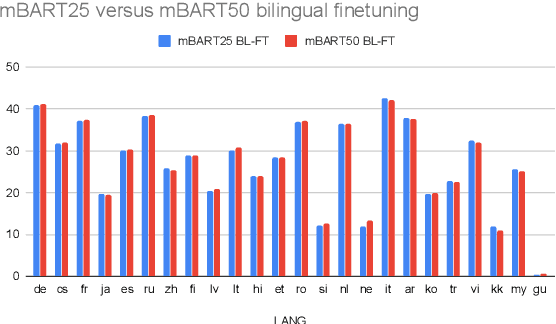
Recent work demonstrates the potential of multilingual pretraining of creating one model that can be used for various tasks in different languages. Previous work in multilingual pretraining has demonstrated that machine translation systems can be created by finetuning on bitext. In this work, we show that multilingual translation models can be created through multilingual finetuning. Instead of finetuning on one direction, a pretrained model is finetuned on many directions at the same time. Compared to multilingual models trained from scratch, starting from pretrained models incorporates the benefits of large quantities of unlabeled monolingual data, which is particularly important for low resource languages where bitext is not available. We demonstrate that pretrained models can be extended to incorporate additional languages without loss of performance. We double the number of languages in mBART to support multilingual machine translation models of 50 languages. Finally, we create the ML50 benchmark, covering low, mid, and high resource languages, to facilitate reproducible research by standardizing training and evaluation data. On ML50, we demonstrate that multilingual finetuning improves on average 1 BLEU over the strongest baselines (being either multilingual from scratch or bilingual finetuning) while improving 9.3 BLEU on average over bilingual baselines from scratch.
Open-Domain Conversational Agents: Current Progress, Open Problems, and Future Directions
Jul 13, 2020We present our view of what is necessary to build an engaging open-domain conversational agent: covering the qualities of such an agent, the pieces of the puzzle that have been built so far, and the gaping holes we have not filled yet. We present a biased view, focusing on work done by our own group, while citing related work in each area. In particular, we discuss in detail the properties of continual learning, providing engaging content, and being well-behaved -- and how to measure success in providing them. We end with a discussion of our experience and learnings, and our recommendations to the community.