 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTTOpt: A Maximum Volume Quantized Tensor Train-based Optimization and its Application to Reinforcement Learning
Apr 30, 2022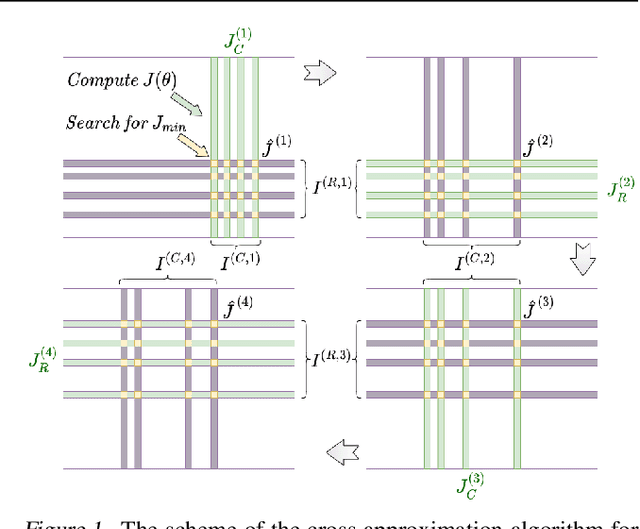
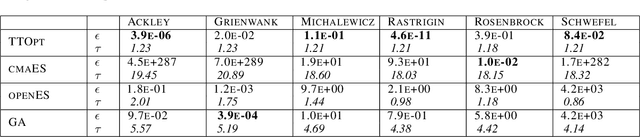
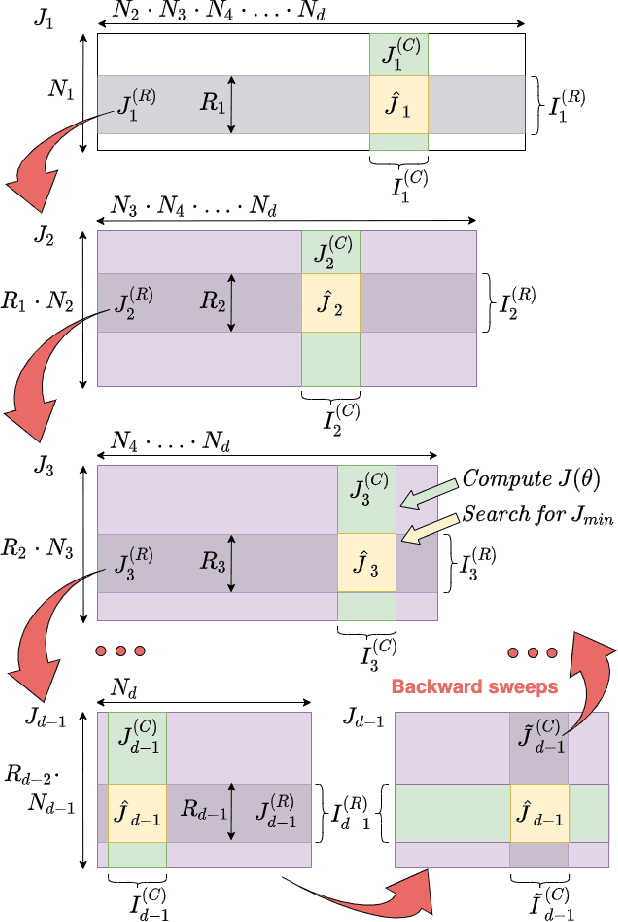
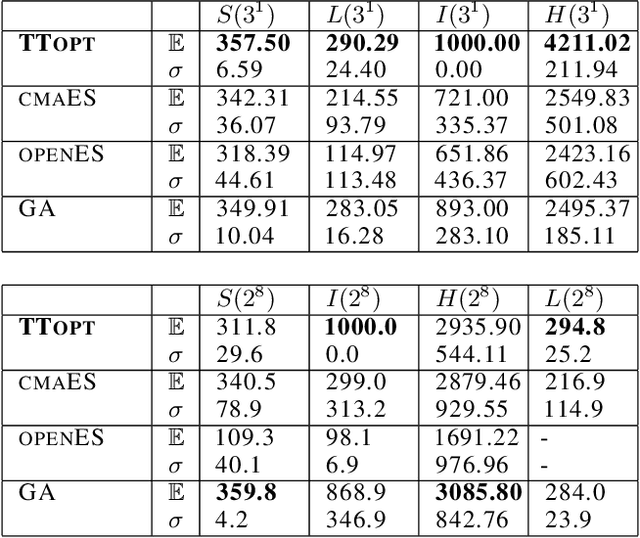
We present a novel procedure for optimization based on the combination of efficient quantized tensor train representation and a generalized maximum matrix volume principle. We demonstrate the applicability of the new Tensor Train Optimizer (TTOpt) method for various tasks, ranging from minimization of multidimensional functions to reinforcement learning. Our algorithm compares favorably to popular evolutionary-based methods and outperforms them by the number of function evaluations or execution time, often by a significant margin.
How to Train Unstable Looped Tensor Network
Mar 05, 2022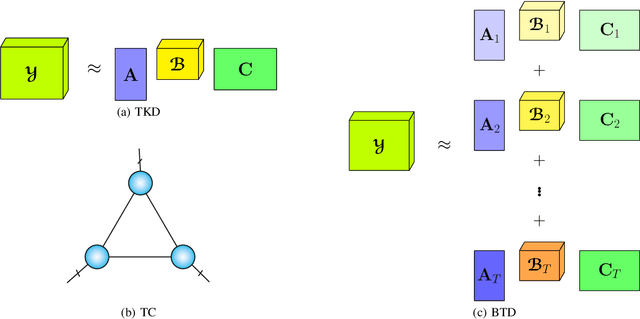
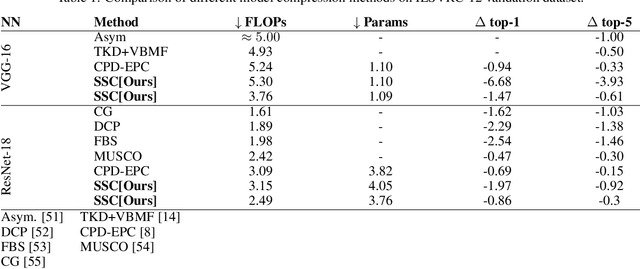
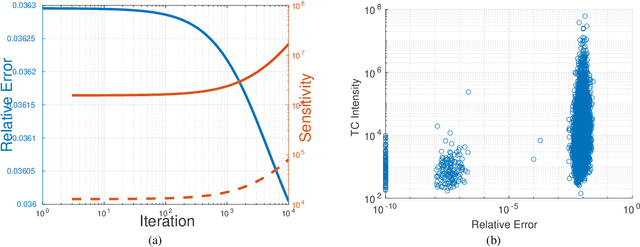
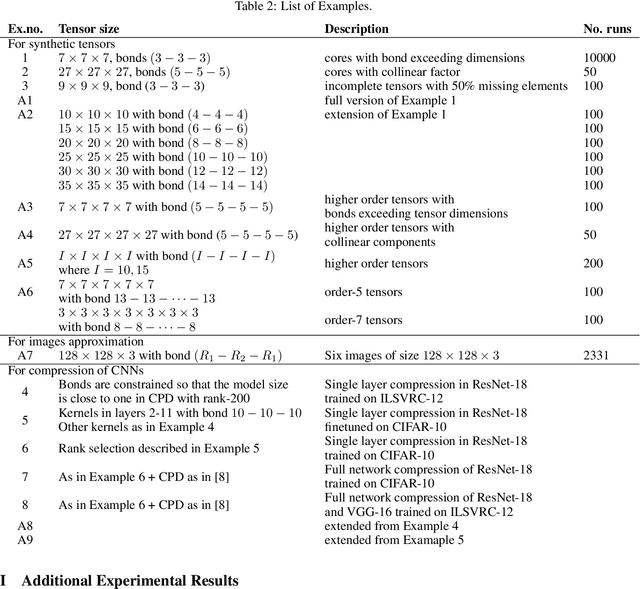
A rising problem in the compression of Deep Neural Networks is how to reduce the number of parameters in convolutional kernels and the complexity of these layers by low-rank tensor approximation. Canonical polyadic tensor decomposition (CPD) and Tucker tensor decomposition (TKD) are two solutions to this problem and provide promising results. However, CPD often fails due to degeneracy, making the networks unstable and hard to fine-tune. TKD does not provide much compression if the core tensor is big. This motivates using a hybrid model of CPD and TKD, a decomposition with multiple Tucker models with small core tensor, known as block term decomposition (BTD). This paper proposes a more compact model that further compresses the BTD by enforcing core tensors in BTD identical. We establish a link between the BTD with shared parameters and a looped chain tensor network (TC). Unfortunately, such strongly constrained tensor networks (with loop) encounter severe numerical instability, as proved by y (Landsberg, 2012) and (Handschuh, 2015a). We study perturbation of chain tensor networks, provide interpretation of instability in TC, demonstrate the problem. We propose novel methods to gain the stability of the decomposition results, keep the network robust and attain better approximation. Experimental results will confirm the superiority of the proposed methods in compression of well-known CNNs, and TC decomposition under challenging scenarios
L3C-Stereo: Lossless Compression for Stereo Images
Aug 21, 2021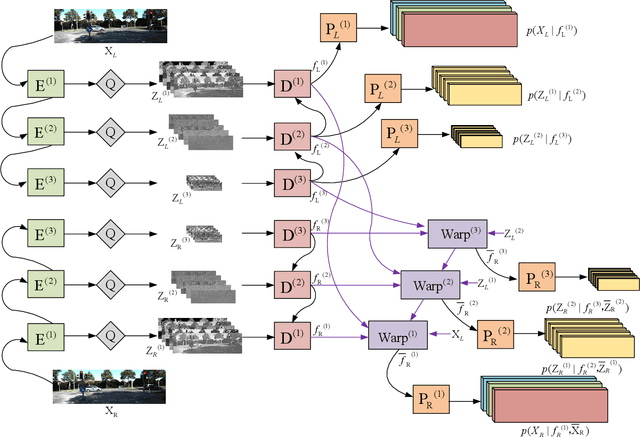
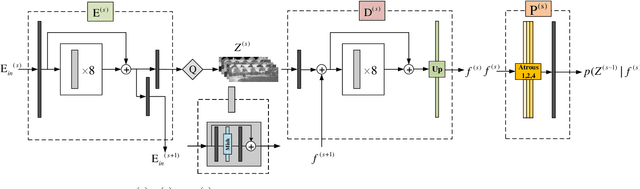
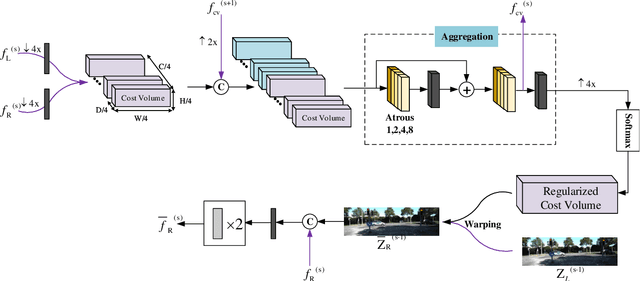

A large number of autonomous driving tasks need high-definition stereo images, which requires a large amount of storage space. Efficiently executing lossless compression has become a practical problem. Commonly, it is hard to make accurate probability estimates for each pixel. To tackle this, we propose L3C-Stereo, a multi-scale lossless compression model consisting of two main modules: the warping module and the probability estimation module. The warping module takes advantage of two view feature maps from the same domain to generate a disparity map, which is used to reconstruct the right view so as to improve the confidence of the probability estimate of the right view. The probability estimation module provides pixel-wise logistic mixture distributions for adaptive arithmetic coding. In the experiments, our method outperforms the hand-crafted compression methods and the learning-based method on all three datasets used. Then, we show that a better maximum disparity can lead to a better compression effect. Furthermore, thanks to a compression property of our model, it naturally generates a disparity map of an acceptable quality for the subsequent stereo tasks.
Meta-Solver for Neural Ordinary Differential Equations
Mar 15, 2021
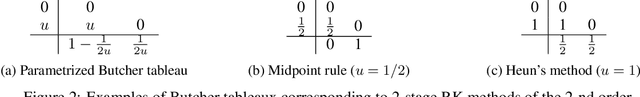

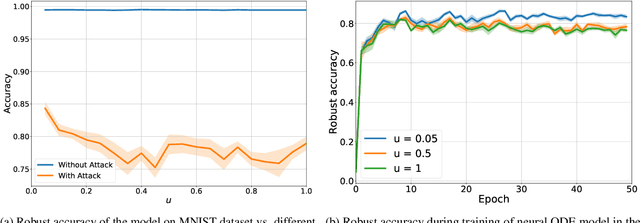
A conventional approach to train neural ordinary differential equations (ODEs) is to fix an ODE solver and then learn the neural network's weights to optimize a target loss function. However, such an approach is tailored for a specific discretization method and its properties, which may not be optimal for the selected application and yield the overfitting to the given solver. In our paper, we investigate how the variability in solvers' space can improve neural ODEs performance. We consider a family of Runge-Kutta methods that are parameterized by no more than two scalar variables. Based on the solvers' properties, we propose an approach to decrease neural ODEs overfitting to the pre-defined solver, along with a criterion to evaluate such behaviour. Moreover, we show that the right choice of solver parameterization can significantly affect neural ODEs models in terms of robustness to adversarial attacks. Recently it was shown that neural ODEs demonstrate superiority over conventional CNNs in terms of robustness. Our work demonstrates that the model robustness can be further improved by optimizing solver choice for a given task. The source code to reproduce our experiments is available at https://github.com/juliagusak/neural-ode-metasolver.
Improving EEG Decoding via Clustering-based Multi-task Feature Learning
Dec 12, 2020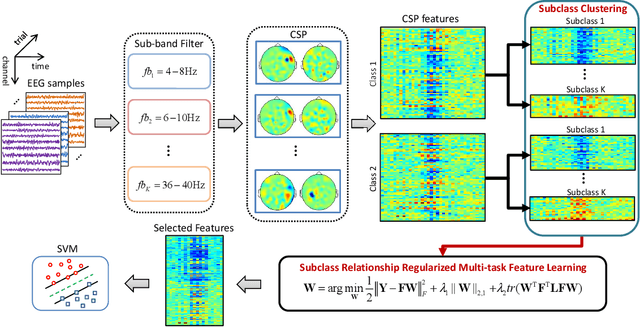
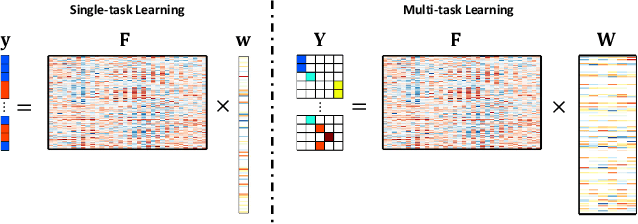
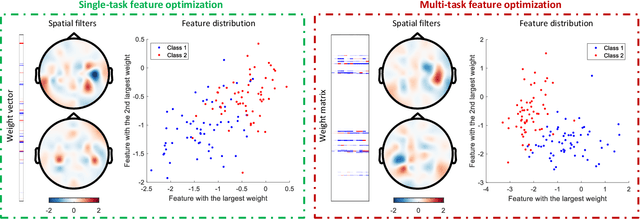
Accurate electroencephalogram (EEG) pattern decoding for specific mental tasks is one of the key steps for the development of brain-computer interface (BCI), which is quite challenging due to the considerably low signal-to-noise ratio of EEG collected at the brain scalp. Machine learning provides a promising technique to optimize EEG patterns toward better decoding accuracy. However, existing algorithms do not effectively explore the underlying data structure capturing the true EEG sample distribution, and hence can only yield a suboptimal decoding accuracy. To uncover the intrinsic distribution structure of EEG data, we propose a clustering-based multi-task feature learning algorithm for improved EEG pattern decoding. Specifically, we perform affinity propagation-based clustering to explore the subclasses (i.e., clusters) in each of the original classes, and then assign each subclass a unique label based on a one-versus-all encoding strategy. With the encoded label matrix, we devise a novel multi-task learning algorithm by exploiting the subclass relationship to jointly optimize the EEG pattern features from the uncovered subclasses. We then train a linear support vector machine with the optimized features for EEG pattern decoding. Extensive experimental studies are conducted on three EEG datasets to validate the effectiveness of our algorithm in comparison with other state-of-the-art approaches. The improved experimental results demonstrate the outstanding superiority of our algorithm, suggesting its prominent performance for EEG pattern decoding in BCI applications.
Deep Learning in EEG: Advance of the Last Ten-Year Critical Period
Nov 22, 2020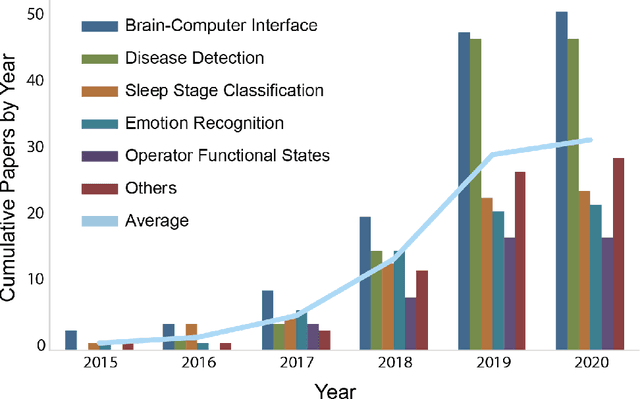
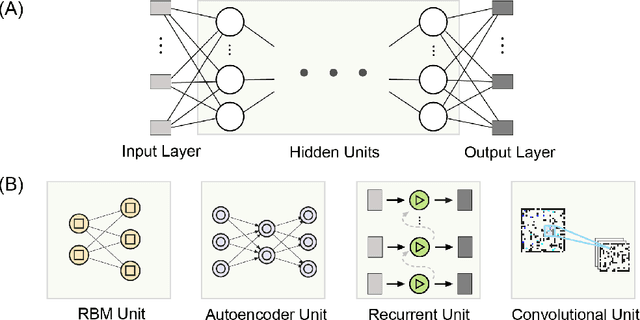
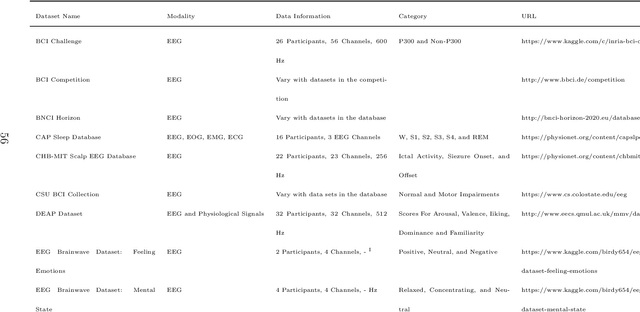
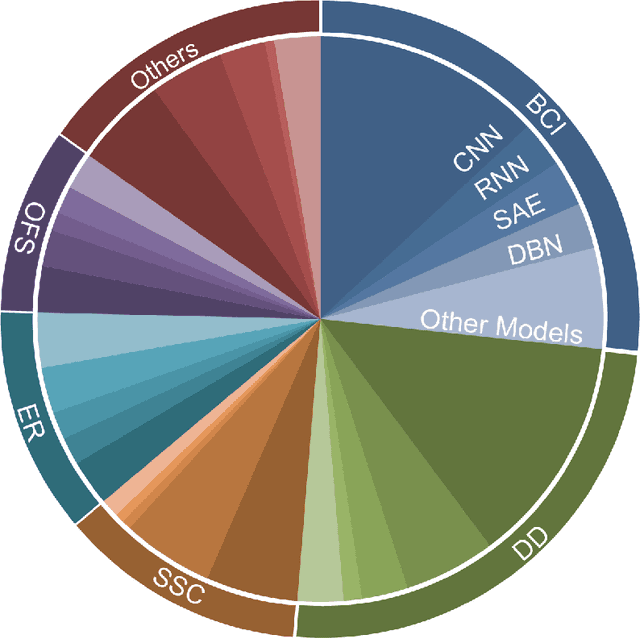
Deep learning has achieved excellent performance in a wide range of domains, especially in speech recognition and computer vision. Relatively less work has been done for EEG, but there is still significant progress attained in the last decade. Due to the lack of a comprehensive survey for deep learning in EEG, we attempt to summarize recent progress to provide an overview, as well as perspectives for future developments. We first briefly mention the artifacts removal for EEG signal and then introduce deep learning models that have been utilized in EEG processing and classification. Subsequently, the applications of deep learning in EEG are reviewed by categorizing them into groups such as brain-computer interface, disease detection, and emotion recognition. They are followed by the discussion, in which the pros and cons of deep learning are presented and future directions and challenges for deep learning in EEG are proposed. We hope that this paper could serve as a summary of past work for deep learning in EEG and the beginning of further developments and achievements of EEG studies based on deep learning.
On Multiple Intelligences and Learning Styles for Artificial Intelligence Systems: Future Research Trends in AI with a Human Face?
Aug 30, 2020
This article discusses recent trends and concepts in developing new kinds of artificial intelligence (AI) systems which relate to complex facets and different types of human intelligence, especially social, emotional, attentional and ethical intelligence, which to date have been under-discussed. We describe various aspects of multiple human intelligence and learning styles, which may impact on a variety of AI problem domains. Using the concept of multiple intelligence rather than a single type of intelligence, we categorize and provide working definitions of various AI depending on their cognitive skills or capacities. Future AI systems will be able not only to communicate with human actors and each other, but also to efficiently exchange knowledge with abilities of cooperation, collaboration and even co-creating something new and valuable and have meta-learning capacities. Multi-agent systems such as these can be used to solve problems that would be difficult to solve by any individual intelligent agent.
Stable Low-rank Tensor Decomposition for Compression of Convolutional Neural Network
Aug 12, 2020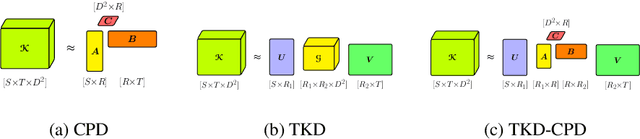
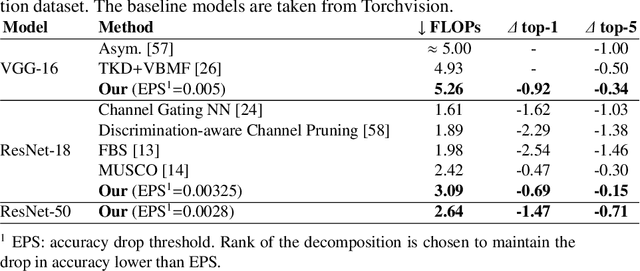
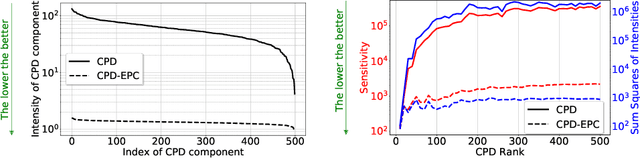
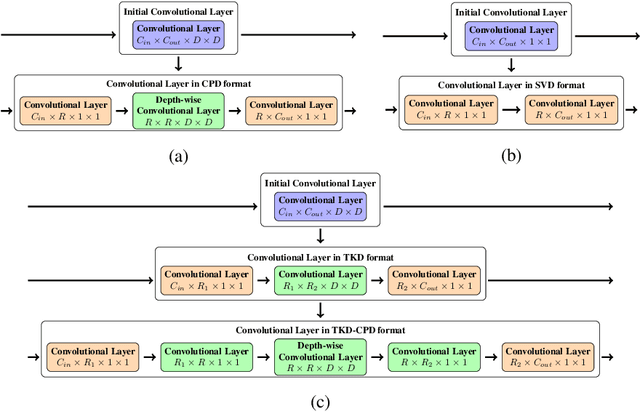
Most state of the art deep neural networks are overparameterized and exhibit a high computational cost. A straightforward approach to this problem is to replace convolutional kernels with its low-rank tensor approximations, whereas the Canonical Polyadic tensor Decomposition is one of the most suited models. However, fitting the convolutional tensors by numerical optimization algorithms often encounters diverging components, i.e., extremely large rank-one tensors but canceling each other. Such degeneracy often causes the non-interpretable result and numerical instability for the neural network fine-tuning. This paper is the first study on degeneracy in the tensor decomposition of convolutional kernels. We present a novel method, which can stabilize the low-rank approximation of convolutional kernels and ensure efficient compression while preserving the high-quality performance of the neural networks. We evaluate our approach on popular CNN architectures for image classification and show that our method results in much lower accuracy degradation and provides consistent performance.
Towards Understanding Normalization in Neural ODEs
Apr 27, 2020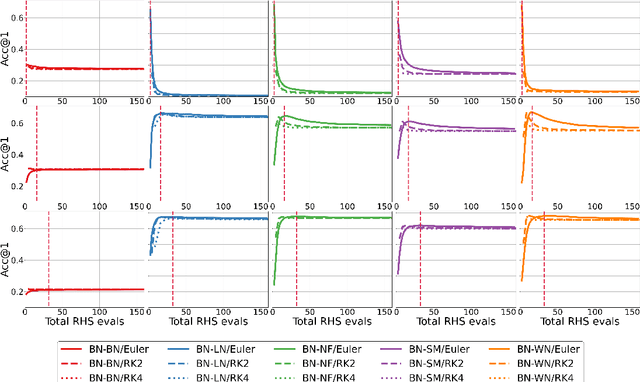
Normalization is an important and vastly investigated technique in deep learning. However, its role for Ordinary Differential Equation based networks (neural ODEs) is still poorly understood. This paper investigates how different normalization techniques affect the performance of neural ODEs. Particularly, we show that it is possible to achieve 93% accuracy in the CIFAR-10 classification task, and to the best of our knowledge, this is the highest reported accuracy among neural ODEs tested on this problem.
Interpolated Adjoint Method for Neural ODEs
Mar 11, 2020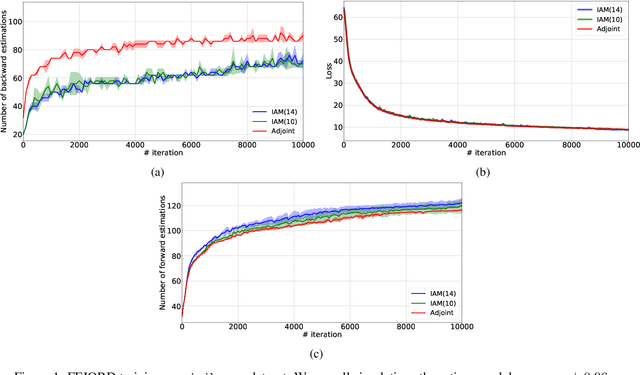
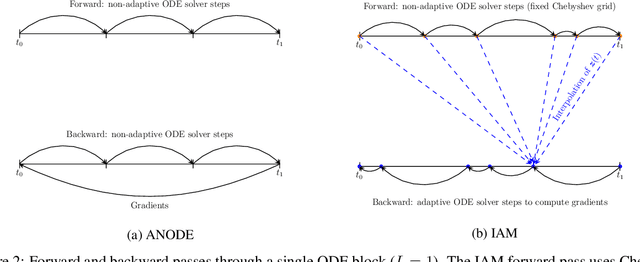

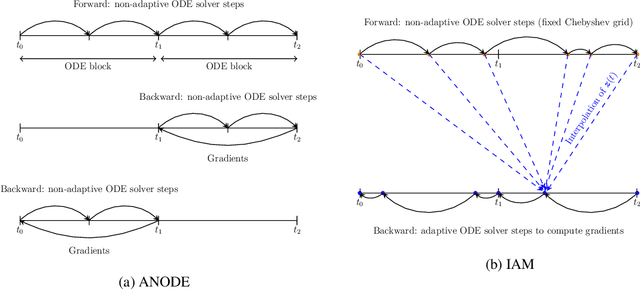
In this paper, we propose a method, which allows us to alleviate or completely avoid the notorious problem of numerical instability and stiffness of the adjoint method for training neural ODE. On the backward pass, we propose to use the machinery of smooth function interpolation to restore the trajectory obtained during the forward integration. We show the viability of our approach, both in theory and practice.