 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Performance Large-Scale Image Recognition Without Normalization
Feb 11, 2021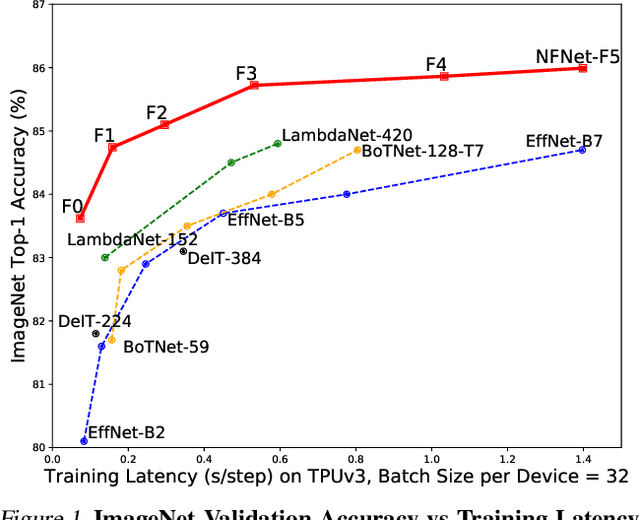
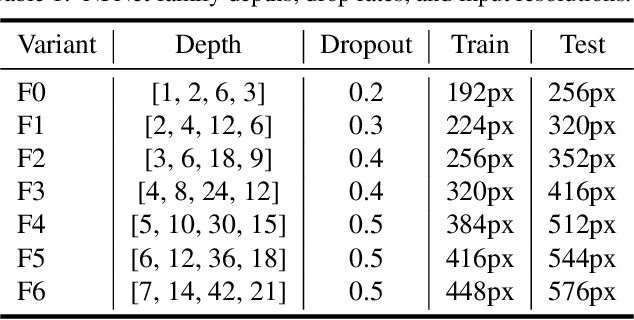
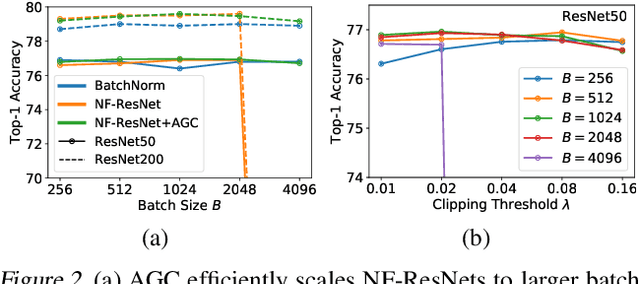
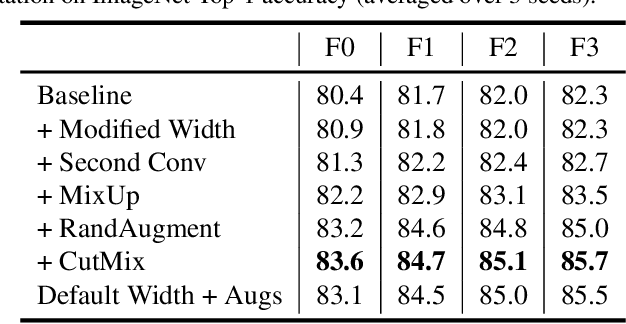
Batch normalization is a key component of most image classification models, but it has many undesirable properties stemming from its dependence on the batch size and interactions between examples. Although recent work has succeeded in training deep ResNets without normalization layers, these models do not match the test accuracies of the best batch-normalized networks, and are often unstable for large learning rates or strong data augmentations. In this work, we develop an adaptive gradient clipping technique which overcomes these instabilities, and design a significantly improved class of Normalizer-Free ResNets. Our smaller models match the test accuracy of an EfficientNet-B7 on ImageNet while being up to 8.7x faster to train, and our largest models attain a new state-of-the-art top-1 accuracy of 86.5%. In addition, Normalizer-Free models attain significantly better performance than their batch-normalized counterparts when finetuning on ImageNet after large-scale pre-training on a dataset of 300 million labeled images, with our best models obtaining an accuracy of 89.2%. Our code is available at https://github.com/deepmind/ deepmind-research/tree/master/nfnets
Characterizing signal propagation to close the performance gap in unnormalized ResNets
Jan 27, 2021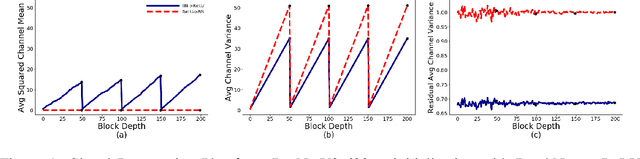

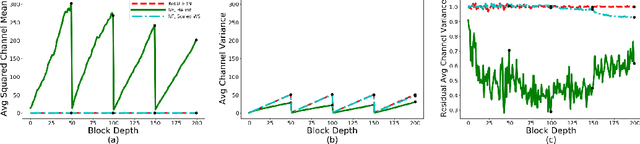

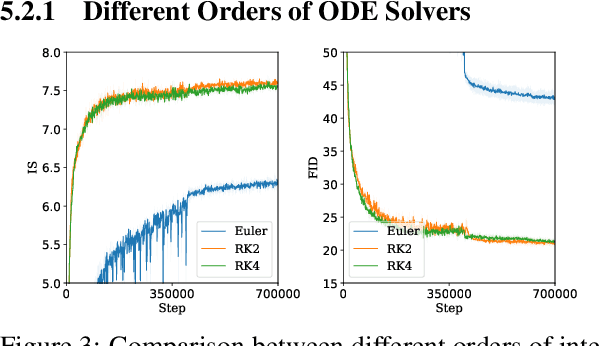
Batch Normalization is a key component in almost all state-of-the-art image classifiers, but it also introduces practical challenges: it breaks the independence between training examples within a batch, can incur compute and memory overhead, and often results in unexpected bugs. Building on recent theoretical analyses of deep ResNets at initialization, we propose a simple set of analysis tools to characterize signal propagation on the forward pass, and leverage these tools to design highly performant ResNets without activation normalization layers. Crucial to our success is an adapted version of the recently proposed Weight Standardization. Our analysis tools show how this technique preserves the signal in networks with ReLU or Swish activation functions by ensuring that the per-channel activation means do not grow with depth. Across a range of FLOP budgets, our networks attain performance competitive with the state-of-the-art EfficientNets on ImageNet.
Training Generative Adversarial Networks by Solving Ordinary Differential Equations
Oct 28, 2020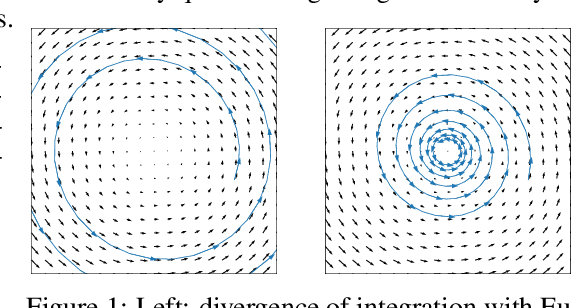
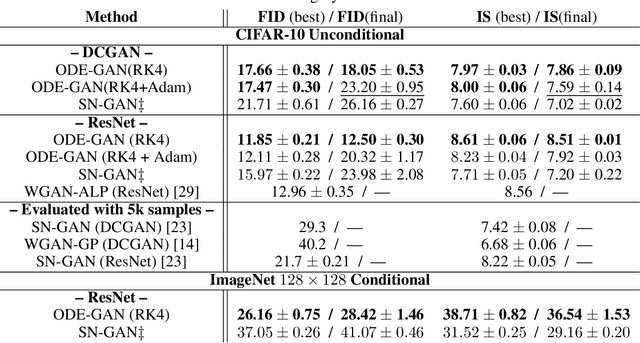
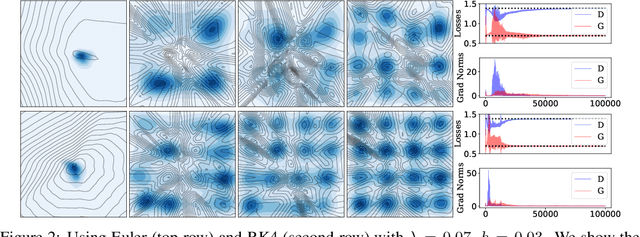
The instability of Generative Adversarial Network (GAN) training has frequently been attributed to gradient descent. Consequently, recent methods have aimed to tailor the models and training procedures to stabilise the discrete updates. In contrast, we study the continuous-time dynamics induced by GAN training. Both theory and toy experiments suggest that these dynamics are in fact surprisingly stable. From this perspective, we hypothesise that instabilities in training GANs arise from the integration error in discretising the continuous dynamics. We experimentally verify that well-known ODE solvers (such as Runge-Kutta) can stabilise training - when combined with a regulariser that controls the integration error. Our approach represents a radical departure from previous methods which typically use adaptive optimisation and stabilisation techniques that constrain the functional space (e.g. Spectral Normalisation). Evaluation on CIFAR-10 and ImageNet shows that our method outperforms several strong baselines, demonstrating its efficacy.
BYOL works even without batch statistics
Oct 20, 2020

Bootstrap Your Own Latent (BYOL) is a self-supervised learning approach for image representation. From an augmented view of an image, BYOL trains an online network to predict a target network representation of a different augmented view of the same image. Unlike contrastive methods, BYOL does not explicitly use a repulsion term built from negative pairs in its training objective. Yet, it avoids collapse to a trivial, constant representation. Thus, it has recently been hypothesized that batch normalization (BN) is critical to prevent collapse in BYOL. Indeed, BN flows gradients across batch elements, and could leak information about negative views in the batch, which could act as an implicit negative (contrastive) term. However, we experimentally show that replacing BN with a batch-independent normalization scheme (namely, a combination of group normalization and weight standardization) achieves performance comparable to vanilla BYOL ($73.9\%$ vs. $74.3\%$ top-1 accuracy under the linear evaluation protocol on ImageNet with ResNet-$50$). Our finding disproves the hypothesis that the use of batch statistics is a crucial ingredient for BYOL to learn useful representations.
Evolving Normalization-Activation Layers
Apr 28, 2020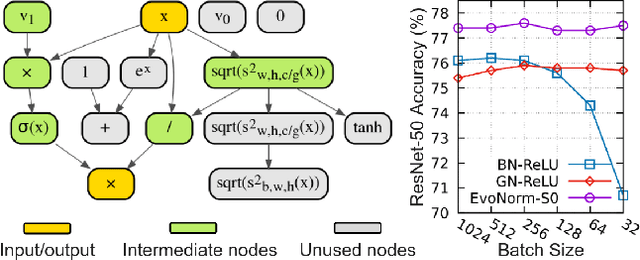

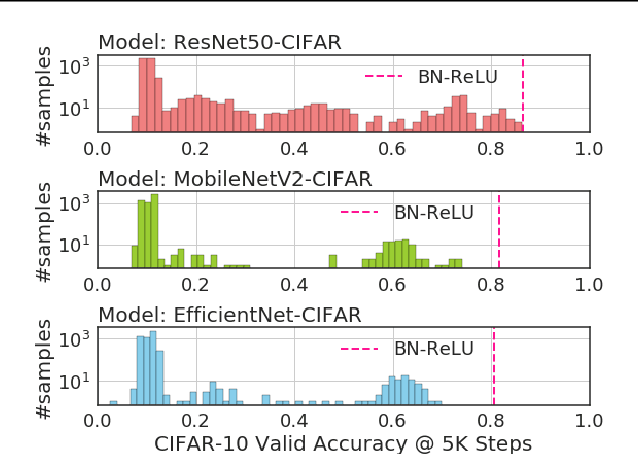
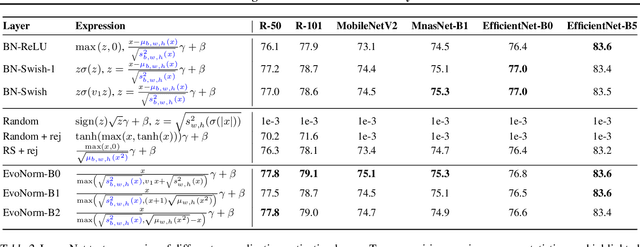
Normalization layers and activation functions are critical components in deep neural networks that frequently co-locate with each other. Instead of designing them separately, we unify them into a single computation graph, and evolve its structure starting from low-level primitives. Our layer search algorithm leads to the discovery of EvoNorms, a set of new normalization-activation layers that go beyond existing design patterns. Several of these layers enjoy the property of being independent from the batch statistics. Our experiments show that EvoNorms not only work well on a variety of image classification models including ResNets, MobileNets and EfficientNets but also transfer well to Mask R-CNN, SpineNet for instance segmentation and BigGAN for image synthesis, significantly outperforming BatchNorm and GroupNorm based layers in many cases.
Large Scale GAN Training for High Fidelity Natural Image Synthesis
Sep 28, 2018
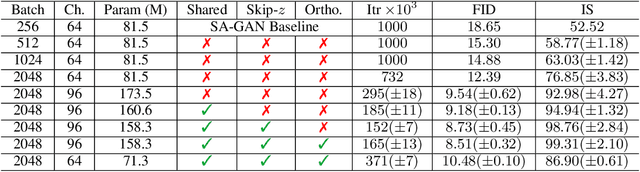


Despite recent progress in generative image modeling, successfully generating high-resolution, diverse samples from complex datasets such as ImageNet remains an elusive goal. To this end, we train Generative Adversarial Networks at the largest scale yet attempted, and study the instabilities specific to such scale. We find that applying orthogonal regularization to the generator renders it amenable to a simple "truncation trick", allowing fine control over the trade-off between sample fidelity and variety by truncating the latent space. Our modifications lead to models which set the new state of the art in class-conditional image synthesis. When trained on ImageNet at 128x128 resolution, our models (BigGANs) achieve an Inception Score (IS) of 166.3 and Frechet Inception Distance (FID) of 9.6, improving over the previous best IS of 52.52 and FID of 18.65.
Implicit Weight Uncertainty in Neural Networks
May 25, 2018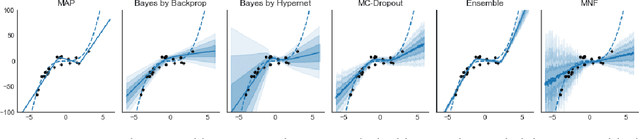

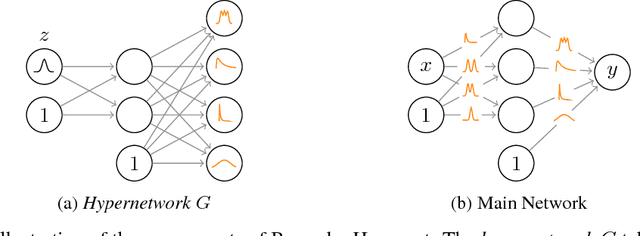

Modern neural networks tend to be overconfident on unseen, noisy or incorrectly labelled data and do not produce meaningful uncertainty measures. Bayesian deep learning aims to address this shortcoming with variational approximations (such as Bayes by Backprop or Multiplicative Normalising Flows). However, current approaches have limitations regarding flexibility and scalability. We introduce Bayes by Hypernet (BbH), a new method of variational approximation that interprets hypernetworks as implicit distributions. It naturally uses neural networks to model arbitrarily complex distributions and scales to modern deep learning architectures. In our experiments, we demonstrate that our method achieves competitive accuracies and predictive uncertainties on MNIST and a CIFAR5 task, while being the most robust against adversarial attacks.
SMASH: One-Shot Model Architecture Search through HyperNetworks
Aug 17, 2017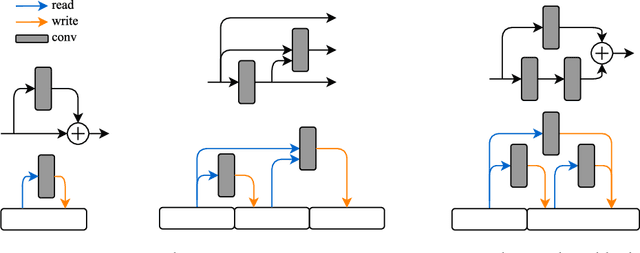
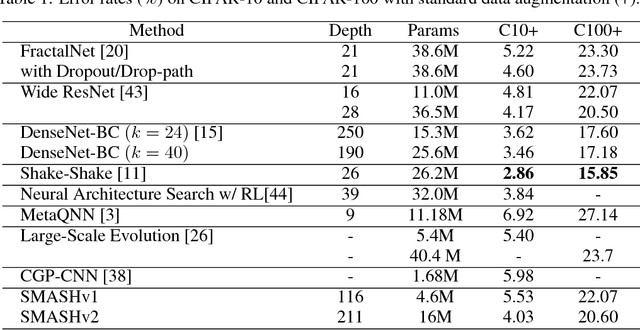

Designing architectures for deep neural networks requires expert knowledge and substantial computation time. We propose a technique to accelerate architecture selection by learning an auxiliary HyperNet that generates the weights of a main model conditioned on that model's architecture. By comparing the relative validation performance of networks with HyperNet-generated weights, we can effectively search over a wide range of architectures at the cost of a single training run. To facilitate this search, we develop a flexible mechanism based on memory read-writes that allows us to define a wide range of network connectivity patterns, with ResNet, DenseNet, and FractalNet blocks as special cases. We validate our method (SMASH) on CIFAR-10 and CIFAR-100, STL-10, ModelNet10, and Imagenet32x32, achieving competitive performance with similarly-sized hand-designed networks. Our code is available at https://github.com/ajbrock/SMASH
FreezeOut: Accelerate Training by Progressively Freezing Layers
Jun 18, 2017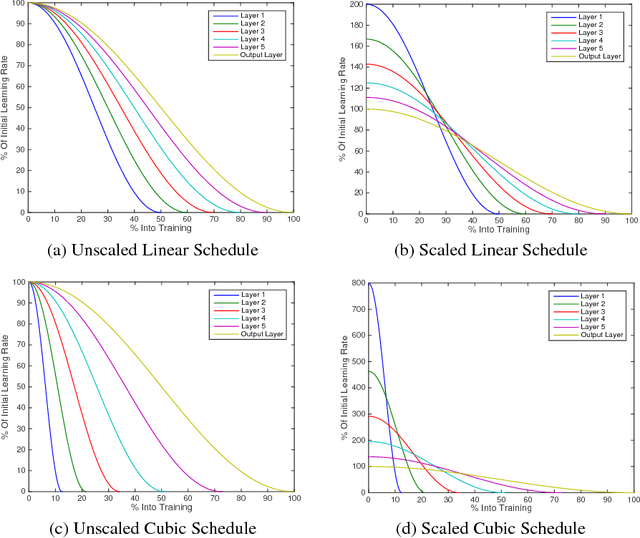
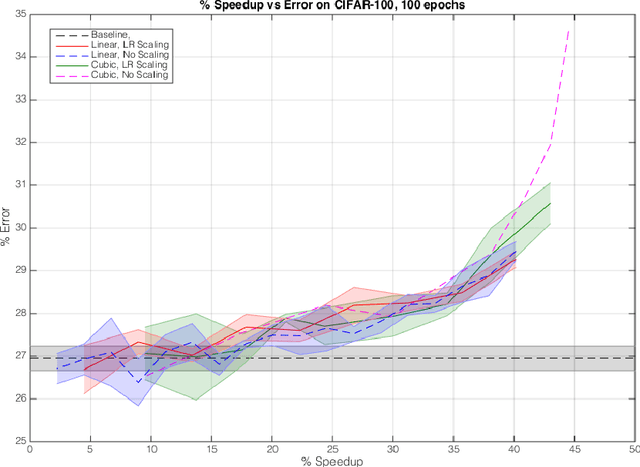
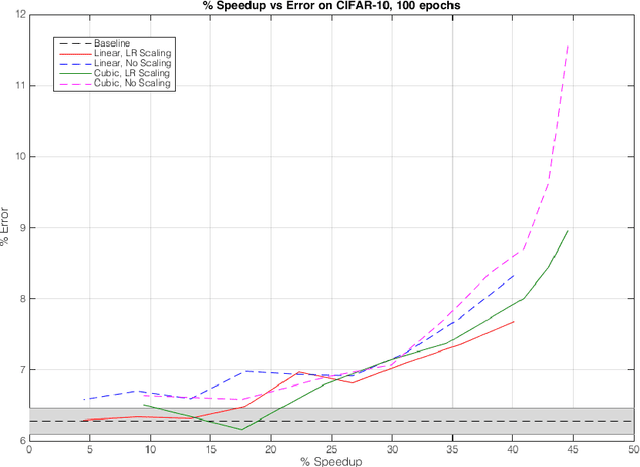
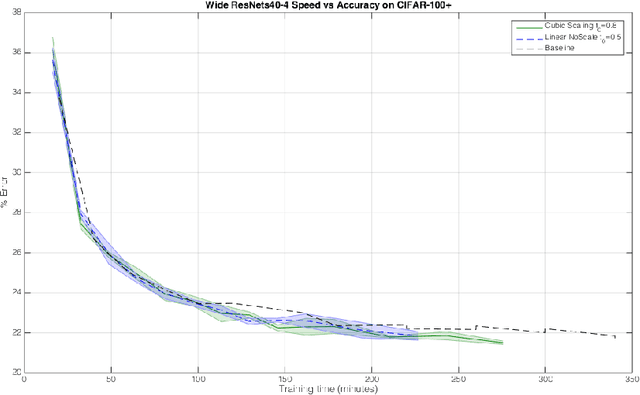
The early layers of a deep neural net have the fewest parameters, but take up the most computation. In this extended abstract, we propose to only train the hidden layers for a set portion of the training run, freezing them out one-by-one and excluding them from the backward pass. Through experiments on CIFAR, we empirically demonstrate that FreezeOut yields savings of up to 20% wall-clock time during training with 3% loss in accuracy for DenseNets, a 20% speedup without loss of accuracy for ResNets, and no improvement for VGG networks. Our code is publicly available at https://github.com/ajbrock/FreezeOut
Neural Photo Editing with Introspective Adversarial Networks
Feb 06, 2017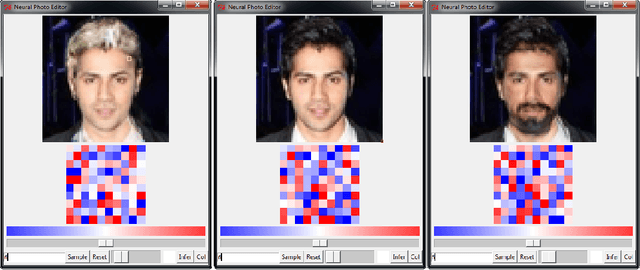
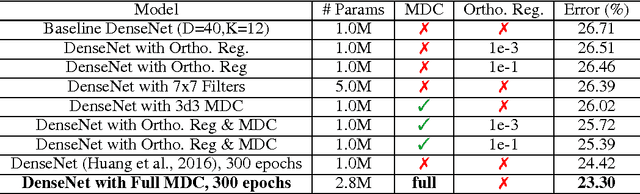

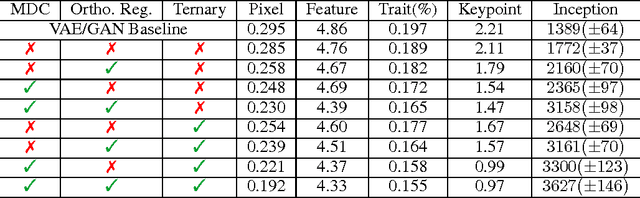
The increasingly photorealistic sample quality of generative image models suggests their feasibility in applications beyond image generation. We present the Neural Photo Editor, an interface that leverages the power of generative neural networks to make large, semantically coherent changes to existing images. To tackle the challenge of achieving accurate reconstructions without loss of feature quality, we introduce the Introspective Adversarial Network, a novel hybridization of the VAE and GAN. Our model efficiently captures long-range dependencies through use of a computational block based on weight-shared dilated convolutions, and improves generalization performance with Orthogonal Regularization, a novel weight regularization method. We validate our contributions on CelebA, SVHN, and CIFAR-100, and produce samples and reconstructions with high visual fidelity.