 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in Translation: Loss and Decay of Linguistic Richness in Machine Translation
Jun 28, 2019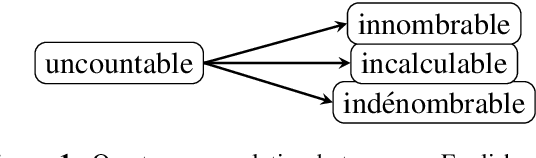
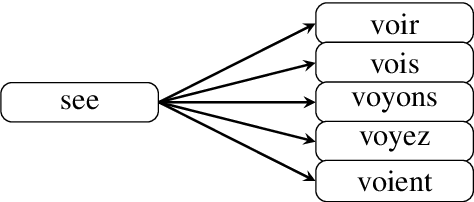
This work presents an empirical approach to quantifying the loss of lexical richness in Machine Translation (MT) systems compared to Human Translation (HT). Our experiments show how current MT systems indeed fail to render the lexical diversity of human generated or translated text. The inability of MT systems to generate diverse outputs and its tendency to exacerbate already frequent patterns while ignoring less frequent ones, might be the underlying cause for, among others, the currently heavily debated issues related to gender biased output. Can we indeed, aside from biased data, talk about an algorithm that exacerbates seen biases?
Adaptation of Machine Translation Models with Back-translated Data using Transductive Data Selection Methods
Jun 18, 2019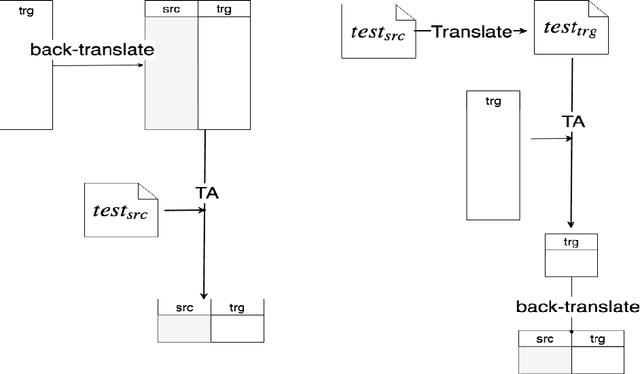

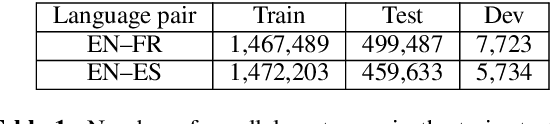
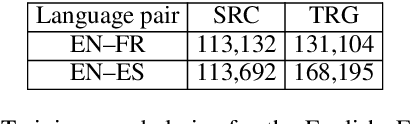
Data selection has proven its merit for improving Neural Machine Translation (NMT), when applied to authentic data. But the benefit of using synthetic data in NMT training, produced by the popular back-translation technique, raises the question if data selection could also be useful for synthetic data? In this work we use Infrequent N-gram Recovery (INR) and Feature Decay Algorithms (FDA), two transductive data selection methods to obtain subsets of sentences from synthetic data. These methods ensure that selected sentences share n-grams with the test set so the NMT model can be adapted to translate it. Performing data selection on back-translated data creates new challenges as the source-side may contain noise originated by the model used in the back-translation. Hence, finding n-grams present in the test set become more difficult. Despite that, in our work we show that adapting a model with a selection of synthetic data is an useful approach.
No Padding Please: Efficient Neural Handwriting Recognition
Feb 28, 2019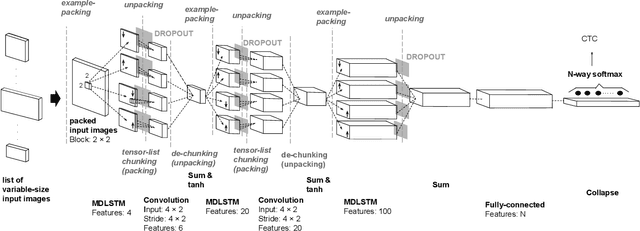
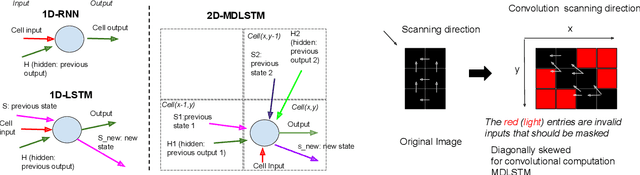
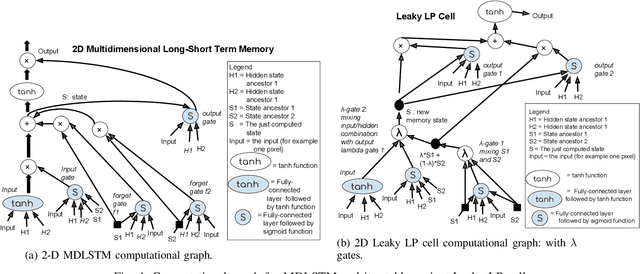
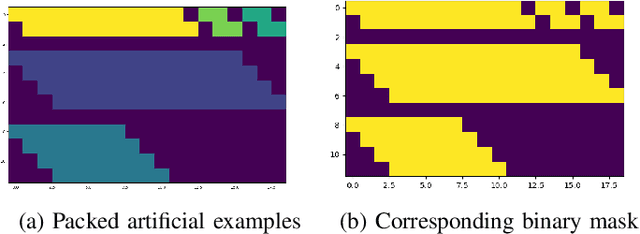
Neural handwriting recognition (NHR) is the recognition of handwritten text with deep learning models, such as multi-dimensional long short-term memory (MDLSTM) recurrent neural networks. Models with MDLSTM layers have achieved state-of-the art results on handwritten text recognition tasks. While multi-directional MDLSTM-layers have an unbeaten ability to capture the complete context in all directions, this strength limits the possibilities for parallelization, and therefore comes at a high computational cost. In this work we develop methods to create efficient MDLSTM-based models for NHR, particularly a method aimed at eliminating computation waste that results from padding. This proposed method, called example-packing, replaces wasteful stacking of padded examples with efficient tiling in a 2-dimensional grid. For word-based NHR this yields a speed improvement of factor 6.6 over an already efficient baseline of minimal padding for each batch separately. For line-based NHR the savings are more modest, but still significant. In addition to example-packing, we propose: 1) a technique to optimize parallelization for dynamic graph definition frameworks including PyTorch, using convolutions with grouping, 2) a method for parallelization across GPUs for variable-length example batches. All our techniques are thoroughly tested on our own PyTorch re-implementation of MDLSTM-based NHR models. A thorough evaluation on the IAM dataset shows that our models are performing similar to earlier implementations of state-of-the-art models. Our efficient NHR model and some of the reusable techniques discussed with it offer ways to realize relatively efficient models for the omnipresent scenario of variable-length inputs in deep learning.
ABI Neural Ensemble Model for Gender Prediction Adapt Bar-Ilan Submission for the CLIN29 Shared Task on Gender Prediction
Feb 23, 2019

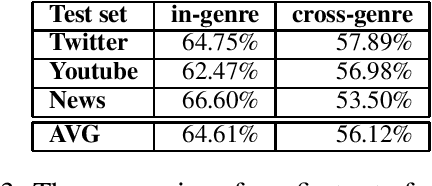
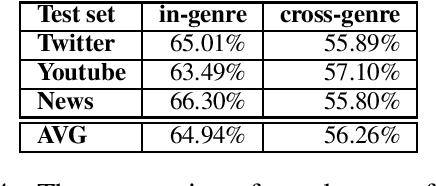
We present our system for the CLIN29 shared task on cross-genre gender detection for Dutch. We experimented with a multitude of neural models (CNN, RNN, LSTM, etc.), more "traditional" models (SVM, RF, LogReg, etc.), different feature sets as well as data pre-processing. The final results suggested that using tokenized, non-lowercased data works best for most of the neural models, while a combination of word clusters, character trigrams and word lists showed to be most beneficial for the majority of the more "traditional" (that is, non-neural) models, beating features used in previous tasks such as n-grams, character n-grams, part-of-speech tags and combinations thereof. In contradiction with the results described in previous comparable shared tasks, our neural models performed better than our best traditional approaches with our best feature set-up. Our final model consisted of a weighted ensemble model combining the top 25 models. Our final model won both the in-domain gender prediction task and the cross-genre challenge, achieving an average accuracy of 64.93% on the in-domain gender prediction task, and 56.26% on cross-genre gender prediction.
The ADAPT System Description for the IWSLT 2018 Basque to English Translation Task
Nov 14, 2018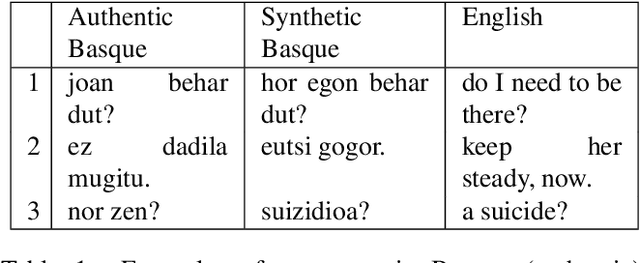
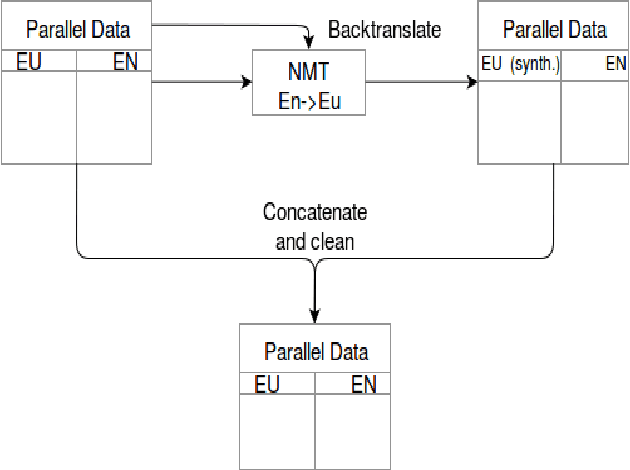
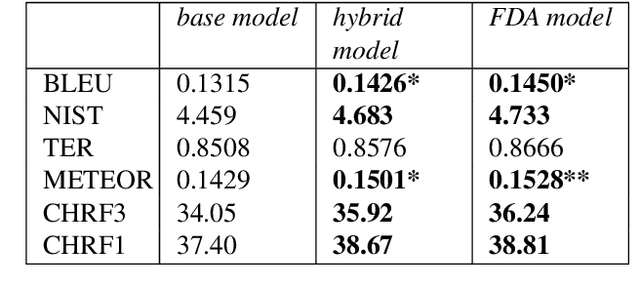
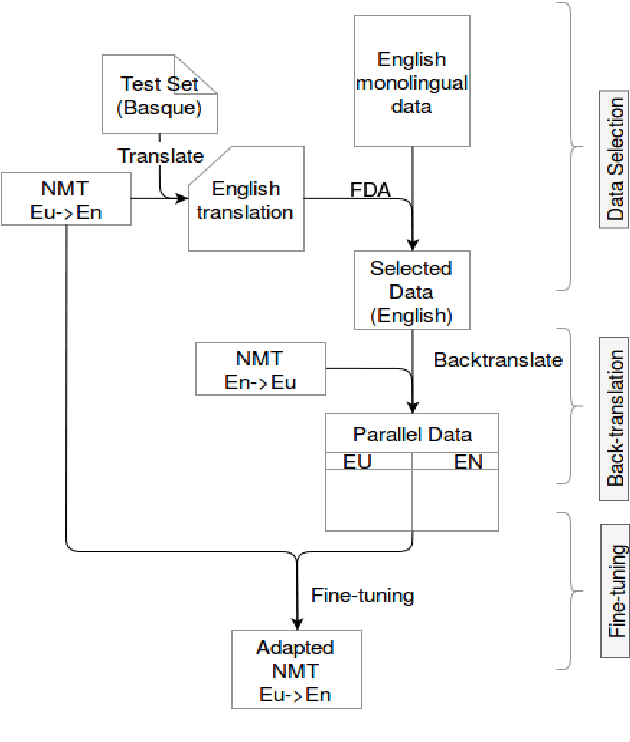
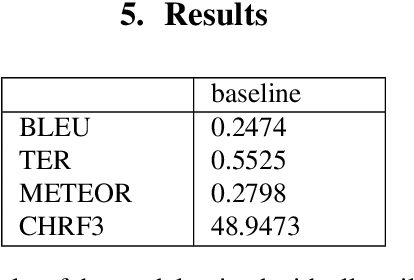
In this paper we present the ADAPT system built for the Basque to English Low Resource MT Evaluation Campaign. Basque is a low-resourced, morphologically-rich language. This poses a challenge for Neural Machine Translation models which usually achieve better performance when trained with large sets of data. Accordingly, we used synthetic data to improve the translation quality produced by a model built using only authentic data. Our proposal uses back-translated data to: (a) create new sentences, so the system can be trained with more data; and (b) translate sentences that are close to the test set, so the model can be fine-tuned to the document to be translated.
Data Selection with Feature Decay Algorithms Using an Approximated Target Side
Nov 07, 2018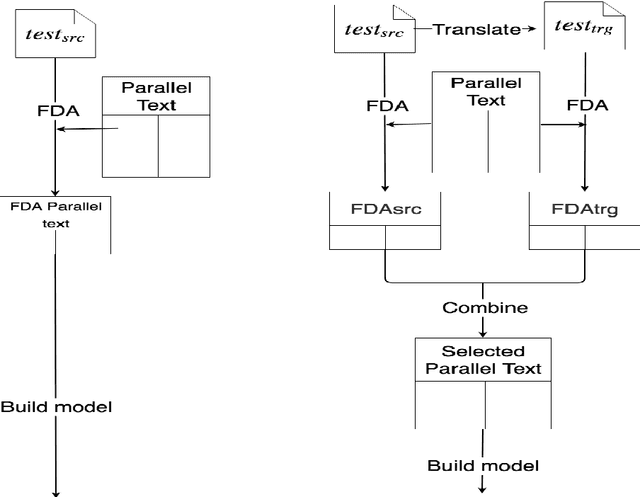
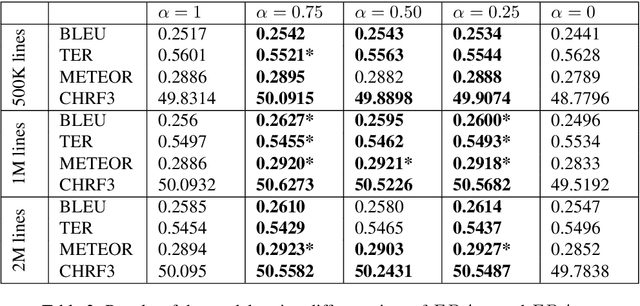
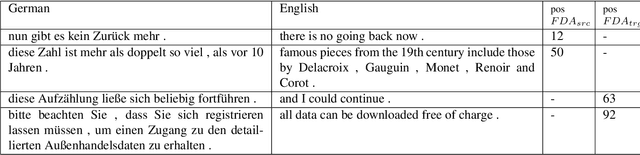
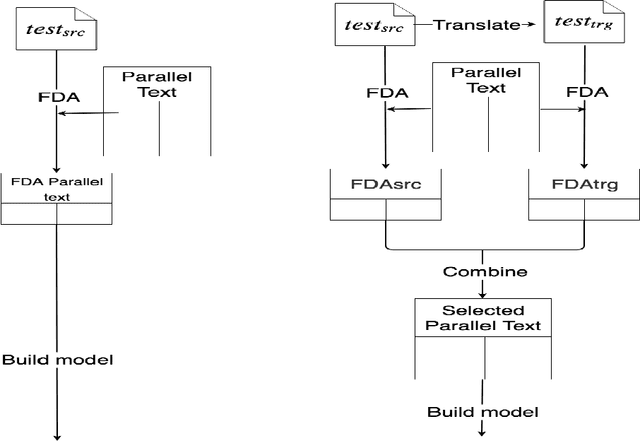
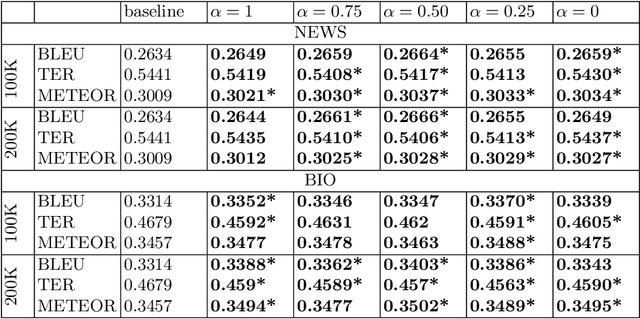
Data selection techniques applied to neural machine translation (NMT) aim to increase the performance of a model by retrieving a subset of sentences for use as training data. One of the possible data selection techniques are transductive learning methods, which select the data based on the test set, i.e. the document to be translated. A limitation of these methods to date is that using the source-side test set does not by itself guarantee that sentences are selected with correct translations, or translations that are suitable given the test-set domain. Some corpora, such as subtitle corpora, may contain parallel sentences with inaccurate translations caused by localization or length restrictions. In order to try to fix this problem, in this paper we propose to use an approximated target-side in addition to the source-side when selecting suitable sentence-pairs for training a model. This approximated target-side is built by pre-translating the source-side. In this work, we explore the performance of this general idea for one specific data selection approach called Feature Decay Algorithms (FDA). We train German-English NMT models on data selected by using the test set (source), the approximated target side, and a mixture of both. Our findings reveal that models built using a combination of outputs of FDA (using the test set and an approximated target side) perform better than those solely using the test set. We obtain a statistically significant improvement of more than 1.5 BLEU points over a model trained with all data, and more than 0.5 BLEU points over a strong FDA baseline that uses source-side information only.
Learning to Jointly Translate and Predict Dropped Pronouns with a Shared Reconstruction Mechanism
Oct 15, 2018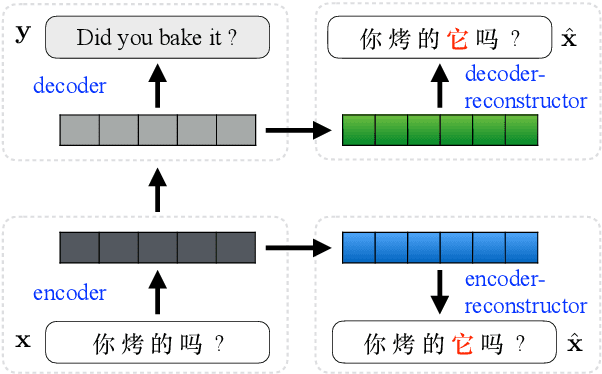

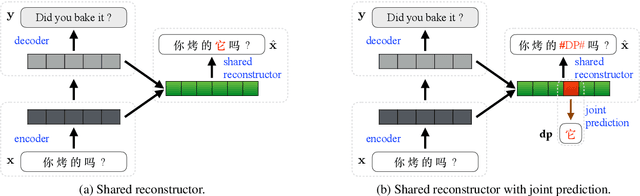
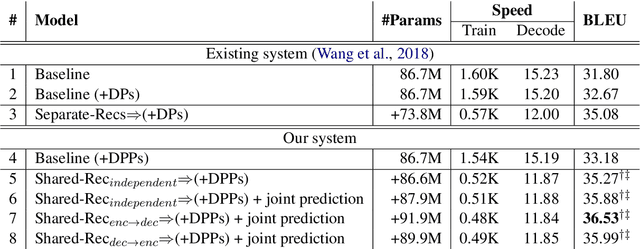
Pronouns are frequently omitted in pro-drop languages, such as Chinese, generally leading to significant challenges with respect to the production of complete translations. Recently, Wang et al. (2018) proposed a novel reconstruction-based approach to alleviating dropped pronoun (DP) translation problems for neural machine translation models. In this work, we improve the original model from two perspectives. First, we employ a shared reconstructor to better exploit encoder and decoder representations. Second, we jointly learn to translate and predict DPs in an end-to-end manner, to avoid the errors propagated from an external DP prediction model. Experimental results show that our approach significantly improves both translation performance and DP prediction accuracy.
Multi-Level Structured Self-Attentions for Distantly Supervised Relation Extraction
Sep 03, 2018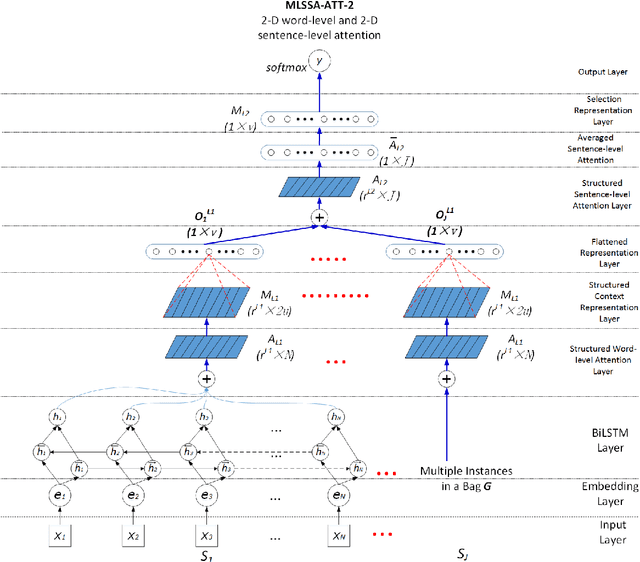
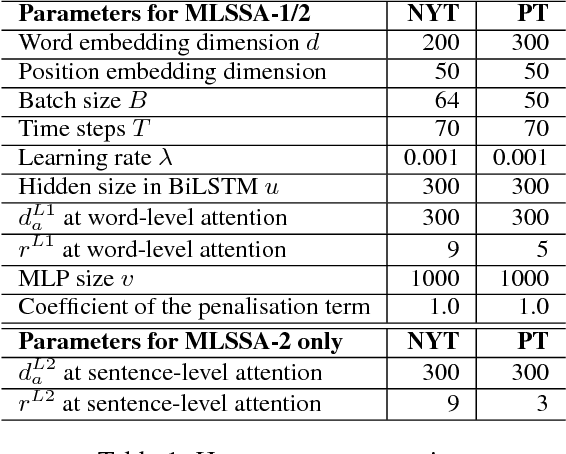
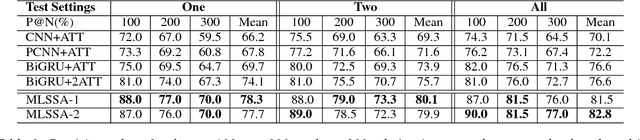
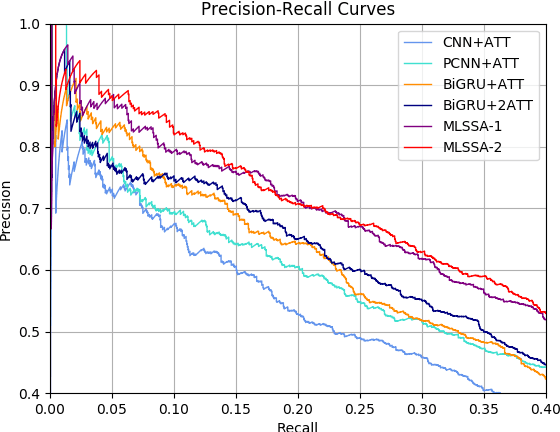
Attention mechanisms are often used in deep neural networks for distantly supervised relation extraction (DS-RE) to distinguish valid from noisy instances. However, traditional 1-D vector attention models are insufficient for the learning of different contexts in the selection of valid instances to predict the relationship for an entity pair. To alleviate this issue, we propose a novel multi-level structured (2-D matrix) self-attention mechanism for DS-RE in a multi-instance learning (MIL) framework using bidirectional recurrent neural networks. In the proposed method, a structured word-level self-attention mechanism learns a 2-D matrix where each row vector represents a weight distribution for different aspects of an instance regarding two entities. Targeting the MIL issue, the structured sentence-level attention learns a 2-D matrix where each row vector represents a weight distribution on selection of different valid in-stances. Experiments conducted on two publicly available DS-RE datasets show that the proposed framework with a multi-level structured self-attention mechanism significantly outperform state-of-the-art baselines in terms of PR curves, P@N and F1 measures.
Attaining the Unattainable? Reassessing Claims of Human Parity in Neural Machine Translation
Aug 30, 2018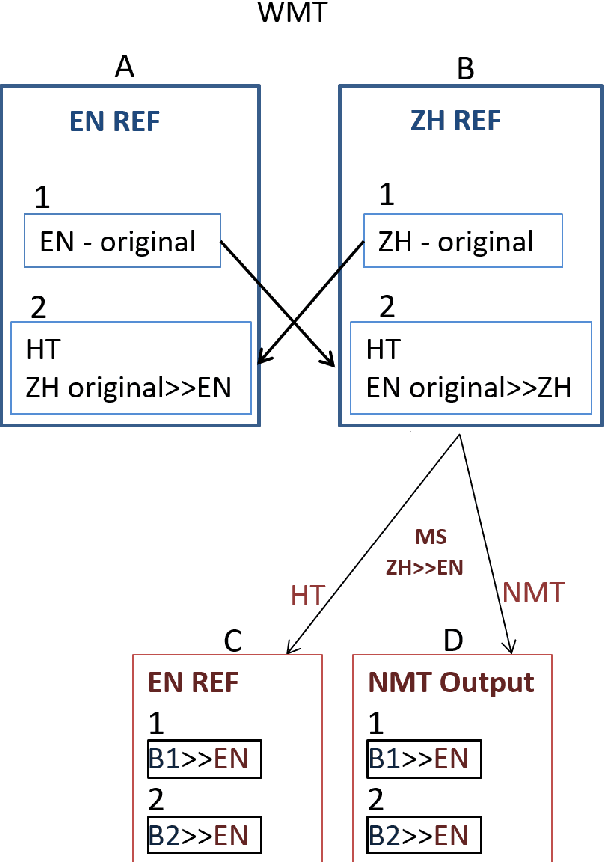
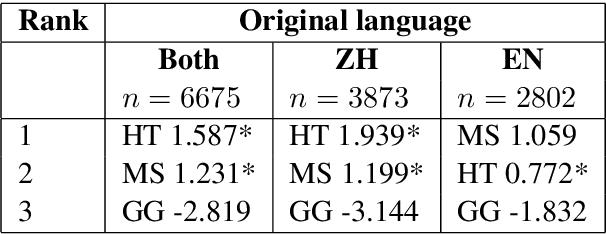

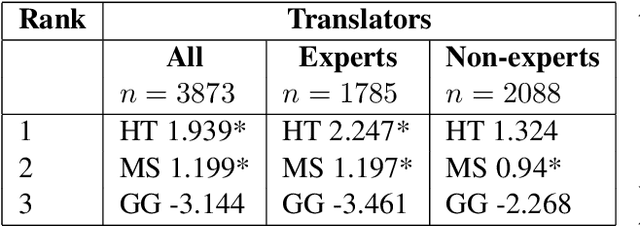
We reassess a recent study (Hassan et al., 2018) that claimed that machine translation (MT) has reached human parity for the translation of news from Chinese into English, using pairwise ranking and considering three variables that were not taken into account in that previous study: the language in which the source side of the test set was originally written, the translation proficiency of the evaluators, and the provision of inter-sentential context. If we consider only original source text (i.e. not translated from another language, or translationese), then we find evidence showing that human parity has not been achieved. We compare the judgments of professional translators against those of non-experts and discover that those of the experts result in higher inter-annotator agreement and better discrimination between human and machine translations. In addition, we analyse the human translations of the test set and identify important translation issues. Finally, based on these findings, we provide a set of recommendations for future human evaluations of MT.
Improving Character-based Decoding Using Target-Side Morphological Information for Neural Machine Translation
Apr 17, 2018
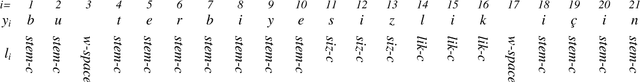
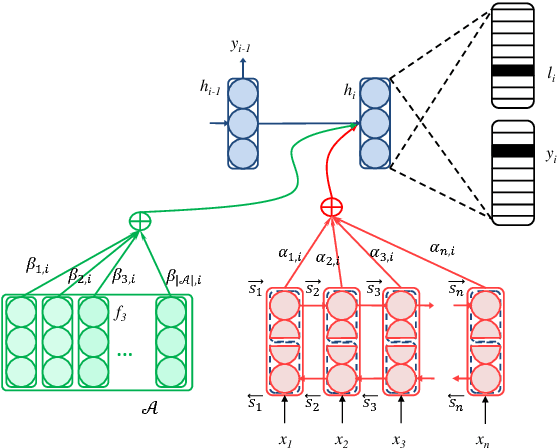
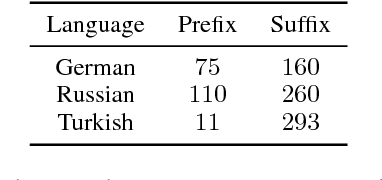
Recently, neural machine translation (NMT) has emerged as a powerful alternative to conventional statistical approaches. However, its performance drops considerably in the presence of morphologically rich languages (MRLs). Neural engines usually fail to tackle the large vocabulary and high out-of-vocabulary (OOV) word rate of MRLs. Therefore, it is not suitable to exploit existing word-based models to translate this set of languages. In this paper, we propose an extension to the state-of-the-art model of Chung et al. (2016), which works at the character level and boosts the decoder with target-side morphological information. In our architecture, an additional morphology table is plugged into the model. Each time the decoder samples from a target vocabulary, the table sends auxiliary signals from the most relevant affixes in order to enrich the decoder's current state and constrain it to provide better predictions. We evaluated our model to translate English into German, Russian, and Turkish as three MRLs and observed significant improvements.