 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence-to-Sequence Learning via Attention Transfer for Incremental Speech Recognition
Nov 04, 2020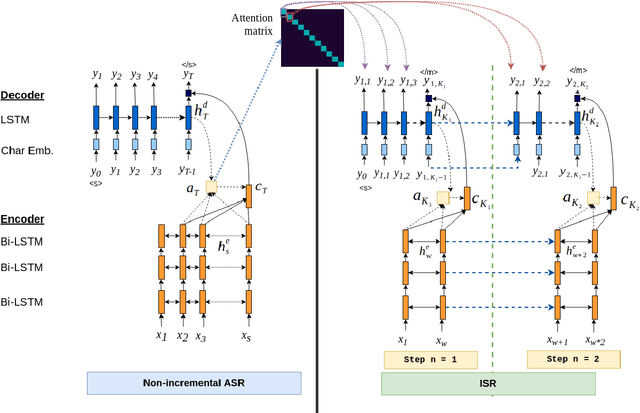
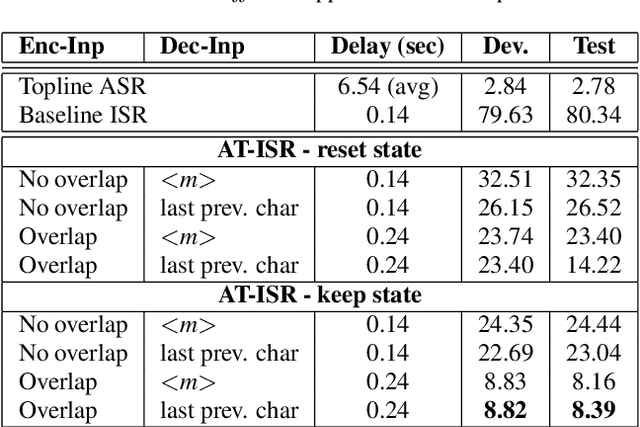
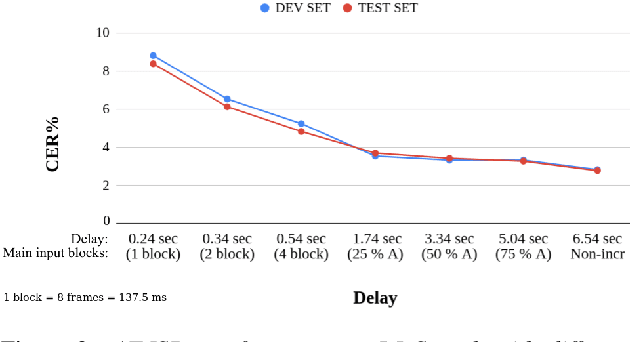
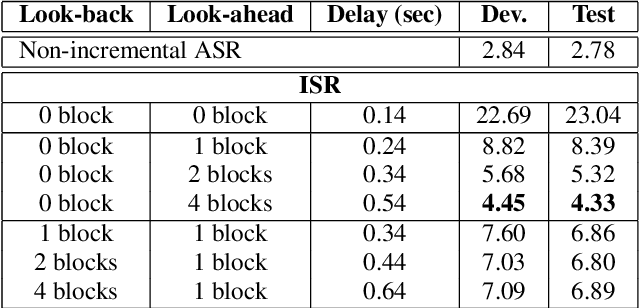
Attention-based sequence-to-sequence automatic speech recognition (ASR) requires a significant delay to recognize long utterances because the output is generated after receiving entire input sequences. Although several studies recently proposed sequence mechanisms for incremental speech recognition (ISR), using different frameworks and learning algorithms is more complicated than the standard ASR model. One main reason is because the model needs to decide the incremental steps and learn the transcription that aligns with the current short speech segment. In this work, we investigate whether it is possible to employ the original architecture of attention-based ASR for ISR tasks by treating a full-utterance ASR as the teacher model and the ISR as the student model. We design an alternative student network that, instead of using a thinner or a shallower model, keeps the original architecture of the teacher model but with shorter sequences (few encoder and decoder states). Using attention transfer, the student network learns to mimic the same alignment between the current input short speech segments and the transcription. Our experiments show that by delaying the starting time of recognition process with about 1.7 sec, we can achieve comparable performance to one that needs to wait until the end.
Incremental Machine Speech Chain Towards Enabling Listening while Speaking in Real-time
Nov 04, 2020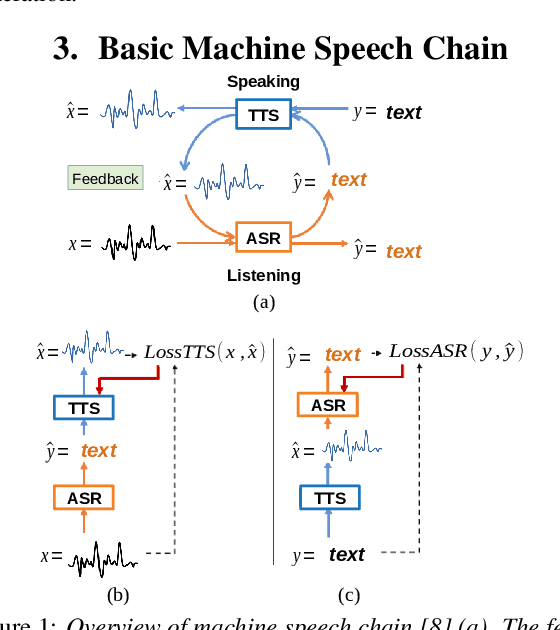
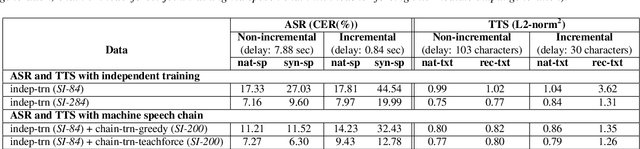
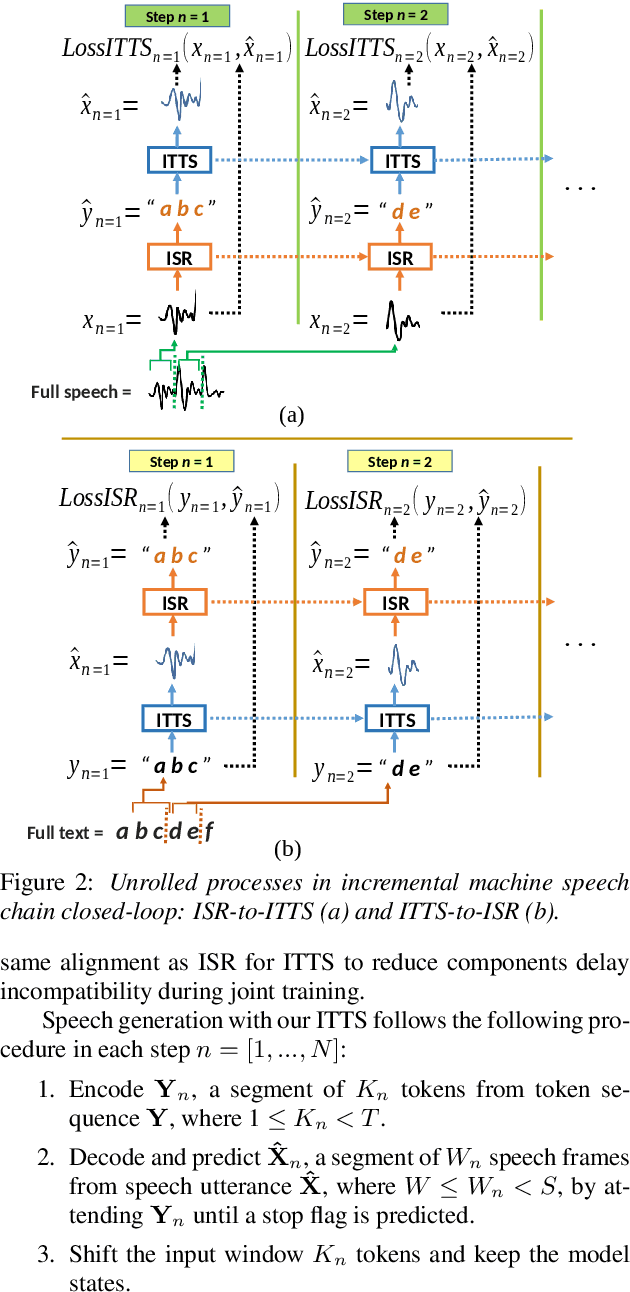
Inspired by a human speech chain mechanism, a machine speech chain framework based on deep learning was recently proposed for the semi-supervised development of automatic speech recognition (ASR) and text-to-speech synthesis TTS) systems. However, the mechanism to listen while speaking can be done only after receiving entire input sequences. Thus, there is a significant delay when encountering long utterances. By contrast, humans can listen to what hey speak in real-time, and if there is a delay in hearing, they won't be able to continue speaking. In this work, we propose an incremental machine speech chain towards enabling machine to listen while speaking in real-time. Specifically, we construct incremental ASR (ISR) and incremental TTS (ITTS) by letting both systems improve together through a short-term loop. Our experimental results reveal that our proposed framework is able to reduce delays due to long utterances while keeping a comparable performance to the non-incremental basic machine speech chain.
Augmenting Images for ASR and TTS through Single-loop and Dual-loop Multimodal Chain Framework
Nov 04, 2020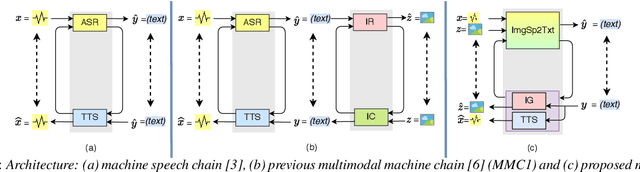
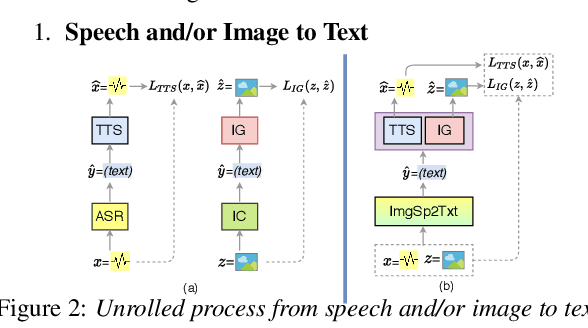
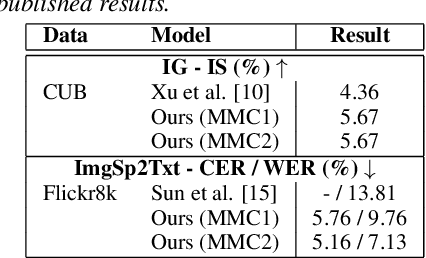
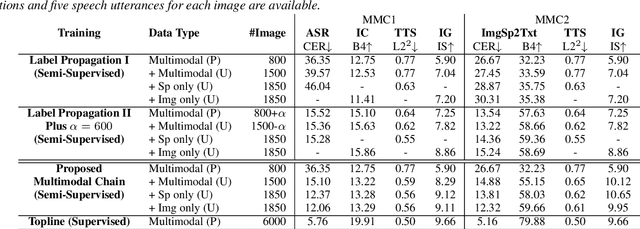
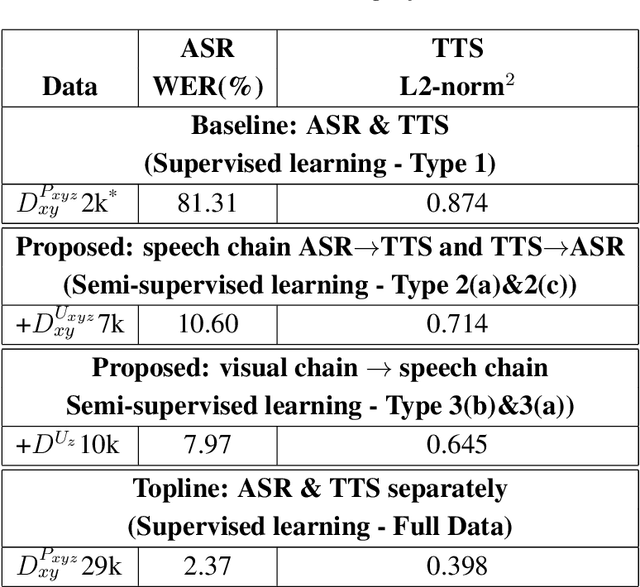
Previous research has proposed a machine speech chain to enable automatic speech recognition (ASR) and text-to-speech synthesis (TTS) to assist each other in semi-supervised learning and to avoid the need for a large amount of paired speech and text data. However, that framework still requires a large amount of unpaired (speech or text) data. A prototype multimodal machine chain was then explored to further reduce the need for a large amount of unpaired data, which could improve ASR or TTS even when no more speech or text data were available. Unfortunately, this framework relied on the image retrieval (IR) model, and thus it was limited to handling only those images that were already known during training. Furthermore, the performance of this framework was only investigated with single-speaker artificial speech data. In this study, we revamp the multimodal machine chain framework with image generation (IG) and investigate the possibility of augmenting image data for ASR and TTS using single-loop and dual-loop architectures on multispeaker natural speech data. Experimental results revealed that both single-loop and dual-loop multimodal chain frameworks enabled ASR and TTS to improve their performance using an image-only dataset.
Unsupervised Learning of Disentangled Speech Content and Style Representation
Oct 24, 2020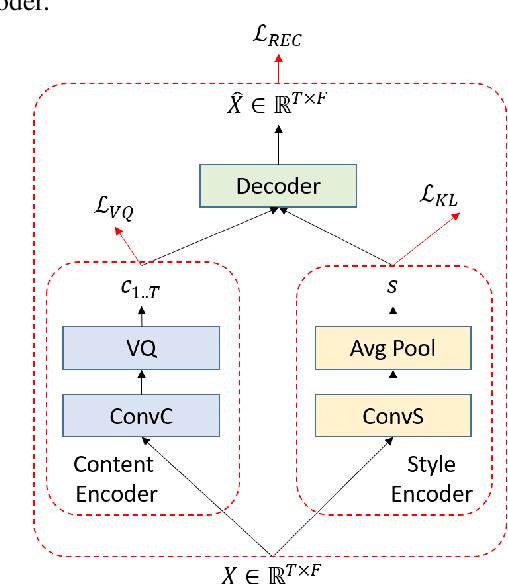
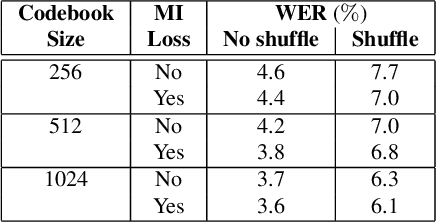
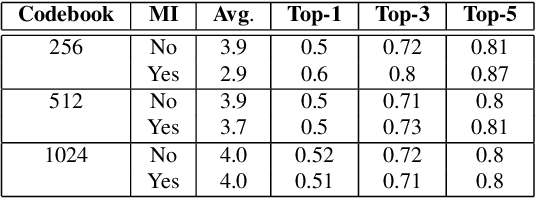
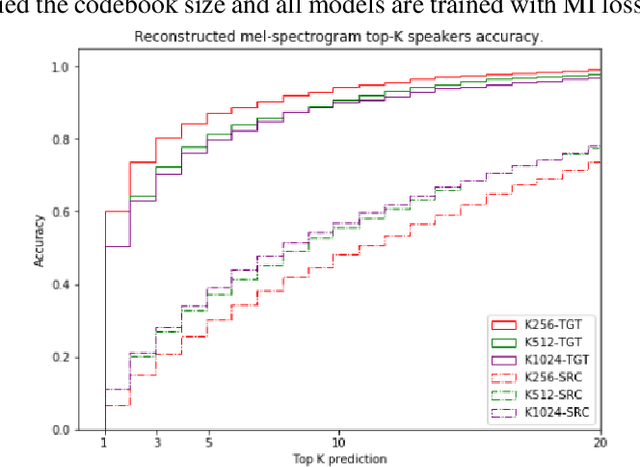
We present an approach for unsupervised learning of speech representation disentangling contents and styles. Our model consists of: (1) a local encoder that captures per-frame information; (2) a global encoder that captures per-utterance information; and (3) a conditional decoder that reconstructs speech given local and global latent variables. Our experiments show that (1) the local latent variables encode speech contents, as reconstructed speech can be recognized by ASR with low word error rates (WER), even with a different global encoding; (2) the global latent variables encode speaker style, as reconstructed speech shares speaker identity with the source utterance of the global encoding. Additionally, we demonstrate an useful application from our pre-trained model, where we can train a speaker recognition model from the global latent variables and achieve high accuracy by fine-tuning with as few data as one label per speaker.
Transformer VQ-VAE for Unsupervised Unit Discovery and Speech Synthesis: ZeroSpeech 2020 Challenge
May 24, 2020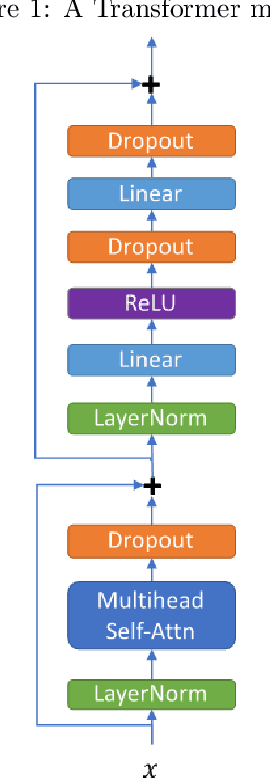
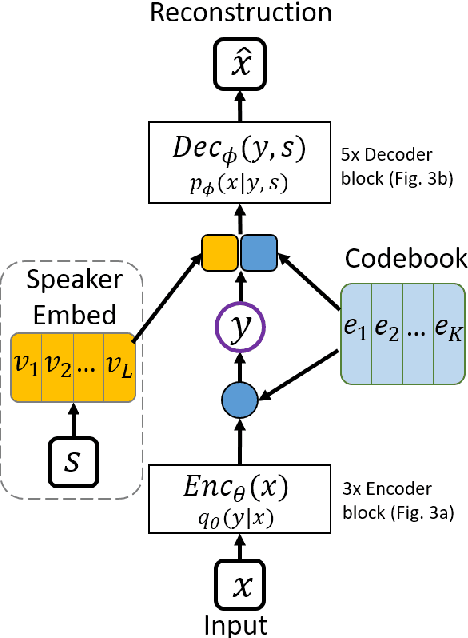

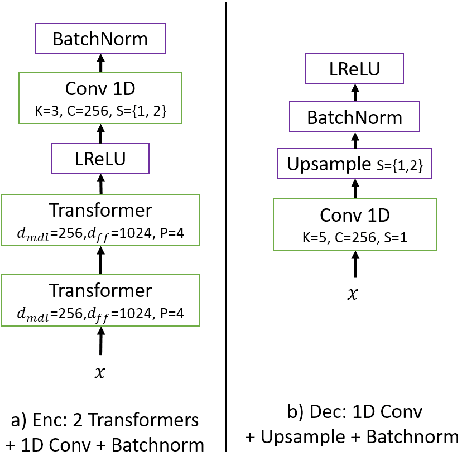
In this paper, we report our submitted system for the ZeroSpeech 2020 challenge on Track 2019. The main theme in this challenge is to build a speech synthesizer without any textual information or phonetic labels. In order to tackle those challenges, we build a system that must address two major components such as 1) given speech audio, extract subword units in an unsupervised way and 2) re-synthesize the audio from novel speakers. The system also needs to balance the codebook performance between the ABX error rate and the bitrate compression rate. Our main contribution here is we proposed Transformer-based VQ-VAE for unsupervised unit discovery and Transformer-based inverter for the speech synthesis given the extracted codebook. Additionally, we also explored several regularization methods to improve performance even further.
Deja-vu: Double Feature Presentation in Deep Transformer Networks
Oct 23, 2019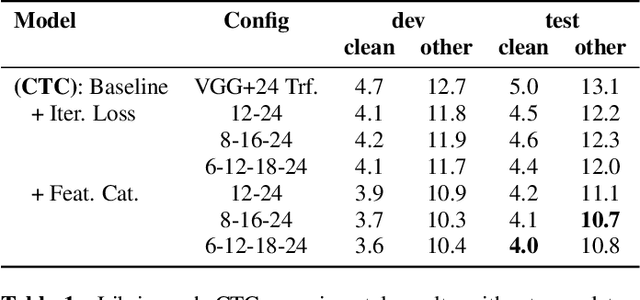
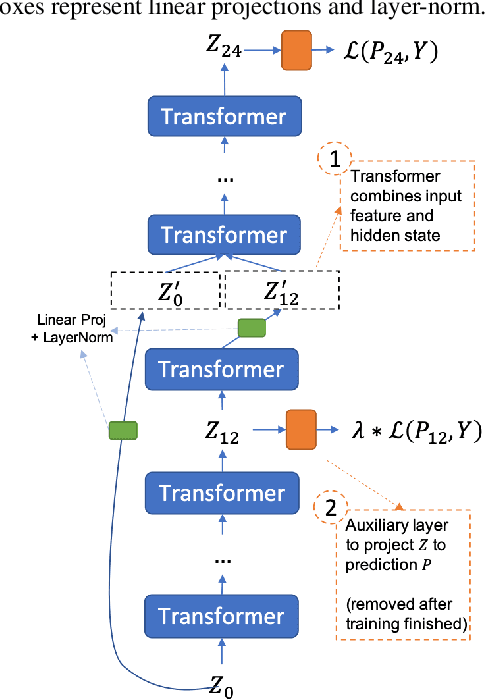
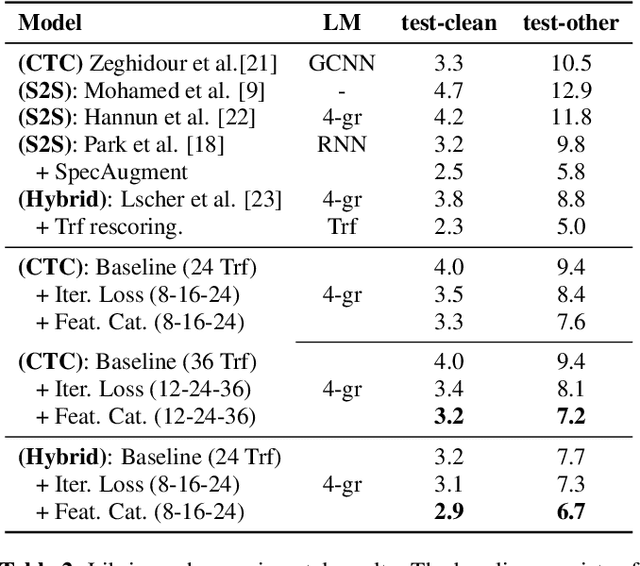
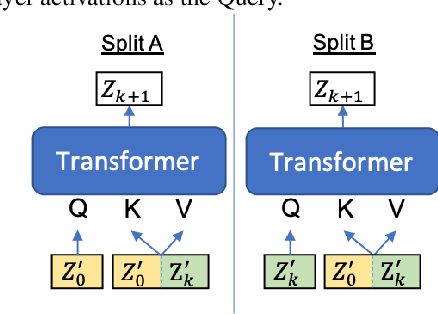
Deep acoustic models typically receive features in the first layer of the network, and process increasingly abstract representations in the subsequent layers. Here, we propose to feed the input features at multiple depths in the acoustic model. As our motivation is to allow acoustic models to re-examine their input features in light of partial hypotheses we introduce intermediate model heads and loss function. We study this architecture in the context of deep Transformer networks, and we use an attention mechanism over both the previous layer activations and the input features. To train this model's intermediate output hypothesis, we apply the objective function at each layer right before feature re-use. We find that the use of such intermediate losses significantly improves performance by itself, as well as enabling input feature re-use. We present results on both Librispeech, and a large scale video dataset, with relative improvements of 10 - 20% for Librispeech and 3.2 - 13% for videos.
Transformer-based Acoustic Modeling for Hybrid Speech Recognition
Oct 22, 2019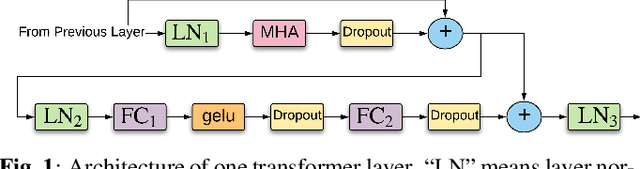
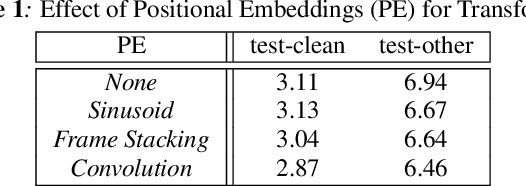
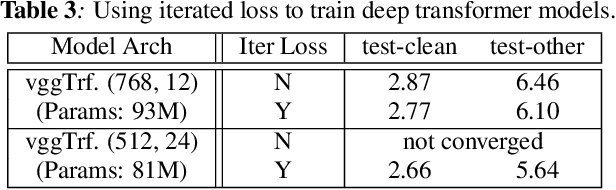
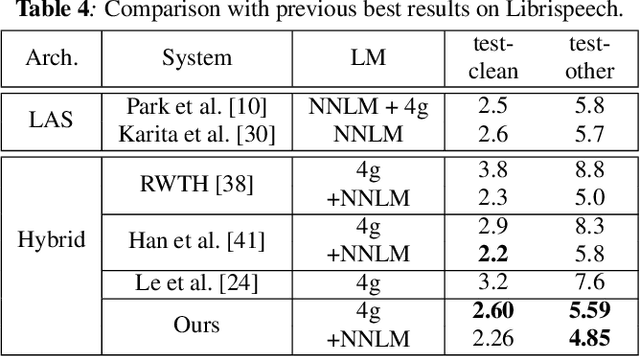
We propose and evaluate transformer-based acoustic models (AMs) for hybrid speech recognition. Several modeling choices are discussed in this work, including various positional embedding methods and an iterated loss to enable training deep transformers. We also present a preliminary study of using limited right context in transformer models, which makes it possible for streaming applications. We demonstrate that on the widely used Librispeech benchmark, our transformer-based AM outperforms the best published hybrid result by 19% to 26% relative when the standard n-gram language model (LM) is used. Combined with neural network LM for rescoring, our proposed approach achieves state-of-the-art results on Librispeech. Our findings are also confirmed on a much larger internal dataset.
Speech-to-speech Translation between Untranscribed Unknown Languages
Oct 05, 2019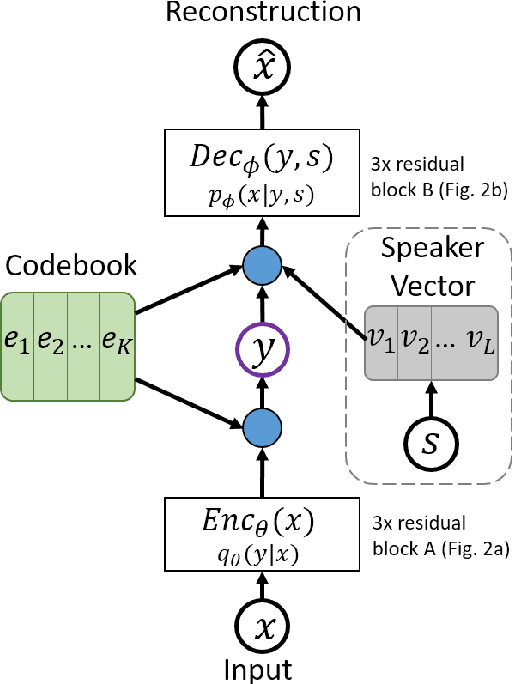
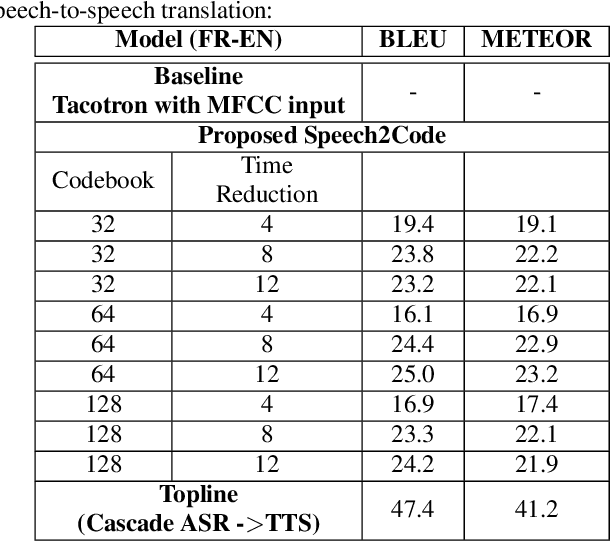
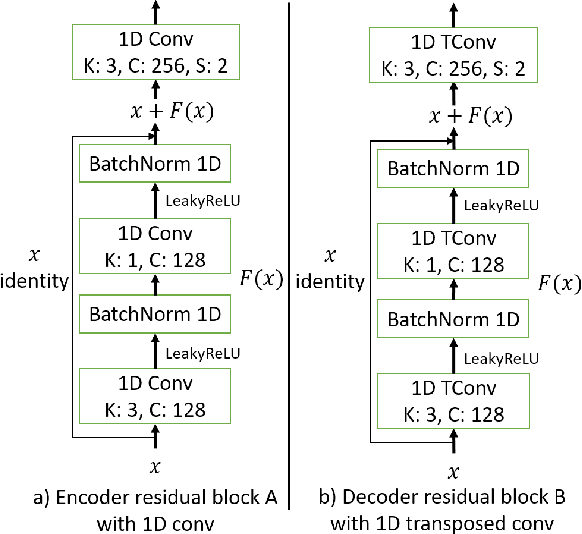
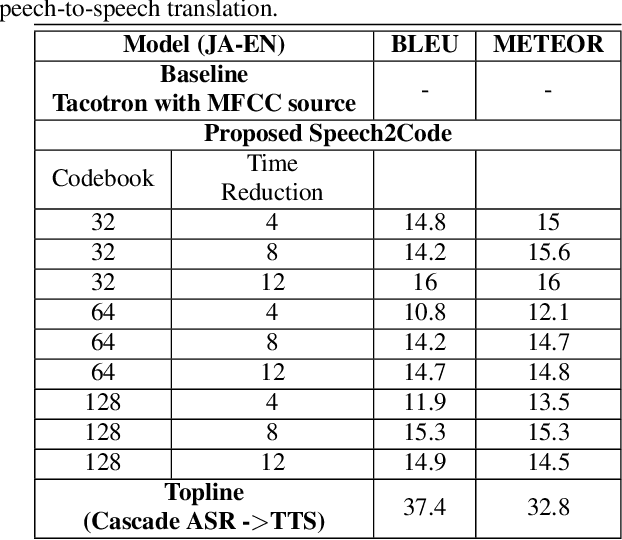
In this paper, we explore a method for training speech-to-speech translation tasks without any transcription or linguistic supervision. Our proposed method consists of two steps: First, we train and generate discrete representation with unsupervised term discovery with a discrete quantized autoencoder. Second, we train a sequence-to-sequence model that directly maps the source language speech to the target language's discrete representation. Our proposed method can directly generate target speech without any auxiliary or pre-training steps with a source or target transcription. To the best of our knowledge, this is the first work that performed pure speech-to-speech translation between untranscribed unknown languages.
From Speech Chain to Multimodal Chain: Leveraging Cross-modal Data Augmentation for Semi-supervised Learning
Jun 03, 2019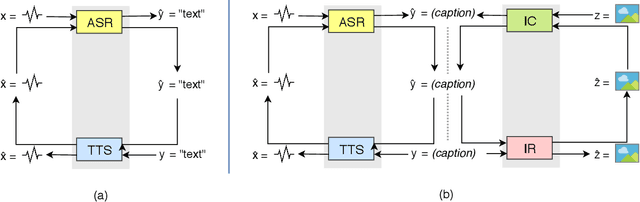
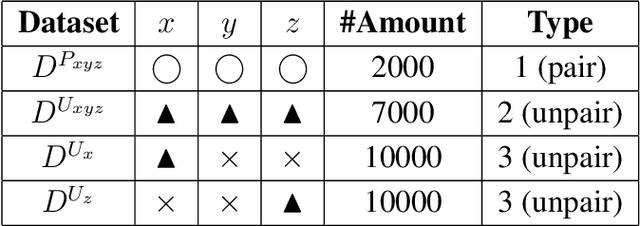
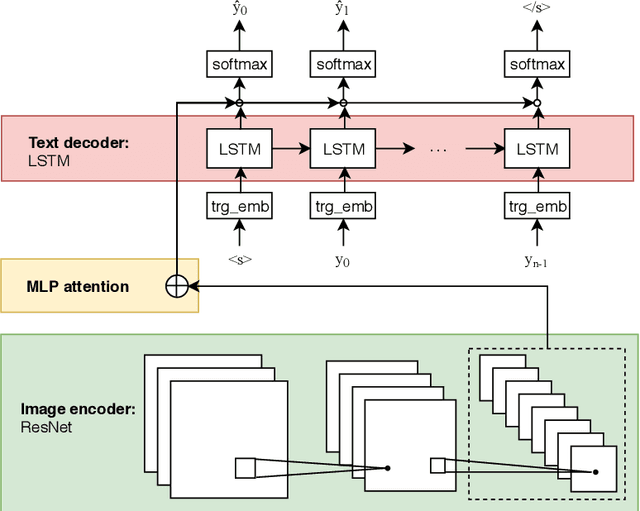
The most common way for humans to communicate is by speech. But perhaps a language system cannot know what it is communicating without a connection to the real world by image perception. In fact, humans perceive these multiple sources of information together to build a general concept. However, constructing a machine that can alleviate these modalities together in a supervised learning fashion is difficult, because a parallel dataset is required among speech, image, and text modalities altogether that is often unavailable. A machine speech chain based on sequence-to-sequence deep learning was previously proposed to achieve semi-supervised learning that enabled automatic speech recognition (ASR) and text-to-speech synthesis (TTS) to teach each other when they receive unpaired data. In this research, we take a further step by expanding the speech chain into a multimodal chain and design a closely knit chain architecture that connects ASR, TTS, image captioning (IC), and image retrieval (IR) models into a single framework. ASR, TTS, IC, and IR components can be trained in a semi-supervised fashion by assisting each other given incomplete datasets and leveraging cross-modal data augmentation within the chain.
VQVAE Unsupervised Unit Discovery and Multi-scale Code2Spec Inverter for Zerospeech Challenge 2019
May 29, 2019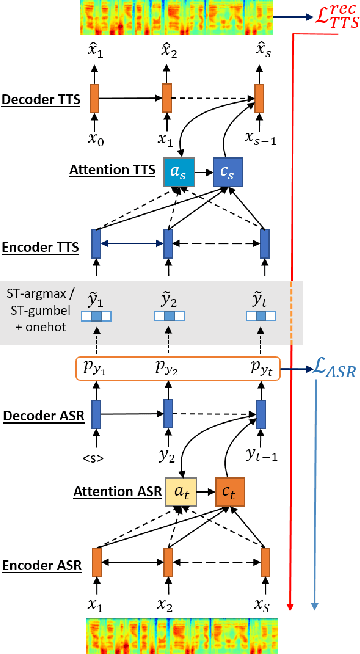
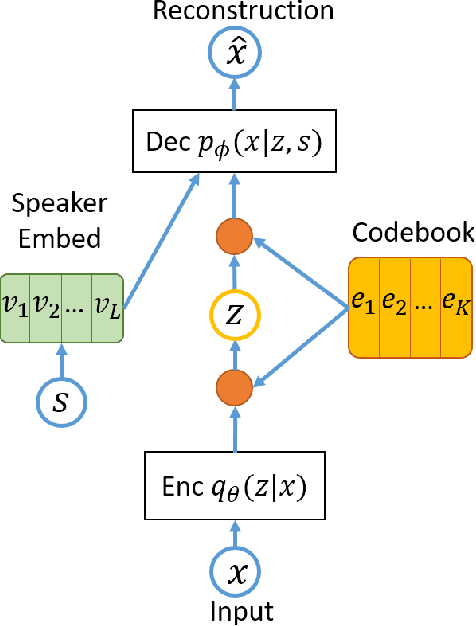
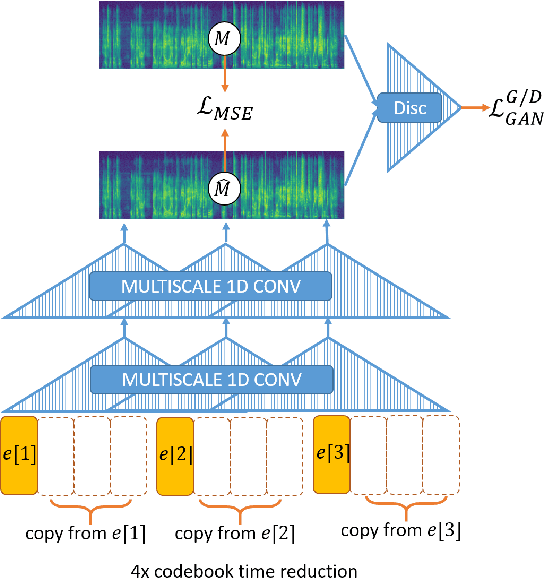
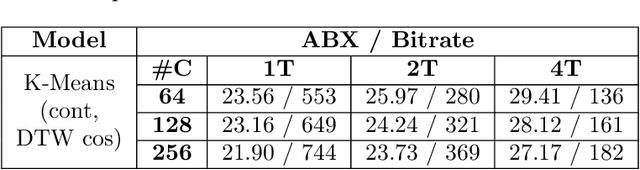
We describe our submitted system for the ZeroSpeech Challenge 2019. The current challenge theme addresses the difficulty of constructing a speech synthesizer without any text or phonetic labels and requires a system that can (1) discover subword units in an unsupervised way, and (2) synthesize the speech with a target speaker's voice. Moreover, the system should also balance the discrimination score ABX, the bit-rate compression rate, and the naturalness and the intelligibility of the constructed voice. To tackle these problems and achieve the best trade-off, we utilize a vector quantized variational autoencoder (VQ-VAE) and a multi-scale codebook-to-spectrogram (Code2Spec) inverter trained by mean square error and adversarial loss. The VQ-VAE extracts the speech to a latent space, forces itself to map it into the nearest codebook and produces compressed representation. Next, the inverter generates a magnitude spectrogram to the target voice, given the codebook vectors from VQ-VAE. In our experiments, we also investigated several other clustering algorithms, including K-Means and GMM, and compared them with the VQ-VAE result on ABX scores and bit rates. Our proposed approach significantly improved the intelligibility (in CER), the MOS, and discrimination ABX scores compared to the official ZeroSpeech 2019 baseline or even the topline.